flink+dolphinscheduler+dinky打造自动化数仓平台
前言
Dinky ,让 Apache Flink 纵享丝滑!
在大数据技术日新月异的今天,实时数据处理能力已成为企业数字化转型的核心竞争力。 Dinky 作为一款基于 Apache Flink 打造的实时计算平台,正以"Dynamic"(动态化)、"Integration"(集成化)、"Native"(原生性)、"Keep"(持久性)和"Yield"(高产出)为核心理念,为开发者提供了一站式的流批一体开发体验。这个源自Apache孵化器的开源项目,通过可视化交互界面将复杂的 Flink 任务开发简化为 SQL 操作,支持从作业开发、调试到运维监控的全生命周期管理。其独创的 FlinkSQL Studio 不仅实现了多版本 Flink 兼容,更通过智能语法校验、血缘分析等创新功能,将实时数仓构建效率提升300%以上。在电商实时大屏、金融风控预警、 IoT 设备监控等场景中, Dinky 正在帮助企业突破传统批处理架构的延迟瓶颈,构建起毫秒级响应的智能决策系统,真正实现了"让实时计算触手可及"的技术愿景。
本文主要介绍以下几点内容:
Dinky的安装方法- 创建和执行
Flink作业 UDF (User-Defined Function)开发- 集成任务调度平台
DolphinScheduler Catalog管理 (Catalog持久化)
安装Dinky
数据库
首先给dinky创建一个mysql数据库
mysql5.x版本
bash
#登录mysql
mysql -uroot -p
#创建数据库
mysql>
create database dinky;
#授权
mysql>
grant all privileges on dinky.* to 'dinky'@'%' identified by 'dinky' with grant option;
mysql>
flush privileges;
#此处用 dinky 用户登录
mysql -h {mysql地址} -udinky -pdinkymysql8.x版本
bash
#登录mysql
mysql -uroot -p
