一、Kafka 集群 KRaft 介绍
Kafka的KRaft模式是一种新的元数据管理方式,旨在去除对ZooKeeper的依赖,使Kafka成为一个完全自包含的系统。在Kafka的传统模式下,元数据管理依赖于ZooKeeper,这增加了部署和运维的复杂性。为了解决这个问题,Kafka社区引入了KRaft模式。在KRaft模式下,所有的元数据,包括主题、分区信息、副本位置等,都被存储在Kafka集群内部的特殊日志中。这个日志使用Raft协议来保证一致性。
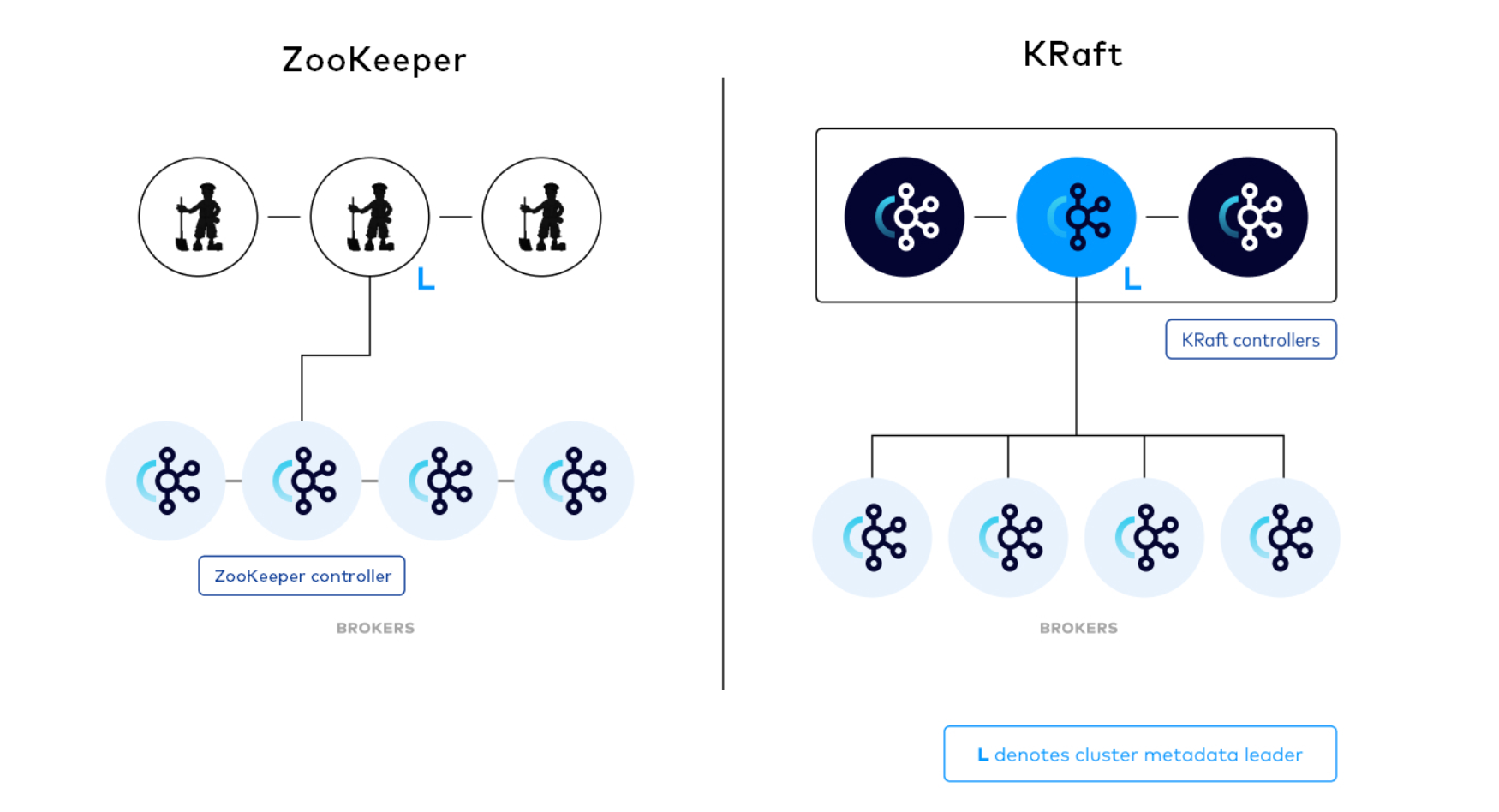
在左边架构中,Kafka集群包含多个 Broker 节点和一个ZooKeeper 集群。Kafka 集群的 Controller 在被选中后,会从 ZooKeeper 中加载它的状态。并且通知其他Broker发生变更,如 Leaderanddis r和 Updatemetdata 请求。
右边新的架构中,三个 Controller 节点替代三个ZooKeeper节点。Controller节点和 Broker 节点运行在不同的进程中。Controller 节点中会选举出一个 Leader 角色。并且Leader 不会主动向 Broker 推送更新,而是由 Broker 拉取元数据信息。
注意:Controller 进程与 Broker 进程在逻辑上是分离的,同时允许部分或所有 Controller 进程和 Broker 进程是同一个进程,即一个Broker节点即是Broker也是Controller。
下面主要实践下 Kafka 集群 KRaft 模式下的搭建。
二、Kafka 集群 KRaft 模式搭建
部署规划如下:
| host | hostname | role | node id |
|---|---|---|---|
| 11.0.1.146 | node1 | Broker,Controller | 1 |
| 11.0.1.147 | node2 | Broker,Controller | 2 |
| 11.0.1.148 | node3 | Broker,Controller | 3 |
以下操作三台机器均需要执行。
配置 hosts :
shell
vi /etc/hosts
shell
11.0.1.146 node1
11.0.1.147 node2
11.0.1.148 node3下载安装包:
shell
wget https://archive.apache.org/dist/kafka/3.4.0/kafka_2.13-3.4.0.tgz解压:
shell
tar -zxvf kafka_2.13-3.4.0.tgz创建数据存储目录:
shell
cd kafka_2.13-3.4.0
mkdir data修改 config/kraft/server.properties 配置文件,注意 node.id和 advertised.listeners 根据不同的机器编码填写,主要修改内容如下:
