HTTP
HTTP 是什么?
HTTP (全称为 "超⽂本传输协议") 是⼀种应⽤⾮常⼴泛的 应用层协议.
所谓 "超⽂本" 的含义, 就是传输的内容不仅仅是⽂本(⽐如 html, css 这个就是⽂本), 还可以是⼀些其他的资源, ⽐如图⽚, 视频, ⾳频等⼆进制的数据
HTTP 往往是基于传输层的 TCP 协议实现的. (HTTP1.0, HTTP1.1, HTTP2.0 均为TCP, HTTP3 基于UDP 实现)
我们平时打开⼀个⽹站, 就是通过 HTTP 协议来传输数据的
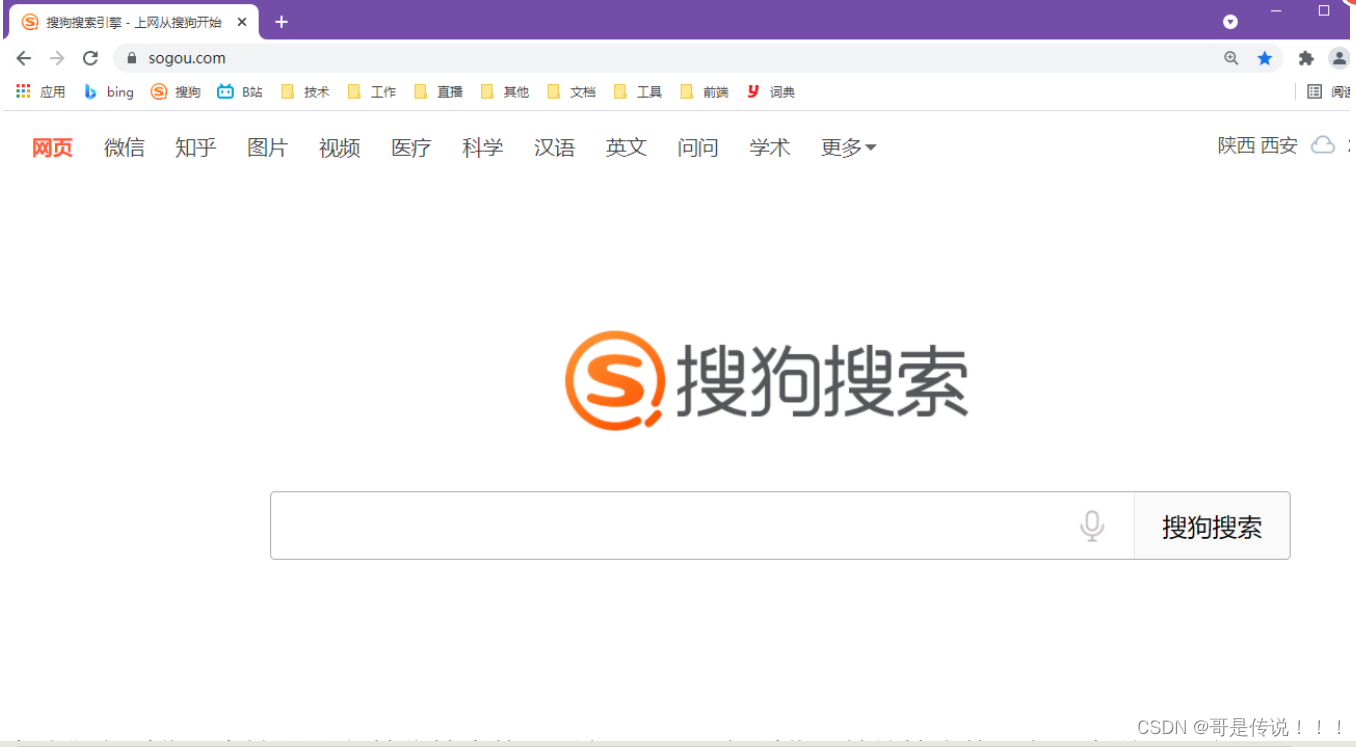
当我们在浏览器中输⼊⼀个 搜狗搜索的 "⽹址" (URL) 时, 浏览器就给搜狗的服务器发送了⼀个 HTTP请求, 搜狗的服务器返回了⼀个 HTTP 响应.
这个响应结果被浏览器解析之后, 就展⽰成我们看到的⻚⾯内容. (这个过程中浏览器可能会给服务器发送多个 HTTP 请求, 服务器会对应返回多个响应, 这些响应⾥就包含了⻚⾯ HTML, CSS, JavaScript, 图⽚, 字体等信息).
理解 HTTP 协议的⼯作过程
当我们在浏览器中输⼊⼀个 "⽹址", 此时浏览器就会给对应的服务器发送⼀HTTP 请求. 对⽅服务器收到这个请求之后, 经过计算处理, 就会返回⼀个 HTTP 响应.
