note
- LLaVA-OneVision-2(LLaVA-OV-2) 是 LLaVA-OneVision 系列的下一代开源多模态大模型,定位是一个 8B 级统一视觉语言模型:同一个模型同时处理 图像、长视频、空间定位、时间定位、目标跟踪、操作轨迹理解 等任务。官方项目页强调它是 "fully-open recipe",模型、数据、训练流程、日志都开放;论文摘要也说它是目前 OneVision 系列里能力最强的版本
- Codec-stream Tokenization:
- 先看 codec 里的运动/残差信息 → 选择关键 GOP/区域 → 打包成视觉 canvas → 再转视觉 token
- 提出了LLaVA-OneVision-2,一种编解码器对齐的长视频多模态语言模型,通过编解码器流token化和共享3D RoPE实现了更高效的视频理解。
- 实验结果表明,LLaVA-OneVision-2在多个视频理解、空间推理和时间定位基准上取得了显著的提升。
- 该模型不仅扩展了长视频推理的事件级覆盖范围,还保留了帧采样作为细节敏感感知的补充路径。
- 未来的工作将进一步扩展编解码器对齐范式,实现流感知和小时级或更长编解码器上下文建模。
文章目录
一、研究背景
链接:https://github.com/EvolvingLMMs-Lab/LLaVA-OneVision-2
- 研究问题:这篇文章要解决的问题是如何在视频理解中实现更高效的感知智能。具体来说,现有的视频理解模型大多采用帧采样的方式,这种方式虽然简单,但会忽略视频的连续空间结构和运动动态,导致对视频的理解不够全面。
- 研究难点:该问题的研究难点包括:如何在有限的视觉token预算下,更稳定地压缩长视频token;如何有效地分配视觉token以捕捉视频中的事件承载内容;如何在高频、密集重复的运动中实现细粒度的时间定位。
- 相关工作:该问题的研究相关工作包括Open Large Vision-Language Models (LVLMs)、视频编解码器的帧内和帧间预测、以及视频理解的时序定位任务。现有的工作主要集中在帧采样和混合分辨率帧的设计上,但这些方法仍然无法充分捕捉视频的连续性和动态性。
二、LLaVA-OneVision-2
