语义检索学习
1. 基础概念篇
1.1 什么是语义搜索?
**语义搜索是一种解读单词和短语含义的搜索引擎技术。**语义搜索的结果将返回与查询含义相匹配的内容,而不是与查询字面意思相匹配的内容。
语义搜索是一系列的搜索引擎功能,包括从搜索者的意图及其搜索上下文中理解单词。
这种类型的搜索旨在根据上下文更准确地解读自然语言来提高搜索结果的质量。语义搜索借助机器学习和人工智能等技术,将搜索意图与语义相匹配,从而实现这一目标。
1.2 语义搜索 vs 关键词搜索
关键词搜索(传统搜索):
- 基于精确匹配或模糊匹配
- 依赖词频统计(TF-IDF、BM25)
- 无法理解语义和上下文
- 示例:搜索"苹果手机"只能匹配包含这些字的文档
语义搜索:
- 理解查询意图和文档含义
- 基于向量相似度
- 能够匹配同义词、相关概念
- 示例:搜索"苹果手机"也能匹配"iPhone"、"iOS设备"
对比示例:
| 查询 | 关键词搜索结果 | 语义搜索结果 |
|---|---|---|
| "如何学习编程" | 包含"学习"和"编程"的文档 | 编程教程、编程入门指南、代码学习资源 |
| "Python 性能优化" | 包含这些关键词的文档 | Python 性能分析、代码加速、内存优化等相关内容 |
1.3 语义搜索的应用场景
-
智能问答系统
- 客户服务机器人
- 企业知识库问答
- 医疗咨询系统
-
推荐系统
- 相似文档推荐
- 内容发现
- 个性化推荐
-
文档检索
- 法律文档检索
- 学术论文搜索
- 企业文档管理
-
电商搜索
- 商品语义搜索
- 用户意图理解
- 跨类目推荐
1.4 语义搜索的优势与局限
优势:
- ✅ 理解用户真实意图
- ✅ 支持自然语言查询
- ✅ 发现相关但不完全匹配的内容
- ✅ 跨语言搜索能力
- ✅ 抗同义词和多义词干扰
局限:
- ❌ 需要高质量的向量模型
- ❌ 计算成本较高
- ❌ 对精确匹配查询可能不如传统搜索
- ❌ 向量模型可能存在偏见
- ❌ 可解释性较差
2. 技术原理篇
2.1 向量化表示(Embeddings)
什么是 Embeddings?
Embeddings(嵌入向量)是将文本、图像等高维数据映射到低维连续向量空间的技术。相似的内容在向量空间中距离较近。
2.1.1 词向量(Word Embeddings)
将单个词映射为向量。
Word2Vec
- 两种训练方式:CBOW(连续词袋)和 Skip-gram
- 通过上下文预测目标词或通过目标词预测上下文
- 向量维度通常为 100-300
示例:
king - man + woman ≈ queenGloVe(Global Vectors)
- 基于全局词共现统计
- 结合了全局矩阵分解和局部上下文窗口方法
FastText
- Facebook 开发
- 考虑子词信息(subword)
- 对拼写错误和罕见词更鲁棒
2.1.2 句子向量(Sentence Embeddings)
将整个句子映射为单个向量。
Sentence-BERT (SBERT)
- 基于 BERT 的孪生网络架构
- 专门优化用于语义相似度任务
- 效率高,适合大规模检索
Universal Sentence Encoder (USE)
- Google 开发
- 支持多语言
- 两种模型:Transformer 和 DAN(Deep Averaging Network)
示例代码(使用 gte-multilingual-base):
向量服务安装 GTE-multilingual-base 本地向量服务部署与 Spring AI 集成方案-CSDN博客
java
package com.zhouquan.ai;
import org.springframework.http.HttpEntity;
import org.springframework.http.HttpHeaders;
import org.springframework.http.MediaType;
import org.springframework.http.ResponseEntity;
import org.springframework.web.client.RestTemplate;
import java.util.*;
/**
* GTE 向量生成示例
* <p>
* 使用 gte-multilingual-base 模型批量生成文本向量
* </p>
*
* @author zhouquan
*/
public class SentenceEmbeddingExample {
// GTE 服务配置
private static final String EMBEDDING_SERVICE_URL = "http://192.168.0.168:5000";
private static final int VECTOR_DIMENSION = 768;
public static void main(String[] args) {
try {
System.out.println("GTE 向量生成示例");
System.out.println("模型: Alibaba-NLP/gte-multilingual-base");
System.out.println("服务地址: " + EMBEDDING_SERVICE_URL);
System.out.println("向量维度: " + VECTOR_DIMENSION);
System.out.println();
// 测试句子
List<String> sentences = Arrays.asList(
"如何学习 Java 编程",
"Java 入门教程",
"今天天气真好"
);
// 批量文本向量化
System.out.println("【批量文本向量化】");
System.out.println();
List<float[]> embeddings = embedBatchTexts(sentences);
for (int i = 0; i < sentences.size(); i++) {
System.out.println("句子: " + sentences.get(i));
// 向量只打印前五个
System.out.print("向量: ");
for (int j = 0; j < Math.min(5, embeddings.get(i).length); j++) {
System.out.print(embeddings.get(i)[j] + " ");
}
System.out.println("向量维度: " + embeddings.get(i).length);
System.out.println();
}
} catch (Exception e) {
System.err.println("错误: " + e.getMessage());
e.printStackTrace();
}
}
/**
* 批量文本向量化
*
* @param texts 待向量化的文本列表
* @return 向量列表
*/
public static List<float[]> embedBatchTexts(List<String> texts) {
try {
RestTemplate restTemplate = new RestTemplate();
String url = EMBEDDING_SERVICE_URL + "/embed_batch";
// 构建请求
Map<String, Object> requestBody = new HashMap<>();
requestBody.put("texts", texts);
HttpHeaders headers = new HttpHeaders();
headers.setContentType(MediaType.APPLICATION_JSON);
HttpEntity<Map<String, Object>> request = new HttpEntity<>(requestBody, headers);
// 发送请求
ResponseEntity<Map> response = restTemplate.postForEntity(url, request, Map.class);
// 解析响应
Map<String, Object> body = response.getBody();
if (body == null || !body.containsKey("embeddings")) {
throw new RuntimeException("响应数据为空");
}
List<List<Double>> embeddings = (List<List<Double>>) body.get("embeddings");
List<float[]> result = new ArrayList<>();
for (List<Double> embedding : embeddings) {
result.add(convertToFloatArray(embedding));
}
return result;
} catch (Exception e) {
throw new RuntimeException("批量文本向量化失败: " + e.getMessage(), e);
}
}
/**
* 将 List<Double> 转换为 float[]
*/
private static float[] convertToFloatArray(List<Double> list) {
float[] array = new float[list.size()];
for (int i = 0; i < list.size(); i++) {
array[i] = list.get(i).floatValue();
