1. 需求简介
读取下面表格数据
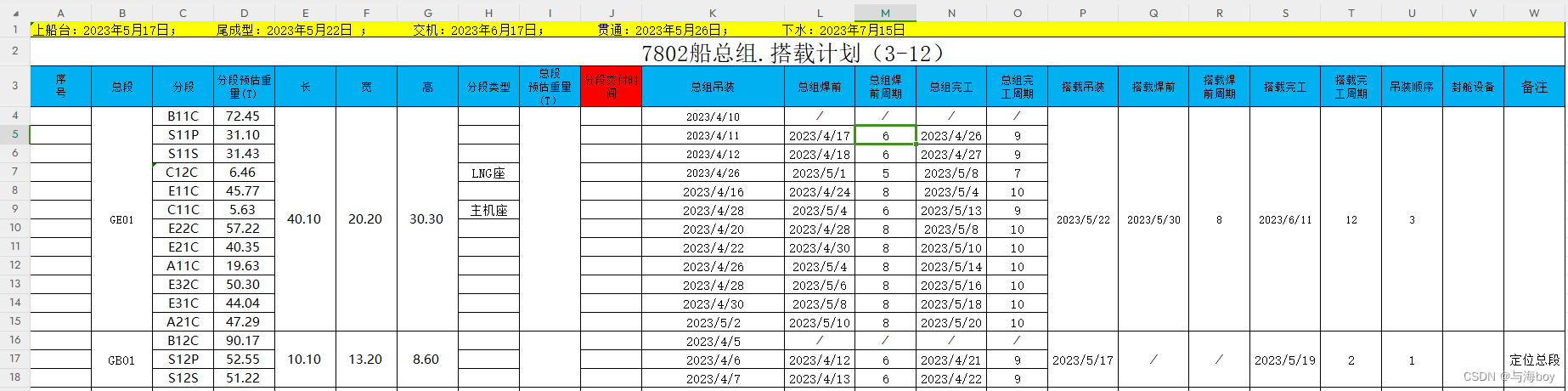
第一行和第二行是计划信息
第三行 是计划详情的抬头信息 ,以下行是计划详情信息
总段包含多个分段,总段使用了单元格合并功能
2. 实现读取功能
2.1 引入easyexcel依赖
java
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>easyexcel</artifactId>
<version>3.1.0</version>
</dependency>2.2 创建计划详情行信息对象
java
package com.gkdz.server.modules.shipyard.domain;
import com.alibaba.excel.annotation.ExcelIgnore;
import com.alibaba.excel.annotation.ExcelProperty;
import lombok.EqualsAndHashCode;
import lombok.Getter;
import lombok.Setter;
import java.util.Date;
@Getter
@Setter
@EqualsAndHashCode
public class Summary {
@ExcelProperty(value = "序号", index = 0)
private String number;
@ExcelProperty(value = "总段", index = 1)
private String totalSection;
@ExcelProperty(value = "分段", index = 2)
private String subSection;
@ExcelProperty(value = "分段预估重量(T)", index = 3)
private Double subExpectWeight;
@ExcelProperty(value = "长", index = 4)
private Double length;
@ExcelProperty(value = "宽", index = 5)
private Double width;
@ExcelProperty(value = "高", index = 6)
private Double height;
@ExcelProperty(value = "分段类型", index = 7)
private String type;
@ExcelProperty(value = "总段预估重量(T)", index = 8)
private Double totalExpectWeight;
@ExcelProperty(value = "分段交付时间", index = 9)
private String subSectionDeliveryTime;
@ExcelProperty(value = "总组吊装日期", index = 10)
private String hoistDate;
@ExcelProperty(value = "总组焊前", index = 11)
private String totalBeWeldDate;
@ExcelProperty(value = "总组焊前周期", index = 12)
private String totalBeWeldCycle;
@ExcelProperty(value = "总组完工日期", index = 13)
private String totalCompletionDate;
@ExcelProperty(value = "总组完工周期", index = 14)
private String totalCompletionCycle;
@ExcelProperty(value = "搭载吊装日期", index = 15)
private String carryLiftDate;
@ExcelProperty(value = "搭载焊前日期", index = 16)
private String carryBeWeldDate;
@ExcelProperty(value = "搭载焊前周期", index = 17)
private String carryBeWeldCycle;
@ExcelProperty(value = "搭载完工日期", index = 18)
private String carryCompletionDate;
@ExcelProperty(value = "搭载完工周期", index = 19)
private String carryCompletionCycle;
@ExcelProperty(value = "吊装顺序", index = 20)
private String hoistOrder;
@ExcelProperty(value = "封舱设备", index = 21)
private String sealingEquipment;
@ExcelProperty(value = "备注", index = 22)
private String remark;
//标记,用于分组,ExcelIgnore为忽略注解
@ExcelIgnore
private String elementStr;
/**行号*/
@ExcelIgnore
private int rowNo;
}2.3 读取execl工具类
java
package com.gkdz.server.modules.shipyard.util;
import cn.hutool.core.util.ObjectUtil;
import cn.hutool.core.util.StrUtil;
import com.alibaba.excel.EasyExcel;
import com.alibaba.excel.annotation.ExcelProperty;
import com.alibaba.excel.context.AnalysisContext;
import com.alibaba.excel.enums.CellExtraTypeEnum;
import com.alibaba.excel.metadata.CellExtra;
import com.alibaba.excel.metadata.data.ReadCellData;
import com.alibaba.excel.read.listener.ReadListener;
import com.alibaba.fastjson.JSON;
import com.gkdz.server.modules.shipyard.domain.Summary;
import lombok.extern.slf4j.Slf4j;
import org.springframework.web.multipart.MultipartFile;
import java.io.IOException;
import java.lang.reflect.Field;
import java.math.BigDecimal;
import java.util.*;
@Slf4j
public class EasyExcelUtil {
