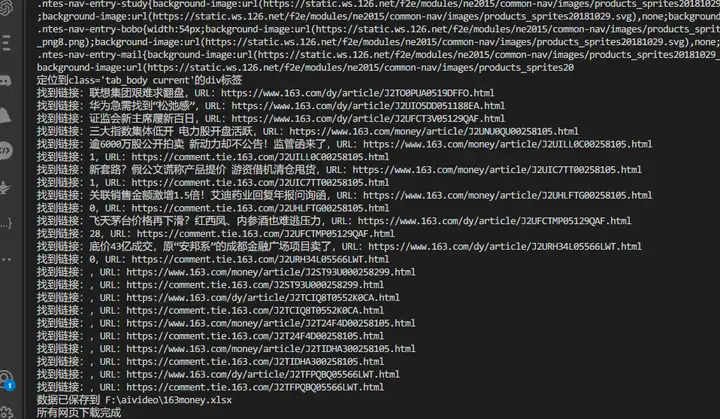
工作任务和目标:批量爬取网易财经的要闻板块

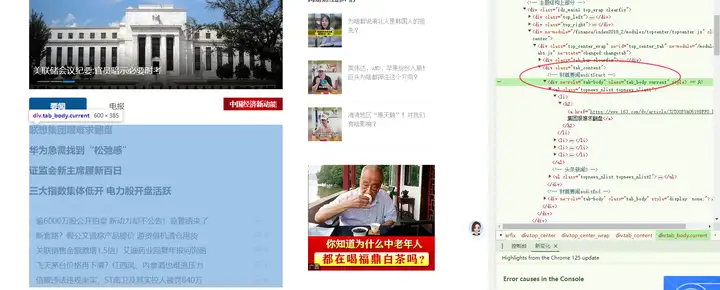
在class="tab_body current"的div标签中;
标题和链接在:<a href="https://www.163.com/dy/article/J2UIO5DD051188EA.html">华为急需找到"松弛感"</a>
第一步,在kimi中输入如下提示词:
你是一个Python爬虫专家,完成以下网页爬取的Python脚本任务:
在F:\aivideo文件夹里面新建一个Excel文件:163money.xlsx
设置chromedriver的路径为:"D:\Program Files\chromedriver125\chromedriver.exe"
用selenium打开网页:https://money.163.com/;
请求标头:
:authority:
:method:
GET
:path:
/
:scheme:
https
Accept:
text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7
Accept-Encoding:
gzip, deflate, br, zstd
Accept-Language:
zh-CN,zh;q=0.9,en;q=0.8
Cache-Control:
max-age=0
Cookie:
__root_domain_v=.163.com; _qddaz=QD.484716194472545; _ntes_origin_from=sogou; _ntes_nuid=af525edefbd3d363cd5876dbe902d85b; s_n_f_l_n3=01cb466d244b7db51716517702302; _antanalysis_s_id=1716517702995; UserProvince=%u5168%u56FD; ne_analysis_trace_id=1716518441938; vinfo_n_f_l_n3=01cb466d244b7db5.1.0.1716517702302.0.1716518672850
If-Modified-Since:
Fri, 24 May 2024 02:40:05 GMT
Priority:
u=0, i
Referer:
https://www.sogou.com/link?url=hedJjaC291M4oaTBlXc5yCiioa5eDVgw
Sec-Ch-Ua:
"Google Chrome";v="125", "Chromium";v="125", "Not.A/Brand";v="24"
Sec-Ch-Ua-Mobile:
?0
Sec-Ch-Ua-Platform:
"Windows"
Sec-Fetch-Dest:
document
Sec-Fetch-Mode:
navigate
Sec-Fetch-Site:
cross-site
Sec-Fetch-User:
?1
Upgrade-Insecure-Requests:
1
User-Agent:
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36
解析源代码,并打印输出;
定位class="tab_body current"的div标签;
在div标签中定位所有的a标签,提取a标签的href作为网页下载URL,保存到163money.xlsx的第2列;
提取a标签的文本内容作为网页文件名,保存到163money.xlsx的第1列;
注意:
每一步都要输出相关信息到屏幕;
每解析一个网页随机暂停1-10秒;
设置请求头,来应对反爬虫机制;

第二步,查看审阅Kimi生成的Python代码:
import pandas as pd
import time
import random
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.by import By
from selenium.common.exceptions import StaleElementReferenceException
设置chromedriver的路径
service = Service(executable_path=r"D:\Program Files\chromedriver125\chromedriver.exe")
使用selenium的ChromeDriverManager来自动管理chromedriver
driver = webdriver.Chrome(service=service)
打开网页
url = "https://money.163.com/"
driver.get(url)
打印网页源代码
print("网页源代码:")
print(driver.page_source)
定位class="tab_body current"的div标签
try:
tab_body = driver.find_element(By.CLASS_NAME, "tab_body.current")
print("定位到class='tab_body current'的div标签")
except Exception as e:
print("定位class='tab_body current'的div标签时出错:", e)
driver.quit()
定位所有的a标签并提取信息
a_tags = tab_body.find_elements(By.TAG_NAME, "a")
urls = \[\]
titles = \[\]
for a in a_tags:
try:
title = a.text
href = a.get_attribute('href')
urls.append(href)
titles.append(title)
print(f"找到链接:{title},URL:{href}")
except StaleElementReferenceException:
print("元素引用已失效,尝试刷新页面后重新获取")
driver.refresh()
time.sleep(3) # 等待页面刷新
保存到Excel文件
excel_path = r"F:\aivideo\163money.xlsx"
df = pd.DataFrame({
'网页文件名': titles,
'网页下载URL': urls
})
使用pandas的ExcelWriter保存到Excel文件
with pd.ExcelWriter(excel_path, engine='openpyxl') as writer:
df.to_excel(writer, index=False)
print(f"数据已保存到 {excel_path}")
每解析一个网页随机暂停1-10秒
time.sleep(random.randint(1, 10))
关闭浏览器
driver.quit()
print("所有网页下载完成")
第三步,打开visual studio code软件,新建一个py文件,将Python代码复制到这个文件中,按下F5键运行程序:
程序运行结果: