
【摘要】由于大型语言模型 (LLM) 的 token 限制不断增加,使得长上下文成为输入,使用单个数据样本进行提示可能不再是一种有效的方式。提高效率的一个直接策略是在 token 限制内对数据进行批处理(例如,gpt-3.5-turbo 为 8k;GPT-4 为 32k),我们称之为 BatchPrompt。对于使用批处理数据进行提示,我们有两个初步观察结果。首先,我们发现与单一数据提示相比,在较长的上下文中使用批处理数据进行提示必然会导致性能下降。其次,由于解码器上下文的相应变化,语言模型的性能与批处理数据的位置和顺序显着相关。为了保持效率并克服性能损失,我们提出了批量排列和组装 (BPE) 和一种新颖的自反射引导早期停止 (SEAS) 技术。我们全面的实验评估表明,BPE 可以在一系列流行的 NLP 任务上显著提升 BatchPrompt 的性能,包括问答 (Boolq)、文本蕴涵 (RTE) 和重复问题识别 (QQP)。这些性能甚至与单数据提示 (SinglePrompt) 相媲美/更高,而 BatchPrompt 需要的 LLM 调用和输入 token 少得多(对于批大小为 32 的 SinglePrompt 与 BatchPrompt,仅使用 9%-16% 的 LLM 调用次数,Boolq 准确率为 90.6% 到 90.9%,使用 27.4% 的 token,QQP 准确率为 87.2% 到 88.4%,使用 18.6% 的 token,RTE 准确率为 91.5% 到 91.1%,使用 30.8% 的 token)。据我们所知,这是首次从技术上提高大型语言模型的提示效率的工作。我们希望我们简单而有效的方法能够为大型语言模型的未来研究提供启示。代码将会发布。
原文:BatchPrompt: Accomplish More with Less
地址:https://arxiv.org/abs/2309.00384
代码:未知
出版:ICLR 24
机构: Microsoft
写的这么辛苦,麻烦关注微信公众号"码农的科研笔记"!
1 研究问题
本文研究的核心问题是: 如何设计一种高效且高性能的大语言模型(LLMs)推理方法,在需要处理大量样本的NLP任务中节省token使用量和调用次数。
假设一家公司需要使用GPT模型对海量的用户评论进行情感分析。如果每条评论都单独输入GPT做推理,不仅token消耗极大,而且inference速度慢,GPU调用费用高。BatchPrompt旨在通过将多条评论打包成一个prompt,大幅减少GPT调用次数,同时保持较高的分析准确率。
本文研究问题的特点和现有方法面临的挑战主要体现在以下几个方面:
-
LLMs在处理长文本序列时,由于注意力机制的计算复杂度随序列长度呈平方增长,导致性能显著下降。简单地将多个样本打包进一个超长的prompt,会造成推理质量的严重劣化。
-
由于LLMs的自回归解码特性,同一个样本在不同的prompt位置会得到不同的预测结果。比如一个二分类任务,样本A单独推理时得到的是标签1,但如果放在一个批量化的prompt中,有可能会得到标签0。
-
增大batch size和多轮投票都可能提高准确率,但同时也会增加token用量。如何在效率和性能之间找到最佳平衡点是一个关键挑战。 针对这些挑战,本文提出了一种结合批量化、置换、投票、自适应早停的"BatchPrompt"方法:
BatchPrompt的核心思想是把多个样本打包成一个prompt,交给LLM一次性完成推理,从而大幅减少调用次数。但与简单的批量处理不同,它还引入了置换(permutation)和投票(voting)机制来提升性能:
-
置换指的是随机改变每个batch内样本的顺序,生成多个置换变体,分别推理并记录结果。这样每个样本都有机会出现在不同位置,减轻位置偏差的影响。
-
投票指的是对每个样本的多个预测结果进行聚合,少数服从多数,得到最终预测。重复多轮置换+推理+投票的过程,可进一步提升鲁棒性。 此外,本文还提出了一个自适应早停(SEAS)技巧,动态调整每个样本的投票轮数。核心思路是对LLM增加一个置信度输出,连续多轮均预测为同一标签且置信度高,则提前确认该预测,停止对该样本的进一步投票。SEAS不仅能节省token,还能提高整体准确率,因为把省下的算力重新分配给那些有歧义的harder cases。 综上,BatchPrompt巧妙地利用置换、投票、自适应早停等机制,最大化地挖掘LLMs的性能,同时显著降低计算资源消耗,达到一个性能和效率的甜点。在标准数据集上的实验表明,它在大幅降低调用次数和token用量的同时,准确率与单样本推理持平,甚至还略有提升。
2 研究方法

2.1 BatchPrompt