/**
* 计划详情正文起始行
*/
private static final Integer headRowNumber = 3;
/**
* 分组切割符号
*/
public static final String splitFlag = "<zld>";
public static Map<String, List> uploadByFile(MultipartFile file) throws IOException {
Map<String, List> map = new HashMap<>();
//正文行数据
List<Summary> saveList = new ArrayList<>();
//抬头行数据
List<String> planInfoList = new ArrayList<>();
//合并单元格数据
List<CellExtra> extraMergeInfoList = new ArrayList<>();
EasyExcel.read(file.getInputStream(), Summary.class, new ReadListener<Summary>() {
/**
* 读取表格抬头行数据,默认为读第一行;
* 可设置headRowNumber(headRowNumber):抬头行为前headRowNumber行
* @param headMap
* @param context
*/
@Override
public void invokeHead(Map<Integer, ReadCellData<?>> headMap, AnalysisContext context) {
planInfoList.add(headMap.get(0).getStringValue());
}
/**
* 读取非抬头行数据
* @param data 行数据格式,自定义,默认为Object
* @param analysisContext
*/
@Override
public void invoke(Summary data, AnalysisContext analysisContext) {
if (StrUtil.isEmptyIfStr(data.getTotalSection())) {
data.setTotalSection(data.getSubSection());
}
saveList.add(data);
}
/**
*
* @param extra
* @param context
*/
@Override
public void extra(CellExtra extra, AnalysisContext context) {
log.info("读取到了一条额外信息:{}", JSON.toJSONString(extra));
switch (extra.getType()) {
case COMMENT: {
log.info("额外信息是批注,在rowIndex:{},columnIndex;{},内容是:{}", extra.getRowIndex(), extra.getColumnIndex(),
extra.getText());
break;
}
case HYPERLINK: {
if ("Sheet1!A1".equals(extra.getText())) {
log.info("额外信息是超链接,在rowIndex:{},columnIndex;{},内容是:{}", extra.getRowIndex(),
extra.getColumnIndex(), extra.getText());
} else if ("Sheet2!A1".equals(extra.getText())) {
log.info(
"额外信息是超链接,而且覆盖了一个区间,在firstRowIndex:{},firstColumnIndex;{},lastRowIndex:{},lastColumnIndex:{},"
+ "内容是:{}",
extra.getFirstRowIndex(), extra.getFirstColumnIndex(), extra.getLastRowIndex(),
extra.getLastColumnIndex(), extra.getText());
} else {
log.error("Unknown hyperlink!");
}
break;
}
case MERGE: {
if (extra.getRowIndex() >= headRowNumber) {
extraMergeInfoList.add(extra);
}
break;
}
default: {
}
}
}
/**
* 数据读取完毕后执行的方法,可做数据整体处理
* @param analysisContext
*/
@Override
public void doAfterAllAnalysed(AnalysisContext analysisContext) {
}
}).extraRead(CellExtraTypeEnum.MERGE).sheet().headRowNumber(headRowNumber).doRead();
final List<Summary> summaries = ExcelSplitUtil.explainMergeData(saveList, extraMergeInfoList, headRowNumber);
map.put("planInfo", planInfoList);
map.put("summary", summaries);
return map;
}
/**
* 根据easyexcel注解给指定实体赋值
*
* @param objects 读取的表格内容
* @param clazz 需转化的实体
* @param <T> 实体
* @return 需转化的提示集合
*/
public static <T> List<T> convertList(List<LinkedHashMap> objects, Class<T> clazz) {
List<T> results = new ArrayList<>(objects.size());
try {
Map<String, Field> objIndex = new HashMap<>();
// 获取转化实体字段信息集合
Field[] fields = clazz.getDeclaredFields();
for (Field field : fields) {
// 根据实体上Easy Excel的ExcelProperty注解中的索引值对应excel读取数据的值
int index = field.getAnnotation(ExcelProperty.class).index();
// 设置字段可编辑
field.setAccessible(true);
objIndex.put(String.valueOf(index), field);
}
T obj = null;
for (LinkedHashMap o : objects) {
obj = clazz.newInstance();
for (Object key : o.keySet()) {
// 如果表格索引与字段注解指定索引一样则赋值
