【OpenClaw 本地实战 Ep.1】抛弃 Ollama?转向 LM Studio!Windows 下用 NVIDIA 显卡搭建 OpenClaw 本地极速推理服务
【OpenClaw 本地实战 Ep.2】零代码对接:使用交互式向导快速连接本地 LM Studio 用 CUDA GPU 推理
【OpenClaw 本地实战 Ep.3】突破瓶颈:强制修改 openclaw.json 解锁 32k 上下文记忆
摘要:
OpenClaw 本地化部署第三弹。连接成功后,为什么 AI 写代码总是报错 Context window too small?这是因为 OpenClaw 默认将本地模型识别为 4k 短记忆。本文教你利用 openclaw.json 的 merge 模式 ,强制覆盖系统检测,解锁 32k 甚至更长的上下文窗口,让你的 Agent 真正拥有过目不忘的能力。
标签:
OpenClaw ContextWindow 上下文超限 参数调优 JSON配置 Debug
写在前面:连接成功后的"当头一棒"
在 Ep.2 零代码对接 中,我们通过向导成功让 OpenClaw 连上了本地的 LM Studio。你可能已经试着和它聊了几句"你好",反应很快,感觉一切都很完美。
但是,当你试图给它派发一个真正的 Agent 任务(比如:"读取 src 目录下的所有代码并写一个 README.md")时,它可能会思考一秒钟,然后狠狠地甩给你一行红色的报错:
❌ Error: Embedded agent failed before reply: Model context window too small (4096 tokens). Minimum is 16000.发生了什么?
明明我的 RTX 3090 有 24G 显存,明明我在 LM Studio 里加载的是支持 32k 甚至 128k 的模型,为什么 OpenClaw 说我只有 4096?
这就是我们今天要解决的**"记忆封印"**问题。
一、 原理分析:被误解的本地模型
OpenClaw 在启动时,会通过 API 询问 LM Studio:"你现在跑的是什么模型?"
LM Studio 会老实回答:"是 openai/gpt-oss-20b。"
