1 数量窗
1.1 数量滚动窗口
0基础学习PyFlink------个数滚动窗口(Tumbling Count Windows)
1.1.1 代码分析
Tumbling Count Windows是指按元素个数计数的滚动窗口。
滚动窗口是指没有元素重叠的窗口。
(1)构造了一个KeyedStream,用于存储word_count_data中的数据。
bash
word_count_data = [("A",), ("A", ), ("B", ), ("A",)]
def word_count():
env = StreamExecutionEnvironment.get_execution_environment()
env.set_runtime_mode(RuntimeExecutionMode.STREAMING)
env.set_parallelism(1) # 将所有数据写到一个文件
source_type_info = Types.TUPLE([Types.STRING()])
# 从列表生成source,指定列表中每个元素的类型
source = env.from_collection(word_count_data, source_type_info)
# 按键分组
keyed_stream = source.key_by(lambda i: i[0])我们并没有让Source是流的形式,是因为为了降低例子复杂度。但是我们将runntime mode设置为流(STREAMING)模式。
(2)定义一个Reduce类,用于对元组中的数据进行计算。
这个类需要继承于WindowFunction,并实现相应方法(本例中是apply)。
apply会计算一个相同key的元素个数。
bash
class SumWindowFunction(WindowFunction[tuple, tuple, str, CountWindow]):
def apply(self, key: str, window: CountWindow, inputs: Iterable[tuple]):
print(inputs, window)
return [(key, len(inputs))](3)keyed_stream.count_window(2)将此keyyedstream窗口转换为滚动计数窗口或滑动计数窗口。
bash
out_type_info = Types.TUPLE([Types.STRING(), Types.INT()])
reduced = (keyed_stream.count_window(2)
.apply(SumWindowFunction(), out_type_info))1.1.2 整体代码
bash
from typing import Iterable
from pyflink.common import Types
from pyflink.datastream import StreamExecutionEnvironment, RuntimeExecutionMode, WindowFunction
from pyflink.datastream.window import CountWindow
class SumWindowFunction(WindowFunction[tuple, tuple, str, CountWindow]):
def apply(self, key: str, window: CountWindow, inputs: Iterable[tuple]):
print(inputs, window)
return [(key, len(inputs))]
word_count_data = [("A",), ("A", ), ("B", ), ("A",)]
def word_count():
env = StreamExecutionEnvironment.get_execution_environment()
env.set_runtime_mode(RuntimeExecutionMode.STREAMING)
env.set_parallelism(1) # 将所有数据写到一个文件
source_type_info = Types.TUPLE([Types.STRING()])
# 从列表生成source,指定列表中每个元素的类型
source = env.from_collection(word_count_data, source_type_info)
# 按键分组
keyed_stream = source.key_by(lambda i: i[0])
# reducing
out_type_info = Types.TUPLE([Types.STRING(), Types.INT()])