if (objIndex.containsKey(key)) {
Object object = o.get(key);
Object value = null;
Field field = objIndex.get(key);
if (ObjectUtil.isEmpty(object)) {
continue;
}
Class<?> type = field.getType();
String replace = object.toString();
// 有特殊需要处理的字段类型则在此进行处理
if (type == BigDecimal.class) {
value = "--".equals(replace) ? null : new BigDecimal(replace.replace(",", ""));
} else if (type == Integer.class) {
// String强转Integer会报错,所以需要单独进行转化
value = "--".equals(replace) ? null : Integer.valueOf(replace.replace(",", ""));
} else {
value = object;
}
field.set(obj, value);
}
}
results.add(obj);
}
} catch (Exception e) {
log.error("字段解析失败", e);
}
return results;
}
}2.4 拆分单元格工具
java
package com.gkdz.server.modules.shipyard.util;
import com.alibaba.excel.annotation.ExcelProperty;
import com.alibaba.excel.metadata.CellExtra;
import com.gkdz.server.modules.shipyard.domain.Summary;
import lombok.extern.slf4j.Slf4j;
import java.lang.reflect.Field;
import java.util.List;
/**
* @description:拆分单元格数据
*/
@Slf4j
public class ExcelSplitUtil {
/**
* 处理合并单元格
*
* @param data 解析数据
* @param extraMergeInfoList 合并单元格信息
* @param headRowNumber 起始行
* @return 填充好的解析数据
*/
public static List<Summary> explainMergeData(List<Summary> data, List<CellExtra> extraMergeInfoList, Integer headRowNumber) {
// 循环所有合并单元格信息
extraMergeInfoList.forEach(cellExtra -> {
int firstRowIndex = cellExtra.getFirstRowIndex() - headRowNumber;
int lastRowIndex = cellExtra.getLastRowIndex() - headRowNumber;
int firstColumnIndex = cellExtra.getFirstColumnIndex();
int lastColumnIndex = cellExtra.getLastColumnIndex();
// 获取初始值
Object initValue = getInitValueFromList(firstRowIndex, firstColumnIndex, data);
// 设置值
for (int i = firstRowIndex; i <= lastRowIndex; i++) {
for (int j = firstColumnIndex; j <= lastColumnIndex; j++) {
setInitValueToList(initValue, i, j, data);
}
}
});
return data;
}
/**
* 设置合并单元格的值
*
* @param filedValue 值
* @param rowIndex 行
* @param columnIndex 列
* @param data 解析数据
*/
private static void setInitValueToList(Object filedValue, Integer rowIndex, Integer columnIndex, List<Summary> data) {
Summary object = data.get(rowIndex);
for (Field field : object.getClass().getDeclaredFields()) {
//提升反射性能,关闭安全检查
field.setAccessible(true);
ExcelProperty annotation = field.getAnnotation(ExcelProperty.class);
if (annotation != null) {
if (annotation.index() == columnIndex) {
try {
field.set(object, filedValue);
break;
} catch (IllegalAccessException e) {
log.error("解析数据时发生异常!");
}
}
}
}
}
/**
* 获取合并单元格的初始值
* rowIndex对应list的索引
* columnIndex对应实体内的字段
*
* @param firstRowIndex 起始行
* @param firstColumnIndex 起始列
* @param data 列数据
* @return 初始值
*/
private static Object getInitValueFromList(Integer firstRowIndex, Integer firstColumnIndex, List<Summary> data) {
Object filedValue = null;
Summary object = data.get(firstRowIndex);
for (Field field : object.getClass().getDeclaredFields()) {
//提升反射性能,关闭安全检查
field.setAccessible(true);
ExcelProperty annotation = field.getAnnotation(ExcelProperty.class);
if (annotation != null) {
if (annotation.index() == firstColumnIndex) {
try {
filedValue = field.get(object);
break;
} catch (IllegalAccessException e) {
log.error("解析数据时发生异常!");
}
}
}
}
return filedValue;
}
}