}
return array;
}
}输出结果:
java
GTE 向量生成示例
模型: Alibaba-NLP/gte-multilingual-base
服务地址: http://192.168.0.168:5000
向量维度: 768
【批量文本向量化】
句子: 如何学习 Java 编程
向量: 0.026278736 -0.027642524 -0.11199176 -0.052430928 0.050870888 向量维度: 768
句子: Java 入门教程
向量: -0.014897345 0.011146749 -0.091105774 -0.050095912 0.012215903 向量维度: 768
句子: 今天天气真好
向量: -0.030632775 0.057086878 -0.06665294 -0.026957892 -0.02842947 向量维度: 7682.1.3 文档向量(Document Embeddings)
将长文档映射为向量。
Doc2Vec
- Word2Vec 的扩展
- 在训练时加入文档 ID
长文本向量化策略:
- 分块平均:将文档分块,对每块向量取平均
- 加权平均:使用 TF-IDF 等权重
- 层次化编码:先编码段落,再聚合为文档向量
- 长文本模型:如 Longformer、BigBird
2.1.4 常用向量化模型对比
| 模型 | 类型 | 向量维度 | 多语言 | 适用场景 |
|---|---|---|---|---|
| Word2Vec | 词向量 | 100-300 | ❌ | 词语相似度 |
| GloVe | 词向量 | 50-300 | ❌ | 词语相似度 |
| BERT | 上下文词向量 | 768/1024 | ✅ | NLP 任务 |
| Sentence-BERT | 句子向量 | 384/768 | ✅ | 句子相似度、检索 |
| USE | 句子向量 | 512 | ✅ | 句子相似度、分类 |
| OpenAI text-embedding-ada-002 | 文本向量 | 1536 | ✅ | 通用文本检索 |
| text-embedding-3-small | 文本向量 | 1536 | ✅ | 高效检索 |
| text-embedding-3-large | 文本向量 | 3072 | ✅ | 高精度检索 |
2.2 向量相似度计算
2.2.1 余弦相似度(Cosine Similarity)
最常用的相似度度量方法,计算两个向量之间的夹角。
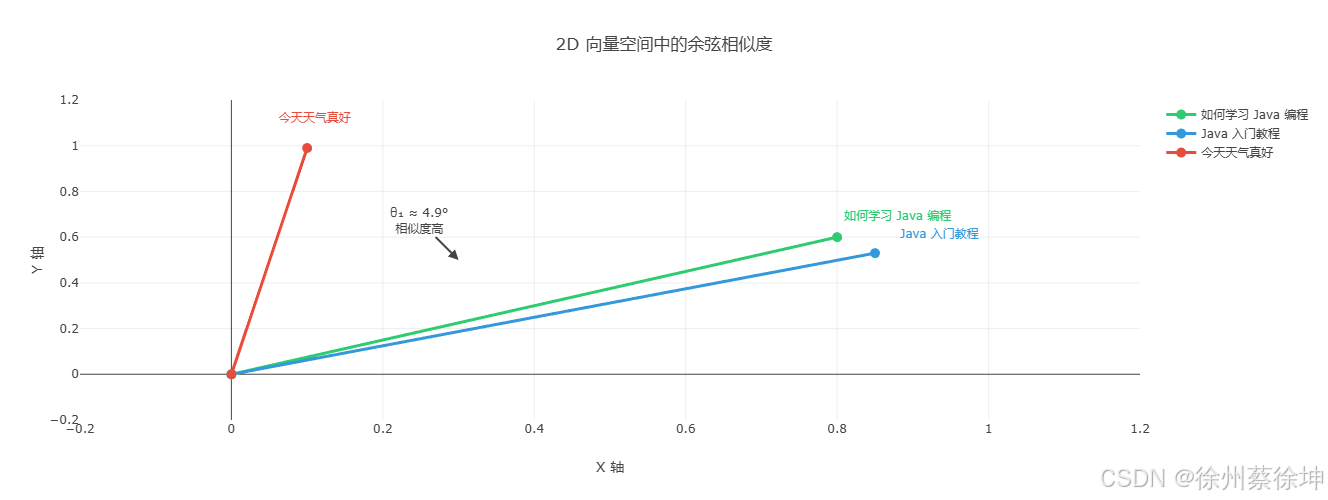
2D 向量空间可视化
**说明:**实际的 GTE 模型生成的是 768 维向量,为了便于理解,这里先用 2D 向量展示余弦相似度的几何意义。
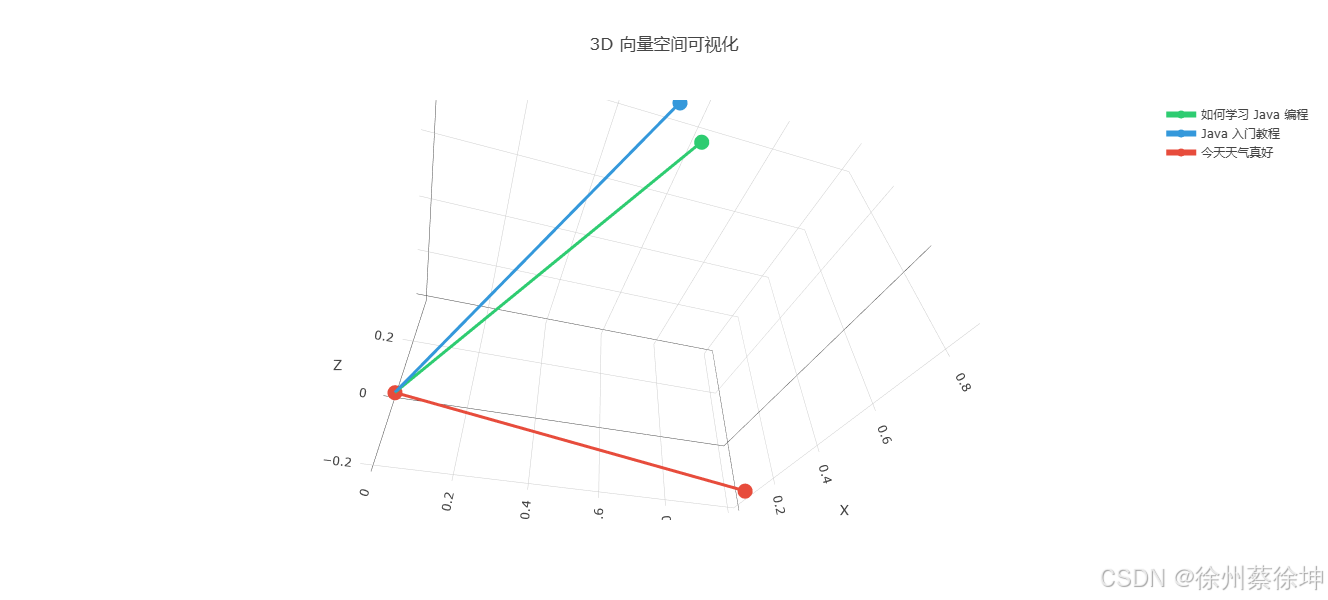
3D 向量空间可视化
公式:
mathematica
公式:
cosine_similarity(A, B) = (A · B) / (||A|| × ||B||)
其中:
• A · B = 点积 = A₀×B₀ + A₁×B₁ + A₂×B₂ + ... + A₇₆₇×B₇₆₇
• ||A|| = 向量A的模长 = √(A₀² + A₁² + A₂² + ... + A₇₆₇²)
• ||B|| = 向量B的模长 = √(B₀² + B₁² + B₂² + ... + B₇₆₇²)特点:
- 值域:-1, 1,1 表示完全相同,-1 表示完全相反
- 不受向量长度影响,只关注方向
- 最适合文本向量相似度
Java 实现:
java
/**
* 计算余弦相似度
*
* @param vec1 向量1
* @param vec2 向量2
* @return 相似度值 (0-1之间,越大越相似)
*/
public static double cosineSimilarity(float[] vec1, float[] vec2) {
// 初始化三个累加器
double dotProduct = 0.0; // 点积:A·B
double norm1 = 0.0; // ||A||²
double norm2 = 0.0; // ||B||²
// 遍历所有维度(768维)
for (int i = 0; i < vec1.length; i++) {
dotProduct += vec1[i] * vec2[i]; // 累加点积
norm1 += vec1[i] * vec1[i]; // 累加A的平方和
norm2 += vec2[i] * vec2[i]; // 累加B的平方和
}
// 返回余弦相似度
return dotProduct / (Math.sqrt(norm1) * Math.sqrt(norm2));
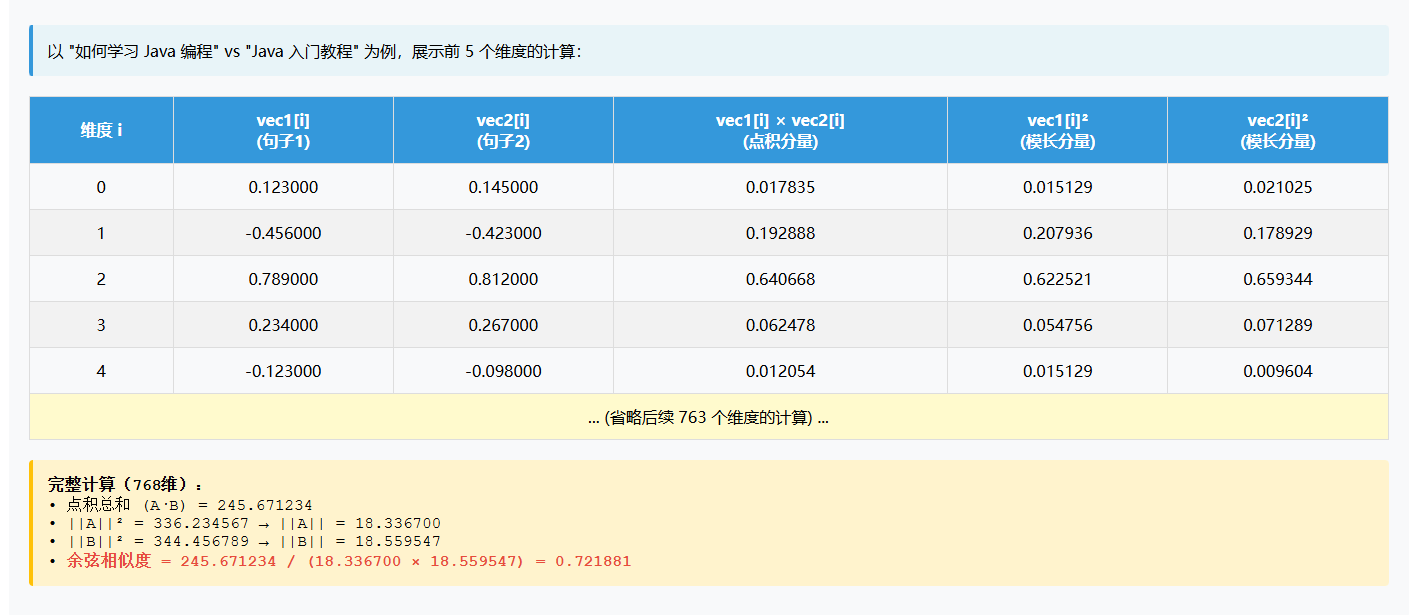
}详细计算过程(前5个维度)
