引言
在大数据时代,数据集成作为企业数据流转的核心枢纽,承担着异构数据源之间高效同步的重要职责。随着数据量的爆炸式增长,传统的行存同步方式在面对大规模列存数据处理时,逐渐显露出性能瓶颈。
为解决这一挑战,DataWorks数据集成推出基于Apache Arrow列存格式的高性能同步能力,实现从"行式传输"到"列式直通"的技术跃迁。通过引入零拷贝、列式内存标准Apache Arrow,DataWorks实现了跨数据源的列存到列存高效同步,性能提升最高达10倍以上,助力企业实现数据流转的"高速通道"。
技术创新:基于Arrow的列存同步方案
Apache Arrow:下一代数据处理的"通用语言"
Apache Arrow是一项由Apache基金会主导的跨语言、高性能列式内存数据标准,被广泛应用于大数据生态(如Spark、Flink、Presto等)。核心优势在于:
-
零序列化/反序列化:数据以内存二进制块直接传输,避免格式转换开销
-
零拷贝(Zero-Copy):跨进程/跨系统共享内存,极大降低CPU与内存消耗
-
CPU缓存友好:列式存储提升缓存命中率,优化计算效率
-
统一类型系统:支持复杂嵌套结构,保障跨平台类型兼容性
简单来说:Arrow让数据"原样流动",不再"反复翻译"。
传统架构 vs Arrow架构:从"搬砖"到"高速专列"
当前大多数数据集成工具仍基于"行存驱动"设计:
-
Reader读取列存文件 → 解码成单行Record对象;
-
框架传递Record → Writer再将其编码回目标列存格式。
这一过程存在严重性能浪费:
-
多次类型转换与对象创建(如String → BigDecimal)
-
高频GC压力导致频繁Stop-The-World
-
内存带宽利用率低下
而Arrow则彻底改变了这一流程:Reader直接输出列式Batch → Writer直接消费列式Batch,中间无需任何转换,真正实现"端到端列式流水线"。
传统行存同步架构:
面向单行行存的格式设计,每一个Record对象定义了若干个Column,每个Column包含当前行对应该列的列值Value。以MaxCompute(ODPS)列存数据同步到MaxCompute(ODPS)列存为例: 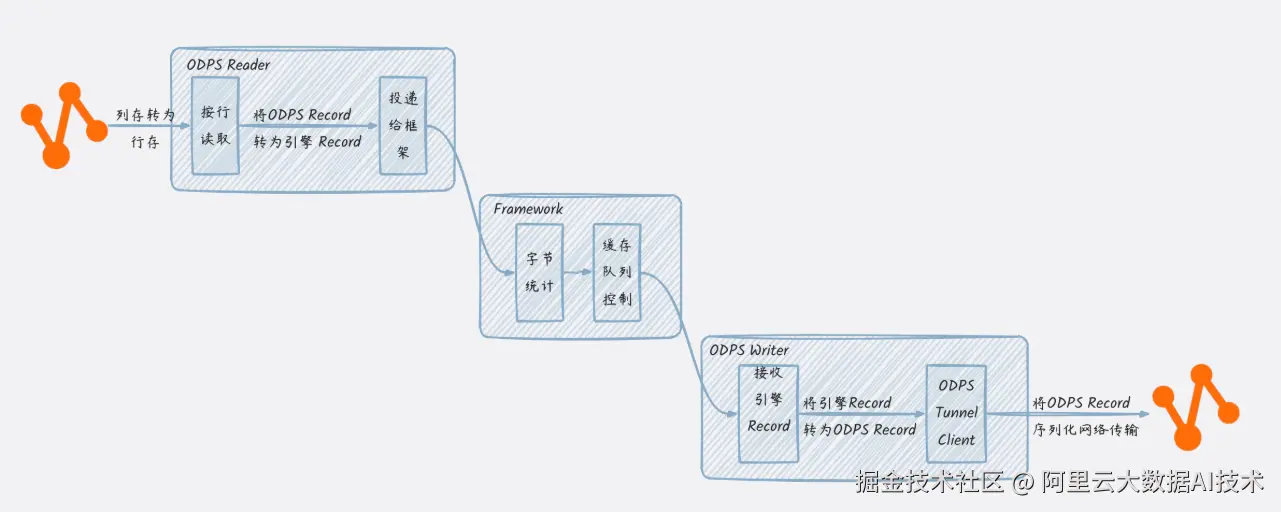
MaxCompute表数据可能以ORC、Parquet等列存格式存储的数据,同步核心流程分为:
- 通过MaxCompute Tunnel将数据按行读取出来,并转为MaxCompute Record对象;
- MaxCompute Reader将MaxCompute Record转换为同步引擎的Record对象,投递给框架;
- 框架收到Record放入缓存队列;
- Writer从框架接收引擎Record,再转换为MaxCompute Record,并通过Tunnel client将数据进行序列化后通过网络传输给Tunnel server。
数据集成Arrow列存同步架构:
当列存到列存同步场景下,将列存先转为行存格式,再将行存格式转为列存格式,中间多了不必要的转换及序列化操作。通过构建全新的 ArrowTabularRecord 数据结构,DataWorks实现了对Arrow列式数据的原生支持,跳过行式转换环节,实现端到端列存"短路同步",大幅提升吞吐、降低延迟。 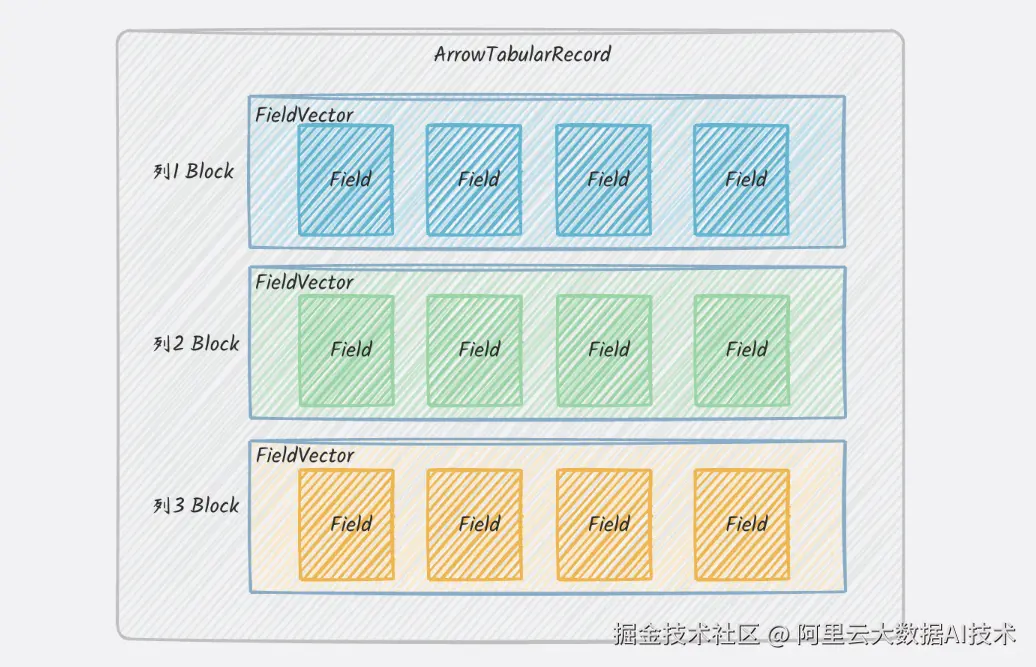