#创建数据库
mysql>
CREATE DATABASE dinky;
#创建用户并允许远程登录,密码 dinky 可以自行修改
mysql>
create user 'dinky'@'%' IDENTIFIED WITH mysql_native_password by 'dinky';
#授权
mysql>
grant ALL PRIVILEGES ON dinky.* to 'dinky'@'%';
mysql>
flush privileges;手动安装
下载dinky压缩包并本地解压
bash
cd /opt/dinky
# 下载安装
wget https://github.com/DataLinkDC/dinky/releases/download/v1.2.2/dinky-release-1.19-1.2.2.tar.gz
tar -zxvf dinky-release-1.19-1.2.2.tar.gz
mv dinky-release-1.19-1.2.2 /ops/app/dinky修改配置文件 application.yml ,将默认数据库类型改成mysql
yaml
vim /ops/app/dinky/config/application.yml
# 修改 Dinky 所使用的数据库类型为 mysql
spring:
application:
name: Dinky
profiles:
# The h2 database is used by default. If you need to use other databases, please set the configuration active to: mysql, currently supports [mysql, pgsql, h2]
# If you use mysql database, please configure mysql database connection information in application-mysql.yml
# If you use pgsql database, please configure pgsql database connection information in application-pgsql.yml
# If you use the h2 database, please configure the h2 database connection information in application-h2.yml,
# note: the h2 database is only for experience use, and the related data that has been created cannot be migrated, please use it with caution
active: ${DB_ACTIVE:mysql} #[h2,mysql,pgsql]修改配置文件 application-mysql.yml ,配置mysql数据库地址、驱动等信息。
yaml
vim /ops/app/dinky/config/application-mysql.yml
# 修改 Dinky 的 mysql 链接配置
spring:
datasource:
url: jdbc:mysql://${MYSQL_ADDR:127.0.0.1:3306}/${MYSQL_DATABASE:dinky}?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&useSSL=false&zeroDateTimeBehavior=convertToNull&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true
username: ${MYSQL_USERNAME:dinky}
password: ${MYSQL_PASSWORD:dinky}
driver-class-name: com.mysql.cj.jdbc.Driver初始化数据库表
bash
#首先登录 mysql
mysql -h localhost -udinky -pdinky
mysql> use dinky;