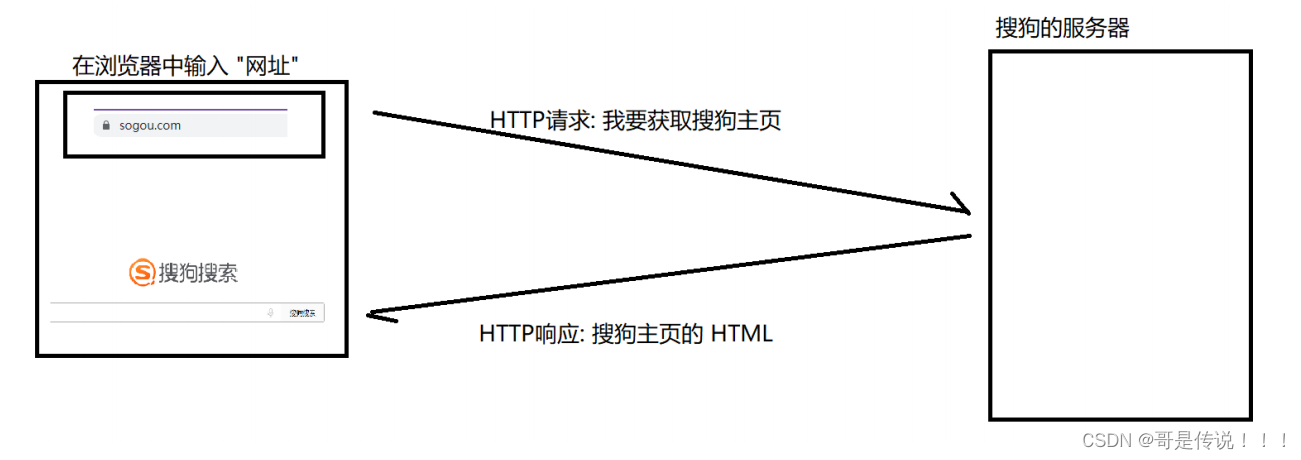
事实上, 当我们访问⼀个⽹站的时候, 可能涉及不⽌⼀次的 HTTP 请求/响应 的交互过程
HTTP 协议格式
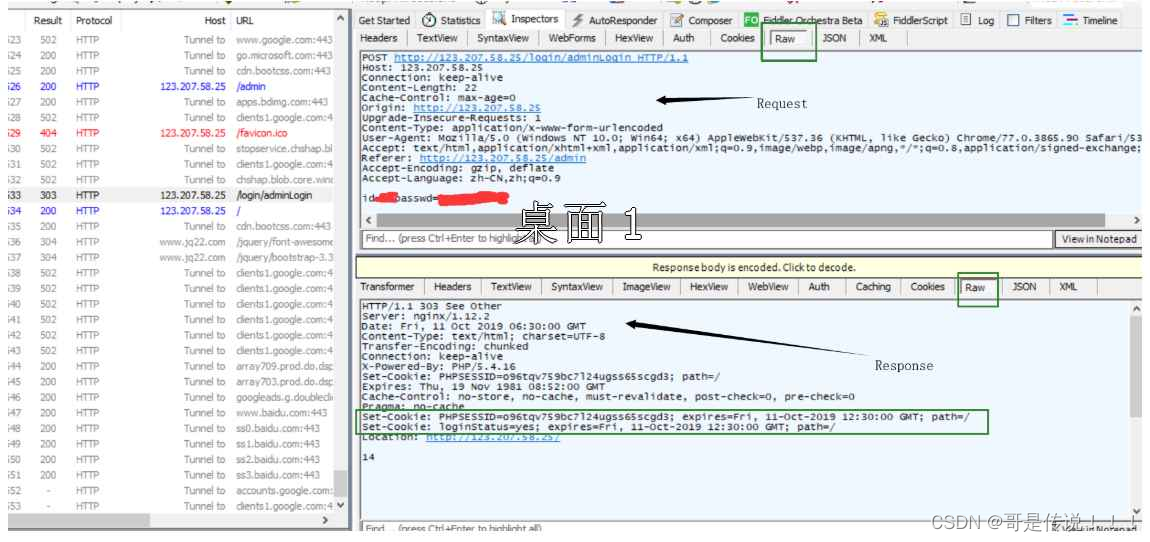
HTTP 是⼀个⽂本格式的协议. 可以通过 Chrome 开发者⼯具或者 Fiddler 抓包, 分析 HTTP 请求/响应的细节
抓包⼯具的使用
1.以 Fiddler 为例
(下载地址: https://www.telerik.com/fiddler/)
2.浏览器内置的抓包工具
3.wireshark
不仅能抓到HTTP,也能抓到TCP,UDP,IP,功能非常强的专业软件,但是使用的门槛比较高,抓取HTTP时缺少针对性优化
抓包⼯具的原理
Fiddler 相当于⼀个 "代理".
浏览器访问 sogou.com 时, 就会把 HTTP 请求先发给 Fiddler, Fiddler 再把请求转发给 sogou 的服务器. 当 sogou 服务器返回数据时, Fiddler 拿到返回数据, 再把数据交给浏览器.因此 Fiddler 对于浏览器和 sogou 服务器之间交互的数据细节, 都是⾮常清楚的.
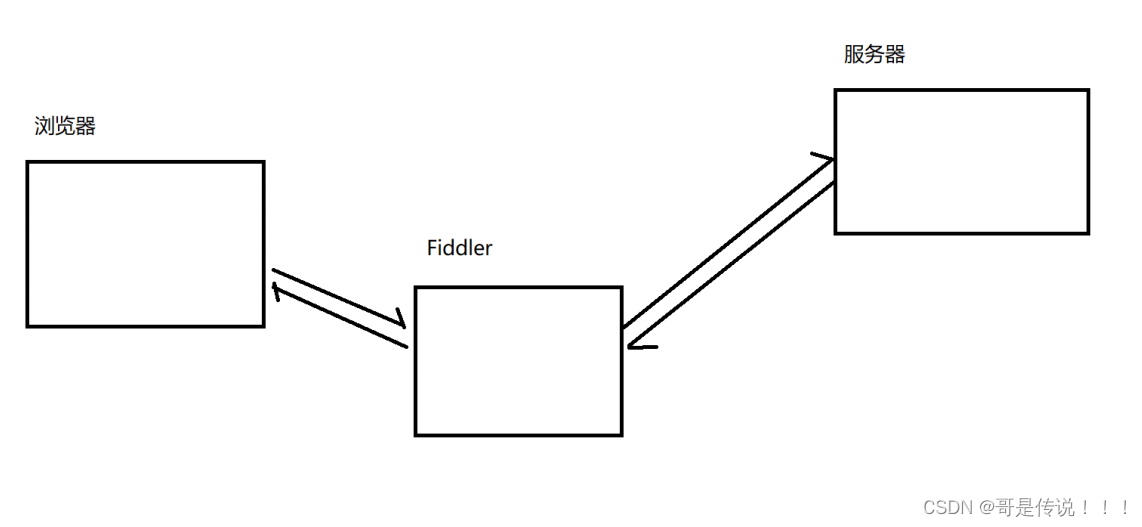
抓包结果
以下是⼀个 HTTP请求/响应 的抓包结果.