但问题在于,OpenClaw 的内部数据库里并没有这个本地模型的详细参数。出于安全和稳定性的考虑,对于所有"不认识"的模型,OpenClaw 会默认将其上下文限制在 4096 token。
这就像你买了一辆法拉利(32k 模型),但系统以为它是老头乐(4k),于是给你的油门加了把锁,死活不让你开快。
我们需要修改配置文件,告诉 OpenClaw:"别猜了,听我的,这辆车能跑 32000!"
二、 核心操作:强制覆写模型参数
我们要修改的核心文件依然是 openclaw.json。
1. 打开配置文件
根据你的运行环境找到文件(通常在 ~/.openclaw/openclaw.json 或 ~/.openclaw-dev/openclaw.json)。
2. 植入"解除封印"代码
我们需要用到 OpenClaw 配置系统的一个高级特性:mode: "merge"。这允许我们手动定义的参数覆盖掉系统自动扫描的结果。
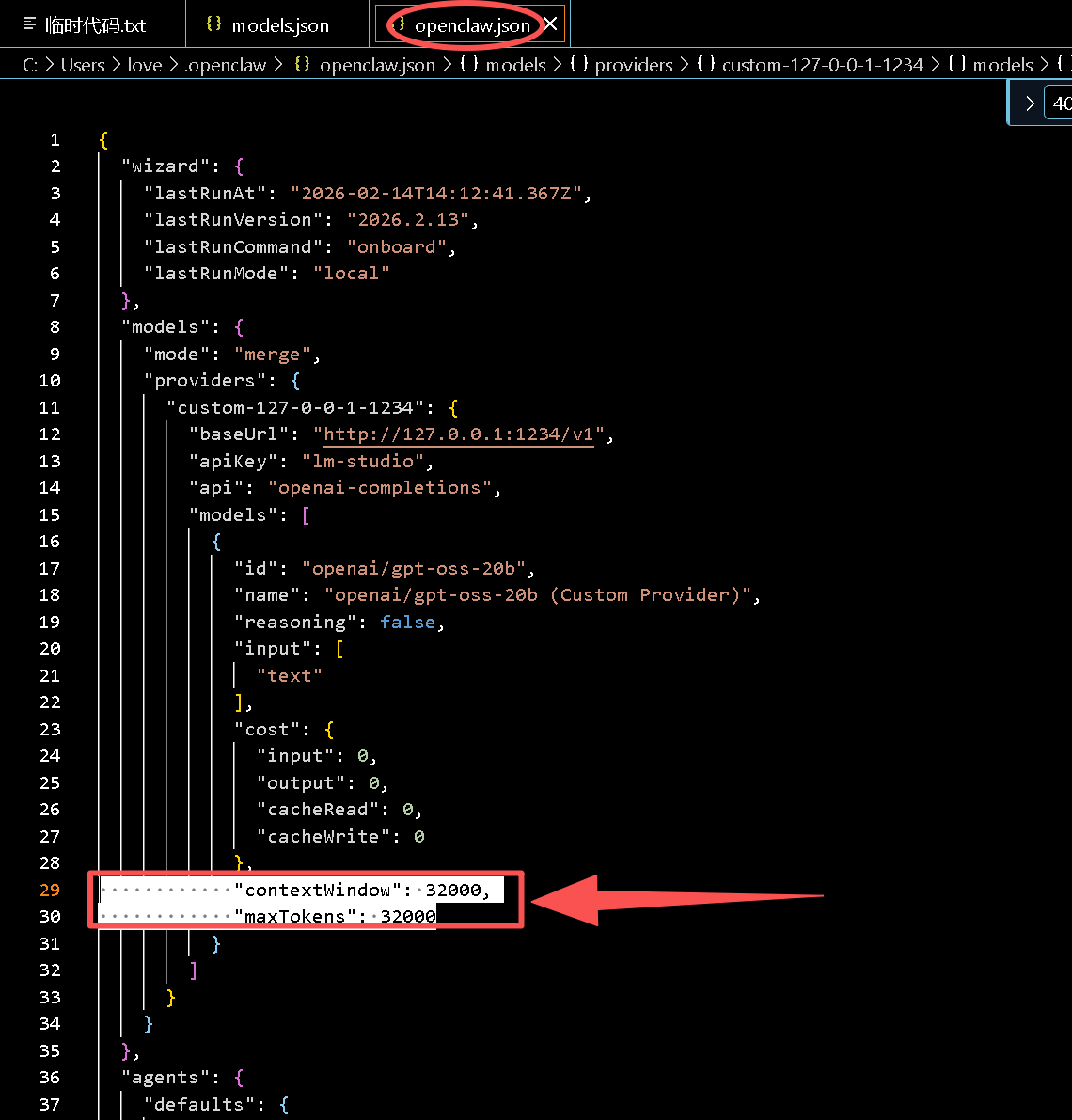
请找到 models 字段,将其修改为如下结构(请仔细核对 contextWindow 和 maxTokens):
{
"models": {
"mode": "merge", // <--- 关键:告诉系统以我的配置为准进行合并
"providers": {
"custom-127-0-0-1-1234": {
"baseUrl": "http://127.0.0.1:1234/v1",
"apiKey": "lm-studio",
"api": "openai-completions",
"models": [
{
"id": "openai/gpt-oss-20b", // 必须与 LM Studio 加载的模型 ID 完全一致
"name": "Local RTX 3090 Power",
"reasoning": false,
"input": [ "text" ],
"cost": {
"input": 0, "output": 0, "cacheRead": 0, "cacheWrite": 0
},
// 👇 核心修改在这里 👇
"contextWindow": 32000,
"maxTokens": 32000
}
]
}
}
},
// ... 其他配置保持不变
}
3. 为什么之前修改 models.json 没用?