2.2.2 欧氏距离(Euclidean Distance)
计算向量在空间中的直线距离。
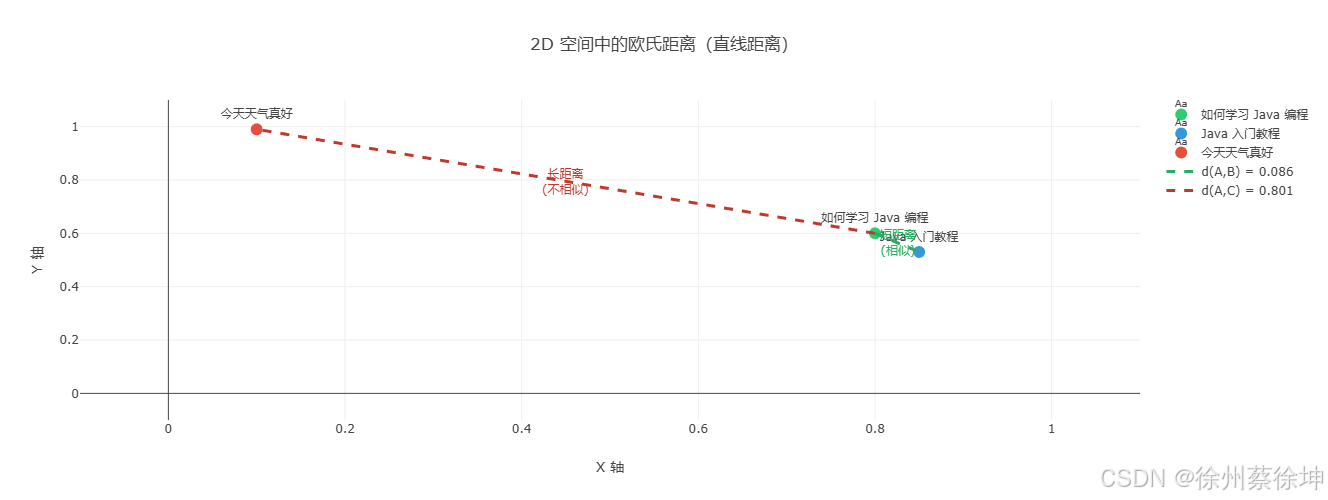
2D 空间直观理解
公式:
euclidean_distance(A, B) = sqrt(Σ(Ai - Bi)²)特点:
- 值域:[0, ∞),0 表示完全相同
- 受向量长度影响
- 适合归一化后的向量
768 维向量的欧氏距离计算
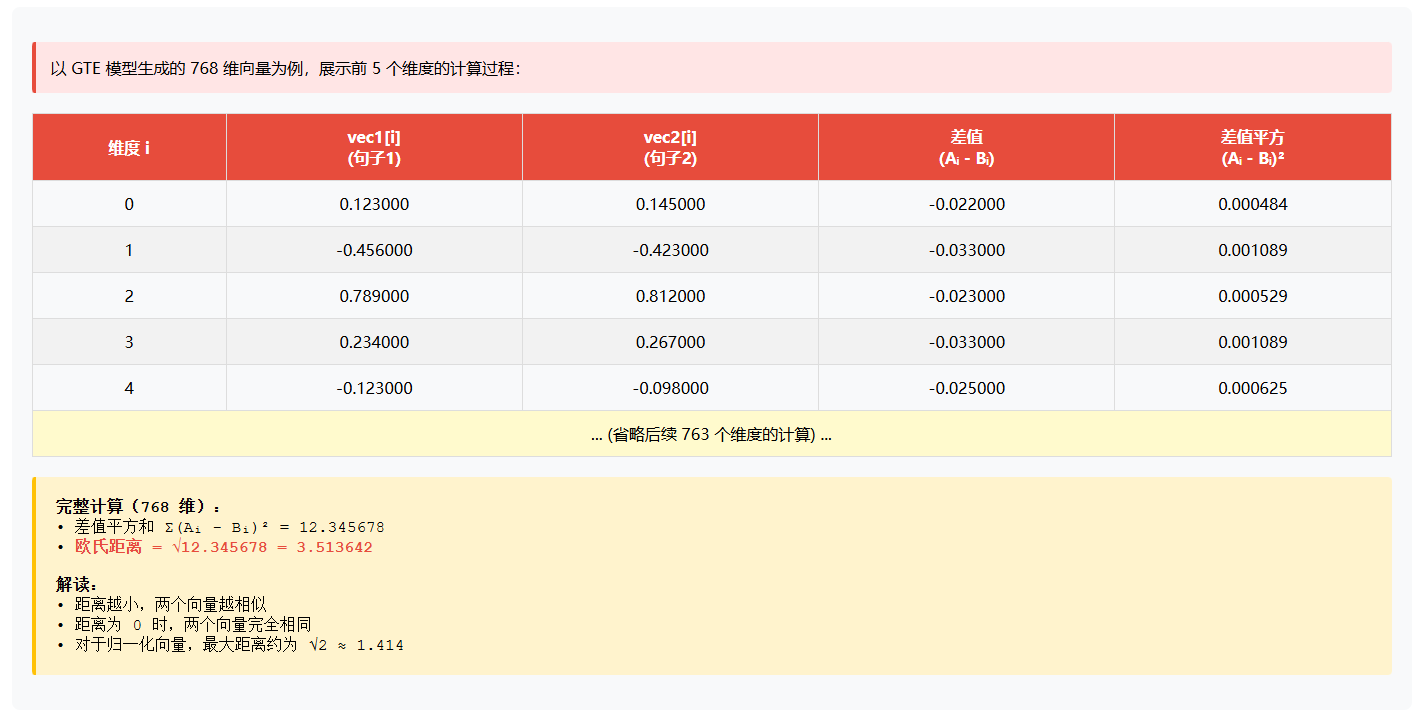
Java 实现:
java
/**
* 计算欧氏距离
*
* @param vec1 向量1 (768维)
* @param vec2 向量2 (768维)
* @return 欧氏距离值 (范围: [0, ∞), 0表示完全相同)
*/
public static double euclideanDistance(float[] vec1, float[] vec2) {
if (vec1.length != vec2.length) {
throw new IllegalArgumentException("向量维度不匹配");
}
double sumSquaredDiff = 0.0; // 差值平方和
// 遍历所有维度(768维)
for (int i = 0; i < vec1.length; i++) {
double diff = vec1[i] - vec2[i]; // 计算差值
sumSquaredDiff += diff * diff; // 累加差值平方
}
// 返回平方根
return Math.sqrt(sumSquaredDiff);
}
/**
* 归一化欧氏距离(范围转换为 [0, 1])
*
* @param vec1 向量1
* @param vec2 向量2
* @return 归一化后的距离 (0表示相同, 1表示最远)
*/
public static double normalizedEuclideanDistance(float[] vec1, float[] vec2) {
double distance = euclideanDistance(vec1, vec2);
// 对于单位向量,最大距离是 √2
double maxDistance = Math.sqrt(2.0);
return distance / maxDistance;
}
/**
* 将欧氏距离转换为相似度 (范围: [0, 1])
*
* @param vec1 向量1
* @param vec2 向量2
* @return 相似度 (1表示相同, 0表示最远)
*/
public static double euclideanSimilarity(float[] vec1, float[] vec2) {
double distance = euclideanDistance(vec1, vec2);
// 使用公式: similarity = 1 / (1 + distance)
return 1.0 / (1.0 + distance);
}2.2.3 点积相似度(Dot Product)
计算两个向量的点积。
公式:
mathematica
代数定义:
dot_product(A, B) = Σ(Aᵢ × Bᵢ)
展开形式:
A · B = A₀×B₀ + A₁×B₁ + A₂×B₂ + ... + A₇₆₇×B₇₆₇
几何定义:
A · B = ||A|| × ||B|| × cos(θ)
其中:
• ||A|| = 向量 A 的长度(模长)
• ||B|| = 向量 B 的长度(模长)
• θ = 向量 A 和 B 之间的夹角特点:
- 值域:(-∞, ∞)
- 同时考虑方向和长度
- 计算效率高
2D 空间几何理解
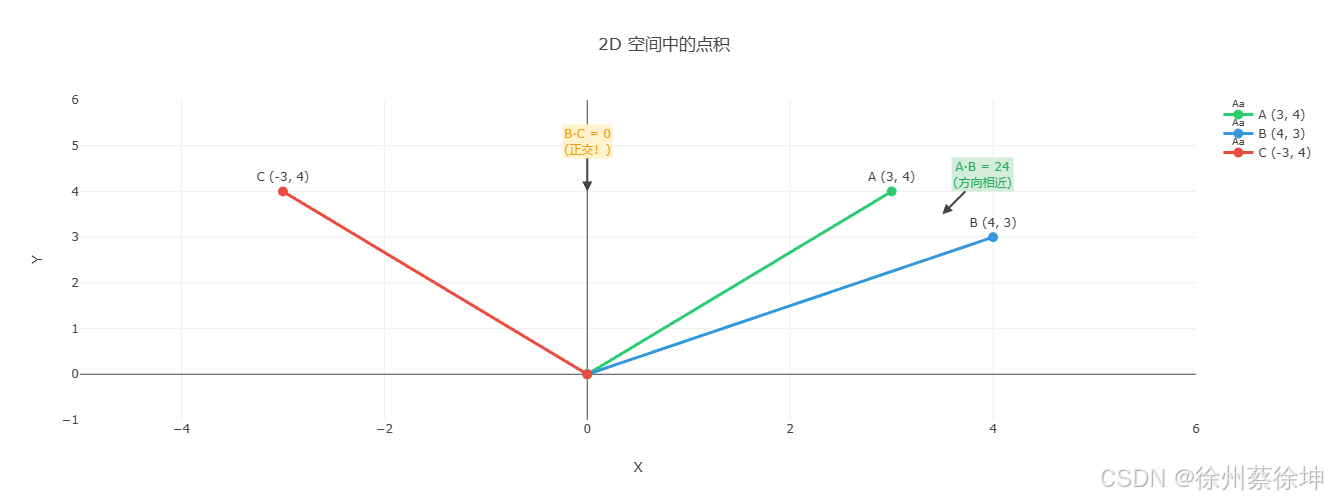
Java 实现:
java
/**
* 计算点积(内积)
*
* @param vec1 向量1 (768维)
* @param vec2 向量2 (768维)
* @return 点积值 (范围: (-∞, +∞))
*/
public static double dotProduct(float[] vec1, float[] vec2) {
if (vec1.length != vec2.length) {
throw new IllegalArgumentException("向量维度不匹配");
}
double result = 0.0;
// 遍历所有维度(768维)- 最简单高效的计算
for (int i = 0; i < vec1.length; i++) {
result += vec1[i] * vec2[i]; // 只需乘法和加法
}
return result;
}
/**
* 点积与余弦相似度的关系
* cosine = dotProduct / (||A|| × ||B||)