HTTP请求
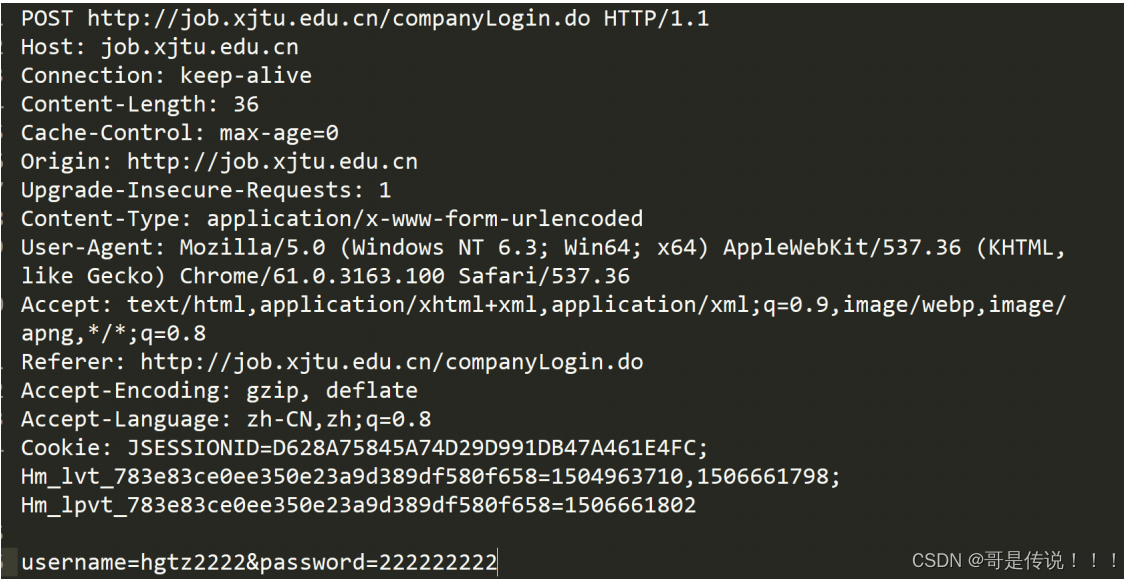
• ⾸⾏: ⽅法 + url + 版本
• Header: 请求的属性, 冒号分割的键值对;每组属性之间使⽤\n分隔;遇到空⾏表⽰Header部分结束
• Body: 空⾏后⾯的内容都是Body.Body允许为空字符串. 如果Body存在, 则在Header中会有⼀个Content-Length属性来标识Body的⻓度;
HTTP响应
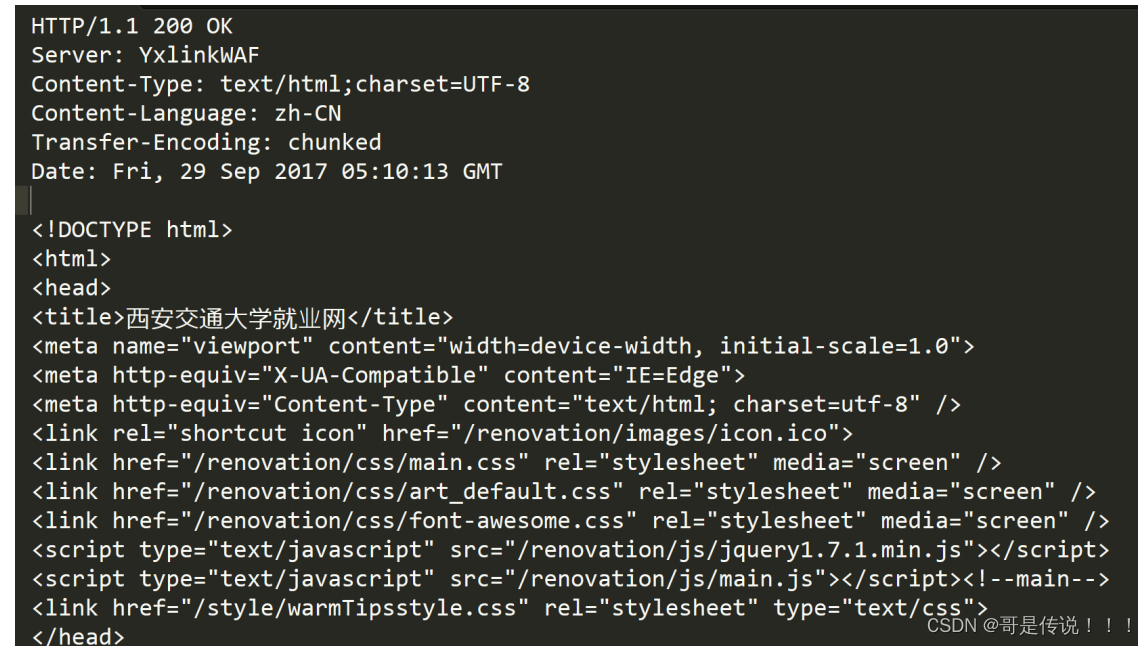
• ⾸⾏: 版本号 + 状态码 + 状态码解释 • Header: 请求的属性,冒号分割的键值对;每组属性之间使⽤\n分隔;遇到空⾏表⽰Header部分结束
• Body: 空⾏后⾯的内容都是Body.Body允许为空字符串. 如果Body存在, 则在Header中会有⼀个 Content-Length属性来标识Body的⻓度;如果服务器返回了⼀个html⻚⾯, 那么html⻚⾯内容就是 在body中.
