Job那块的断点代码截图省略,直接进入切片逻辑
参考:Hadoop3:MapReduce源码解读之Map阶段的Job任务提交流程(1)
5、TextInputFormat源码解析
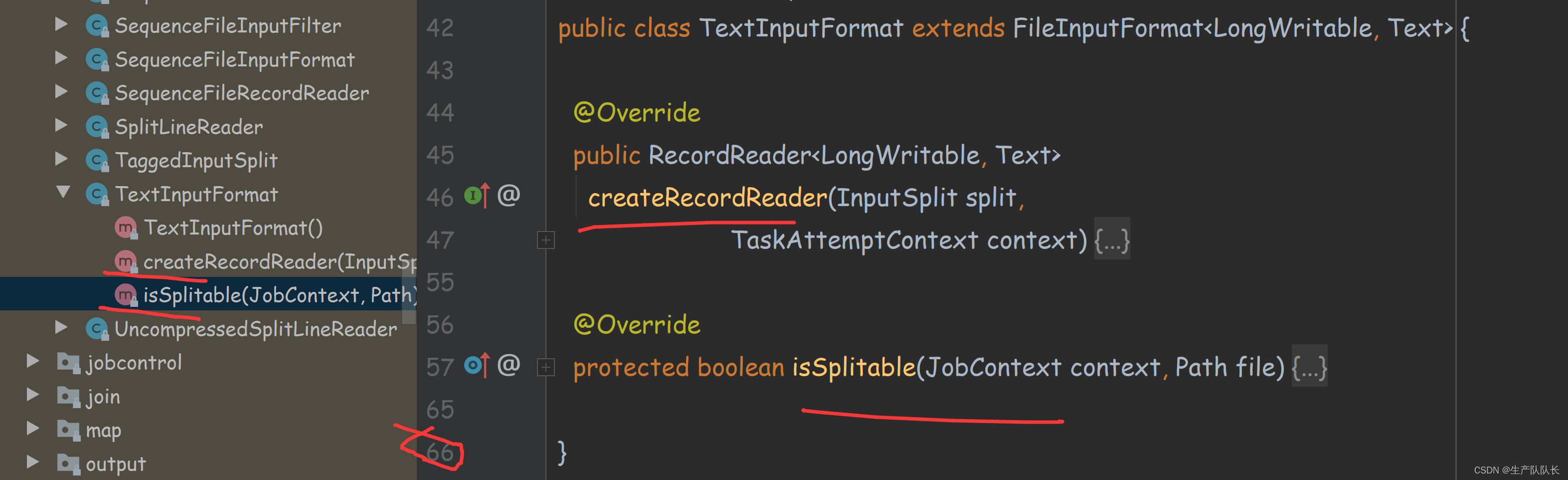
类的继承关系

它的内容比较少
重写了两个父类的方法
这里关心一下泛型参数,发现是LongWritable, Text,这就是为什么之前我们开发WC案例的时候,固定传入LongWritable和Text类型的原因
说明
TextInputFormat是默认的FileInputFormat实现类。按行读取每条记录。键是存储该行在整个文件中的起始字节偏移量, LongWritable类型。值是这行的内容,不包括任何行终止符(换行符和回车符),Text类型。
