随着数据处理需求的日益增长,选择一个高效、灵活的数据处理工具变得尤为关键。SeaTunnel,作为一个开源的数据集成工具,不仅支持多种数据处理引擎,还提供了丰富的连接器和灵活的数据同步方案。
本文将详细介绍 SeaTunnel 的优势和部署流程,帮助开发者和数据科学家快速上手,提升数据处理的效率和灵活性。
一、SeaTunnel优势
1、丰富且可扩展的连接器
2、连接器插件
3、流批集成,支持实时数据同步也支持离线数据同步
4、JDBC多路复用
5、多引擎支持。 支持SeaTunnel原生引擎、Spark引擎、Flink引擎。
6、高吞吐量和低延迟
7、完善的实时监控
8、支持两种作业开发方法:编码和画布设计。
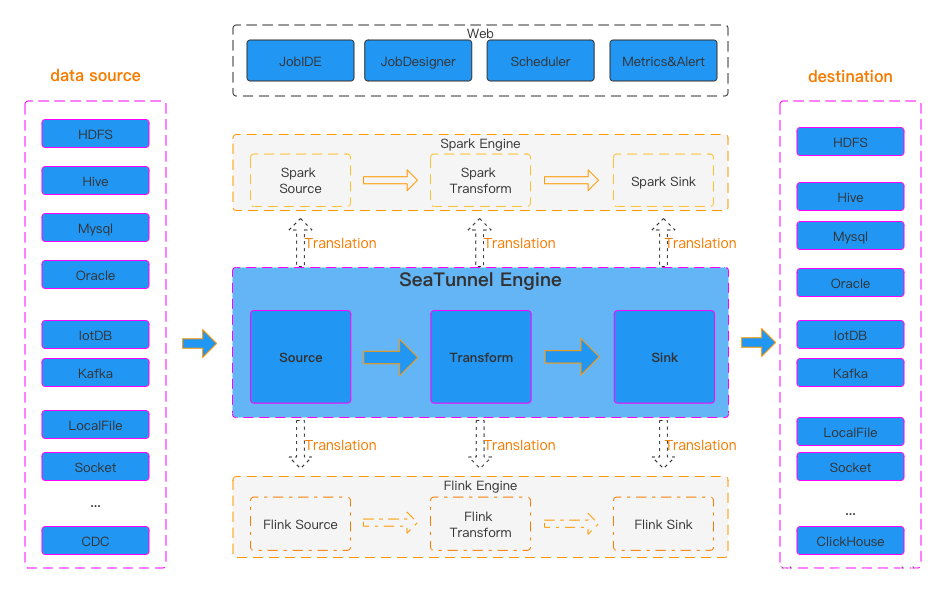
二、SeaTunnel部署:
export version="2.3.5"
wget "https://archive.apache.org/dist/seatunnel/${version}/apache-seatunnel-${version}-bin.tar.gz"
tar -xzvf "apache-seatunnel-${version}-bin.tar.gz"安装插件
sh bin/install-plugin.sh部署后的目录结构:

三、对接Spark引擎
修改config目录的seatunnel-env.sh文件的SPARK_HOME配置,指向Spark的Home目录。

四、配置SeaTunnel任务
创建 config/v2.mysql.config 任务配置文件。
读取127.0.0.1数据库的lhotsetest.lb\_task\_run表,并通过控制台输出。
env {
parallelism = 1
job.mode = "BATCH"
}
source {
Jdbc {
url = "jdbc:mysql://127.0.0.1:3306/lhotsetest?serverTimezone=GMT%2b8"
driver = "com.mysql.cj.jdbc.Driver"
connection_check_timeout_sec = 100
user = ""
password = ""
table_path = "lhotsetest.lb_task_run"
query = "select * from lhotsetest.lb_task_run"
split.size = 10000
}
}
sink {
Console {}
}五、SeaTunnel集成CDP,基于Yarn进行任务资源管理:
通过Spark On Yarn的方式进行提交。
(1)进行keytab认证 --keytab /dir1/dir2/user.keytab --principal user@COM
(2)通过yarn集群模式进行提交 --master yarn --deploy-mode cluster
(3)指定任务配置文件 --config ./config/v2.mysql.config
./bin/start-seatunnel-spark-2-connector-v2.sh --keytab /dir1/dir2/user.keytab --principal user@COM --master yarn --deploy-mode cluster --config ./config/v2.mysql.config提交后任务在大数据平台可以看到任务的状态:

任务执行完毕后,可查询任务执行详情和日志:


通过本文的介绍,相信您已对 SeaTunnel 有了深入的了解。从优化的连接器到强大的引擎支持,SeaTunnel 为数据处理提供了广泛而高效的解决方案。
无论您是在寻找实时数据同步工具,还是需要一个可靠的数据集成平台,SeaTunnel 都能满足您的需求。现在就开始您的 SeaTunnel 之旅,解锁数据处理的新可能!
本文由 白鲸开源科技 提供发布支持!