|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 英文名称: You Only Cache Once: Decoder-Decoder Architectures for Language Models 中文名称: 只缓存一次:用于语言模型的解码器-解码器架构 链接: http://arxiv.org/abs/2405.05254v2 作者: Yutao Sun, Li Dong, Yi Zhu, Shaohan Huang, Wenhui Wang, Shuming Ma, Quanlu Zhang, Jianyong Wang, Furu Wei 机构: 微软研究院, 清华大学 日期: 2024-05-08 |
读后感
这篇论文介绍了一种大模型优化的方法。并非专为某个特定的模型设计,而是可以用来优化当前大多数的大模型。该方法在 GPU 内存的使用和模型生成的速度上都有显著的改善。
在 Transformer 方法中,存储 Attention 的 KV 值占用了大量的资源。目前已有许多针对此问题的优化方法,这篇论文也是其中之一。其主要思想是重复利用 KV 缓存。其核心是对 Decoder-Decoder 架构的改进,并不复杂,可以与其他方法结合使用。
如果这种方法成立,那么许多约 70G 左右的模型就可以在只有 10G 显存的机器上运行。这意味着本地模型的效果将大大提高。每个程序员家里花一万块钱就能部署一个 llama-70B,相当于 GPT-3.5+ 的效果,这将可能带来行业布局的新变化。
摘要
- 目标:提出名为 YOCO 的 Self Decoder + Cross Decoder 架构。主要用于优化大型语言模型,其特点是只缓存一次键值对。
- 方法:该架构包括两个主要组件,分别是自解码器和交叉解码器。自解码器负责有效地编码全局键值(KV)缓存,然后通过交叉注意力,这些全局键值(KV)被交叉解码器重复使用,模式与 Transformer 的仅解码器类似。
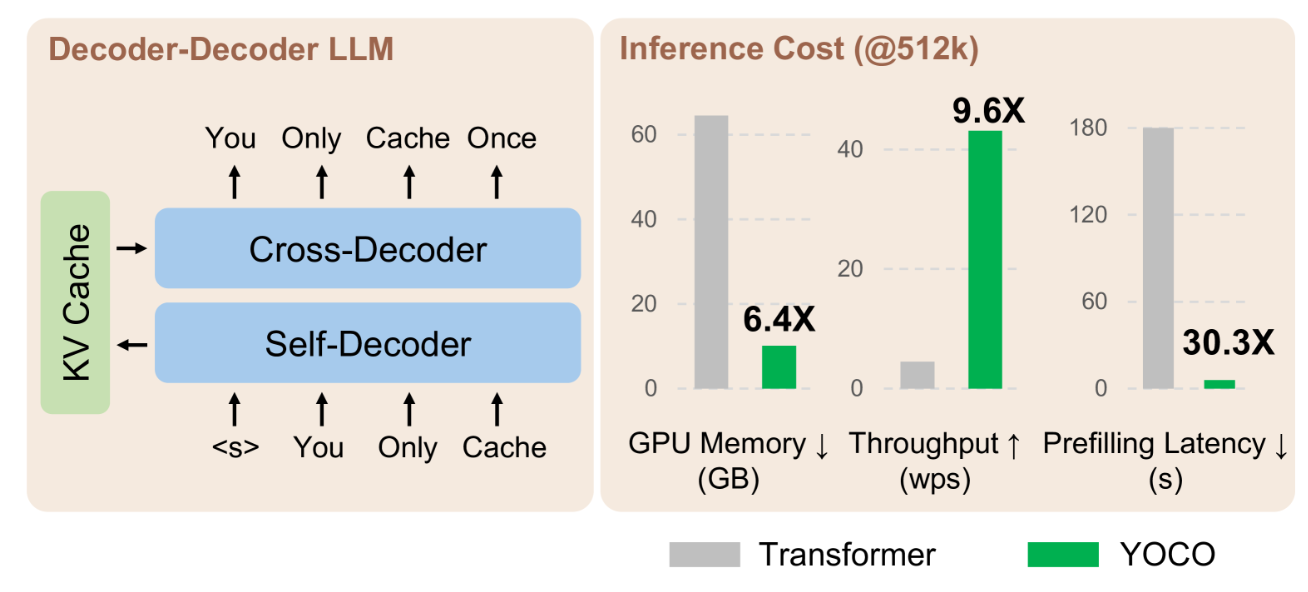
- 结论:实验结果显示,与 Transformer 相比,YOCO 在扩大模型大小和训练令牌数量的不同环境下,都能有效降低 GPU 内存需求、预填充延迟和吞吐量。此外,还成功地将 YOCO 的上下文长度扩展到了 1M 个令牌,实现了近乎完美的针头检索精度。