mysql> source /ops/app/dinky/sql/dinky-mysql.sql添加 MySQL 依赖,将 MySQL 驱动文件放入 /ops/app/dinky/customJar 路径下
bash
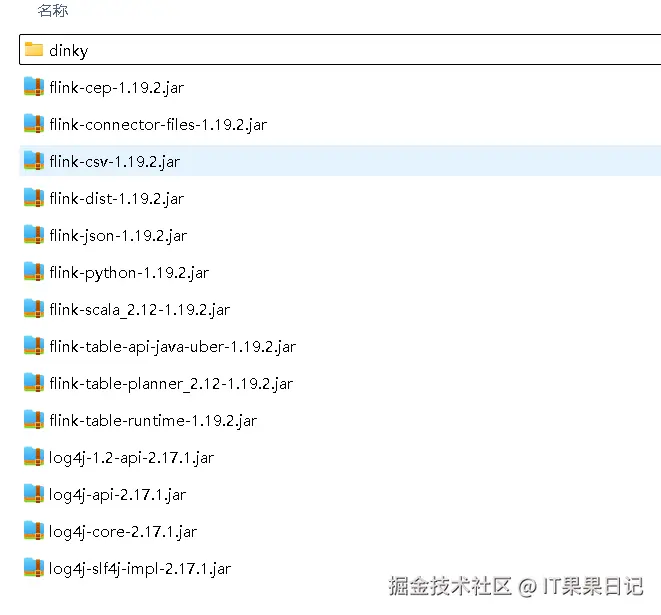
mysql-connector-java-8.0.19.jar添加 Flink 依赖,将下列文件添加到 /ops/app/dinky/extends/flink1.19 路径下,以下文件可以去$FLINK_HOME/lib 目录下拷贝。
bash
flink-cep-1.19.2.jar
flink-connector-files-1.19.2.jar
flink-csv-1.19.2.jar
flink-dist-1.19.2.jar
flink-json-1.19.2.jar
flink-python-1.19.2.jar
flink-scala_2.12-1.19.2.jar
flink-table-api-java-uber-1.19.2.jar
flink-table-planner_2.12-1.19.2.jar
flink-table-runtime-1.19.2.jar
log4j-1.2-api-2.17.1.jar
log4j-api-2.17.1.jar
log4j-core-2.17.1.jar
log4j-slf4j-impl-2.17.1.jar拷贝以后,/ops/app/dinky/extends/flink1.19 目录下文件如图所示
手动安装方式启动
bash
cd /ops/app/dinky
# 启动
bin/auto.sh start
#停止
bin/auto.sh stop
#重启
bin/auto.sh restart
#查看状态
bin/auto.sh status
# 前台启动(调试使用,会输出日志,阻塞当前终端,结束请Ctrl+C,但是会直接退出服务,仅供启动时无日志输出且在排查问题时使用)
bin/auto.sh startOnPendingdocker安装