*/
public static double cosineSimilarityFromDotProduct(float[] vec1, float[] vec2) {
double dot = dotProduct(vec1, vec2);
double norm1 = Math.sqrt(dotProduct(vec1, vec1)); // ||A|| = √(A·A)
double norm2 = Math.sqrt(dotProduct(vec2, vec2)); // ||B|| = √(B·B)
return dot / (norm1 * norm2);
}
/**
* 对于归一化向量,点积就等于余弦相似度
* 因为 ||A|| = ||B|| = 1
*/
public static double dotProductNormalized(float[] vec1, float[] vec2) {
// 假设向量已经归一化
// 此时 dot(A, B) = ||A|| × ||B|| × cos(θ) = 1 × 1 × cos(θ) = cos(θ)
return dotProduct(vec1, vec2);
}
/**
* 使用 SIMD 优化的点积(性能优化版本)
* 实际生产中可以使用 Java Vector API (JDK 16+)
*/
public static double dotProductOptimized(float[] vec1, float[] vec2) {
double sum0 = 0, sum1 = 0, sum2 = 0, sum3 = 0; // 4路并行累加
int i = 0;
int limit = vec1.length - 3;
// 循环展开,利用 CPU 流水线
for (; i < limit; i += 4) {
sum0 += vec1[i] * vec2[i];
sum1 += vec1[i+1] * vec2[i+1];
sum2 += vec1[i+2] * vec2[i+2];
sum3 += vec1[i+3] * vec2[i+3];
}
// 处理剩余元素
for (; i < vec1.length; i++) {
sum0 += vec1[i] * vec2[i];
}
return sum0 + sum1 + sum2 + sum3;
}2.2.4 相似度度量选择建议
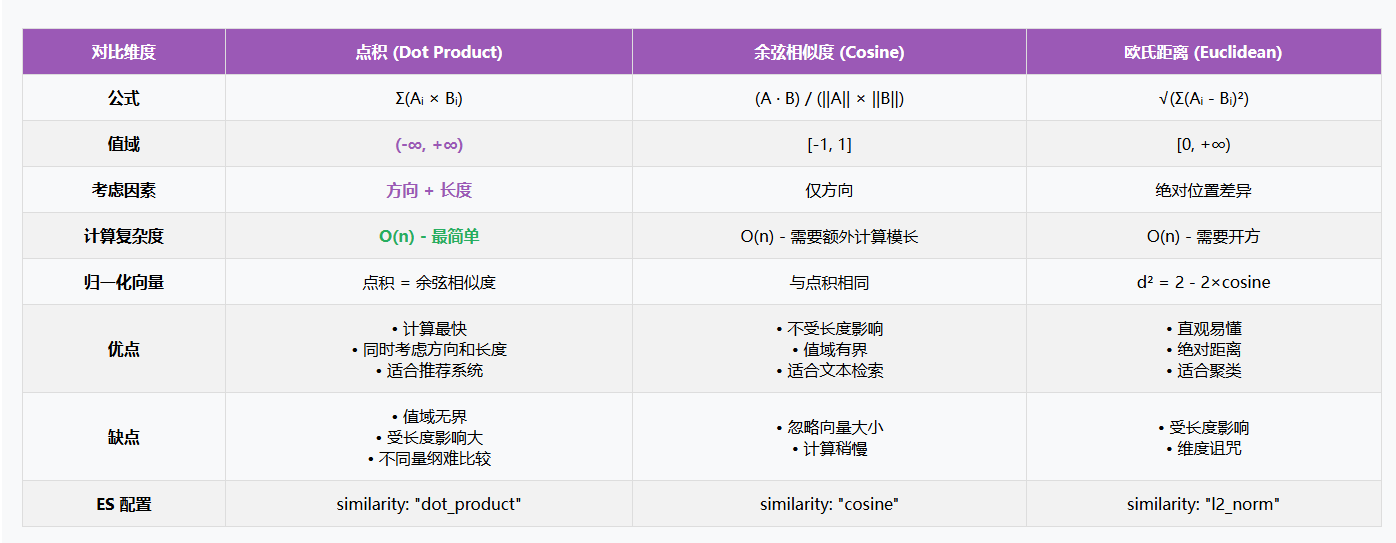
| 场景 | 推荐度量 | 原因 |
|---|---|---|
| 文本语义检索 | 余弦相似度 | 不受文本长度影响 |
| 归一化向量 | 点积或余弦 | 计算效率高 |
| 图像检索 | L2 距离或余弦 | 根据模型训练方式选择 |
| 推荐系统 | 余弦相似度 | 关注内容相关性 |
2.3 向量搜索技术
2.3.1 HNSW(Hierarchical Navigable Small World)
原理: 分层图结构 + 贪婪搜索
- 构建多层图,每层节点数递减(类似跳表)
- 上层用于快速跳跃,下层用于精确搜索
- 搜索时从顶层开始,逐层下降找到最近邻
- 时间复杂度: O(log N) 查询
- 空间复杂度: O(N × M),M 为连接数
特点:
- ✅ 查询速度快,适合实时检索
- ✅ 召回率高(通常 > 95%)
- ✅ 工业界广泛应用,技术成熟
- ❌ 内存占用大
- ❌ 构建索引较慢
搜索步骤详解
1 进入顶层(高速路):从入口点出发,在稀疏的顶层节点间跳跃,快速接近目标区域
2下降到中层(省道):在中层继续搜索,节点更密集,进一步缩小范围
3 到达底层(街道):在最密集的底层进行精确搜索,找到最近邻
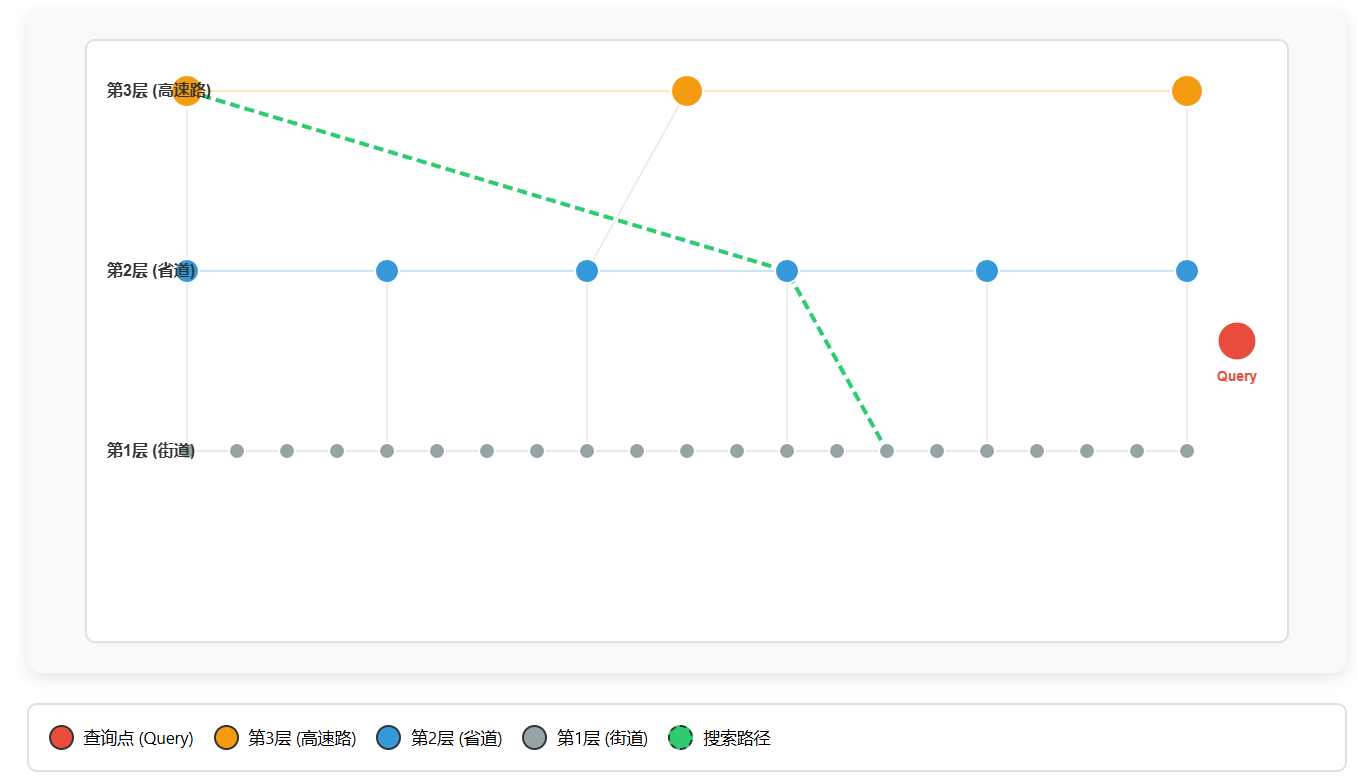
应用场景:
- Elasticsearch(默认使用 HNSW)
- Faiss(Facebook AI 向量搜索库)
- Milvus(开源向量数据库)
- Pinecone、Weaviate 等向量数据库
推荐指数:⭐⭐⭐⭐⭐
适合 95% 的向量搜索场景,工业界首选方案。
2.3.2 IVF(Inverted File Index)
原理:
- 使用聚类(如 K-Means)将向量空间划分为多个区域
- 搜索时只在最近的几个聚类中查找
- 类似倒排索引的思想
特点:
- ✅ 内存占用小
- ✅ 适合超大规模数据(亿级以上)
- ✅ 可与 PQ(Product Quantization)结合进一步压缩
- ❌ 召回率相对较低(80-95%)
- ❌ 需要选择合适的聚类数
搜索步骤详解
聚类阶段(预处理):使用 K-Means 将所有向量分成 N 个簇,计算每个簇的中心点
找到最近的簇:计算查询向量到所有聚类中心的距离,找出最近的 nprobe 个簇
只在选中的簇内搜索:只计算这 nprobe 个簇内数据点的距离,跳过其他簇