方法
|500
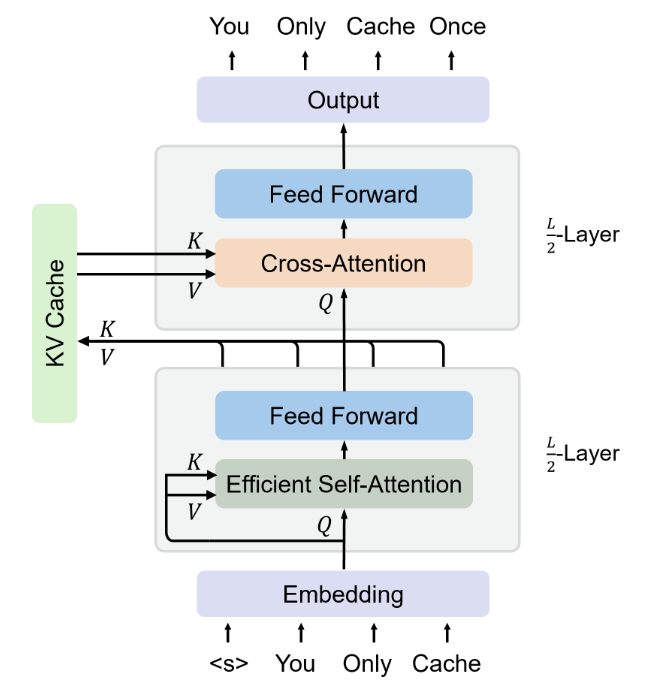
YOCO 是由总共 𝐿 块模块堆叠而成的。其中,自解码器在第 L/2 层,其余部分是交叉解码器。
这两种解码器的布局与 Transformer 类似,包括注意力和前馈网络,包括 RMSNorm、SwiGLU 和分组查询注意力。对于输入序列,自解码器采用有效的自我注意力机制,例如滑动窗口注意力。而交叉解码器则使用全局交叉注意力来处理由自解码器生成的共享 KV 缓存。
自解码器
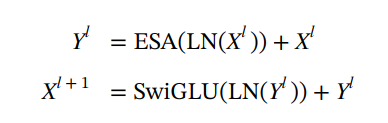
其中 ESA(⋅) 表示有效的自注意力。
交叉解码器
首先,自解码器 𝑋𝐿/2 的输出 𝐾,𝑉 为交叉解码器生成全局 KV 缓存。
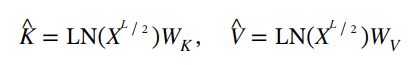
缓存 𝐾,𝑉 由所有 𝐿/2 交叉解码器模块重用。
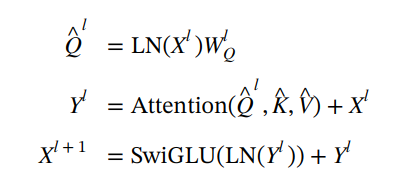