由于mysql与Apache 2.0协议不兼容,dinky无法默认提供mysql驱动,所以需要您手动提供mysql依赖并放到 /opt/dinky/lib 目录下,下面已经给出了映射,如果你有自己的依赖目录,修改即可
bash
docker pull dinkydocker/dinky-standalone-server:1.2.2-flink1.19
# 如果提示连不上数据库,可以将 127.0.0.1 修改成指定 ip 地址
docker run --restart=always -p 8888:8888 \
--name dinky \
-e DB_ACTIVE=mysql \
-e MYSQL_ADDR=127.0.0.1:3306 \
-e MYSQL_DATABASE=dinky \
-e MYSQL_USERNAME=dinky \
-e MYSQL_PASSWORD=dinky \
-v /opt/dinky/lib:/opt/dinky/customJar/ \
dinkydocker/dinky-standalone-server:1.2.2-flink1.19如果不想容器随服务器启动而启动,可以修改重启策略
bash
docker update --restart=no <容器名或ID>
访问
web 地址:http://localhost:8888/
第一步,设置密码 123456

第二步,设置基本配置
第三步,Flink 配置

初始化完成
Flink作业
我们以一个读取 Kafka 数据并写入到 MySQL 的示例作为入门教程。
添加依赖包
在此之前,需要把相关依赖的 Jar 包引入到 /opt/dinky/lib 这个目录下**(docker 安装方式)**,这个目录映射的是 dinky docker 容器的 /opt/dinky/customJar/ 路径下 ;如果是手动安装方式,直接放在 /opt/dinky/customJar/ 路径下。依赖的 Jar 包清单如图所示:

重启 dinky docker 容器
bash
docker restart dinky注册Flink实例
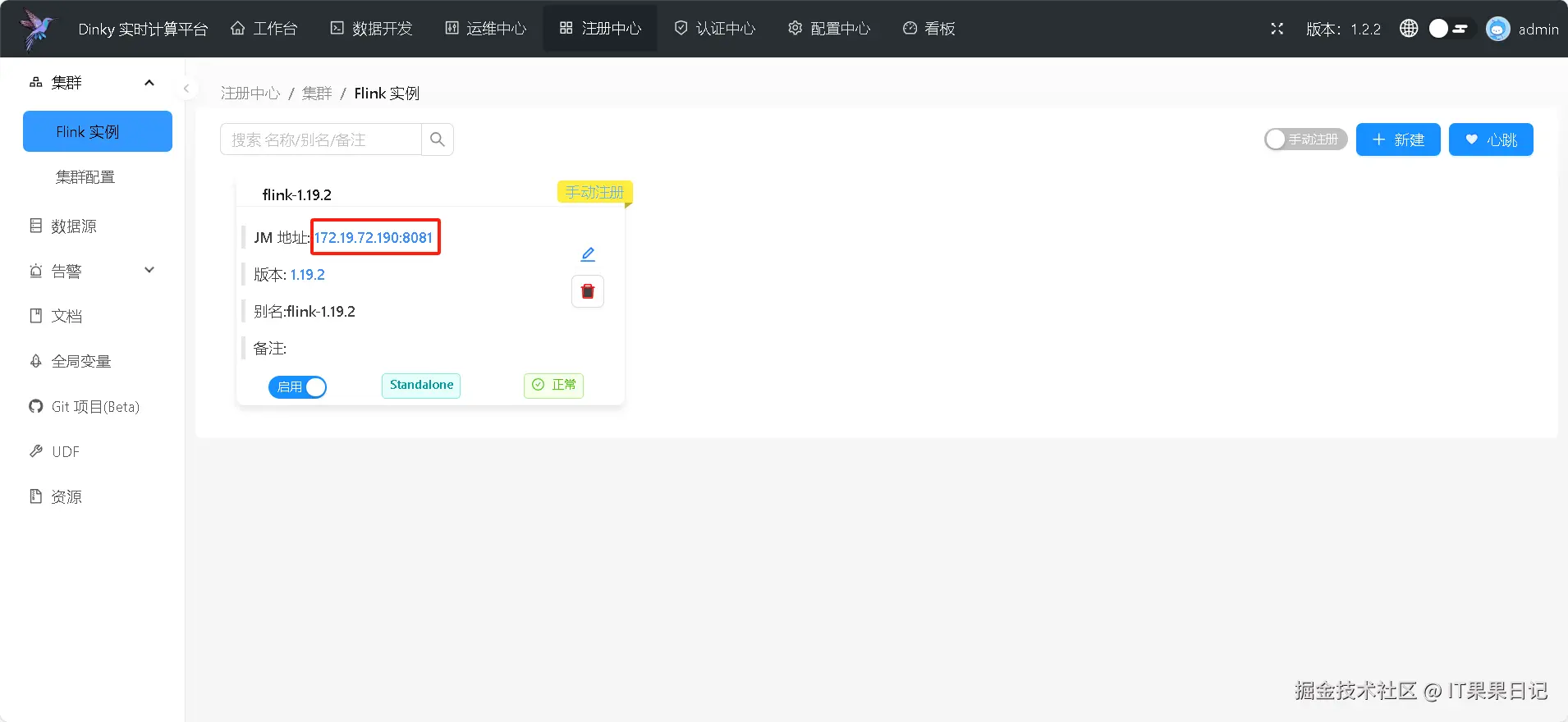