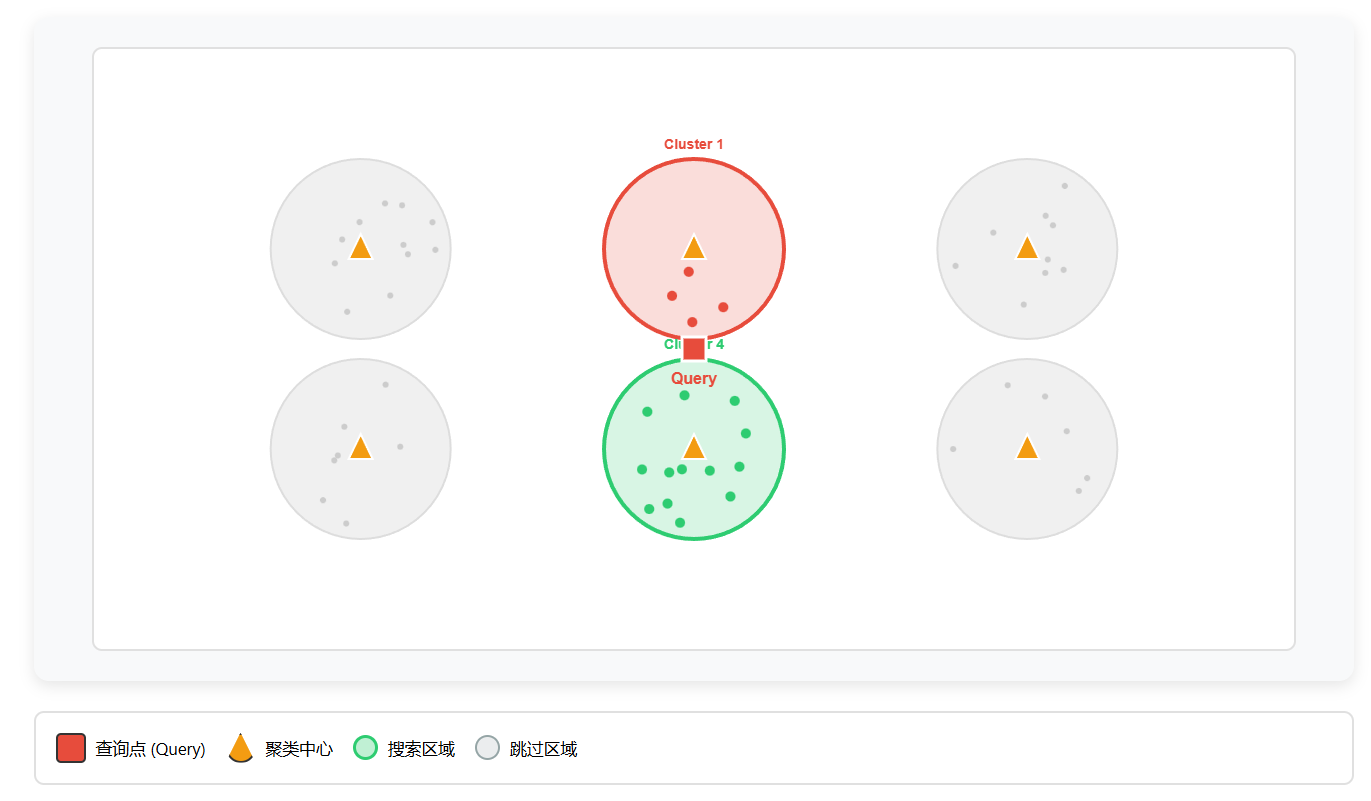
应用场景:
- Faiss IVF 系列索引
- 超大规模向量检索(> 千万级)
- 对内存有严格限制的场景
推荐指数:⭐⭐⭐⭐
超大规模数据的首选,需要在召回率和性能间权衡。
2.3.3 暴力搜索(Brute Force)
原理:
- 计算查询向量与所有候选向量的相似度
- 返回 Top-K 最相似的结果
特点:
- ✅ 精确搜索,召回率 100%
- ✅ 实现简单,无需调参
- ✅ 适合小规模数据验证
- ❌ 时间复杂度 O(N×D),N 为文档数,D 为向量维度
- ❌ 不适合大规模数据
应用场景:
- 小规模数据(< 10万)
- 验证其他算法的召回率基准
- 原型开发和测试
推荐指数:⭐⭐
仅用于小规模场景或作为对比基准。
2.3.4 LSH(Locality-Sensitive Hashing)
原理:
- 使用哈希函数将相似向量映射到相同的桶
- 只在相同桶内搜索
特点:
- ✅ 构建速度快
- ✅ 内存友好
- ✅ 适合动态更新场景
- ❌ 召回率较低(70-90%)
- ❌ 参数调优困难
- ❌ 对高维向量效果不佳
应用场景:
- 对精度要求不高的推荐系统
- 需要频繁更新索引的场景
- 低维向量检索
推荐指数:⭐⭐
现代场景中已较少使用,多被 HNSW 替代。
2.3.5 向量索引算法对比
总体推荐
| 算法 | 流行度 | 查询速度 | 召回率 | 内存占用 | 构建速度 | 适用场景 | 推荐指数 |
|---|---|---|---|---|---|---|---|
| HNSW | ⭐⭐⭐⭐⭐ | 快 | 95-99% | 高 | 中等 | 中大规模实时检索 | ⭐⭐⭐⭐⭐ |
| IVF | ⭐⭐⭐⭐ | 中等 | 80-95% | 中等 | 快 | 超大规模数据(亿级) | ⭐⭐⭐⭐ |
| Brute Force | ⭐⭐ | 慢 | 100% | 低 | 快 | 小规模数据(< 10万) | ⭐⭐ |
| LSH | ⭐ | 快 | 70-90% | 低 | 快 | 对精度要求不高的场景 | ⭐⭐ |
查询速度对比
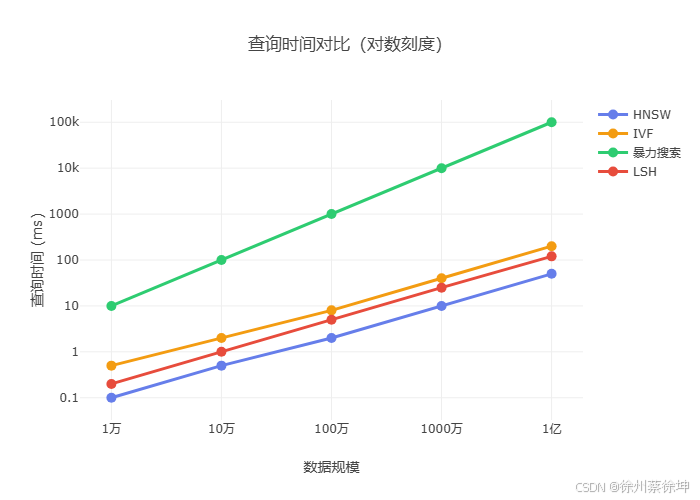
召回率对比
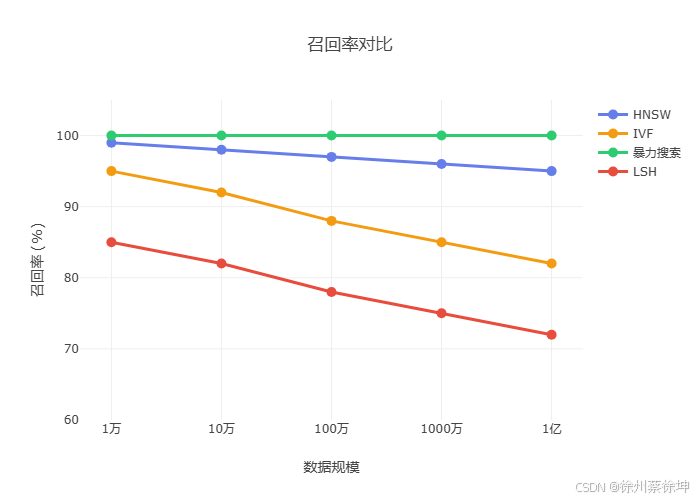
选择建议:
- 首选 HNSW:适合 95% 的场景,Elasticsearch 默认方案
- 超大规模用 IVF:数据量 > 千万级,内存受限
- 小规模用暴力:< 10万数据,追求 100% 召回
- 避免使用 LSH**:已有更好的替代方案
2.3.6 向量搜索性能优化
-
向量维度优化
- 降维技术:PCA、t-SNE
- 使用较小的模型:如 MiniLM 系列
-
量化技术
- 标量量化:float32 → int8
- 乘积量化(PQ):将向量分段量化
-
硬件加速
- GPU 加速
- 专用向量搜索硬件
3. Elasticsearch 实践篇
3.1 Elasticsearch 中的向量搜索
Elasticsearch 从 7.x 版本开始支持向量搜索,8.x 版本功能更加完善。
3.1.1 dense_vector 字段类型
字段定义:
json
PUT /my_index
{
"mappings": {
"properties": {
"title": {
"type": "text"
},
"content": {
"type": "text"
},
"title_vector": {
"type": "dense_vector",
"dims": 768,
"index": true,
"similarity": "cosine"
},
"content_vector": {
"type": "dense_vector",
"dims": 768,
"index": true,
"similarity": "cosine"
}
}
}
}参数说明:
dims:向量维度,必须与模型输出维度一致index:是否创建向量索引(true = HNSW 索引)similarity:相似度度量方式cosine:余弦相似度(推荐)dot_product:点积l2_norm:欧氏距离
索引数据
测试数据:zhouxiaoquan.github.io/zhouquan.github.io/esdata.txt
json
POST /my_index/_doc
{
"title": "Python 数据分析实战",
"content": "本课程将介绍如何使用 Python 进行数据分析,包括 NumPy、Pandas、Matplotlib 等库的使用,从数据清洗到可视化,带你掌握数据分析的核心技能。",
"title_vector": [ -0.0208999402821064,
0.01331911701709032,
-0.06355377286672592
...