这篇论文提出了LLaVA-OneVision-2(LLaVA-OV-2),用于解决视频理解中的感知智能问题。
1、模型架构
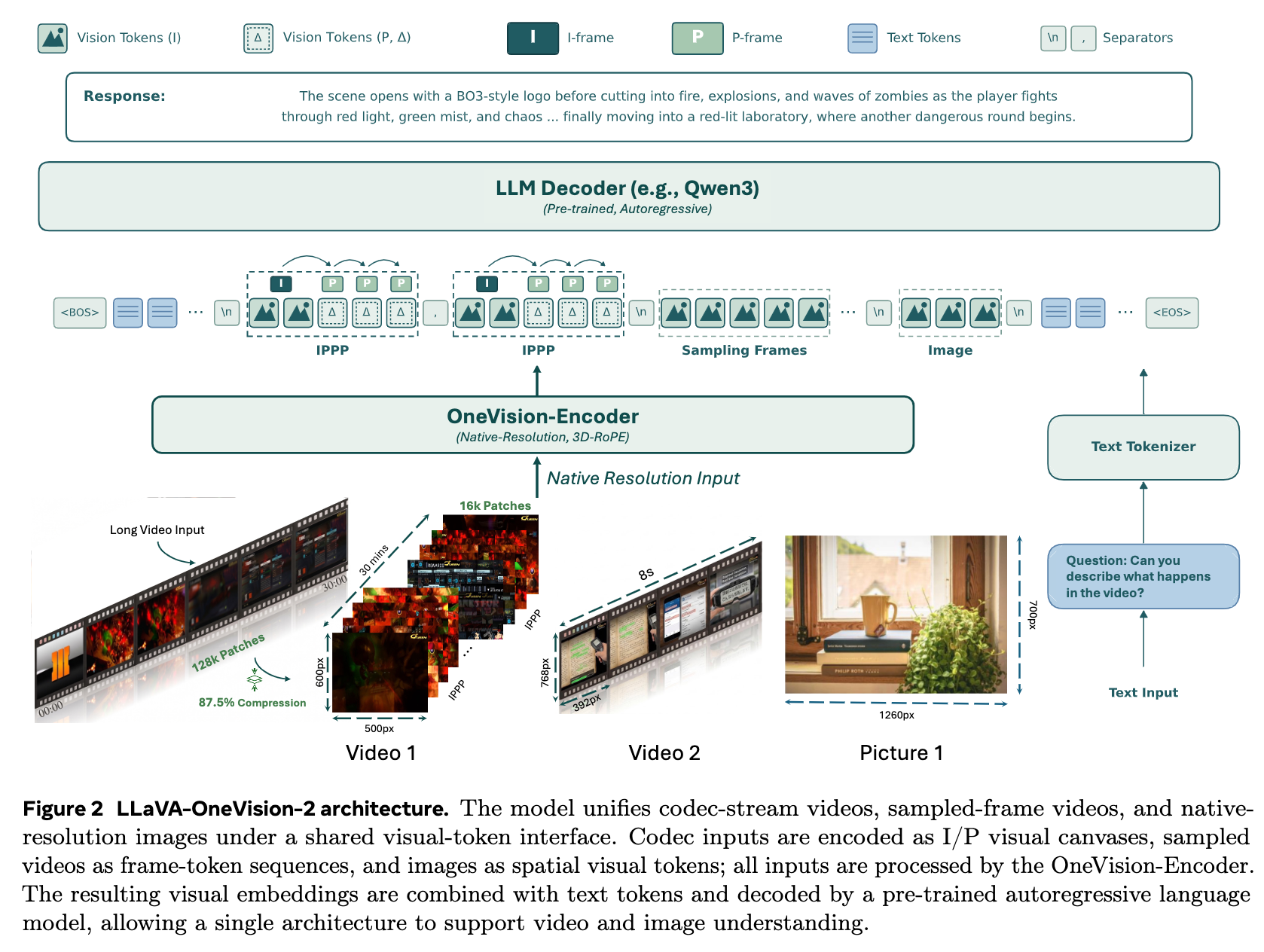
模型架构:LLaVA-OneVision-2基于OneVision-Encoder(OV-Encoder),并结合了窗口化注意力机制以实现高效的局部计算。该模型将压缩视频视为一个连续的比特成本流,通过比特成本动态确定自适应的时间组,并使用运动残差线索将显著的空间证据浓缩成紧凑的视觉画布。
模型架构:
2、Codec-stream Tokenization
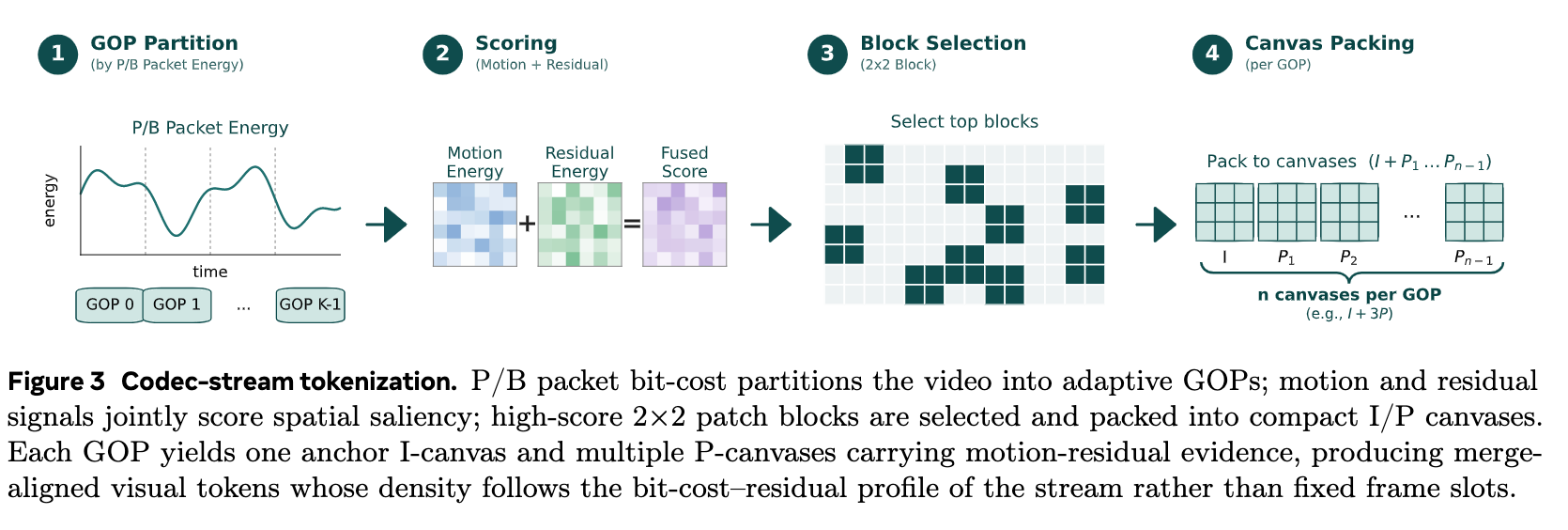
它不是盲目抽帧,而是借助 codec 信息做 事件感知的视频 token 压缩。
论文摘要里说,这比固定 GOP / 固定抽帧更适合长视频,
在相同 visual-token budget 下,codec-stream 输入在 JumpScore temporal grounding 上提升 9.7 分
python
分析压缩视频码流
→ 看哪里 bit-cost 高、运动残差强
→ 自适应分组
→ 选择关键空间区域
→ 形成 compact visual canvases编解码器流token化:
编解码器流token化是该模型的核心创新。它将压缩视频视为一个连续的比特成本流,比特成本的动态变化决定了自适应的时间组边界,而运动残差线索则将显著的空间证据浓缩成紧凑的合并对齐的视觉画布。这种流感知设计使得token密度跟随压缩流的比特成本残差轮廓,在感知转变处密集,在可预测间隔处稀疏,从而实现比固定图像组(GOP)更稳定的长视频token压缩。
| 步骤 | 通俗比喻 | 核心操作与目的 |
|---|---|---|
| 1. GOP 划分(看哪里值得细看) | 给电影分镜头 | 视频编码本来就是一段段(GOP)存的。这里根据码率高低(P/B Packet Energy)来切分。码率高的地方(画面变化剧烈、细节多)就多给它分配"名额"。 |
| 2. 打分(哪里重要选哪里) | 挑重点画草图 | 结合"运动幅度"(Motion)和"残差细节"(Residual,即画面模糊/清晰程度)给画面打分。哪里有明显的动作或细节丰富,哪里分数就高。 |