重新进入到 dinky web 界面,点击顶部菜单 注册中心 ,新建一个 Flink 实例,这是一个外部实例,并不是 dinky 自带的嵌入式 flink 。 如果运行 flink 作业时选择 local 模式就不需要新建 flink 实例。
创建Flink作业
点击顶部菜单 数据开发 ,左侧项目点 + 号创建目录,在目录下右键创建点 创建作业 。填写作业名称等信息。
保存后进入到作业编辑区,将 flink sql 代码填写进去。
sql
-- 设置 SQL 客户端执行模式为可视化表格(可选)
SET 'sql-client.execution.result-mode' = 'tableau';
-- 创建 Kafka 数据源表(JSON 格式)
CREATE TABLE KafkaSource (
`user_id` BIGINT,
`item_id` BIGINT,
`behavior` STRING,
`ts` TIMESTAMP_LTZ(3) METADATA FROM 'timestamp' -- 从 Kafka 消息元数据提取时间戳
) WITH (
'connector' = 'kafka',
'topic' = 'test-topic',
'properties.bootstrap.servers' = 'localhost:9092',
'properties.group.id' = 'flink-consumer-group',
'scan.startup.mode' = 'earliest-offset', -- 从最早位点开始消费
'format' = 'json', -- 指定 JSON 格式
'json.ignore-parse-errors' = 'true' -- 跳过解析错误
);
-- 创建 MySQL Sink 表(结构参考前文)
CREATE TABLE MysqlSink (
`user_id` BIGINT,
`item_id` BIGINT,
`behavior` STRING,
`ts` TIMESTAMP,
PRIMARY KEY (`user_id`, `item_id`, `ts`) NOT ENFORCED -- 主键需与 MySQL 表一致