细心的朋友可能发现 OpenClaw 目录下有个 models.json 文件。
千万不要改那个文件! 那是系统的"临时缓存"。每次重启网关,OpenClaw 都会重新扫描并覆盖它,把你改的 32000 变回 4096。只有修改 openclaw.json 才是永久生效的。
三、 双端对齐:别忘了 LM Studio
光改 OpenClaw 还不够,作为服务端的 LM Studio 也必须真的开启这么大的窗口,否则会爆显存或报错。
-
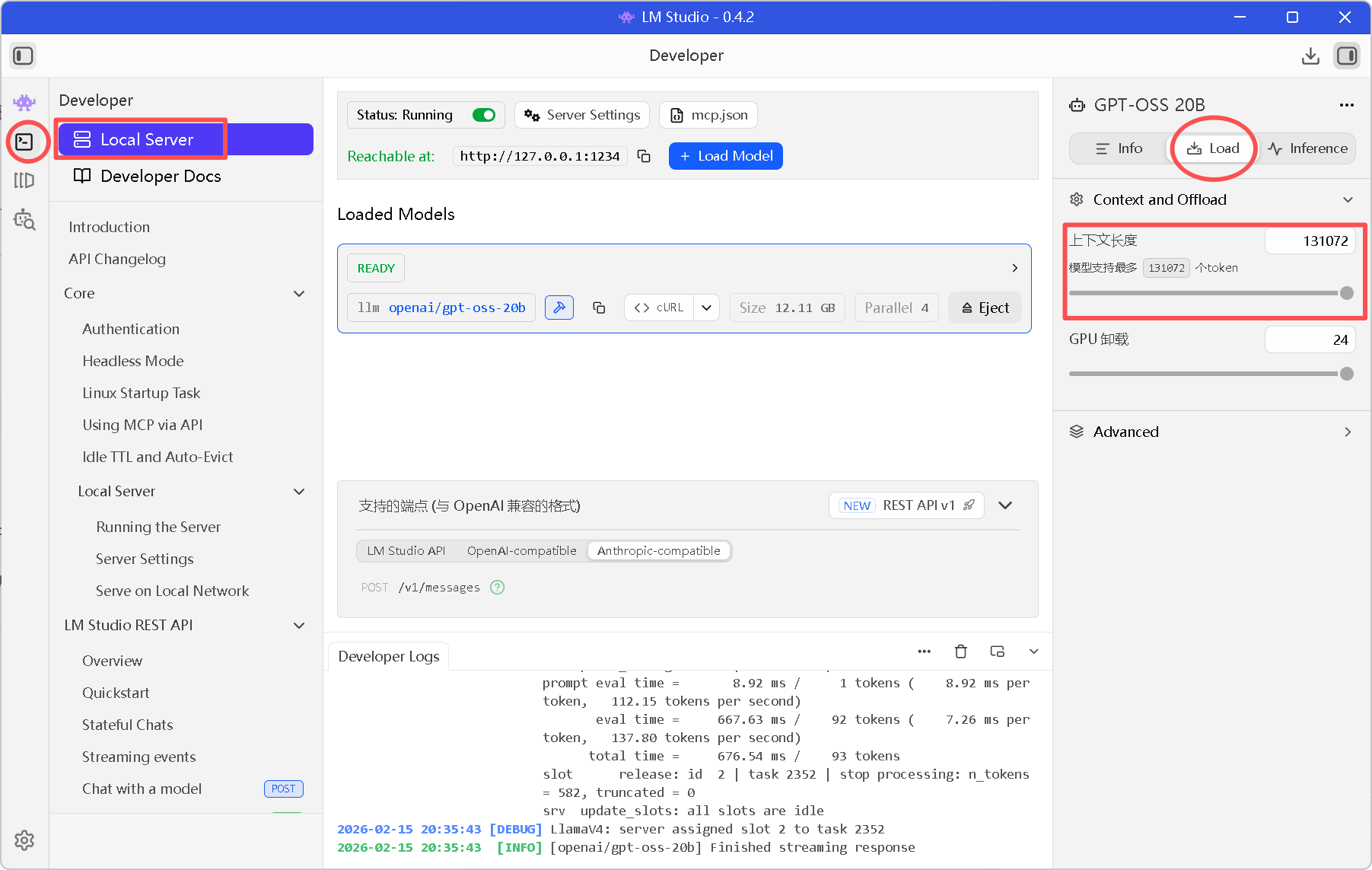
回到 LM Studio。
-
在右侧侧边栏找到 Context Length(通常在 Model Options 里)。
-
确保滑块拉到了 模型支持的最高值 。
- 注意:RTX 3090 跑 20B 模型开 32k 上下文大约需要 18-20G 显存,请量力而行。
四、 验证:见证"过目不忘"
保存配置,重启 OpenClaw 网关:
pnpm openclaw gateway验证方法:
在聊天框里扔给它一篇超长的文章,或者让它分析整个项目的代码结构。
如果没有报错,并且能在日志里看到 Agent 正在从容地处理大量 Token,恭喜你,封印已解除!
五、 下一步计划
现在的系统已经非常强悍了:
✅ 算力:RTX 3090 满血输出
✅ 连接:本地服务自动对接
✅ 记忆:32k 长文本无压力
但在高频调试的过程中,你肯定发现了一个烦人的问题:每次重启 OpenClaw,它都会生成一个新的 Token 。如果你在浏览器里按了刷新,或者换了个浏览器,就会立刻弹出一个红色报错:unauthorized: device token mismatch。
每次都要去终端复制那一长串字符太反人类了。
下一篇预告:
👉 《【OpenClaw 本地实战 Ep.4】终极提效:一劳永逸解决 Token 鉴权失败问题》
-
当前 Token 是动态生成的,每次重启网关都会变化
-
无法方便地在多个浏览器/设备间切换
-
需要每次手动获取 Token 并组装 URL
我将分享一个最简单的配置技巧,把 Token 固定下来,实现"万能钥匙"登录。
相关阅读:
还没有配置好 OpenClaw?请回顾:零代码对接 LM Studio
你的显卡在摸鱼?请回顾:LM Studio 显卡加速配置