reduced = (keyed_stream.count_window(4)
.apply(SumWindowFunction(), out_type_info))
# # define the sink
reduced.print()
# submit for execution
env.execute()
if __name__ == '__main__':
word_count()1.1.3 结果
(1)window=1,
A的个数是3,被3个窗口承载
B的个数是1,被1个窗口承载

(2)window=2
A的个数是3,但是会产生两个窗口,第一个窗口承载了前两个元素,第二个窗口当前只有一个元素。于是第一个窗口进行了Reduce计算,得出一个(A,2);第二个窗口还没进行reduce计算,就没有展现出结果;
B的个数是1,被1个窗口承载,只有一个元素,还没进行reduce计算,没有展示结果。

(3)window=3
A的个数是3,被1个窗口承载,有3个元素;
B的个数是1,被1个窗口承载,只有一个元素,还没进行reduce计算,没有展示结果。
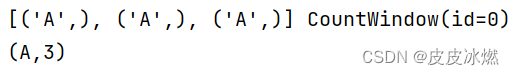
(4)window=4
A的个数是3,被1个窗口承载,只有3个元素,还没进行reduce计算,没有展示结果。
B的个数是1,被1个窗口承载,只有1个元素,还没进行reduce计算,没有展示结果。
输出空
1.2 数量滑动窗口
0基础学习PyFlink------个数滑动窗口(Sliding Count Windows)
1.2.1 整体代码
"滑动"是指这个窗口沿着一定的方向,按着一定的速度"滑行"。
滚动窗口,则是一个个"衔接着",而不是像上面那样交错着。
它们的相同之处就是:只有窗口内的事件数量到达窗口要求的数值时,这些窗口才会触发计算。
bash
from typing import Iterable
from pyflink.common import Types
from pyflink.datastream import StreamExecutionEnvironment, RuntimeExecutionMode, WindowFunction
from pyflink.datastream.window import CountWindow
class SumWindowFunction(WindowFunction[tuple, tuple, str, CountWindow]):
def apply(self, key: str, window: CountWindow, inputs: Iterable[tuple]):
print(inputs, window)
return [(key, len(inputs))]
word_count_data = [("A",), ("A", ), ("B", ), ("A",)]
def word_count():
env = StreamExecutionEnvironment.get_execution_environment()
env.set_runtime_mode(RuntimeExecutionMode.STREAMING)
env.set_parallelism(1) # 将所有数据写到一个文件
source_type_info = Types.TUPLE([Types.STRING()])
# 从列表生成source,指定列表中每个元素的类型
source = env.from_collection(word_count_data, source_type_info)
# 按键分组
keyed_stream = source.key_by(lambda i: i[0])
# reducing
out_type_info = Types.TUPLE([Types.STRING(), Types.INT()])
reduced = (keyed_stream.count_window(2,1)
.apply(SumWindowFunction(), out_type_info))
# # define the sink
reduced.print()
# submit for execution
env.execute()
if __name__ == '__main__':
word_count()1.2.2 结果
(1)window=1,slide=1

(2)window=2,slide=1
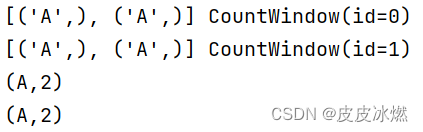
(3)window=1,slide=2

2 时间窗
2.1 时间滚动窗口(处理时间)