同步引擎基于新的面向Arrow列存格式的ArrowTabularRecord,列存到列存数据流转如下: 
同步核心流程如下:
-
通过MaxCompute Tunnel Arrow API将数据直接按照Arrow列存格式读取出来,并存入ArrowTabularRecord,投递给框架;
-
框架收到Record放入缓存队列;
-
Writer从框架收到引擎ArrowTabularRecord,直接通过Tunnel Arrow API将数据基于Arrow格式,省去做序列化的开销,直接将内存二进制数据传输给Tunnel Server。
核心能力:全链路列式加速,支持主流数据源
DataWorks数据集成现已全面支持 MaxCompute、Hologres、Hive/OSS/HDFS(Parquet/ORC) 等主流列存数据源的Arrow读写能力,用户仅需在任务配置中添加 "useArrow": true 即可一键启用。
列存直读直写,显著提升性能
| 数据源 | 支持能力 | 同步性能提升 |
|---|---|---|
| MaxCompute | 通过Tunnel Arrow API直读列存数据 | 同步性能提升 200% |
| Hologres | 支持Arrow格式导出,避免JDBC行式瓶颈 | 同步性能提升 95% |
| Hive\OSS\HDFS等分布式文件 | 直接读取Parquet/ORC底层Arrow格式数据 | PARQUET同步性能提升5.55倍 ORC同步性能提升 9.85倍 |
示例:Hive ORC → MaxCompute 写入,原需数小时的任务,现可在数十分钟内完成。
性能压测报告
我们对多个典型场景进行了端到端性能测试,同步性能显著提升,可实现从小时级到分钟级的数据同步周期提升:
场景一:MaxCompute列存短路同步(Arrow → Arrow)
| 并发数 | 传统行存 | Arrow列存 | 性能提升 |
|---|---|---|---|
| 1 | 67.8 MB/s 3740 R/s | 212.6 MB/s 11462 R/s | +206.5% |
| 3 | 185.6 MB/s 10226 R/s | 569.9 MB/s 30728 R/s | +200.5% |
| 8 | 462.1 MB/s 25467 R/s | 1321.0 MB/s 71143 R/s | +197.4% |
场景二:Hologres → MaxCompute 同步
| 并发数 | 传统同步 | Arrow同步 | 性能提升 |
|---|---|---|---|
| 4 | 439.1 MB/s 216480 R/s | 906.1 MB/s 404270 R/s | +87% |
| 8 | 773.3 MB/s 381300 R/s | 1669.1 MB/s 745654 R/s | +95% |
场景三:Parquet/ORC → MaxCompute 同步
| 并发数 | 传统同步 | Arrow同步 | 性能提升 |
|---|---|---|---|
| Parquet | 26.1 MB/s 35631 R/s | 1198.1 MB/s 233587 R/s | 5.55倍 |
| ORC | 21.4 MB/s 27661 R/s | 3256.3 MB/s 300326 R/s | 9.85倍 |