协议格式总结
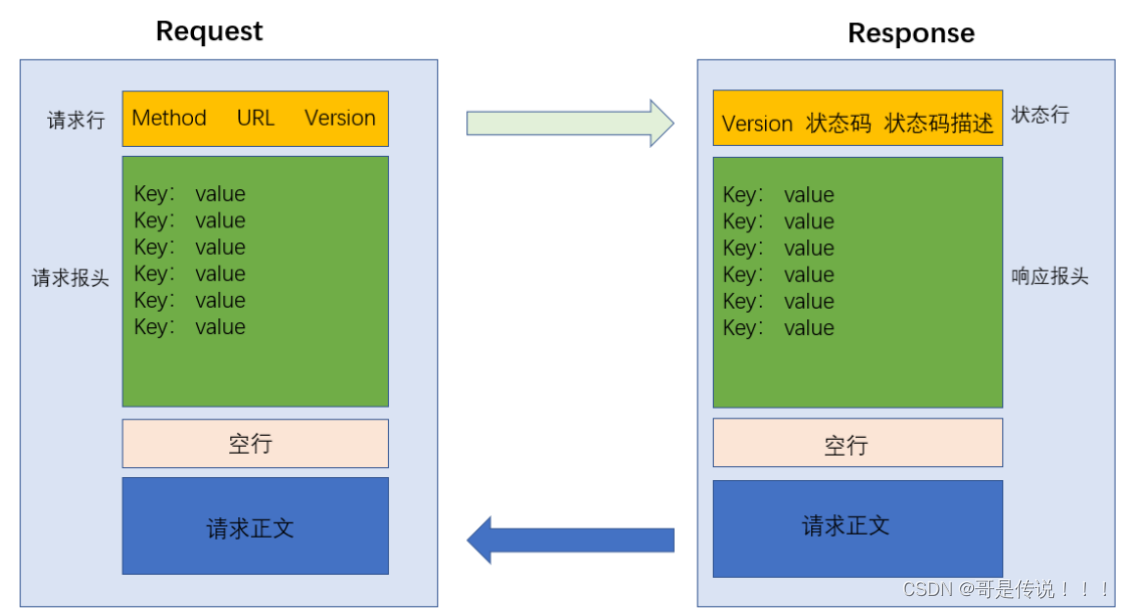
为什么 HTTP 报文中要存在 "空行"?
因为 HTTP 协议并没有规定报头部分的键值对有多少个. 空⾏就相当于是 "报头的结束标记", 或者是"报头和正⽂之间的分隔符".
HTTP 在传输层依赖 TCP 协议, TCP 是⾯向字节流的. 如果没有这个空⾏, 就会出现 "粘包问题"
HTTP 请求 (Request)
认识 URL
URL 基本格式
平时我们俗称的 "⽹址" 其实就是说的 URL (Uniform Resource Locator统⼀资源定位符).互联⽹上的每个⽂件都有⼀个唯⼀的URL,它包含的信息指出⽂件的位置以及浏览器应该怎么处理它.URL 的详细规则由因特⽹标准RFC1738 进⾏了约定
https : 协议⽅案名. 常⻅的有 http 和 https, 也有其他的类型. (例如访问 mysql 时⽤的jdbc:mysql )
user:pass : 登陆信息. 现在的⽹站进⾏⾝份认证⼀般不再通过 URL 进⾏了. ⼀般都会省略
v.bitedu.vip : 服务器地址. 此处是⼀个 "域名", 域名会通过 DNS 系统解析成⼀个具体的 IP 地 址. (通过ping 命令可以看到, v.bitedu.vip 的真实 IP 地址为 118.24.113.28 )
端⼝号 : 上⾯的 URL中端⼝号被省略了. 当端⼝号省略的时候, 浏览器会根据协议类型⾃动决定使⽤ 哪个端⼝. 例如 http 协议默认使⽤ 80 端⼝,https 协议默认使⽤ 443 端⼝
/personInf/student : 带层次的⽂件路径.
userId=10000&classId=100 : 查询字符串(query string). 本质是⼀个键值对结构. 键值对之 间使⽤ &分隔. 键和值之间使⽤ = 分隔.
片段标识: 此 URL 中省略了⽚段标识. ⽚段标识主要⽤于⻚⾯内跳转. (例如 Vue 官⽅⽂档:https://cn.vuejs.org/v2/guide/#起步, 通过不同的⽚段标识跳转到⽂档的不同章节)

URL 中的可省略部分
协议名 : 可以省略, 省略后默认为 http://
ip 地址 / 域名 : 在 HTML 中可以省略(⽐如 img, link,script, a 标签的 src 或者 href 属性). 省略后表⽰服务器的 ip / 域名与当前 HTML 所属的 ip /域名⼀致.
端⼝号 : 可以省略. 省略后如果是 http 协议, 端⼝号⾃动设为 80; 如果是 https 协议,端⼝号⾃动设为443.
带层次的⽂件路径 : 可以省略. 省略后相当于 / . 有些服务器会在发现 /路径的时候⾃动访问/index.html
查询字符串 : 可以省略
⽚段标识: 可以省略
关于 URL encode
像 / ? : 等这样的字符, 已经被url当做特殊意义理解了. 因此这些字符不能随意出现. ⽐如, 某个参数中需要带有这些特殊字符,就必须先对特殊字符进⾏转义.
⼀个中⽂字符由 UTF-8 或者 GBK 这样的编码⽅式构成, 虽然在 URL 中没有特殊含义, 但是仍然需要进⾏转义. 否则浏览器可能把 UTF-8/GBK 编码中的某个字节当做 URL 中的特殊符号.
转义的规则如下: 将需要转码的字符转为16进制,然后从右到左,取4位(不⾜4位直接处理),每2位做⼀位,前⾯加上%,编码成%XY格式
例: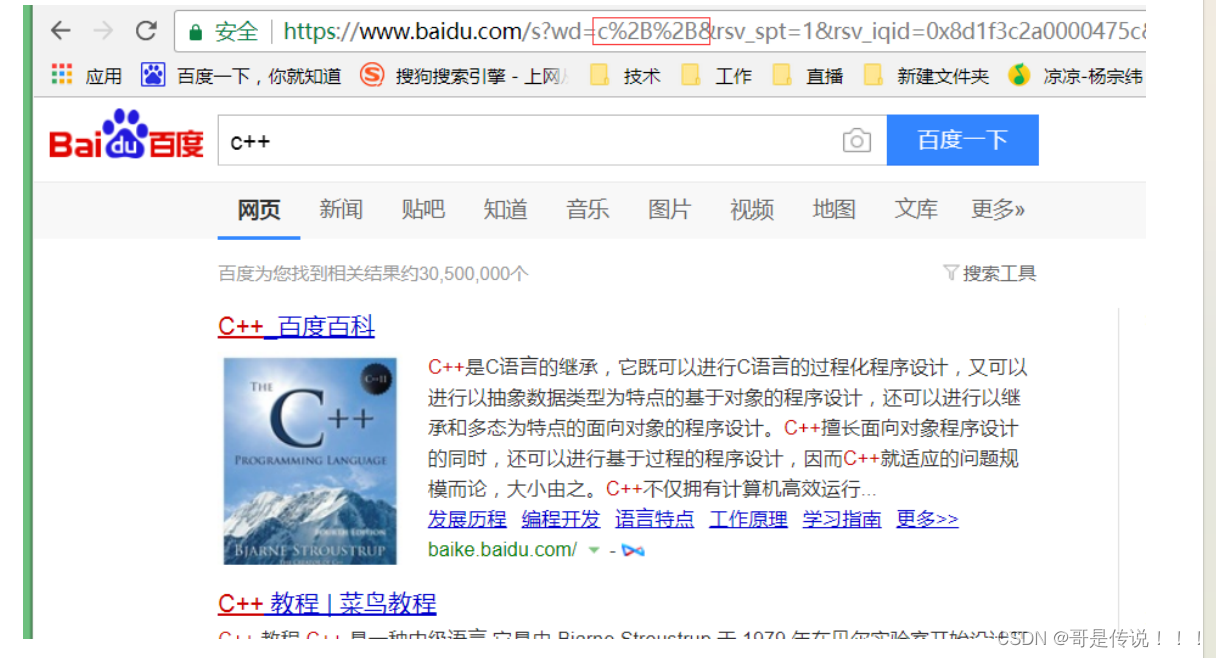
认识 "方法" (method)
1.GET ⽅法
GET 是最常⽤的 HTTP ⽅法. 常⽤于获取服务器上的某个资源.在浏览器中直接输⼊ URL, 此时浏览器就会发送出⼀个 GET 请求.另外, HTML 中的 link, img, script 等标签, 也会触发 GET 请求
GET 请求的特点
• ⾸⾏的第⼀部分为 GET
• URL 的 query string 可以为空, 也可以不为空.