参考0基础学习PyFlink------时间滚动窗口(Tumbling Time Windows)
对于数量滚动窗口,如果窗口内元素数量没有达到窗口大小时,计算个数的函数是不会被调用的。
如果想让不满足数量的窗口,也执行计算,就可以使用时间滚动窗口。
它不依赖于窗口中元素的个数,而是窗口的时间,即窗口时间到了,计算就会进行。
2.1.1 代码分析
(1)构造了一个KeyedStream,用于存储word_count_data中的数据。
bash
word_count_data = [("A",), ("A", ), ("B", ), ("A",), ("A", ), ("B", ), ("A",)]
def word_count():
env = StreamExecutionEnvironment.get_execution_environment()
env.set_runtime_mode(RuntimeExecutionMode.STREAMING)
env.set_parallelism(1) # 将所有数据写到一个文件
source_type_info = Types.TUPLE([Types.STRING()])
# 从列表生成source,指定列表中每个元素的类型
source = env.from_collection(word_count_data, source_type_info)
# 按键分组
keyed_stream = source.key_by(lambda i: i[0])我们并没有让Source是流的形式,是因为为了降低例子复杂度。但是我们将runntime mode设置为流(STREAMING)模式。
(2)定义一个Reduce类,用于对元组中的数据进行计算。
这个类需要继承于WindowFunction,并实现相应方法(本例中是apply)。
apply会计算一个相同key的元素个数。
bash
class SumWindowFunction(WindowFunction[tuple, tuple, str, TimeWindow]):
def apply(self, key: str, window: TimeWindow, inputs: Iterable[tuple]):
print(inputs, window)
return [(key, len(inputs))](3)这儿我们的Window使用的是滚动时间窗口(处理时间),其中参数Time.milliseconds(2)是指窗口时长,即2毫秒一个窗口。
bash
# reducing
out_type_info = Types.TUPLE([Types.STRING(), Types.INT()])
reduced = (keyed_stream\
.window(TumblingProcessingTimeWindows.of(Time.milliseconds(2)))\
.apply(SumWindowFunction(), out_type_info))
# define the sink
reduced.print()
# submit for execution
env.execute()2.1.2 整体代码
bash
from typing import Iterable
from pyflink.common import Types, Time
from pyflink.datastream import StreamExecutionEnvironment, RuntimeExecutionMode, WindowFunction
from pyflink.datastream.window import TimeWindow, TumblingProcessingTimeWindows
class SumWindowFunction(WindowFunction[tuple, tuple, str, TimeWindow]):
def apply(self, key: str, window: TimeWindow, inputs: Iterable[tuple]):
print(inputs, window)
return [(key, len(inputs))]
word_count_data = [("A",), ("A", ), ("B", ), ("A",), ("A", ), ("B", ), ("A",)]
def word_count():
env = StreamExecutionEnvironment.get_execution_environment()
env.set_runtime_mode(RuntimeExecutionMode.STREAMING)