| 3. 区块选择(挑最好的碎片) | 精挑细选拼图块 | 把画面切成 2x2 的小格子,只挑打分最高的那些格子(图中深色方块)。这就实现了动态分辨率的核心思想:重要的地方看得清,不重要的地方直接忽略。 |
| 4. 画布打包(重新排排坐) | 塞进紧凑小画布 | 把选出来的高分块,像俄罗斯方块一样紧凑地拼进新的画布(Canvases)里。· I-canvas :放关键帧(全景)。· P-canvas:放带动作的帧(局部细节)。这样做的结果是,最终生成的 Tokens 密度完全跟着视频原本的"信息量"走,而不是死板的固定帧数。 |
和其他做法的区别:
| 路线 | 代表思路 |
|---|---|
| 均匀抽帧 | 简单,但容易漏关键片段 |
| 视觉 token 压缩 | 压缩冗余 token,让视频更长 |
| temporal grounding | 先找关键时间段,再密集看 |
| agentic crop/clip | 模型主动请求看某段 |
| codec-aware tokenization | 利用视频压缩码流判断哪里重要 |
| memory / streaming | 分段看视频,维护长期记忆 |
3、OneVision-Encoder + Windowed Attention
| 模块 | 作用 |
|---|---|
| OneVision-Encoder | 统一编码图片、视频、空间任务 |
| Windowed Attention | 在保持原生分辨率的同时降低局部计算成本 |
| native resolution | 不粗暴压缩图片/视频,保留细节 |
这对细粒度感知很重要,比如文字、目标边界、操作轨迹、局部运动。
4、共享3D RoPE
共享3D RoPE:共享的3D RoPE将编解码器画布、采样帧和图像放置在统一的时空坐标系统中,进一步增强了模型的感知能力。
三类视觉输入:图片、采样帧、codec visual canvases
5、模型训练
| 数据 | 作用 |
|---|---|
| 约 8M re-captioned video samples | 视频预训练 |
| 约 4M spatial corpus | 空间理解/定位微调 |