例如

注意
如果我们在开发Mapper程序时,没有指定切片类,则默认选择TextInputFormat来进行切片
案例
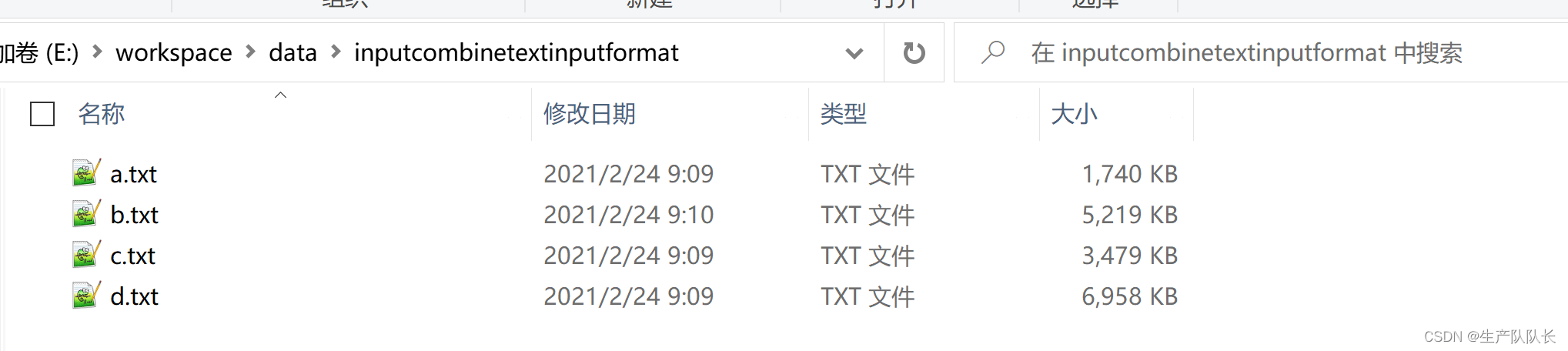
准备4个文件
依然用wordcount代码进行演练
指定文件路径
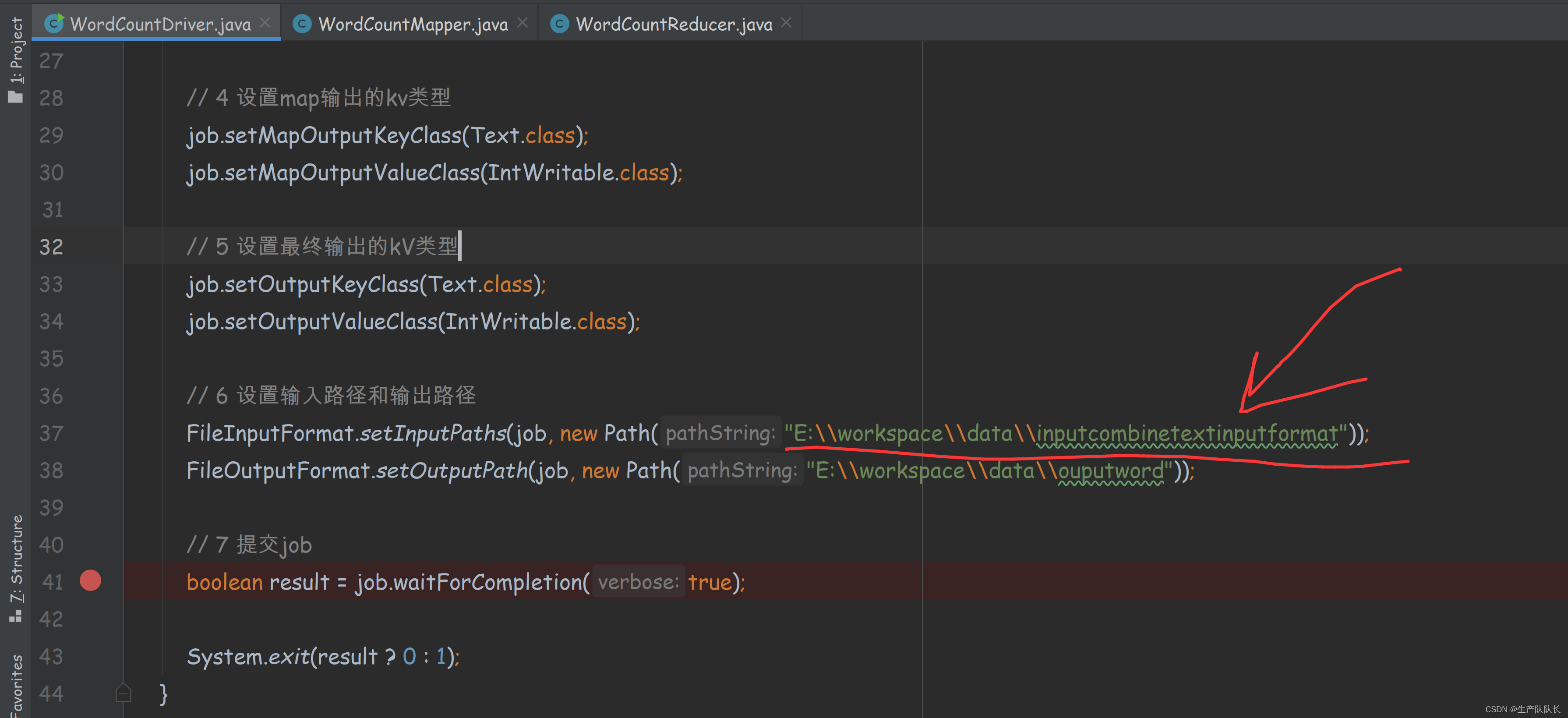
如果,我们仅仅替换了文件源路径,那么,切片类默认选择的是TextInputFormat
根据之前学习的切片逻辑
splitSzie=32M
按照每个文件单独切片
由于,这里每个文件都是小文件,都不大于32M,所以切片数量为4个
所以,会生成4个MapTask线程来处理数据
查看执行日志:
1、切片数量日志
