1.概述

艺术、交流以及我们对现实世界的认知正在迅速地转变。如果我们回顾人类创新的历史,我们可能会认为轮子的发明或电的发现是巨大的飞跃。今天,一场新的革命正在发生------弥合人类创造力和机器计算之间的鸿沟。这正是生成式人工智能。
生成模型正在模糊人类和机器之间的界限。随着采用Transformer模块的GPT-4等模型的出现,我们离自然且上下文丰富的语言生成又近了一步。这些进步推动了文档创建、聊天机器人对话系统,甚至合成音乐创作中的应用。
最近大型科技公司的决策凸显了其重要性。微软已经停止使用Cortana应用程序,本月优先考虑较新的生成式人工智能创新,例如Bing Chat。苹果还投入了很大一部分资金,22.6亿美元的研发预算,正如首席执行官蒂姆·库克所指出的,用于生成式人工智能。
这段话概述了生成式人工智能在艺术、交流和现实感知方面所带来的变革,以及它在文档创建、聊天机器人对话系统和音乐创作中的应用。同时,也提到了微软和苹果等大型科技公司在这一领域的投资和决策,显示了生成式人工智能在当前技术发展中的重要性。
2. 生成模型
生成式人工智能(Generative AI)的故事确实不仅限于它的应用,还深刻地涉及其内部运作机制。在人工智能领域,判别模型和生成模型是两种基本的模型类型,它们各自扮演着不同的角色。
判别模型(Discriminative Models) :
判别模型的主要任务是区分不同的类别或做出决策。它们通过学习输入数据的特征和模式,然后根据这些特征来预测或分类新的数据点。在日常生活中,我们遇到的许多机器学习算法都属于判别模型,例如:
- 图像识别:识别图像中的对象。
- 语音识别:将语音转换为文本。
- 垃圾邮件过滤:判断电子邮件是否为垃圾邮件。
- 医学诊断:根据症状和测试结果预测疾病。
判别模型通常用于分类、回归、异常检测等任务。
生成模型(Generative Models) :
与判别模型不同,生成模型的目标是生成新的数据实例,这些数据与训练数据具有相似的分布。它们不仅仅是解释或预测已有的数据,而是能够创造出全新的内容。生成模型的例子包括:
- 图像生成:生成看起来真实的新图像。
- 文本生成:创作诗歌、故事或对话。
- 音乐合成:创作新的音乐作品。
- 数据增强:在训练机器学习模型时生成额外的训练数据。
生成模型通常基于概率分布来生成数据,这意味着它们可以生成与训练数据分布相似的新实例,但具体内容是全新的。
3. 生成模型背后的技术
生成模型之所以能够存在并发展,确实在很大程度上归功于深度神经网络技术的进步。深度神经网络(DNNs)是由多层人工神经元组成的网络,它们能够学习数据中的复杂模式和表示,这使得它们非常适合于生成任务。
这些生成模型是如何实现的?以下是一些关键点:
(1). 深度神经网络:生成模型通常使用深度神经网络来学习数据的高维表示。这些网络能够自动提取特征,而不需要手动设计特征提取器。
(2). 优化:通过训练过程,网络的权重会被优化,以便能够生成与训练数据相似的新数据实例。
(3). 生成对抗网络(GAN):GAN由两个关键部分组成,生成器(Generator)和判别器(Discriminator)。生成器的目标是产生逼真的数据,而判别器的目标是区分真实数据和生成器产生的假数据。这两部分在训练过程中相互竞争,推动彼此的性能提升。
(4). 变分自动编码器(VAE):VAE是另一种生成模型,它通过编码器将输入数据映射到一个潜在空间的分布上,然后通过解码器从这个分布中采样来生成新的数据。VAE的关键特性是它能够生成连续的数据点,并且可以控制生成过程的随机性。
