1.GeForce RTX3070 Ti官网参数:
GeForce RTXTM 3070 Ti 和 RTX 3070 显卡采用第 2 代 NVIDIA RTX 架构 - NVIDIA Ampere 架构。该系列产品搭载专用的第 2 代 RT Core ,第 3 代 Tensor Core、全新的 SM 多单元流处理器以及高速显存,助您在高性能要求的游戏中所向披靡。
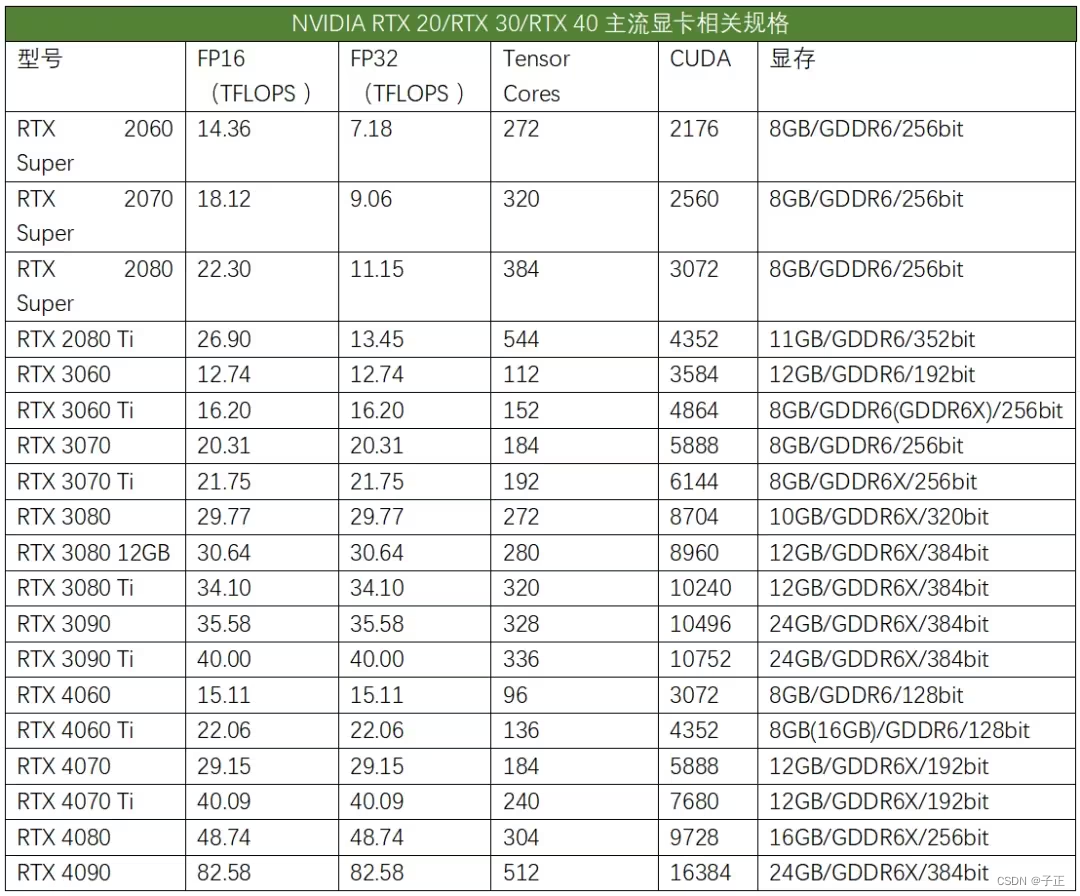
2.一处未知来源的评测表:
3.另一处基于Ti3090跑yolov5的测试结果
3090量化到FP32,使用官方的Pytorch跑,完整的60 classes coco数据集一个是18.04小时。

Coco训练集大概是12万张图片,60 classes.
4.Yolov5实测数据
- 运算环境:I5-12400
- 数据集的规模:9000张图片;25.5万个标记框,5classes
- 模型,训练环境Yolo-v5s, Pytorch, FP32, 5个类别
- 1.5 hours/epochs
- 结果:Optimizer stripped from runs\train\exp39\weights\last.pt, 14.3MB
附录 A 最简训练步骤
模型环境初始化的部分很简单,从略:
1.在yolov5 的data目录准备.yaml文件
相关数据集是在csdn下载的,大概6元钱。2276张图片。
train: ./smoker/images/train
val: ./smoker/images/val
nc: 1
names: "smoker"
2.将数据集放置在yolov5主目录内。smoker目录
3.修改train.py
def parse_opt(known=False):
parser = argparse.ArgumentParser()
parser.add_argument('--weights ', type=str, default='./yolov5-master/weights/yolov5s.pt', help='initial weights path')
parser.add_argument('--cfg ', type=str, default='./yolov5-master/models/yolov5s.yaml', help='model.yaml path')
parser.add_argument('--data ', type=str, default='./data/smoker.yaml' , help='dataset.yaml path')
parser.add_argument('--hyp', type=str, default='data/hyps/hyp.scratch.yaml', help='hyperparameters path')
parser.add_argument('--epochs ', type=int, default=2) # *300
普遍用的训练模型都是这个yolov5s,
Model Summary: 270 layers, 7022326 parameters, 7022326 gradients
7M个参数。梯度和参数是一回事,都是指一层一层的转换矩阵的总参数个数。
4.模型测试效果:
大概30分钟跑完一轮