env.set_parallelism(1) # 将所有数据写到一个文件
source_type_info = Types.TUPLE([Types.STRING()])
# 从列表生成source,指定列表中每个元素的类型
source = env.from_collection(word_count_data, source_type_info)
# 按键分组
keyed_stream = source.key_by(lambda i: i[0])
# reducing
out_type_info = Types.TUPLE([Types.STRING(), Types.INT()])
reduced = (keyed_stream\
.window(TumblingProcessingTimeWindows.of(Time.milliseconds(2)))\
.apply(SumWindowFunction(), out_type_info))
# define the sink
reduced.print()
# submit for execution
env.execute()
if __name__ == '__main__':
word_count()2.1.3 结果
运行多次代码可以得到不同的结果。
可以发现结果并不稳定。但是可以发现,每个元素都参与了计算,而不像数量滚动窗口那样部分数据没有被触发计算。
这是因为每次运行时,CPU等系统资源的繁忙程度是不一样的,这就影响了最后的运行结果。
(1)第一次运行
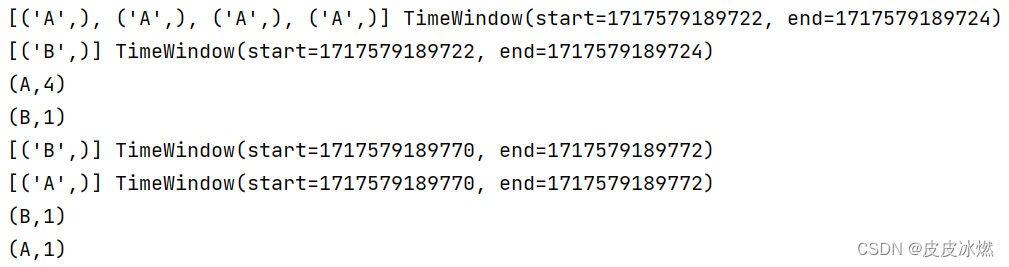
(2)第二次运行

(3)第三次运行
2.2 时间滑动窗口(处理时间)
0基础学习PyFlink------时间滑动窗口(Sliding Time Windows)
2.2.1 整体代码
bash
from typing import Iterable
from pyflink.common import Types, Time
from pyflink.datastream import StreamExecutionEnvironment, RuntimeExecutionMode, WindowFunction
from pyflink.datastream.window import TimeWindow, SlidingProcessingTimeWindows
class SumWindowFunction(WindowFunction[tuple, tuple, str, TimeWindow]):
def apply(self, key: str, window: TimeWindow, inputs: Iterable[tuple]):
print(inputs, window)
return [(key, len(inputs))]
word_count_data = [("A",), ("A", ), ("B", ), ("A",), ("A", ), ("B", ), ("A",)]
def word_count():
env = StreamExecutionEnvironment.get_execution_environment()
env.set_runtime_mode(RuntimeExecutionMode.STREAMING)
env.set_parallelism(1) # 将所有数据写到一个文件
source_type_info = Types.TUPLE([Types.STRING()])
# 从列表生成source,指定列表中每个元素的类型
source = env.from_collection(word_count_data, source_type_info)
# 按键分组
keyed_stream = source.key_by(lambda i: i[0])
# reducing
out_type_info = Types.TUPLE([Types.STRING(), Types.INT()])
reduced = (keyed_stream\
.window(SlidingProcessingTimeWindows.of(Time.milliseconds(2),Time.milliseconds(1)))\
.apply(SumWindowFunction(), out_type_info))
# define the sink
reduced.print()
# submit for execution
env.execute()
if __name__ == '__main__':
word_count()2.2.2 结果
运行两次上述代码,我们发现每次都不同,而且有重叠计算的元素。