(5). 应用领域:生成模型的应用非常广泛,包括艺术创作(如绘画和风格转移)、音乐合成、游戏玩法设计等。它们能够创造出新颖的内容,推动创意产业的发展。
(6). 创造性和想象力:生成模型不仅仅是复制现有数据,它们还能够创造出全新的、以前从未存在过的数据实例,这在艺术和设计等领域尤其有价值。
4. 生成式 AI 类型:文本到文本、文本到图像
4.1 Transformer和LLM
论文《Attention Is All You Need》由 Google Brain 团队撰写,代表了对文本建模方式的一次重大革新。该论文提出的 Transformer 模型放弃了传统的循环神经网络(RNN)和卷积神经网络(CNN)等依赖序列展开的复杂结构,转而采用了注意力机制这一创新概念。这种机制的核心在于,它能够根据上下文动态地关注输入文本的不同部分。
通过这种方式,Transformer 模型的主要优势之一是其易于并行化的能力。这与传统的 RNN 形成鲜明对比,后者由于其内在的序列处理特性,在扩展性上存在限制,特别是在处理大型数据集时。相比之下,Transformer 能够同时处理整个序列的多个部分,极大地加速了训练过程,使得在大规模数据集上的训练变得更加迅速和高效。这一突破性的设计,为自然语言处理领域带来了新的可能性,并为未来的研究和应用奠定了基础。
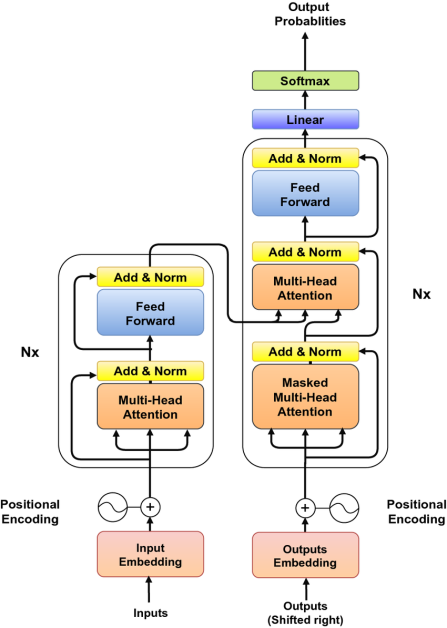
在长文本处理中,不是每个单词或句子都同等重要。注意力机制正是为了解决这一问题而设计的,它模仿人类理解语言时的注意力分配,即根据上下文的重要性来调整对不同部分的关注。
以下面句子为例:"联合人工智能发布人工智能和机器人新闻。" 在这个句子中,不同词语承载着不同的信息量和指向性。当使用注意力机制来预测下一个单词时,模型会分析上下文并识别关键词汇,从而决定哪些部分更值得关注。
- "机器人"(robots)这个术语可能会吸引注意力,因为这是一个特定领域(人工智能的一个分支)的关键词。在预测下一个单词时,模型可能会考虑与机器人技术、应用或最新发展相关的词汇。
- "发布"(publishing)这个动作则可能表明接下来的内容与新闻报道、研究成果的发布或信息的传播有关。因此,模型可能会预测与文章、期刊、发现或公告相关的词汇。
注意力机制通过为句子中的每个单词分配一个权重(即注意力分数),来确定每个单词在预测下一个单词时的重要性。权重较高的单词对模型的预测影响更大。这样,模型不仅能够捕捉局部的语法和语义信息,还能够捕捉到更远距离的依赖关系,这在处理复杂或长距离的语言结构时尤为重要。

Transformers中的注意力机制确实设计得非常巧妙,它能够实现对输入文本的选择性关注。这种机制评估文本中不同部分的重要性,并在生成响应时决定关注点,这与以往RNN等架构将所有输入信息压缩进单一状态或记忆中的方式截然不同。
注意力机制的工作原理类似于一个高效的键值检索系统。在预测句子中的下一个单词时,每个已出现的单词都相当于提供了一个"键",这个"键"指示了该单词与预测任务的潜在相关性。然后,根据这些"键"与当前上下文(或查询)的匹配程度,为每个单词分配一个"值"或权重,这些权重共同作用于预测过程。
这种先进的深度学习模型已经被广泛应用于各种场景,从谷歌的BERT搜索引擎优化到GitHub的Copilot,后者利用大型语言模型(LLM)的能力,将简单的代码片段转化为完整的源代码。
GPT-4、Bard和LLaMA等大型语言模型(LLM)是规模庞大的结构,它们旨在解码和生成人类语言、代码等。这些模型的规模(从数十亿到数万亿个参数)是它们最显著的特征之一。通过大量文本数据的训练,这些法学硕士掌握了人类语言的复杂性。它们的一项显著能力是"少样本学习",这意味着与传统模型相比,它们能够从极少量的示例中进行有效的学习和泛化。