| JumpScore benchmark | 评测高频重复运动里的细粒度时间定位 |
三、实验设计
- 数据收集:LLaVA-OneVision-2的训练数据集包括约800万重新注释的视频样本和400万的2D/3D空间语料库。数据集涵盖了从30秒到15分钟的长视频字幕,并且在每个训练阶段逐步增加帧预算。
- 训练过程:训练过程分为四个阶段,逐步增加监督范围从图像定位到长视频和空间推理。每个阶段使用不同的数据集和帧预算进行训练,确保模型能够逐步学习和适应不同的视频理解任务。
- 评估基准:LLaVA-OneVision-2在多个视频理解、空间推理和图像文档理解基准上进行评估。特别地,引入了JumpScore时间定位基准,用于评估高频、密集重复运动中的细粒度时间定位能力。
四、结果与分析
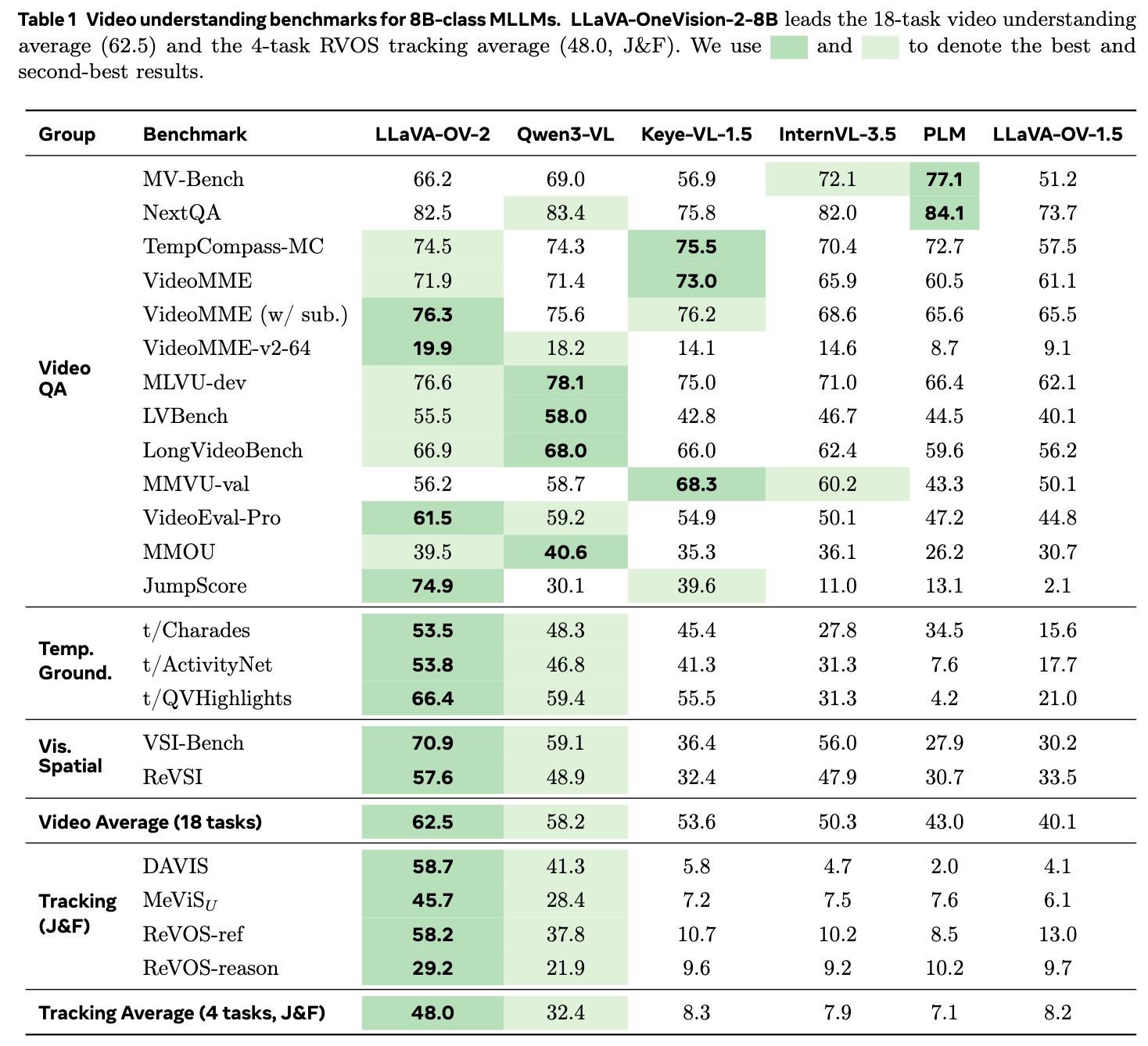
- 视频理解:在18个视频理解基准上,LLaVA-OneVision-2-8B平均得分提高了4.3点(62.5 vs. 58.2)。在时序定位任务上,编解码器输入比帧采样输入提高了9.7点。
- 空间推理:在11个空间推理基准上,LLaVA-OneVision-2-8B平均得分提高了5.3点(63.5 vs. 58.2)。特别是在CrossPoint和TraceSpatial-3D基准上,分别提高了35.0点和近4倍。
- 图像和文档理解:在11个图像和文档理解基准上,LLaVA-OneVision-2-8B保持了竞争力,并在V*-Bench上领先。
- JumpScore:在JumpScore基准上,LLaVA-OneVision-2-8B达到了74.9 JumpScore mAP,比Qwen3-VL-8B提高了44.8点。
JumpScore简介:
- JumpScore = 考 VideoLLM 能不能在"看起来一模一样的重复动作"里,真正记住时序节奏并精确定位每一拍
- 采用 mAP@δ,δ ∈ {0.1s, 0.2s, 0.3s},即预测时间戳与真值在 δ 秒容差内的平均精度均值。
Reference
1 LLaVA-OneVision-2: Towards Next-Generation Perceptual Intelligence