],
"content_vector": [-0.03954795375466347,
0.007010910660028458,
-0.07348231226205826,
...
]
}
POST /my_index/_doc
{
"title": "机器学习基础",
"content": "机器学习是人工智能的一个分支,它使计算机能够学习而不需要明确编程。本课程将从监督学习、无监督学习等基础概念讲起,带你进入机器学习的世界。",
"title_vector": [ -0.013987698592245579,
-0.0579521618783474,
-0.08713562786579132
],
"content_vector": [ -0.030959052965044975,
-0.042195241898298264,
-0.0682775005698204,
...
]
}
POST /my_index/_doc
{
"title": "Elasticsearch 分布式搜索",
"content": "Elasticsearch 是一个基于 Lucene 的分布式搜索引擎,它提供了一个分布式多用户能力的全文搜索引擎,具有高可用性、高扩展性和实时性。",
"title_vector": [ -0.08578959107398987,
0.02684123069047928,
-0.03178650140762329,
...
],
"content_vector": [
-0.09641386568546295,
0.017185380682349205,
-0.004696432966738939,
...
]
}3.1.2 kNN 搜索
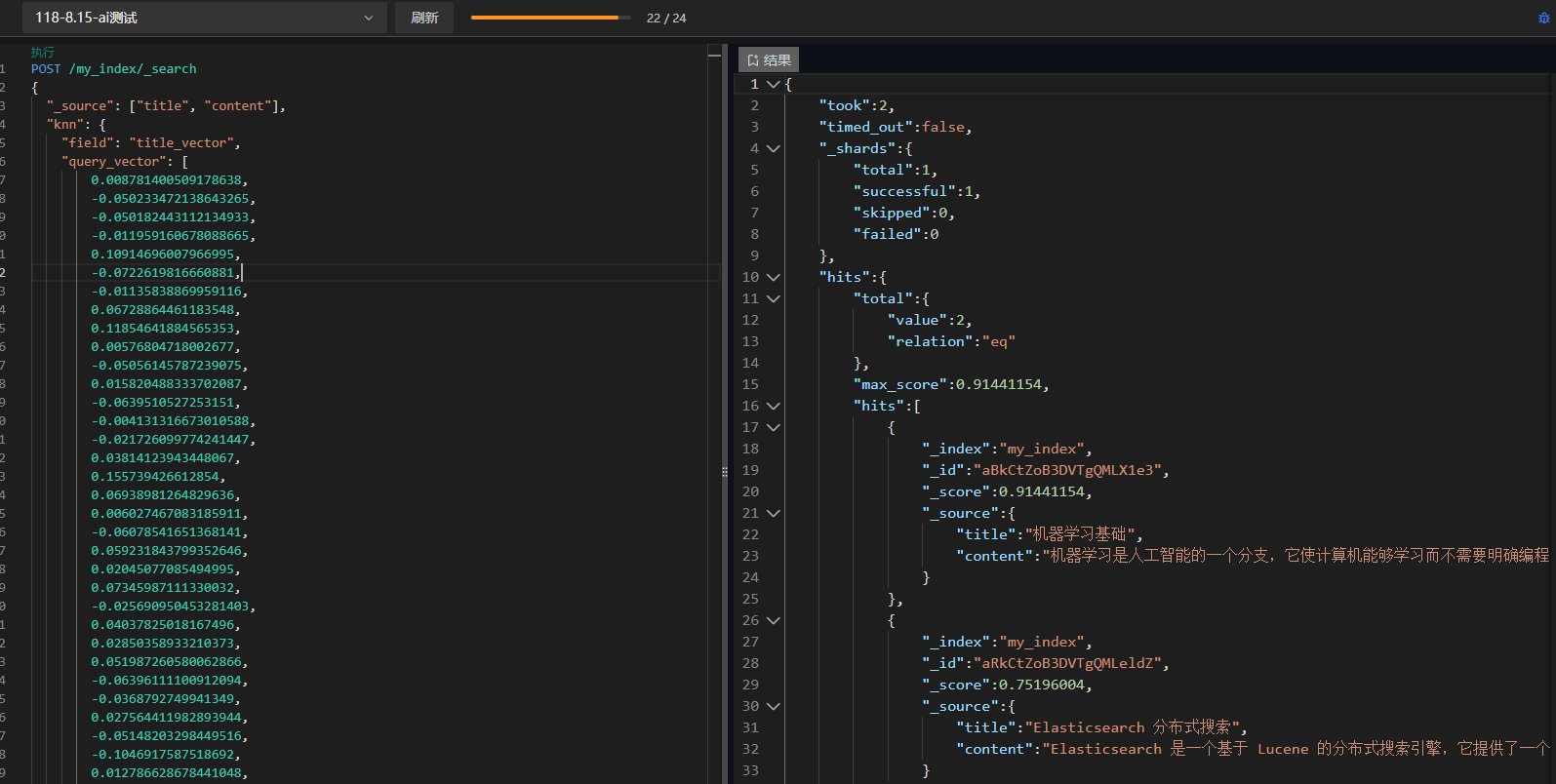
基本 kNN 查询:
json
POST /my_index/_search
{
"_source": ["title", "content"],
"knn": {
"field": "title_vector",
"query_vector": [ // machine learning
0.008781400509178638,
-0.050233472138643265,
-0.050182443112134933
...
],
"k": 2,
"num_candidates": 4
}
}参数说明:
field:向量字段名query_vector:查询向量k:返回 Top-K 结果num_candidates:候选数量,越大召回率越高但速度越慢(建议 >= 2k)
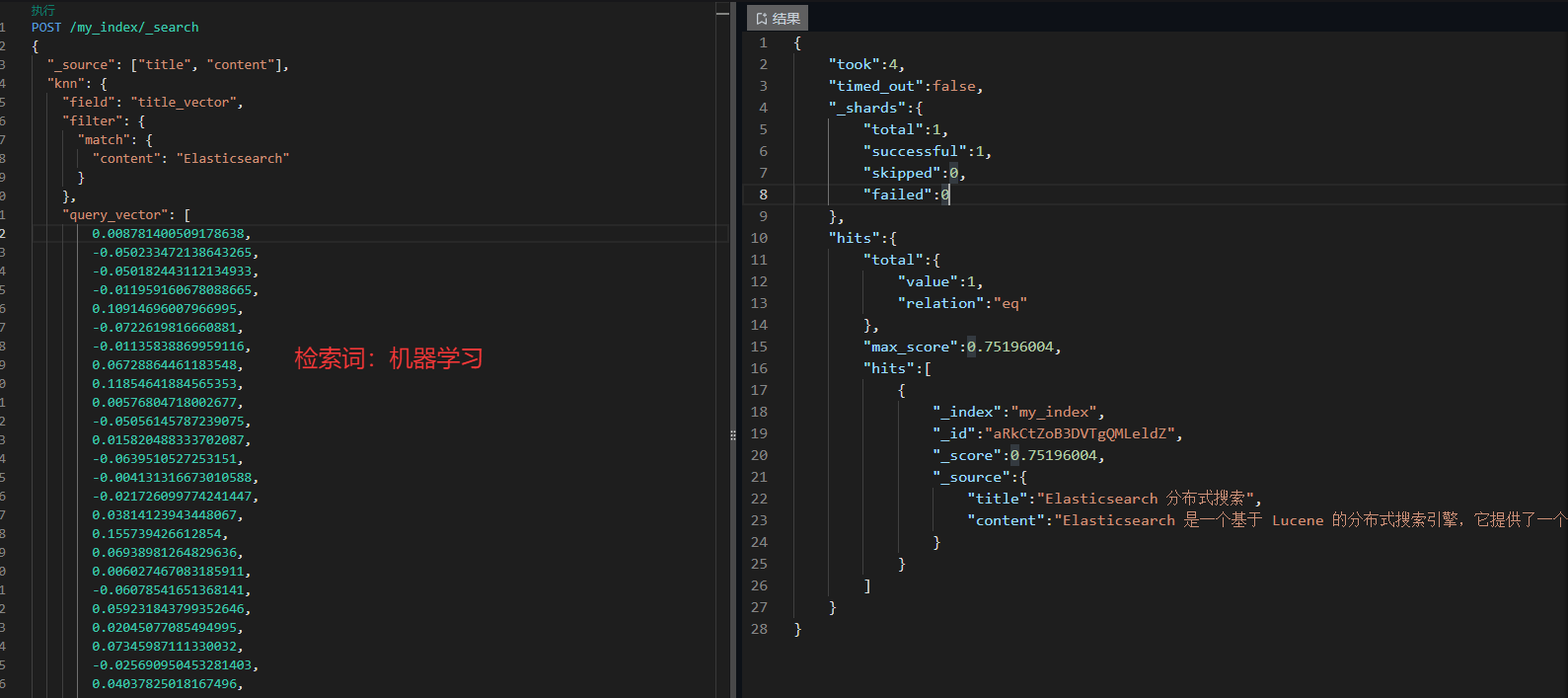
检索结果:检索词machine learning,得分相关度最高为机器学习基础
带过滤条件的 kNN 查询:
json
POST /my_index/_search
{
"knn": {
"field": "content_vector",
"query_vector": [0.1, 0.2, 0.3, ...],
"k": 10,
"num_candidates": 100,
"filter": {
"term": {
"category": "技术文档"
}
}
}
}
3.1.3 向量维度选择
常见维度及其特点:
| 维度 | 存储空间 | 搜索速度 | 精度 | 适用场景 |
|---|---|---|---|---|
| 128 | 小 | 快 | 中等 | 对精度要求不高的场景 |
| 384 | 中等 | 中等 | 高 | 通用推荐(SBERT mini) |
| 768 | 大 | 慢 | 很高 | 高精度要求 |
| 1536 | 很大 | 很慢 | 非常高 | OpenAI embeddings |
选择建议:
- 数据量 < 100万:可选择 768 或更高维度
- 数据量 100万 - 1000万:建议 384 维度
- 数据量 > 1000万:建议 256 或 384 维度,考虑降维
3.2 文本向量化方案
3.2.1 集成外部向量化服务
架构模式:
应用程序 → 向量化服务 → Elasticsearch
↓
[批量处理队列]使用 Spring Boot 构建向量化服务:
向量化服务使用:GTE-multilingual-base 本地向量服务部署与 Spring AI 集成方案-CSDN博客
java
/**
* 批量将文本转换为向量
* <p>
* 支持自动重试机制,最多重试3次,采用指数退避策略。
* </p>
*
* @param texts 待向量化的文本列表
* @return 向量列表
*/
public List<float[]> embedTexts(List<String> texts) {
if (texts == null || texts.isEmpty()) {
return new ArrayList<>();
}
int maxRetries = 3;
int retryDelay = 1000; // 初始延迟 1秒
for (int attempt = 1; attempt <= maxRetries; attempt++) {
try {
String url = appConfig.getEmbeddingServiceUrl() + "/embed_batch";
log.info("[向量化] 调用本地 embedding 服务: {}, 文本数量: {}, 尝试次数: {}/{}",
url, texts.size(), attempt, maxRetries);
// 计算请求大小
long totalChars = texts.stream().mapToLong(String::length).sum();
log.debug("[向量化] 请求文本总字符数: {}", totalChars);
// 构建请求体
Map<String, Object> requestBody = new HashMap<>();
requestBody.put("texts", texts);
// 设置请求头
HttpHeaders headers = new HttpHeaders();
headers.setContentType(MediaType.APPLICATION_JSON);
headers.set("Connection", "keep-alive");
HttpEntity<Map<String, Object>> request = new HttpEntity<>(requestBody, headers);
// 发送 POST 请求
ResponseEntity<EmbedBatchResponse> response = restTemplate.postForEntity(
url,
request,
EmbedBatchResponse.class