为了提高大语言模型(LLMs)在处理下游任务时的效率,本文提出了BatchPrompt方法。传统的LLM推理方式是每次只将一个样本输入到模型中进行预测,这导致了大量的LLM调用开销。BatchPrompt的基本思想是将多个数据样本批量输入到LLM中,从而减少LLM的调用次数,提高效率。然而,简单地批量输入数据会导致预测性能的下降。这是因为LLM在生成每个输出token时,都会受到之前生成token的影响。当批量较大时,前面样本的预测结果可能会对后面样本产生误导,降低整体的预测质量。
2.2 Batch Permutation and Ensembling (BPE)
为了缓解批量输入导致的性能下降问题,论文提出了Batch Permutation and Ensembling (BPE)方法。BPE包含两个关键步骤:随机排列和集成。
在随机排列阶段,BPE将每个批次内的数据顺序打乱,使得同一样本在不同批次中出现在不同的位置。这样可以减少特定样本对其后样本预测结果的影响。假设有个批次,每个批次大小为,则每个样本都会被放置到个不同的位置上。
在集成阶段,BPE对同一样本在不同批次中的多次预测结果进行投票集成,得到最终的输出标签。具体来说,令为一个批次内的数据,为对应的预测答案,为次随机排列后的数据顺序,则样本的最终预测答案由下式给出:
其中表示样本在第次排列中的预测答案,为指示函数。上式本质上是对次预测结果进行多数投票。
图1展示了BPE的完整流程。首先将原始数据批量化,然后进行次随机排列,每次排列后输入LLM得到一组预测答案。最后对组预测答案进行投票集成得到最终输出。
2.3 Self-reflection-guided EArly Stopping (SEAS)
尽管BPE能够提升BatchPrompt的预测性能,但是多次重复预测也带来了额外的计算开销。为了进一步提高效率,论文提出了Self-reflection-guided EArly Stopping (SEAS)方法。
SEAS的核心思想是根据LLM自身对预测结果的置信度评估,决定是否提前停止对某些样本的重复预测。具体来说,它在指令中让LLM在输出预测答案的同时,也给出一个置信度标签("confident"或"not confident")。当某个样本连续多次被预测为相同的标签,且置信度标签均为"confident"时,就停止对该样本的预测,而将当前结果作为最终答案。算法1给出了SEAS的详细流程。

以下是一个SEAS的运行示例。假设批次大小为4,共进行5轮投票预测。在第1轮中,4个样本的预测结果和置信度分别为(1, c),(0, c),(1, n)和(0, n),其中"c"表示"confident","n"表示"not confident"。 在第2轮中,结果为(1, c),(0, c),(1, c)和(0, c)。此时样本1连续两次被预测为1且置信度为"c",样本2连续两次被预测为0且置信度为"c",因此这两个样本达到早停条件,在后续轮次中被去除。第3~5轮仅对剩余的样本3和4进行预测。最终样本1~4的输出标签分别为1,0,1,0。
3 实验
3.1 实验场景介绍
该论文提出了一种高效的LLM prompting技术BatchPrompt,通过将多个样本批量输入到prompt中,提高token利用率。BatchPrompt使用Batch Permutation and Ensembling (BPE)方法进一步提高性能,并提出Self-reflection-guided EArly Stopping (SEAS)技术降低token使用和LLM调用次数。论文实验主要在3个NLP任务数据集上评估BatchPrompt的有效性。
3.2 实验设置
-
Datasets:
-
Boolq:是/否类型的问答数据集,15942个样本
-
QQP:Quora Question Pairs,40万对问题,二分类任务判断两个问题是否语义相同
-
RTE:Recognizing Textual Entailment,文本蕴含数据集,分类任务判断前提和假设关系
-
-
Baseline: SinglePrompt,即常规的每个样本一次LLM调用的prompting方式
-
Implementation details:
-
Language models: gpt-3.5-turbo (ChatGPT)和GPT-4
-
使用few-shot形式,无需额外训练/微调
-
每个任务使用2-4个few-shot样本作为prompt中的演示
-
Temperature设为0保证结果一致性
-
Batch size: 16/32/64/160
-
Voting round数: 1,3,5,7,9
-
-
metric:
-
准确率
-
Token数
-
LLM调用次数
-
3.3 实验结果
3.3.1 实验一、BatchPrompt+BPE在Boolq、QQP、RTE上的性能

目的:评估BatchPrompt+BPE在3个数据集上的性能,与SinglePrompt对比