• header部分有若⼲个键值对结构.
• body 部分为空.
关于 GET 请求的 URL ⻓度问题
⽹上有些资料上描述: get请求⻓度最多1024kb 这样的说法是错误的.
HTTP 协议由 RFC 2616 标准定义, 标准原⽂中明确说明: "Hypertext Transfer Protocol -- HTTP/1.1,"does not specify any requirement for URL length.
没有对 URL 的⻓度有任何的限制.实际 URL 的⻓度取决于浏览器的实现和 HTTP 服务器端的实现. 在浏览器端, 不同的浏览器最⼤⻓度是不同的, 但是现代浏览器⽀持的⻓度⼀般都很⻓; 在服务器端, ⼀般这个⻓度是可以配置的.
2. POST ⽅法
POST ⽅法也是⼀种常⻅的⽅法. 多⽤于提交⽤⼾输⼊的数据给服务器(例如登陆⻚⾯).
通过 HTML 中的 form 标签可以构造 POST 请求, 或者使⽤ JavaScript 的 ajax 也可以构造 POST 请求.
POST 请求的特点
• ⾸⾏的第⼀部分为 POST
• URL 的 query string ⼀般为空 (也可以不为空)
• header部分有若⼲个键值对结构.
•body 部分⼀般不为空. body 内的数据格式通过 header 中的 Content-Type 指定.body 的⻓度 由 header 中的 Content-Length 指定.
谈谈 GET 和 POST 的区别
1.语义不同 : GET ⼀般⽤于获取数据, POST ⼀般⽤于提交数据.
2.GET 的 body ⼀般为空, 需要传递的数据通过query string 传递, POST 的 query string ⼀般为空, 需 要传递的数据通过 body 传递
3.GET请求⼀般是幂等的, POST 请求⼀般是不幂等的. (如果多次请求得到的结果⼀样, 就视为请求是 幂等的)
4.GET 可以被缓存, POST 不能被缓存. (这⼀点也是承接幂等性).
补充说明:关于语义: GET 完全可以⽤于提交数据, POST也完全可以⽤于获取数据.
关于幂等性: 标准建议 GET 实现为幂等的. 实际开发中 GET 也不必完全遵守这个规则(主流⽹站都有 "猜你喜欢" 功能, 会根据⽤⼾的历史⾏为实时更新现有的结果. 关于安全性: 有些资料上说 "POST ⽐ GET 请安全". 这样的说法是不科学的. 是否安全取决于前端在 传输密码等敏感信息时是否进⾏加密, 和 GET POST ⽆关.
关于传输数据量:有的资料上说 "GET 传输的数据量⼩, POST 传输数据量⼤". 这个也是不科学的, 标 准没有规定 GET 的 URL 的⻓度, 也没有规定 POST 的 body 的⻓度. 传输数据量多少, 完全取决于不 同浏览器和不同服务器之间的实现区别. 关于传输数据类型: 有的资料上说 "GET 只能传输⽂本数据, POST 可以传输⼆进制数据". 这个也是 不科学的. GET 的 query string虽然⽆法直接传输⼆进制数据, 但是可以针对⼆进制数据进⾏ url encode.
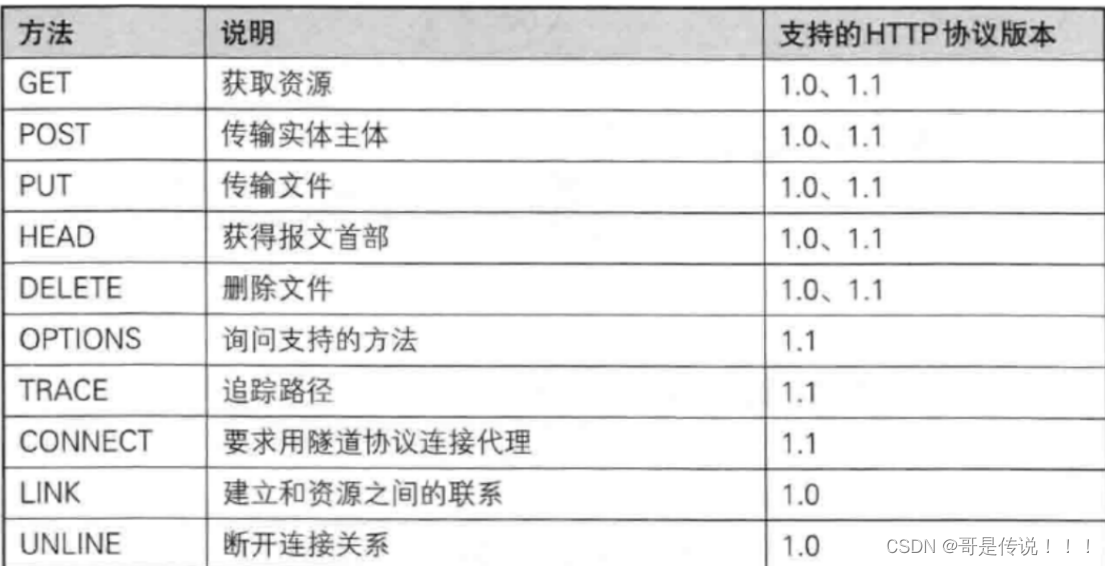
3. 其他⽅法
• PUT 与 POST 相似,只是具有幂等特性,⼀般⽤于更新
• DELETE 删除服务器指定资源
• OPTIONS 返回服务器所⽀持的请求⽅法
• HEAD 类似于GET,只不过响应体不返回,只返回响应头
• TRACE 回显服务器端收到的请求,测试的时候会⽤到这个
• CONNECT 预留,暂⽆使⽤
认识请求 "报头" (header)
header 的整体的格式也是 "键值对" 结构. 每个键值对占⼀⾏. 键和值之间使⽤分号分割.