其中 Attention(⋅) 是标准的多头注意力, 𝑊𝑄是一个可学习的矩阵。
推理
原理见:Attention的常见问题
|400
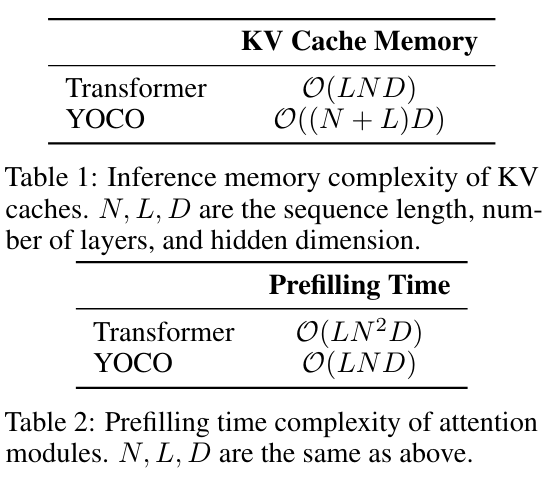
表 1,2 展示了复杂度,N 是序列长度,L 是层数,D 是隐藏层的维度;这可以理解为在多层之间共用 KV 缓存。
实验结果
模型效果略有提升:
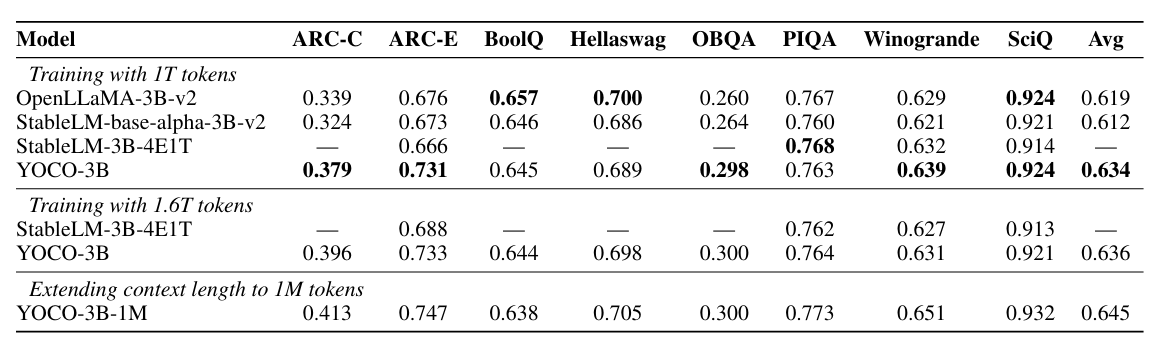
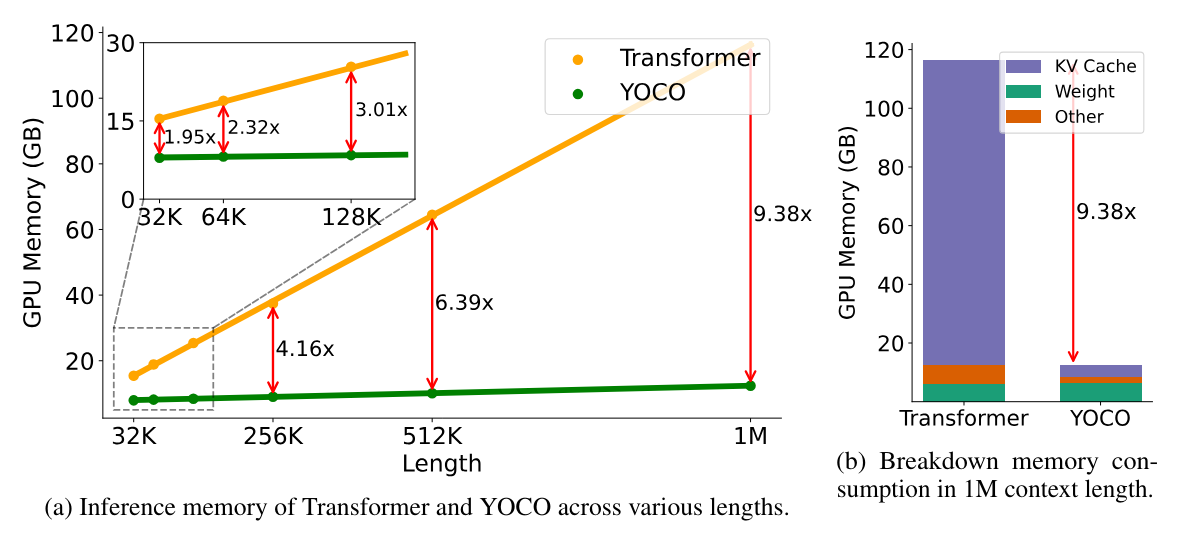
上下文越长内存占用越大。
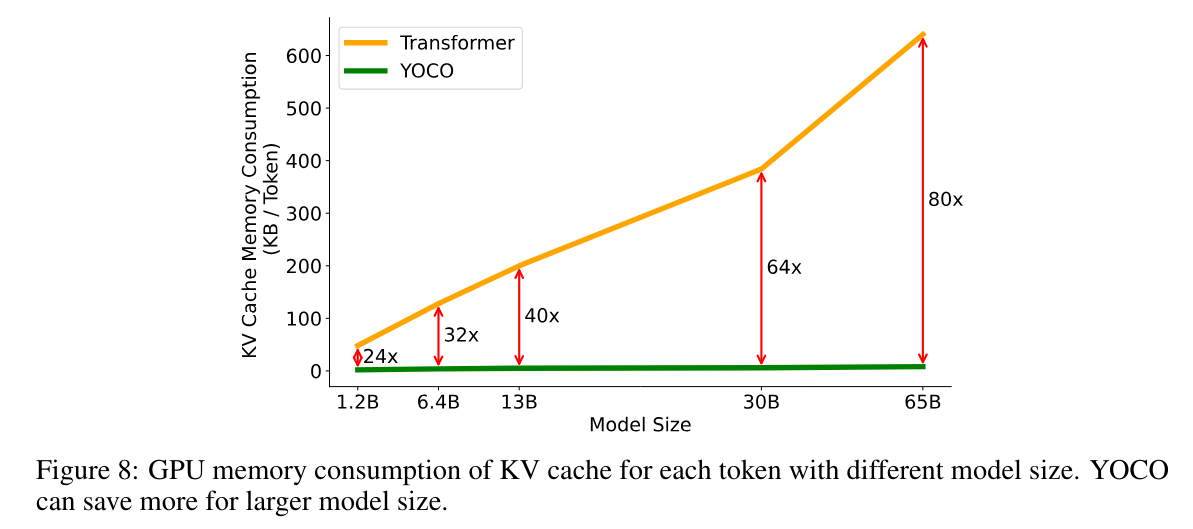
模型越大,KV 缓存占用越大。
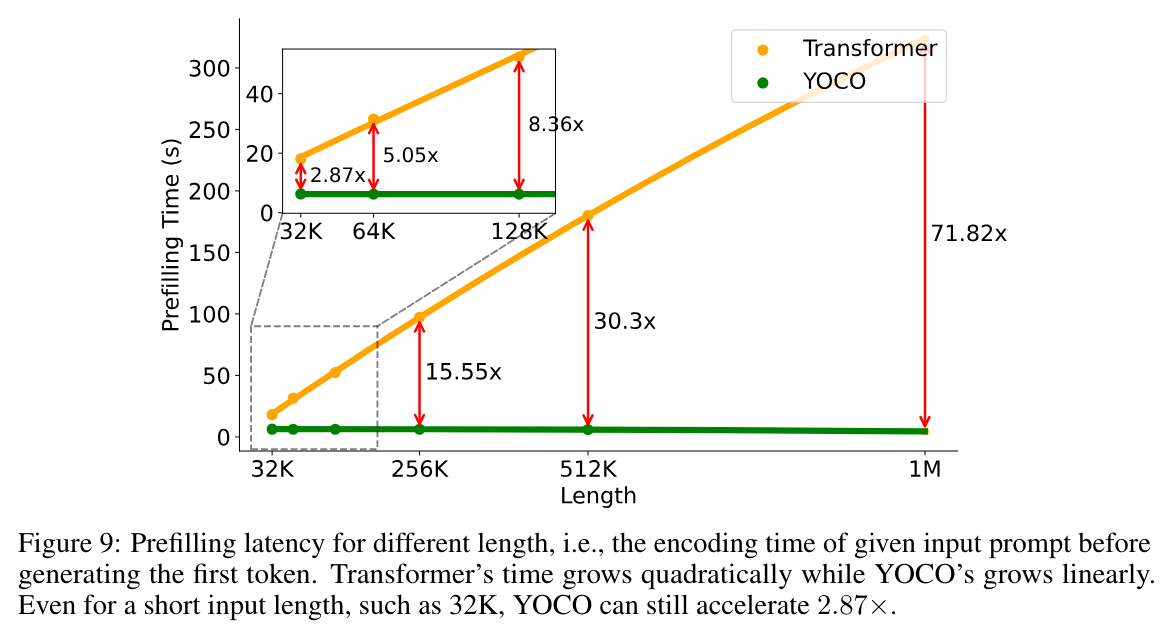
预填充延迟是长上下文模型用户体验的痛点,对于 512K 和 1M 长度的输入序列,Transformer 分别需要大约 180 秒和 300 秒。
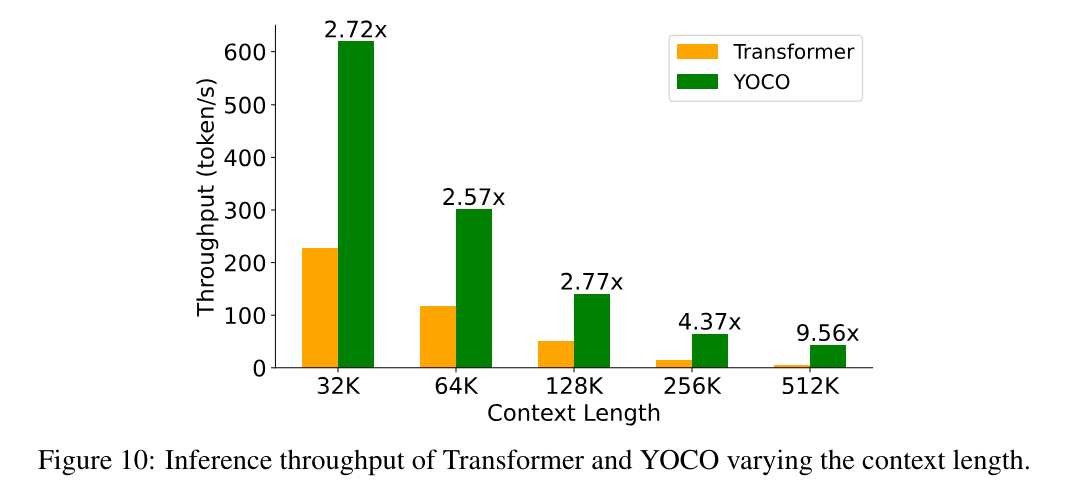
生成速度 (吞吐量) 对比: