中国国家地理网
单张图片爬取
python
import requests
url = 'http://img0.dili360.com/ga/M00/02/AB/wKgBzFQ26i2AWujSAA_-xvEYLbU441.jpg@!rw9'
headers = {
"User-Agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36'
}
img_data = requests.get(url = url,headers=headers).content
with open('./img0.jpg','wb') as fp:
fp.write(img_data)
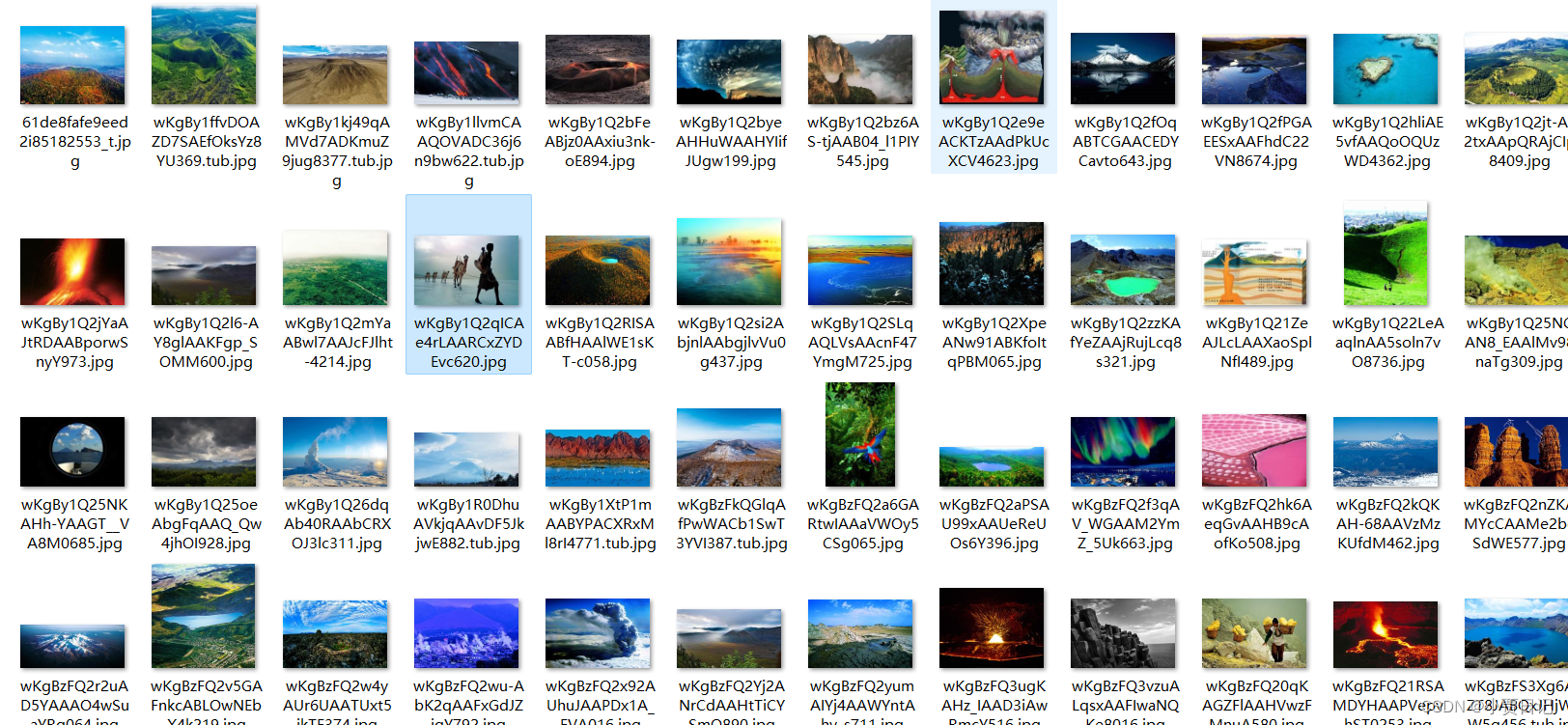
多张爬取
python
import requests
import re
import os
if not os.path.exists('./tupian'):
os.mkdir('./tupian')
# UA标识
headers = {
"User-Agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36'
}
url= 'http://www.dili360.com/travel/sight/20400.htm'
page_text = requests.get(url=url,headers=headers).text
ex = '<div class="thumb-img">.*?<img src="(.*?)".*?</div>'
img_src_list = re_text = re.findall(ex,page_text,re.S)
print(img_src_list)
for src in img_src_list:
img_data = requests.get(url=src).content
img_name = src.split('/')[-1]
img_name = img_name.split('@')[0]
img_path = './tupian/'+img_name
with open(img_path,'wb') as fp:
fp.write(img_data)
print(img_name,"success")
多页爬取
python
import requests
import re
import os
if not os.path.exists('./tupian'):
os.mkdir('./tupian')
# UA标识
headers = {
"User-Agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36'
}
url= 'http://www.dili360.com/Travel/sight/20400/%d.htm'
for page_num in range(1,6):
new_url = format(url % page_num)
page_text = requests.get(url=new_url,headers=headers).text
ex = '<div class="thumb-img">.*?<img src="(.*?)".*?</div>'
img_src_list = re_text = re.findall(ex,page_text,re.S)
print(img_src_list)
for src in img_src_list:
img_data = requests.get(url=src).content
img_name = src.split('/')[-1]
img_name = img_name.split('@')[0]
img_path = './tupian/'+img_name
with open(img_path,'wb') as fp:
fp.write(img_data)
print(img_name,"success")