);
EmbedBatchResponse body = response.getBody();
if (body == null || body.getEmbeddings() == null || body.getEmbeddings().isEmpty()) {
log.error("[向量化] 向量化服务返回结果为空");
throw new RuntimeException("向量化服务返回结果为空");
}
log.info("[向量化] 成功,返回 {} 个向量,维度: {}", body.getCount(), body.getDimension());
// 将 List<List<Double>> 转换为 List<float[]>
List<float[]> result = new ArrayList<>();
for (List<Double> embedding : body.getEmbeddings()) {
float[] floatArray = new float[embedding.size()];
for (int i = 0; i < embedding.size(); i++) {
floatArray[i] = embedding.get(i).floatValue();
}
result.add(floatArray);
}
return result;
} catch (ResourceAccessException e) {
if (attempt == maxRetries) {
log.error("[向量化] 失败,已达最大重试次数 {}", maxRetries, e);
throw new RuntimeException("批量文本向量化失败(连接错误): " + e.getMessage() +
"。请检查向量化服务是否正常运行: " + appConfig.getEmbeddingServiceUrl(), e);
}
log.warn("[向量化] 第 {} 次尝试失败(连接错误),{}ms 后重试: {}",
attempt, retryDelay, e.getMessage());
try {
Thread.sleep(retryDelay);
retryDelay *= 2; // 指数退避
} catch (InterruptedException ie) {
Thread.currentThread().interrupt();
throw new RuntimeException("重试被中断", ie);
}
} catch (Exception e) {
log.error("[向量化] 失败,文本数量: {}", texts.size(), e);
throw new RuntimeException("批量文本向量化失败: " + e.getMessage(), e);
}
}
throw new RuntimeException("批量文本向量化失败:未知错误");
}3.2.2 Elasticsearch Inference API
Elasticsearch 8.8+ 支持内置的推理 API,可以直接调用机器学习模型。
配置推理模型:
json
PUT _ml/trained_models/sentence-transformers
{
"input": {
"field_names": ["text"]
},
"inference_config": {
"text_embedding": {}
}
}使用推理处理器自动向量化:
json
PUT _ingest/pipeline/text-embeddings
{
"description": "Text embedding pipeline",
"processors": [
{
"inference": {
"model_id": "sentence-transformers",
"target_field": "text_embedding",
"field_map": {
"content": "text"
}
}
}
]
}索引时自动生成向量:
json
POST /my_index/_doc?pipeline=text-embeddings
{
"content": "这是一段需要向量化的文本"
}3.3 混合搜索策略
混合搜索结合了语义搜索和传统关键词搜索的优势。
3.3.1 语义搜索 + 关键词搜索
基本混合查询:
json
POST /my_index/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"content": {
"query": "Elasticsearch 教程",
"boost": 1.0
}
}
}
]
}
},
"knn": {
"field": "content_vector",
"query_vector": [0.1, 0.2, ...],
"k": 10,
"num_candidates": 100,
"boost": 2.0
}
}参数说明:
boost:调整语义搜索和关键词搜索的权重比例- 语义搜索 boost 越大,越重视语义相关性
- 关键词搜索 boost 越大,越重视精确匹配
3.3.3 混合搜索最佳实践
场景一:精确匹配优先
json
{
"query": {
"match": {
"title": {
"query": "iPhone 15 Pro",
"boost": 3.0
}
}
},
"knn": {
"field": "description_vector",
"query_vector": [...],
"k": 10,
"num_candidates": 100,
"boost": 1.0
}
}场景二:语义理解优先
json
{
"query": {
"match": {
"content": {
"query": "如何提升代码质量",
"boost": 0.5
}
}
},
"knn": {
"field": "content_vector",
"query_vector": [...],
"k": 10,
"num_candidates": 100,
"boost": 3.0
}
}参考资源
官方文档
-
Elasticsearch 官方文档
-
Sentence-BERT
-
OpenAI Embeddings
技术博客与教程
- 什么是语义搜索?| Elastic
- 混合搜索最佳实践
- LangChain RAG Tutorial
- HNSW 算法详解
- 向量数据库对比
- ANN Benchmarks
- Hugging Face Transformers
- Sentence Transformers
r.html)
-
Sentence-BERT
-
OpenAI Embeddings