涉及图表:表1,表2,表3
实验细节概述:不同batch size(16/32/64)和voting round数量(1/3/5/7/9)设置下的BatchPrompt+BPE性能
结果:
-
更大的batch size通常导致性能下降,但5+轮voting后准确率可恢复到与SinglePrompt相当
-
Voting轮数增加不一定持续提高性能,因为错误标签也会累积。SEAS可以缓解这个问题
-
BatchPrompt在GPT-4上效果优于gpt-3.5-turbo,推测是因为基准性能更高时majority voting更有效
-
小batch size(<=64)下,1轮voting的BatchPrompt性能已接近SinglePrompt。更多voting轮数会增加token,但能超越SinglePrompt性能
-
大batch size(>=64)下,不做BPE的BatchPrompt性能明显低于SinglePrompt,但多轮voting后可以追平
3.3.2 实验二、BatchPrompt+BPE+SEAS的节约效果
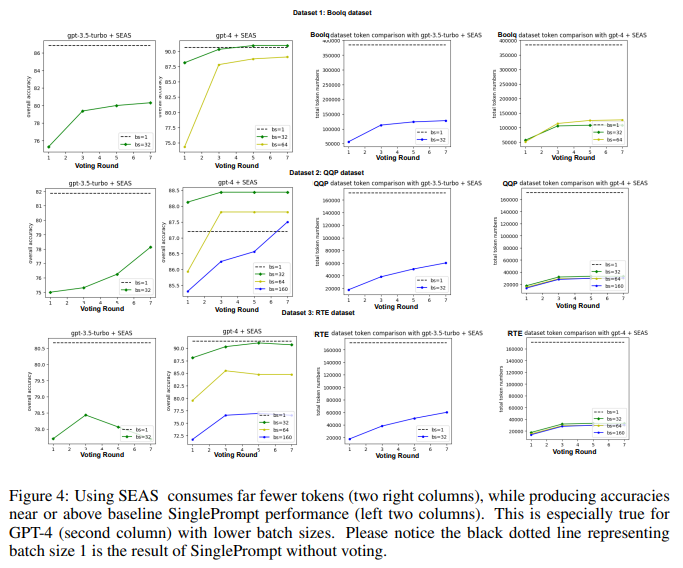
目的:评估BatchPrompt+BPE+SEAS在token使用和LLM调用次数上的节约效果
涉及图表:图3,图4
实验细节概述:分析不同任务、模型、batch size设置下SEAS的token和LLM调用节约情况
结果:
-
使用SEAS的token数远低于SinglePrompt,尤其在GPT-4和小batch size下接近SinglePrompt性能
-
SEAS在第3轮后token数增长缓慢,说明大部分简单样本在早期就完成了连续一致预测的要求,从而有效节约了token
-
使用SEAS的LLM调用次数显著低于SinglePrompt
3.3.3 实验三、BatchPrompt+BPE+SEAS消融实验

目的:验证SEAS相比随机减少batch size的有效性
涉及图表:图5
实验细节概述:在3个任务上对比BatchPrompt+BPE+SEAS和BatchPrompt+BPE+random drop的性能
结果:
- 加入self-reflection后,随着voting轮数增加,SEAS的准确率持续提升,优于随机减少batch size,说明了SEAS根据LLM自身置信度减少简单样本的有效性
3.3.4 实验四、BatchPrompt在GSM8K上的小规模实验
目的:将BatchPrompt扩展到算术推理任务
实验细节概述:在GSM8K测试集的1280个样本上评估BatchPrompt的性能
结果:
-
SinglePrompt准确率94.9%
-
Batch size为32时,voting从1轮到5轮,准确率从89.1%提高到92.0%
-
观察到即使1轮voting的大batch size准确率也很高,推测是因为batch中前面的样本可作为后面的few-shot示例,在该任务上有很好的指导作用
4 总结后记
本论文针对大语言模型(LLM)在推理阶段的效率问题,提出了BatchPrompt的方法,通过将多个样本打包到一个prompt中进行推理,大幅提升了效率。同时,为了解决简单batch会导致准确率下降的问题,提出了Batch Permutation and Ensembling (BPE)策略,通过随机排列batch内样本顺序并进行多轮投票,有效提升了准确率。此外,还引入了Self-reflection-guided EArly Stopping (SEAS)机制来进一步优化效率。实验结果表明,所提方法能在多个NLP任务上取得与逐条推理相当甚至更优的效果,同时大幅降低了推理成本。
疑惑和想法:
-
除了随机排列,是否可以探索更有效的batch内样本排列方式,如根据样本难度、长度等先验知识进行排序?
-
投票策略目前是简单的多数投票,是否可以设计更复杂的投票机制,如加权投票、置信度阈值等?
-
SEAS目前依赖于LLM自身对置信度的判断,是否存在更可靠的早停机制?如何权衡准确率和效率的平衡?
-
BatchPrompt的思想是否可以推广到其他形式的LLM,如encoder-only模型? 在生成式任务(如问答、摘要)上的效果如何?
可借鉴的方法点:
-
Batch推理的思想可以应用于各种LLM的推理加速中,在保证效果的同时显著提升效率。
-
BPE采用了随机重排+投票的思路,这种通过引入随机性、多次采样来提升鲁棒性的方法值得借鉴,可用于缓解其他任务中的特定样本依赖问题。
-
SEAS通过LLM自身输出来动态调整计算量,这种根据推理过程反馈信息动态决策的思想很有启发,可用于指导其他任务的计算资源分配。
-
本文展示了无需重新训练,仅通过prompt工程就能实现高效推理,这种轻量级地利用LLM的范式可以推广到更广泛的应用中。