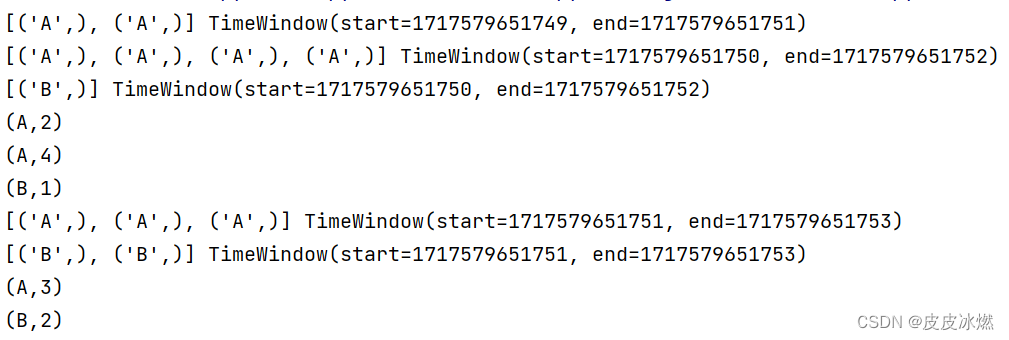
(1)第一次运行
A:9,B:3
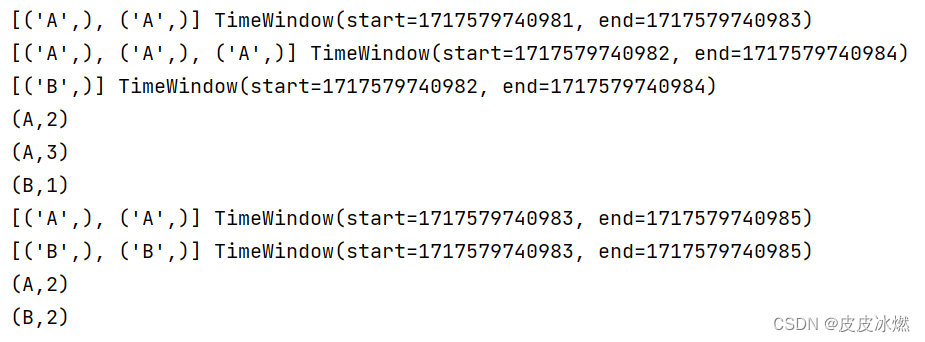
(2)第二次运行
A:7,B:3
4.3 时间滚动窗口(事件时间)
0基础学习PyFlink------事件时间和运行时间的窗口
使用的是运行时间(Tumbling ProcessingTimeWindows)作为窗口的参考时间,得到的结果是不稳定的。
这是因为每次运行时,CPU等系统资源的繁忙程度是不一样的,这就影响了最后的运行结果。
为了让结果稳定,我们可以不依赖运行时间(ProcessingTime),而使用不依赖于运行环境,只依赖于数据的事件时间(EventTime)。
一般,我们需要大数据处理的数据,往往存在一个字段用于标志该条数据的"顺序"。
这个信息可以是单调递增的ID,也可以是不唯一的时间戳,我们可以将这类信息看做事件发生的时间。
那如何让输入的数据中的"事件时间"参与到窗口时长的计算中呢?这儿就要引入时间戳和Watermark(水位线)的概念 。
假如我们把数据看成一张纸上的内容,水位线则是这张纸的背景。它并不影响纸上内容的表达,只是系统要用它来做更多的事情。
将数据中表达"顺序"的数据转换成时间戳,我们可以使用水位线单调递增时间戳分配器。
2.3.1 代码分析
(1)构造了一个Stream,用于存储word_count_data中的数据。
bash
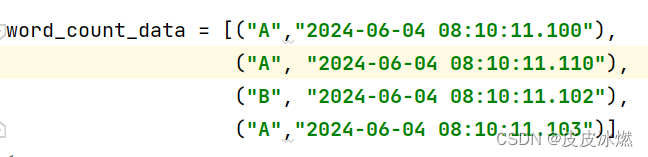
word_count_data = [("A","2024-06-04 08:10:11.100"),
("A", "2024-06-04 08:10:11.101"),
("B", "2024-06-04 08:10:11.102"),
("A","2024-06-04 08:10:11.103")]
def word_count():
env = StreamExecutionEnvironment.get_execution_environment()
env.set_runtime_mode(RuntimeExecutionMode.STREAMING)
env.set_parallelism(1) # 将所有数据写到一个文件
source_type_info = Types.TUPLE([Types.STRING(),Types.STRING()])
source = env.from_collection(word_count_data, source_type_info)(2)定制策略
bash
class ElementTimestampAssigner(TimestampAssigner):
def extract_timestamp(self, value, record_timestamp)-> int:
time_str = value[1]
dt = datetime.datetime.strptime(time_str, "%Y-%m-%d %H:%M:%S.%f")
ts_s = dt.timestamp() # 时间戳,单位秒
ts_ms = int(ts_s * 1000) # 时间戳,单位毫秒
return ts_ms
# 定义水位线策略
watermark_strategy = WatermarkStrategy.for_monotonous_timestamps() \
.with_timestamp_assigner(ElementTimestampAssigner())for_monotonous_timestamps会分配一个水位线单调递增时间戳分配器,然后使用with_timestamp_assigner告知输入数据中"顺序"字段的值。这样系统就会根据这个字段的值生成一个单调递增的时间戳。这个时间戳相对顺序就和输入数据一样,是稳定的。
(3)运行策略
然后对原始数据使用该策略,这样source_with_wartermarks中的数据就包含了时间戳。
bash
# 对原始数据使用该策略
source_with_wartermarks = source.assign_timestamps_and_watermarks(watermark_strategy)(4)使用TumblingEventTimeWindows,即事件时间(EventTime)窗口,而不是运行时间(ProcessingTime)窗口。
bash
# reducing
out_type_info = Types.TUPLE([Types.STRING(), Types.INT()])
reduced = (source_with_wartermarks.key_by(lambda i: i[0])\