备注:Parquet、ORC文件可以在HDFS、OSS等分布式文件系统中
核心优势:不止于快,更稳、更低成本
| 特性 | 价值说明 |
|---|---|
| 高性能 | 吞吐量提升最高达10倍,适合宽表、大数据量搬站同步 |
| 低资源消耗 | 零拷贝 + 内存复用,降低GC压力,节省计算成本 |
| 高兼容性 | 支持MaxCompute、Hologres、Hive等主流列存系统 |
| 易用性 | 仅需配置useArrow: true,无需代码改造 |
典型应用场景:释放数据流转的无限可能
场景一:大数据搬站迁移
痛点 :从Hive向MaxCompute迁移数百TB数据,耗时较久,影响业务上线 方案 :启用Arrow同步,列存直传,避免格式转换 成果 :迁移时间从小时级同步缩短至分钟级 ,效率提升10倍以上
场景二:异构数据源融合与湖仓一体化
支持Hive(湖)与Hologres/MaxCompute(仓)之间的列存高效互通,为数据湖仓一体架构提供核心数据流转引擎,实现"一数多用、湖仓协同"。
如何使用?一步开启Arrow加速
整库解决方案
数据集成已经发布Hive->MaxCompute整库同步功能,默认会自动根据同步字段类型,渲染开启Arrow高性能同步能力。 
💡 无需代码改造,无需理解底层细节,一键开启高性能同步。
单表离线同步
DataWorks数据集成单表离线任务,在reader和writer parameter下添加 useArrow: true 参数,即可开启列式加速(由于是列存格式直读直写,开启前提是需要保证源端和目标端列类型保持一致):
json
{
"type": "job",
"steps": [
{
"stepType": "hive",
"parameter": {
"useArrow": true,
"datasource": "my_datasource",
"column": [
"col1",
"col2"
],
"readMode": "hdfs",
"table": "table"
},
"name": "Reader",
"category": "reader"
},
{
"stepType": "odps",
"parameter": {
"useArrow": true,
"truncate": false,
"datasource": "odps_test",
"column": [
"col1",
"col2"
],
"table": "table"
},
"name": "Writer",
"category": "writer"
}
],
"setting": {
"speed": {
"concurrent": 3
}
}
}未来演进:构建更强大的数据同步生态
DataWorks将持续深化Arrow能力,打造企业级高性能数据流转平台:
-
更多数据源支持:扩展至HDFS、Paimon、ClickHouse、Iceberg等;
-
智能调度优化:根据数据特征自动选择Arrow或行式模式;
-
生态融合:为DataWorks数据搬站,提供端到端数据解决方案
结语:让数据真正高性能"跑"起来
DataWorks数据集成引入Apache Arrow列存同步能力,列式、零拷贝、内存级传输为同步性能带来显著提升。DataWorks数据集成正以技术创新为引擎,帮助企业打破数据孤岛、消除性能瓶颈,让数据在湖仓之间、系统之间、业务之间高速、稳定、低成本流动。