mysql索引是什么?
想象一下,你手上有一本数学教材,但是目录被别人给撕掉了,现在要你翻到三三角函数的那一页,该怎么办?
没有了目录,就只有两种方法,要么一页一页翻,要么随机翻。
如果数据表没有目录的话,那要查询满足条件的记录行,就需要进行全表扫描,现在的互联网应用,数据量都非常大,百万千万都很常见,这要是全表扫描,那可就恼火了,所以为了加快查询的速度,得给数据表也设置目录,这个为数据表设计的目录就是索引。
MySql采用B+数作为数据结构的原因
二叉树------>平衡二叉树------>B树------>B+树
想要实现查询,最简单的办法就是二分法查找,比如要根据ID来查找,就可以根据ID字段来构建一棵二叉树,顺着二叉树就可以找到要查询的内容,但是普通的二叉树存在一个问题,就是随着新的数据节点不断地插入,很有可能造成树的不平衡,极端的情况之下甚至会变成一个链表,这就非常不利于数据的查询
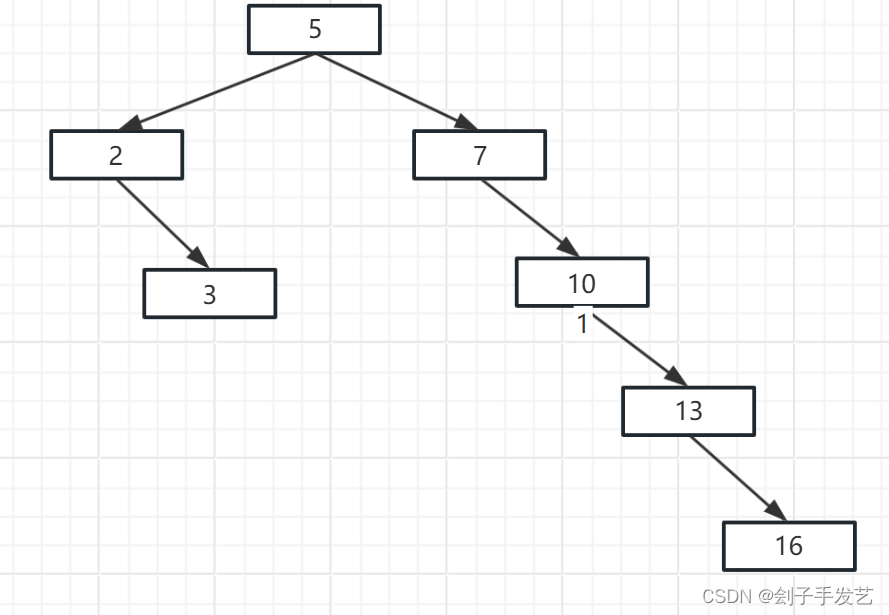
为了防止上述情况的出现,可以将二叉树升级一下变成一个平衡二叉树,这样就避免了不平衡的情况,但是随着数据量越来越大,这棵平衡二叉树的高度就会变得非常深,每层的节点数被锁定位上层节点的二倍,以此类推,即便是存1000条数据,二叉树就会变成10层,查找数据就需要多次分叉,每一次分叉都需要读取一次硬盘的数据,这样一来,一次查询就需要进行好多次的IO操作,而读取硬盘的数据,相对于内存是非常慢的。
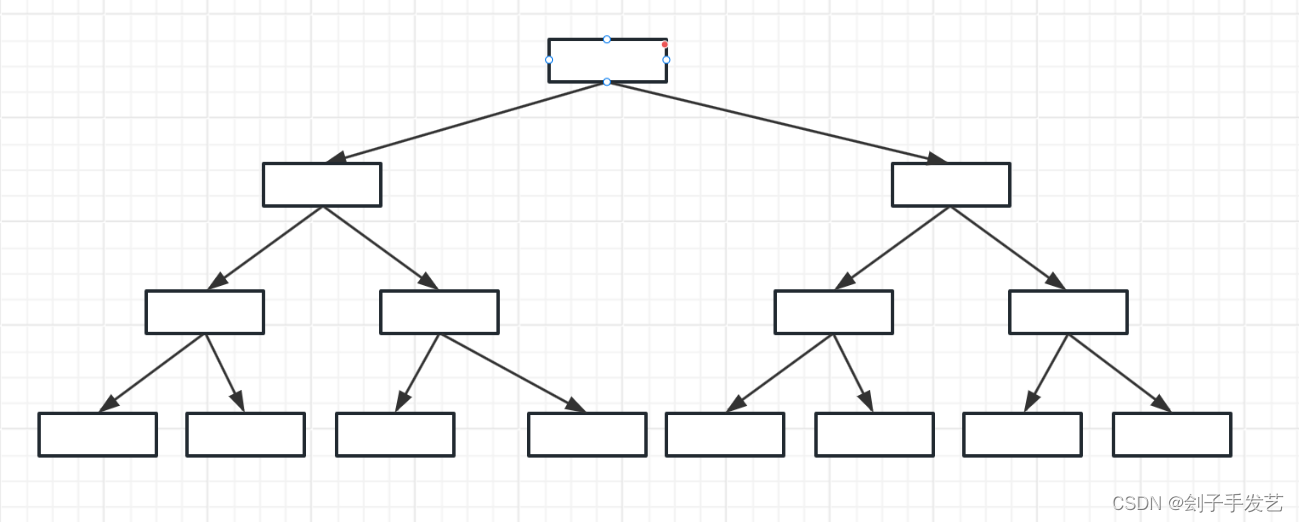