.window(TumblingEventTimeWindows.of(Time.milliseconds(2)))\
.apply(SumWindowFunction(), out_type_info))
# # define the sink
reduced.print()
# submit for execution
env.execute()2.3.2 整体代码
bash
from typing import Iterable
from pyflink.common import Types, Time, WatermarkStrategy
from pyflink.common.watermark_strategy import TimestampAssigner
from pyflink.datastream import StreamExecutionEnvironment, RuntimeExecutionMode, WindowFunction
from pyflink.datastream.window import TimeWindow, TumblingEventTimeWindows
import datetime
class SumWindowFunction(WindowFunction[tuple, tuple, str, TimeWindow]):
def apply(self, key: str, window: TimeWindow, inputs: Iterable[tuple]):
print(inputs, window)
return [(key, len(inputs))]
class ElementTimestampAssigner(TimestampAssigner):
def extract_timestamp(self, value, record_timestamp)-> int:
time_str = value[1]
dt = datetime.datetime.strptime(time_str, "%Y-%m-%d %H:%M:%S.%f")
ts_s = dt.timestamp() # 时间戳,单位秒
ts_ms = int(ts_s * 1000) # 时间戳,单位毫秒
return ts_ms
word_count_data = [("A","2024-06-04 08:10:11.100"),
("A", "2024-06-04 08:10:11.110"),
("B", "2024-06-04 08:10:11.102"),
("A","2024-06-04 08:10:11.103")]
def word_count():
env = StreamExecutionEnvironment.get_execution_environment()
env.set_runtime_mode(RuntimeExecutionMode.STREAMING)
env.set_parallelism(1) # 将所有数据写到一个文件
source_type_info = Types.TUPLE([Types.STRING(),Types.STRING()])
source = env.from_collection(word_count_data, source_type_info)
# 定义水位线策略
watermark_strategy = WatermarkStrategy.for_monotonous_timestamps() \
.with_timestamp_assigner(ElementTimestampAssigner())
# 对原始数据使用该策略
source_with_wartermarks = source.assign_timestamps_and_watermarks(watermark_strategy)
# reducing
out_type_info = Types.TUPLE([Types.STRING(), Types.INT()])
reduced = (source_with_wartermarks.key_by(lambda i: i[0])\
.window(TumblingEventTimeWindows.of(Time.milliseconds(2)))\
.apply(SumWindowFunction(), out_type_info))
# # define the sink
reduced.print()
# submit for execution
env.execute()
if __name__ == '__main__':