shell
vi config/kraft/server.properties
shell
process.roles=broker,controller
node.id=1
controller.quorum.voters=1@node1:9093,2@node2:9093,3@node3:9093
listeners=PLAINTEXT://:9092,CONTROLLER://:9093
inter.broker.listener.name=PLAINTEXT
advertised.listeners=PLAINTEXT://node1:9092
controller.listener.names=CONTROLLER
生成集群唯一标志 ID,官方提供了 kafka-storage 工具可以生成唯一ID,也可以自己生成一个唯一的 ID:
shell
bin/kafka-storage.sh random-uuid
使用唯一标志 ID 初始化存储路径:
shell
bin/kafka-storage.sh format -t cGuFZQ70Rf6OQFNMumq33g -c config/kraft/server.properties
以 KRaft 模式启动服务:
shell
bin/kafka-server-start.sh -daemon config/kraft/server.properties观察日志是否启动成功:
shell
tail -f logs/server.log
三、环境测试
查看 Broker 情况:
shell
bin/kafka-broker-api-versions.sh --bootstrap-server node1:9092,node2:9092,node3:9092
测试创建 topic :
shell
bin/kafka-topics.sh --create --topic test --partitions 3 --replication-factor 2 --bootstrap-server node1:9092,node2:9092,node3:9092
查看 topic 的情况:
shell
bin/kafka-topics.sh --describe --bootstrap-server node1:9092,node2:9092,node3:9092
发送 Topic 消息测试:
shell
bin/kafka-console-producer.sh --broker-list node1:9092,node2:9092,node3:9092 --topic test
消费者消费消息:
shell
bin/kafka-console-consumer.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --topic test