报头的种类有很多, 此处仅介绍⼏个常⻅的:
Host
表⽰服务器主机的地址和端⼝.
Content-Length
表⽰ body 中的数据⻓度.
Content-Type 关于 Content-Type 的详细情况
Content-Type
响应中的 Content-Type 常⻅取值有以下⼏种:
• text/html : body 数据格式是 HTML
• text/css : body 数据格式是 CSS
•application/javascript : body 数据格式是 JavaScript
• application/json :body 数据格式是 JSON
User-Agent (简称 UA)
表⽰浏览器/操作系统的属性

其中 Windows NT 10.0; Win64; x64 表⽰操作系统信息
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36 表⽰浏览器信息 .
Referer
表⽰这个⻚⾯是从哪个⻚⾯跳转过来的.
Cookie
Cookie 中存储了⼀个字符串, 这个数据可能是客⼾端(⽹⻚)⾃⾏通过 JS 写⼊的, 也可能来⾃于服务器(服务器在 HTTP 响应的 header 中通过 Set-Cookie 字段给浏览器返回数据).往往可以通过这个字段实现 "⾝份标识" 的功能.
每个不同的域名下都可以有不同的 Cookie, 不同⽹站之间的 Cookie 并不冲突.
Cookie是啥:浏览器本地存储数据的一种机制(不是唯一的只是典型的一种)
Cookie怎么存的:按照不同的域名,分别存储在硬盘上,不同域名之间的Cookie互不干扰。键值对,存储文本,键和值都是用户自己定义的
Cookie从那里来:从服务器来,服务器的HTTP响应header中可以填写Set-Cookie字段,就会带一些键值对
Cookie到哪里去:在后续请求中,通过HTTP请求header中的Cookie字段,把信息传输给服务器
HTTP 响应详解
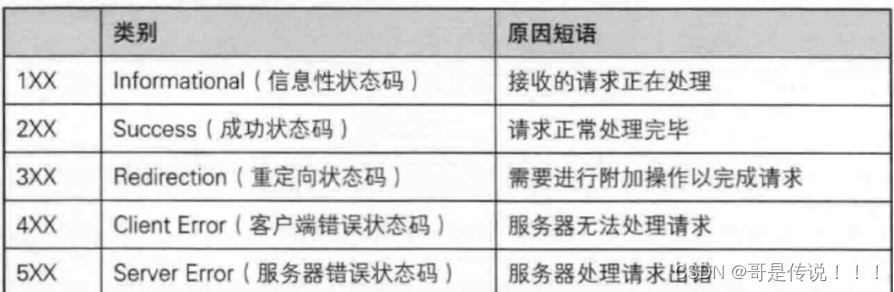
认识 "状态码 " (status code)
状态码表⽰访问⼀个⻚⾯的结果. (是访问成功, 还是失败, 还是其他的⼀些情况...
以下为常⻅的状态码
200 OK
这是⼀个最常⻅的状态码, 表⽰访问成功
404 Not Found
没有找到资源.
403 Forbidden
表⽰访问被拒绝. 有的⻚⾯通常需要⽤⼾具有⼀定的权限才能访问(登陆后才能访问). 如果⽤⼾没有登陆
直接访问, 就容易⻅到 403
405 Method Not Allowed
前⾯我们已经学习了 HTTP 中所⽀持的⽅法, 有 GET, POST, PUT, DELETE 等.
但是对⽅的服务器不⼀定都⽀持所有的⽅法(或者不允许⽤⼾使⽤⼀些其他的⽅法)
500 Internal Server Error
服务器出现内部错误. ⼀般是服务器的代码执⾏过程中遇到了⼀些特殊情况(服务器异常崩溃)会产⽣这
个状态码
504 Gateway Timeout
当服务器负载⽐较⼤的时候, 服务器处理单条请求的时候消耗的时间就会很⻓, 就可能会导致出现超时
的情况.
这种情况在双⼗⼀等 "秒杀" 场景中容易出现, 平时不太容易⻅到
临时重定向.
理解 "重定向"
就相当于⼿机号码中的 "呼叫转移" 功能. ⽐如我本来的⼿机号是 186-1234-5678, 后来换了个新号码
135-1234-5678, 那么不需要让我的朋友知 道新号码, 只要我去办理⼀个呼叫转移业务, 其他⼈拨打 186-1234-5678 ,就会⾃动转移到 135-1234-5678 上.
301 Moved Permanently
永久重定向. 当浏览器收到这种响应时, 后续的请求都会被⾃动改成新的地址.
301 也是通过 Location 字段来表⽰要重定向到的新地址
状态码小结
HTTPS
HTTPS 是什么
HTTPS 也是⼀个应⽤层协议. 是在 HTTP 协议的基础上引⼊了⼀个加密层.
HTTP 协议内容都是按照⽂本的⽅式明⽂传输的. 这就导致在传输过程中出现⼀些被篡改的情况.