word_count()2.3.3 结果
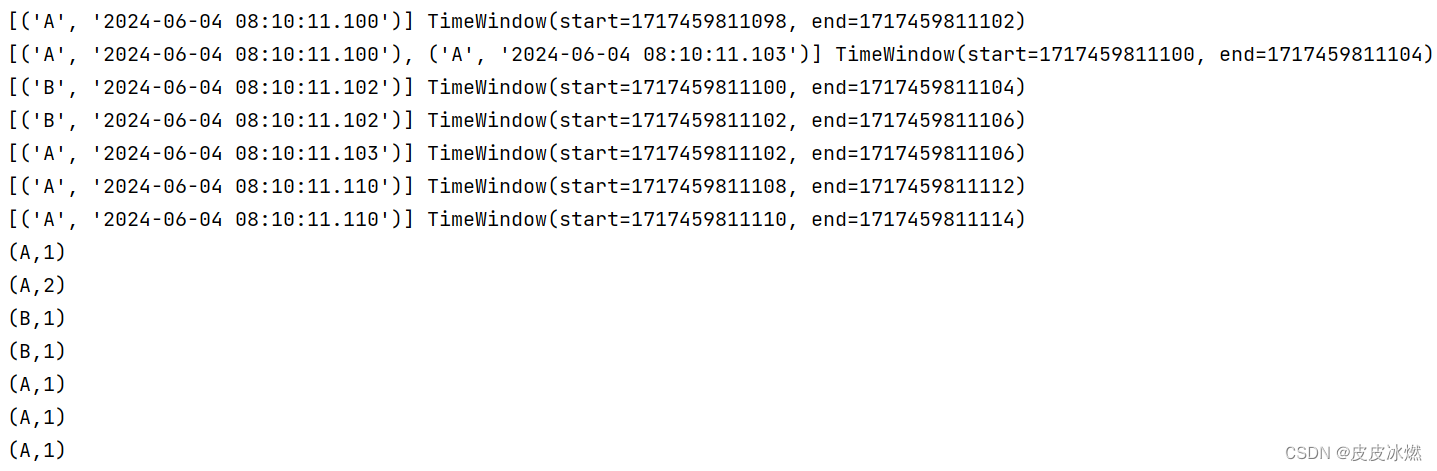
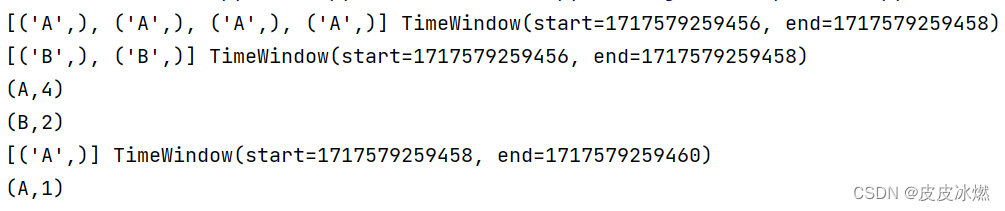
数据乱序也没关系,会自动排序。
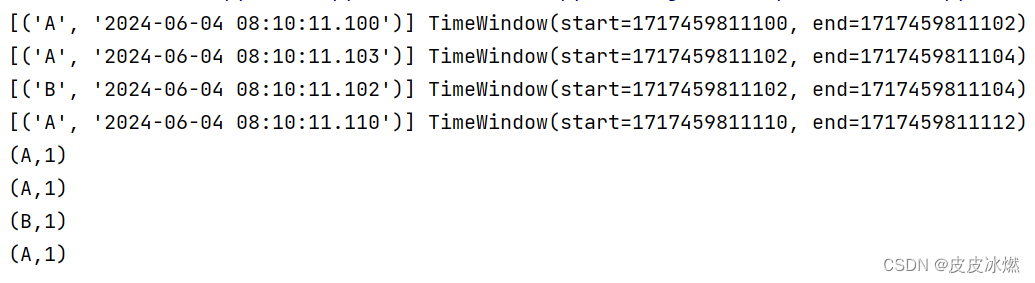
2.4 时间滑动窗口(事件时间)
2.4.1 整体代码
bash
from typing import Iterable
from pyflink.common import Types, Time, WatermarkStrategy
from pyflink.common.watermark_strategy import TimestampAssigner
from pyflink.datastream import StreamExecutionEnvironment, RuntimeExecutionMode, WindowFunction
from pyflink.datastream.window import TimeWindow, SlidingEventTimeWindows
import datetime
class SumWindowFunction(WindowFunction[tuple, tuple, str, TimeWindow]):
def apply(self, key: str, window: TimeWindow, inputs: Iterable[tuple]):
print(inputs, window)
return [(key, len(inputs))]
class ElementTimestampAssigner(TimestampAssigner):
def extract_timestamp(self, value, record_timestamp)-> int:
time_str = value[1]
dt = datetime.datetime.strptime(time_str, "%Y-%m-%d %H:%M:%S.%f")
ts_s = dt.timestamp() # 时间戳,单位秒
ts_ms = int(ts_s * 1000) # 时间戳,单位毫秒
return ts_ms
word_count_data = [("A","2024-06-04 08:10:11.100"),
("A", "2024-06-04 08:10:11.110"),
("B", "2024-06-04 08:10:11.102"),
("A","2024-06-04 08:10:11.103")]
def word_count():
env = StreamExecutionEnvironment.get_execution_environment()
env.set_runtime_mode(RuntimeExecutionMode.STREAMING)
env.set_parallelism(1) # 将所有数据写到一个文件
source_type_info = Types.TUPLE([Types.STRING(),Types.STRING()])
source = env.from_collection(word_count_data, source_type_info)
# 定义水位线策略
watermark_strategy = WatermarkStrategy.for_monotonous_timestamps() \
.with_timestamp_assigner(ElementTimestampAssigner())
# 对原始数据使用该策略
source_with_wartermarks = source.assign_timestamps_and_watermarks(watermark_strategy)
# reducing
out_type_info = Types.TUPLE([Types.STRING(), Types.INT()])
reduced = (source_with_wartermarks.key_by(lambda i: i[0])\
.window(SlidingEventTimeWindows.of(Time.milliseconds(4),Time.milliseconds(2)))\
.apply(SumWindowFunction(), out_type_info))
# # define the sink
reduced.print()
# submit for execution
env.execute()
if __name__ == '__main__':
word_count()2.4.2 结果