后来,B树的使用使得书的深度问题得到了解决。在B树中,一个节点可以有多个数据,并且他们按顺序排列起来,此外原来二叉树的节点最多只能分开两个叉,现在可以开非常多的分叉,查找的时候还是先从根节点触发,因为节点里的所有数据都是有序排列的,在节点中试用二分法就可以快速的定位到,如果没有查到,就根据数据节点所在的区间,去往下一级分叉的节点,重复查找的过程,由于可以有很多的分叉,所以这棵B树变得非常扁平化,即使是非常大的数据量,也只需要很少几次IO访问就能完成查找。
【有很多的数据库都采用了B树作为数据存储的和索引的数据结构】
但是B树还是存在一些问题,比如 他的查询效率不太稳定,有些在根节点或者根节点附近就能找到,那么他的查询效率就很快,如果距离根节点的距离比较远,那么查询的效率就比较慢了,所以性能不是很稳定。
另外,B树也不适合用来做范围查找,因为数据散落在不同的节点上,要查询某个范围的数据,就需要在B树上不用层级节点间进进出出,效率也会随之降低。
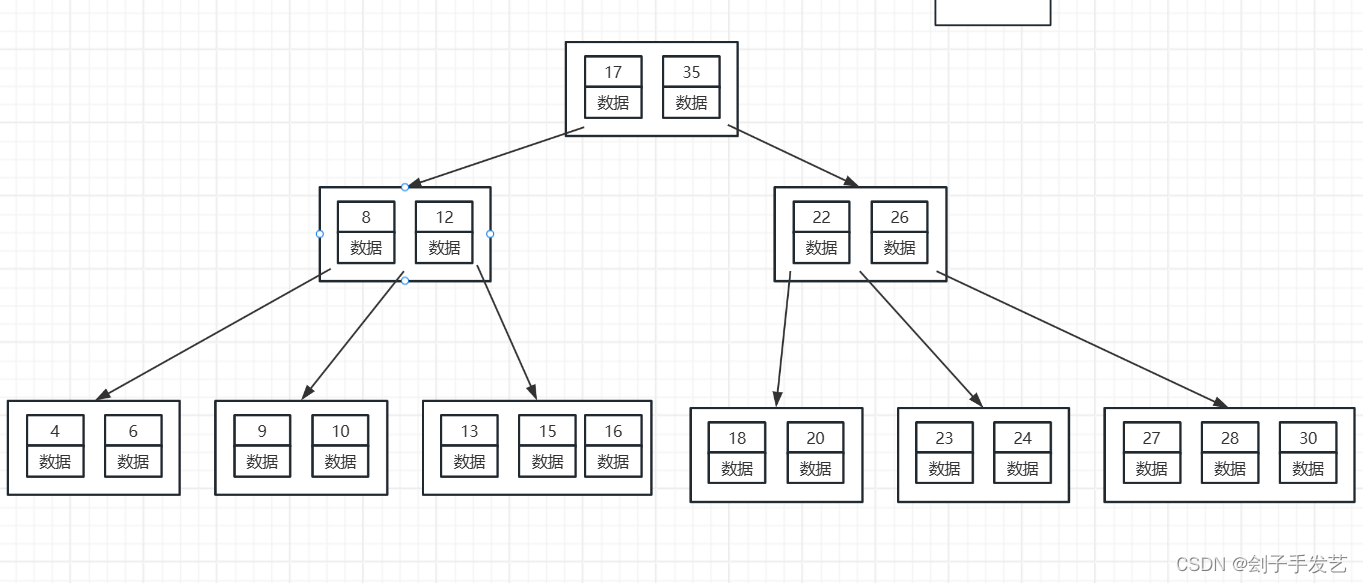
【MySql的索引采用B+树的数据结构】
所以就MySql就采用了B+树作为索引的结构。
B+树将数据全部都放在了叶子节点上,这样一来不管要查询哪个数据,最终都要走到叶子节点上,解决了查询性能不稳定的问题,其次,上面这些节点不用来存储数据了,省下来的空间用来存储指向其他节点的指针,这样一来,中间的节点中可以分出的叉就变得更多了,整个书变得更加的扁平,进一步减少IO查询的次数,最后再将叶子节点之间用指针连接起来,这样一来,就能解决范围查询的问题了。
在一些其他的场景中,还可以使用哈希索引来设计。