number of splits:4

2、查看MapTask数量
attempt_local1807000288_0001_m_000000_0
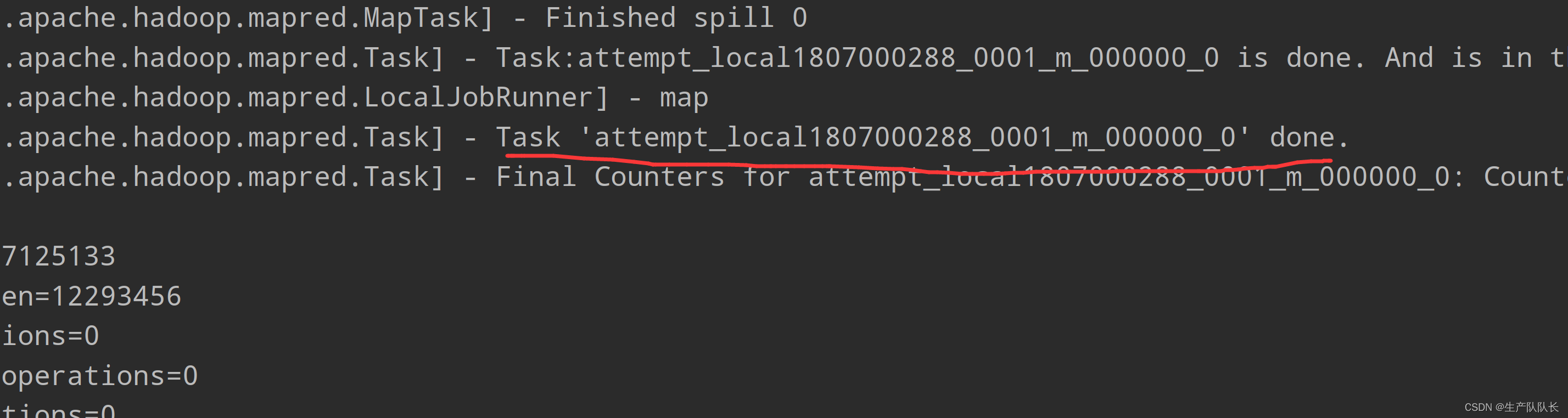
attempt_local1807000288_0001_m_000001_0
attempt_local1807000288_0001_m_000002_0
attempt_local1807000288_0001_m_000003_0
3、查看Reducer线程数量
attempt_local1807000288_0001_r_000000_0
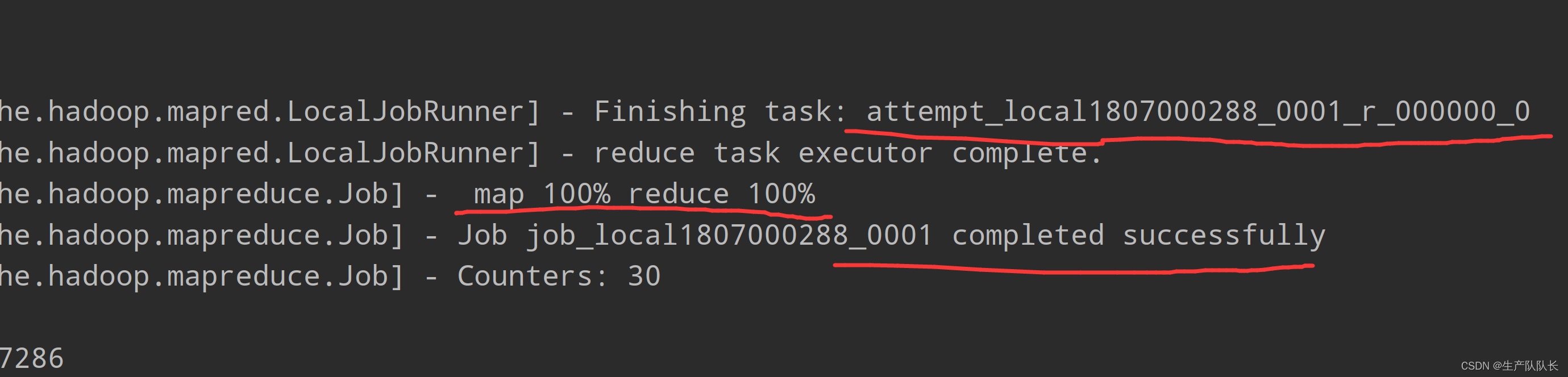
通过日志,可以看出,和预计的一样