4.2 截至 2024 年中后期的大型语言模型 (LLM) 状况
|------------|------------------|--------------|------------------------------------------|--------------------------------------------------------------------------------------------------------------|
| Model Name | Developer | Parameters | Availability and Access | Notable Features & Remarks |
| GPT-4 | OpenAI | 1.5 Trillion | Not Open Source, API Access Only | Impressive performance on a variety of tasks can process images and text, maximum input length 32,768 tokens |
| GPT-3 | OpenAI | 175 billion | Not Open Source, API Access Only | Demonstrated few-shot and zero-shot learning capabilities. Performs text completion in natural language. |
| BLOOM | BigScience | 176 billion | Downloadable Model, Hosted API Available | Multilingual LLM developed by global collaboration. Supports 13 programming languages. |
| LaMDA | Google | 173 billion | Not Open Source, No API or Download | Trained on dialogue could learn to talk about virtually anything |
| MT-NLG | Nvidia/Microsoft | 530 billion | API Access by application | Utilizes transformer-based Megatron architecture for various NLP tasks. |
| LLaMA | Meta AI | 7B to 65B) | Downloadable by application | Intended to democratize AI by offering access to those in research, government, and academia. |
4.3 如何使用LLM
LLM通过多种方式使用,包括:
(1). 直接利用:只需使用预先训练的法学硕士进行文本生成或处理。 例如,使用 GPT-4 编写博客文章,无需任何额外的微调。
(2). 微调:针对特定任务调整预先训练的法学硕士,这种方法称为迁移学习。一个例子是定制 T5 来生成特定行业文档的摘要。
(3). 信息检索:使用 LLM(例如 BERT 或 GPT)作为大型架构的一部分来开发可以获取信息和对信息进行分类的系统。
4.4 多头注意力