臭名昭著的 "运营商劫持"
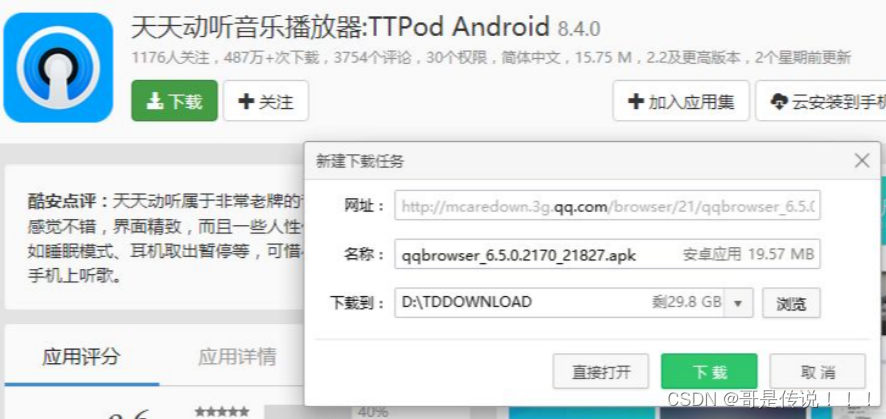
下载⼀个 天天动听
未被劫持的效果, 点击下载按钮, 就会弹出天天动听的下载链接
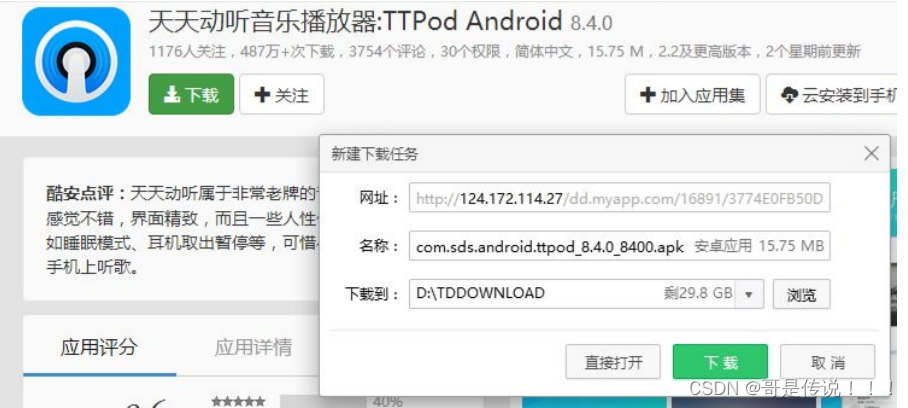
已被劫持的效果, 点击下载按钮, 就会弹出 QQ 浏览器的下载链接
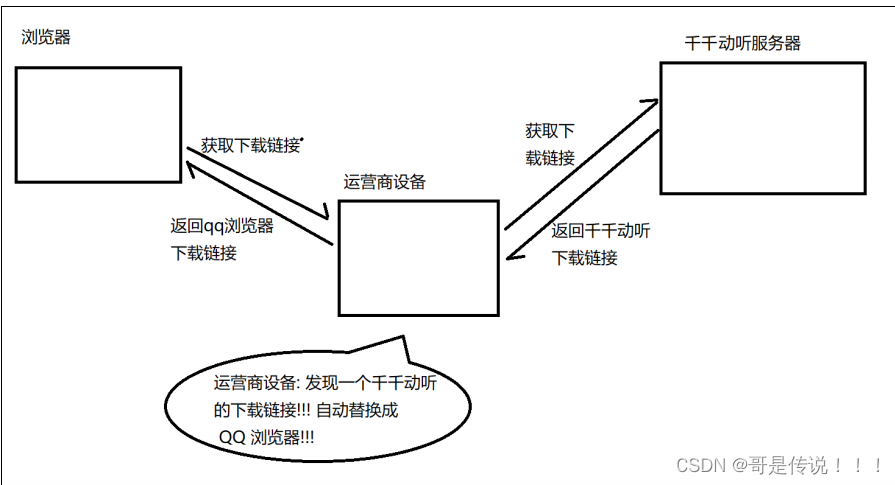
由于我们通过⽹络传输的任何的数据包都会经过运营商的⽹络设备(路由器, 交换机等), 那么运营商的⽹
络设备就可以解析出你传输的数据内容, 并进⾏篡改.
点击 "下载按钮", 其实就是在给服务器发送了⼀个 HTTP 请求, 获取到的 HTTP 响应其实就包含了该APP 的下载链接. 运营商劫持之后, 就发现这个请求是要下载天天动听, 那么就⾃动的把交给⽤⼾的响应给篡改成 "QQ浏览器" 的下载地址了
"加密" 是什么
加密就是把 明⽂ (要传输的信息)进⾏⼀系列变换, ⽣成 密⽂ .
解密就是把 密⽂ 再进⾏⼀系列变换, 还原成 明⽂ .
在这个加密和解密的过程中, 往往需要⼀个或者多个中间的数据, 辅助进⾏这个过程, 这样的数据称为 密
钥 (正确发⾳ yue 四声, 不过⼤家平时都读作 yao 四声)
HTTPS 的⼯作过程
既然要保证数据安全, 就需要进⾏ "加密".
⽹络传输中不再直接传输明⽂了, ⽽是加密之后的 "密⽂".
加密的⽅式有很多, 但是整体可以分成两⼤类: 对称加密 和 ⾮对称加密
引⼊对称加密
对称加密其实就是通过同⼀个 "密钥" , 把明⽂加密成密⽂, 并且也能把密⽂解密成明⽂.
⼀个简单的对称加密, 按位异或 假设 明⽂ a = 1234, 密钥 key = 8888 则加密 a ^ key 得到的密⽂ b 为 9834. 然后针对密⽂ 9834 再次进⾏运算 b ^ key, 得到的就是原来的明⽂ 1234. (对于字符串的对称加密也是同理, 每⼀个字符都可以表⽰成⼀个数字)
当然, 按位异或只是最简单的对称加密. HTTPS 中并不是使⽤按位异或.
引⼊对称加密之后, 即使数据被截获, 由于⿊客不知道密钥是啥, 因此就⽆法进⾏解密, 也就不知道请求 的真实内容是啥了.