然而,依赖单一的注意力机制可能会受到限制。 文本中的不同单词或序列可以具有不同类型的相关性或关联。 这就是多头注意力的用武之地。多头注意力不是一组注意力权重,而是采用多组注意力权重,使模型能够捕获输入文本中更丰富的关系。 每个注意力"头"可以关注输入的不同部分或方面,它们的组合知识用于最终预测。
4.5 ChatGPT:最流行的生成式人工智能工具
自 2018 年 GPT 诞生以来,该模型基本上建立在 12 层、12 个注意力头和 120 亿个参数的基础上,主要在名为 BookCorpus 的数据集上进行训练。 这是一个令人印象深刻的开始,让我们得以一睹语言模型的未来。
GPT-2 于 2019 年推出,其层数和注意力头增加了四倍。 值得注意的是,其参数数量猛增至 1.5 亿。 这个增强版本的训练源自 WebText,这是一个包含来自各种 Reddit 链接的 40GB 文本的数据集。
3 年 2020 月推出的 GPT-96 有 96 层、175 个注意力头和 3 亿个海量参数。 GPT-570 的与众不同之处在于其多样化的训练数据,包括 CommonCrawl、WebText、英语维基百科、书籍语料库和其他来源,总计 XNUMX GB。
ChatGPT 错综复杂的运作方式仍然是一个严格保守的秘密。 然而,众所周知,"根据人类反馈进行强化学习"(RLHF)的过程至关重要。 该技术源自早期的 ChatGPT 项目,有助于完善 GPT-3.5 模型,使其与书面指令更加一致。
ChatGPT 的培训包括三层方法:
(1). 监督微调:涉及策划人工编写的对话输入和输出,以完善底层 GPT-3.5 模型。
(2). 奖励建模:人类根据质量对各种模型输出进行排名,帮助训练一个奖励模型,该模型根据对话的上下文对每个输出进行评分。
(3). 强化学习:对话上下文作为基础模型提出响应的背景。 该响应通过奖励模型进行评估,并使用名为近端策略优化 (PPO) 的算法来优化该过程。
5. 扩散和多模态模型
虽然像VAE和GAN这样的模型通过单次生成过程产生输出,因此被锁定在它们所产生的任何内容中,但扩散模型引入了"迭代细化"的概念。通过这种方法,它们回顾并修正前几步中的错误,并逐渐产生更加精细的结果。
扩散模型的核心在于"腐败"和"细化"的艺术。在训练阶段,典型图像通过添加不同级别的噪声逐渐被损坏。然后这个嘈杂的版本被输入到模型中,模型尝试对其进行"去噪"或"去腐败"。经过多轮这样的过程,模型变得擅长于恢复,理解微妙和显著的像差。
5.1 Midjourney
从Midjourney生成新图像的过程在训练后非常有趣。从完全随机的输入开始,它使用模型的预测不断细化。目标是用最少的步骤获得一张纯净的图像。通过"噪声计划"控制腐败的水平,这是一个控制不同阶段应用多少噪声的机制。像"diffusers"这样的库中的调度器,根据既定算法决定这些嘈杂版本的性质。
对于许多扩散模型来说,UNet是其架构的重要支柱------一种为需要输出与输入空间维度相镜像的任务量身定制的卷积神经网络。它由下采样和上采样层组成,这些层复杂地连接在一起,以保留对图像相关输出至关重要的高分辨率数据。

5.2 DALL-E 2
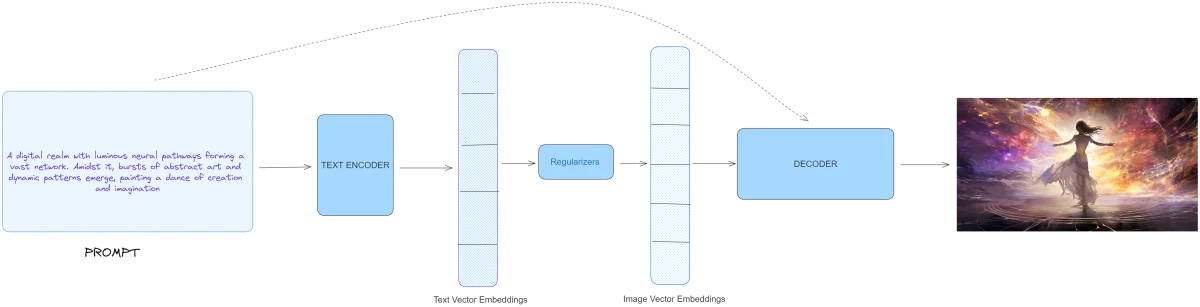
深入到生成模型的领域,OpenAI的DALL-E 2作为文本和视觉AI能力的融合,成为一个突出的例子。它采用了三层结构:
DALL-E 2展示了三重架构:
- .文本编码器:它将文本提示转换为潜在空间中的概念嵌入。这个模型不是从零开始。它依赖于OpenAI的对比语言-图像预训练(CLIP)数据集作为其基础。CLIP通过使用自然语言学习视觉概念,作为视觉和文本数据之间的桥梁。通过一种称为对比学习机制,它识别并匹配图像与其相应的文本描述。
- . 先验:从编码器派生的文本嵌入随后被转换为图像嵌入。DALL-E 2测试了自回归和扩散方法来完成这项任务,后者展示了更优越的结果。像在变换器和PixelCNN中看到的自回归模型,按顺序生成输出。另一方面,像DALL-E 2中使用的扩散模型,借助文本嵌入将随机噪声转换为预测的图像嵌入。
- . 解码器:这个过程的高潮,这部分基于文本提示和先前阶段的图像嵌入生成最终的视觉输出。DALL·E 2的解码器在架构上归功于另一个模型,GLIDE,它也可以从文本提示中产生逼真的图像。
6. 生成式人工智能的应用
6.1 文本领域
从文本开始,生成式人工智能已经因聊天机器人如ChatGPT而发生了根本性的改变。这些实体严重依赖自然语言处理(NLP)和大型语言模型(LLMs),它们被赋予执行从代码生成、语言翻译到摘要和情感分析等一系列任务的能力。例如,ChatGPT已经被广泛采用,成为数百万用户的必备工具。这进一步被基于如GPT-4、PaLM和BLOOM等大型语言模型的对话式人工智能平台所增强,这些平台能够轻松生成文本、协助编程,甚至提供数学推理。
从商业角度来看,这些模型正在变得非常宝贵。企业利用它们进行多种操作,包括风险管理、库存优化和预测需求。一些著名的例子包括Bing AI、Google的BARD和ChatGPT API。
6.1 艺术
自从2022年DALL-E 2推出以来,图像世界已经经历了戏剧性的转变。这项技术可以根据文本提示生成图像,具有艺术和专业意义。例如,midjourney利用这项技术生成了令人印象深刻的逼真图像。最近这篇文章在详细指南中揭开了Midjourney的神秘面纱,阐明了该平台及其提示工程的复杂性。此外,像Alpaca AI和Photoroom AI这样的平台利用生成式AI实现高级图像编辑功能,例如背景移除、对象删除甚至面部恢复。
6.3 视频制作
视频制作虽然在生成式人工智能领域仍处于初级阶段,但正在展示有希望的进展。像Imagen Video、Meta Make A Video和Runway Gen-2这样的平台正在突破可能的界限,即使真正真实的输出仍然在地平线上。这些模型为创建数字人类视频提供了巨大的实用性,其中Synthesia和SuperCreator等应用程序处于领先地位。值得注意的是,Tavus AI通过为个人观众提供个性化视频来提供独特的销售主张,这对企业来说是一个福音。
6.4 代码创建
编码是我们数字世界中不可或缺的一个方面,它也受到了生成式人工智能的影响。虽然ChatGPT是一个受欢迎的工具,但还开发了其他几种针对编码目的的人工智能应用程序。这些平台,如GitHub Copilot、Alphacode和CodeComplete,充当编码助手,甚至可以根据文本提示生成代码。有趣的是这些工具的适应性。Codex是GitHub Copilot背后的驱动力,可以根据个人的编码风格进行定制,凸显了生成式AI的个性化潜力。
7.结论
将人类创造力与机器计算相结合,已经成为一种宝贵的工具,平台如ChatGPT和DALL-E 2正在不断突破我们想象力的边界。它们不仅能够制作文本内容,还能够创造出视觉艺术作品,应用范围广泛且多样化。
然而,与任何技术一样,其道德影响也是至关重要的。尽管生成式人工智能带来了无限的创造潜力,但我们也必须负责任地使用它,并意识到其潜在的偏见和数据操控能力。
随着像ChatGPT这样的工具变得越来越易于使用,现在正是尝试和实验的最佳时机。无论你是艺术家、程序员还是技术爱好者,生成式人工智能领域都充满了等待被探索的可能性。