但事情没这么简单. 服务器同⼀时刻其实是给很多客⼾端提供服务的. 这么多客⼾端, 每个⼈⽤的秘钥都
必须是不同的(如果是相同那密钥就太容易扩散了, ⿊客就也能拿到了). 因此服务器就需要维护每个客⼾
端和每个密钥之间的关联关系, 这也是个很⿇烦的事情~
⽐较理想的做法, 就是能在客⼾端和服务器建⽴连接的时候, 双⽅协商确定这次的密钥是啥
但是如果直接把密钥明⽂传输, 那么⿊客也就能获得密钥了~~ 此时后续的加密操作就形同虚设了.因此密钥的传输也必须加密传输!
但是要想对密钥进⾏对称加密, 就仍然需要先协商确定⼀个 "密钥的密钥". 这就成了 "先有鸡还是先有
蛋" 的问题了. 此时密钥的传输再⽤对称加密就⾏不通了.
就需要引⼊⾮对称加密.
引入非对称加密
⾮对称加密要⽤到两个密钥, ⼀个叫做 "公钥", ⼀个叫做 "私钥".
公钥和私钥是配对的. 最⼤的缺点就是运算速度⾮常慢,⽐对称加密要慢很多.
• 通过公钥对明⽂加密, 变成密⽂
• 通过私钥对密⽂解密, 变成明⽂
也可以反着⽤
• 通过私钥对明⽂加密, 变成密⽂
•通过公钥对密⽂解密, 变成明⽂
⾮对称加密的数学原理⽐较复杂, 涉及到⼀些 数论 相关的知识. 这⾥举⼀个简单的⽣活上的例⼦. A 要给 B ⼀些重要的⽂件, 但是 B可能不在. 于是 A 和 B 提前做出约定: B 说: 我桌⼦上有个盒⼦, 然后我给你⼀把锁, 你把⽂件放盒⼦⾥⽤锁锁上, 然后我回头拿着钥匙来开锁 取⽂件. 在这个场景中, 这把锁就相当于公钥, 钥匙就是私钥. 公钥给谁都⾏(不怕泄露), 但是私钥只有 B⾃⼰持有. 持有私钥的⼈才能解密
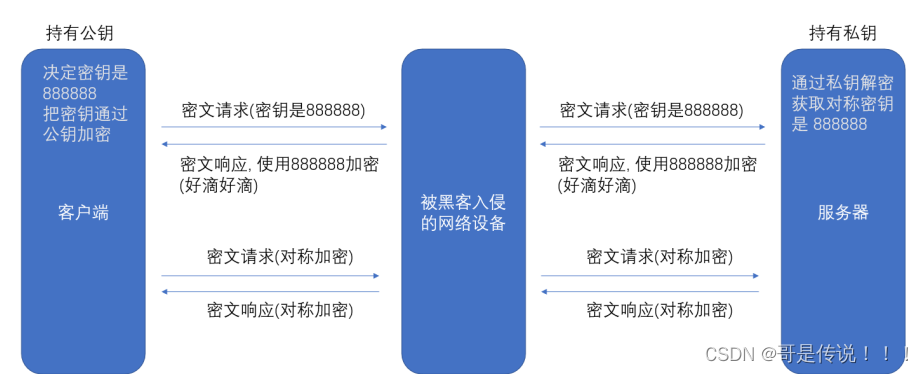
• 客⼾端在本地⽣成对称密钥, 通过公钥加密, 发送给服务器.
• 由于中间的⽹络设备没有私钥, 即使截获了数据, 也⽆法还原出内部的原⽂, 也就⽆法获取到对称密
钥
• 服务器通过私钥解密, 还原出客⼾端发送的对称密钥. 并且使⽤这个对称密钥加密给客⼾端返回的响
应数据.
• 后续客⼾端和服务器的通信都只⽤对称加密即可. 由于该密钥只有客⼾端和服务器两个主机知道, 其
他主机/设备不知道密钥即使截获数据也没有意义.
由于对称加密的效率⽐⾮对称加密⾼很多, 因此只是在开始阶段协商密钥的时候使⽤⾮对称加密, 后续
的传输仍然使⽤对称加密.
中间⼈攻击
⿊客可以使⽤中间⼈攻击, 获取到对称密钥.
- 服务器具有⾮对称加密算法的公钥S,私钥S'
- 中间⼈具有⾮对称加密算法的公钥M,私钥M'
- 客⼾端向服务器发起请求,服务器明⽂传送公钥S给客⼾端
- 中间⼈劫持数据报⽂,提取公钥S并保存好,然后将被劫持报⽂中的公钥S替换成为⾃⼰的公钥M, 并将伪造报⽂发给客⼾端
- 客⼾端收到报⽂,提取公钥M(⾃⼰当然不知道公钥被更换过了),⾃⼰形成对称秘钥X,⽤公钥M加 密X,形成报⽂发送给服务器
- 中间⼈劫持后,直接⽤⾃⼰的私钥M'进⾏解密,得到通信秘钥X,再⽤曾经保存的服务端公钥S加 密后,将报⽂推送给服务器
- 服务器拿到报⽂,⽤⾃⼰的私钥S'解密,得到通信秘钥X
- 双⽅开始采⽤X进⾏对称加密,进⾏通信。但是⼀切都在中间⼈的掌握中,劫持数据,进⾏窃听甚 ⾄修改,都是可以的
引⼊证书
服务端在使⽤HTTPS前,需要向CA机构申领⼀份数字证书,数字证书⾥含有证书申请者信息、公钥信息等。服务器把证书传输给浏览器,浏览器从证书⾥获取公钥就⾏了,证书就如⾝份证,证明服务端公钥的权威性
这个 证书 可以理解成是⼀个结构化的字符串, ⾥⾯包含了以下信息:
• 证书发布机构 • 证书有效期 • 公钥 • 证书所有者 • 签名
需要注意的是:申请证书的时候,需要在特定平台⽣成查,会同时⽣成⼀对⼉密钥对⼉,即公钥和私
钥。这对密钥对⼉就是⽤来在⽹络通信中进⾏明⽂加密以及数字签名的。
当服务端申请CA证书的时候,CA机构会对该服务端进⾏审核,并专⻔为该⽹站形成数字签名,过程如
下:
- CA机构拥有⾮对称加密的私钥A和公钥A'
- CA机构对服务端申请的证书明⽂数据进⾏hash,形成数据摘要
- 然后对数据摘要⽤CA私钥A'加密,得到数字签名S
服务端申请的证书明⽂和数字签名S 共同组成了数字证书,这样⼀份数字证书就可以颁发给服务端了