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://<your_ip>:3306/<database>?useSSL=false&serverTimezone=UTC',-- 替换你的MySQL地址
'table-name' = 'test_flink', -- MySQL 表名
'username' = '<your_user>', -- 替换你的MySQL用户名
'password' = '<your_password>', -- 替换你的MySQL密码
'sink.buffer-flush.interval' = '1s' -- 写入批次间隔(可选调优)
);
-- 执行写入(直接映射字段)
INSERT INTO MysqlSink
SELECT user_id, item_id, behavior, ts
FROM KafkaSource;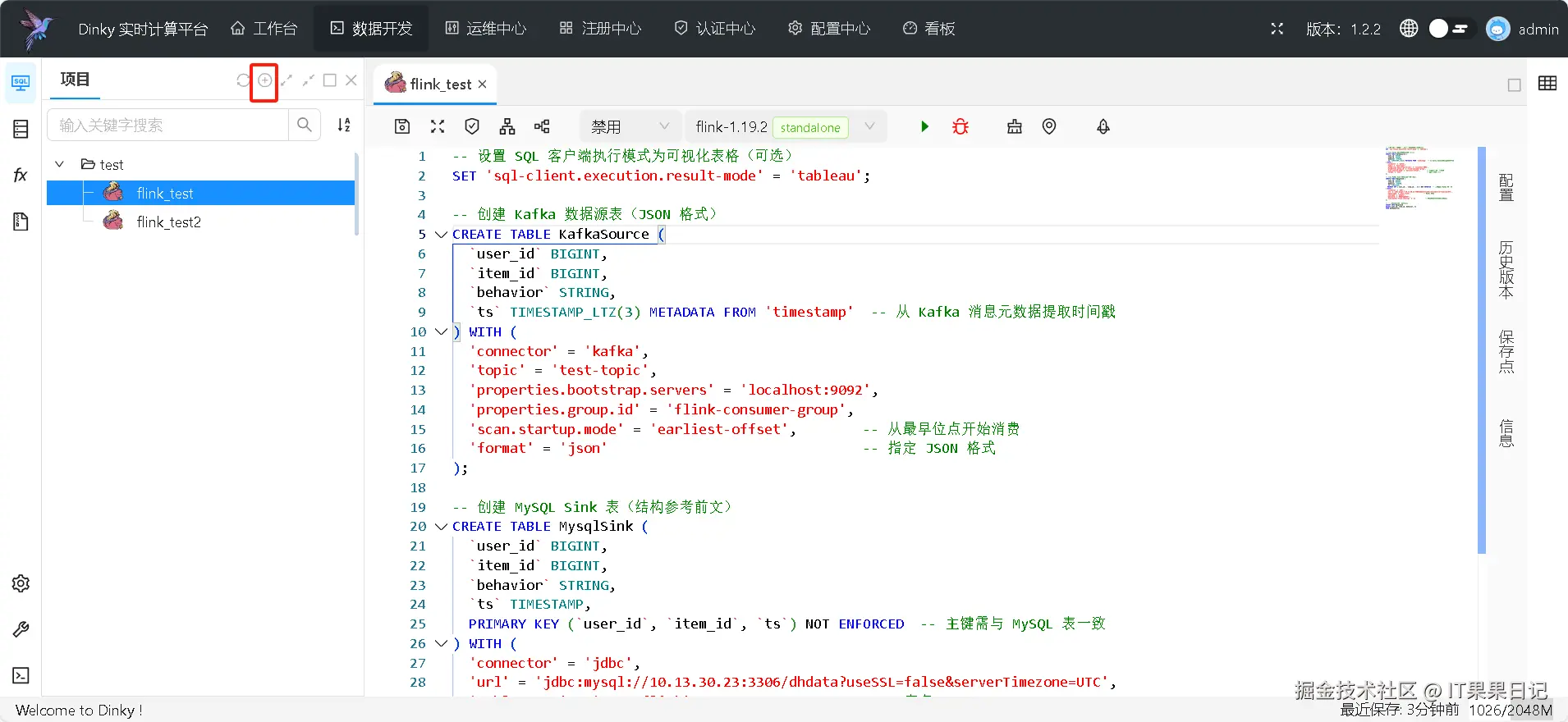
选择 flink 实例,可以选择 local 或者上一步注册的外部 flink 实例。
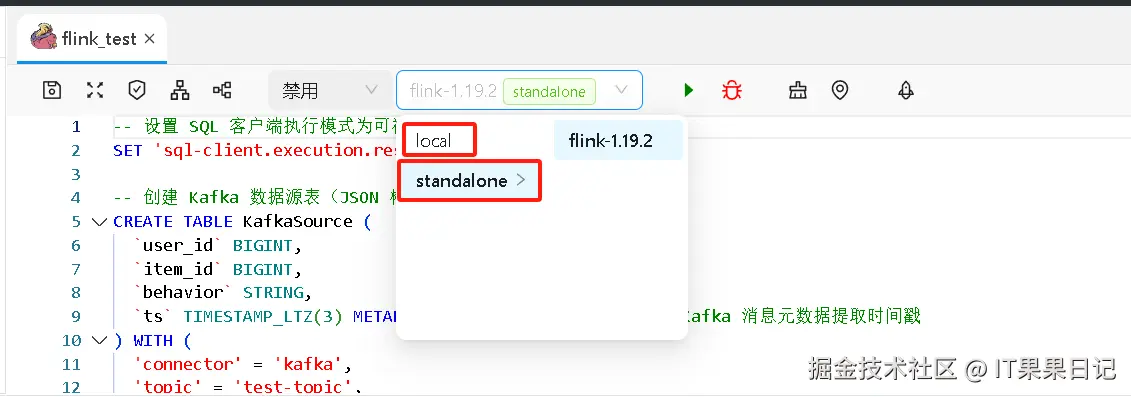
点击绿色三角按钮运行 flink 作业,观察日志提示执行成功。
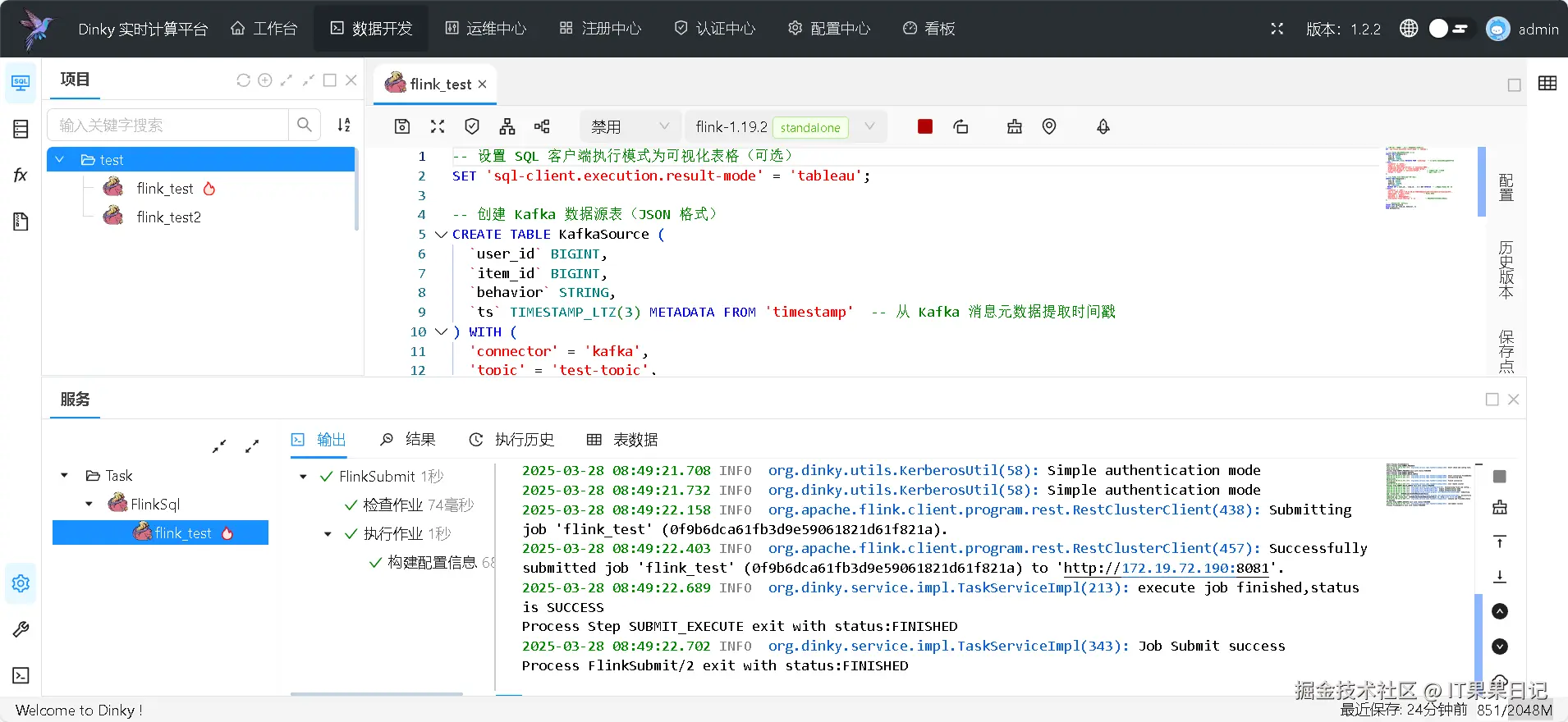
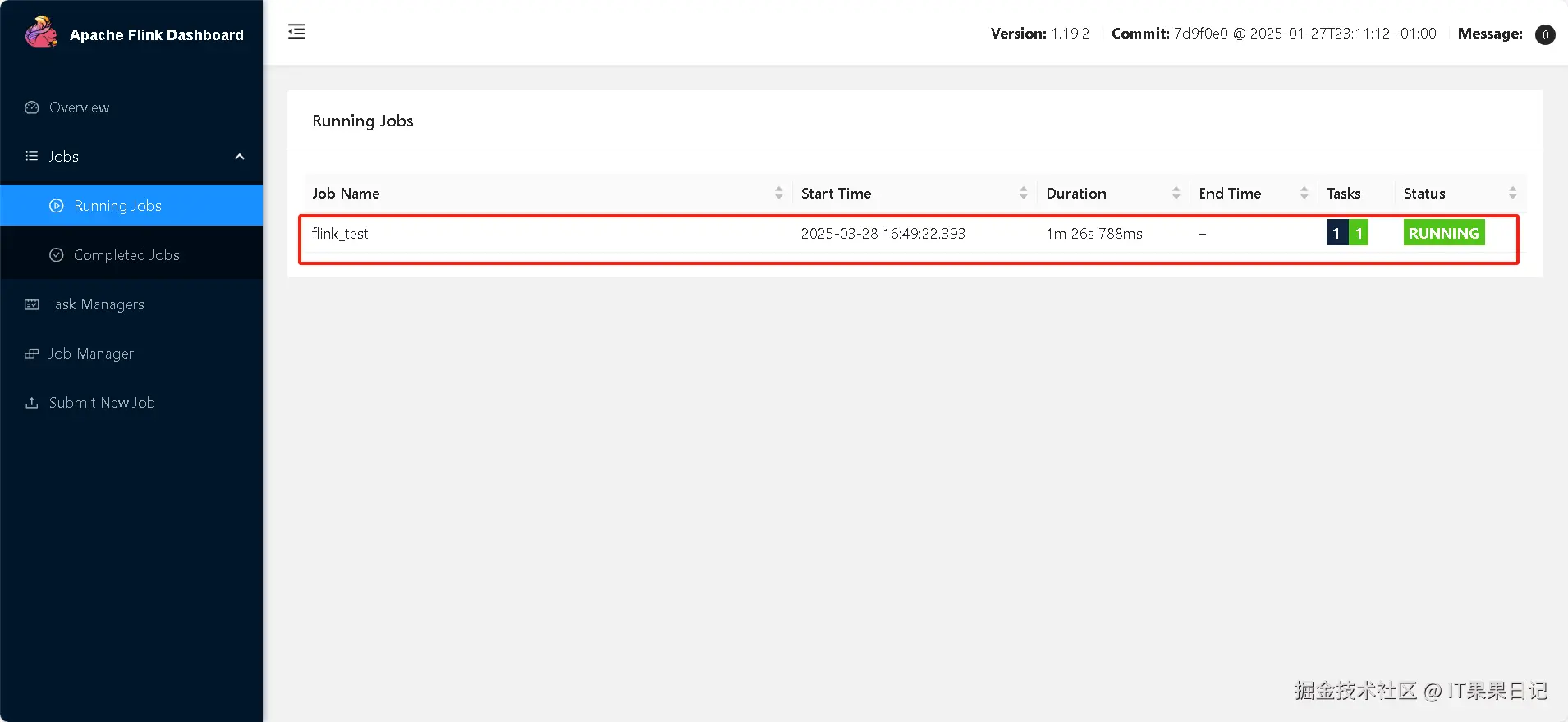
进入 flink dashboard 页面看下 dinky 是否成功提交。
http://localhost:8081/#/job/running
发送Kafka消息
bash
# 进入生产者
bin/kafka-console-producer.sh --topic test-topic --bootstrap-server localhost:9092在交互命令行中输入消息
json
{"user_id": 1001,"item_id": 2001,"behavior": "click"}
{"user_id": 1002,"item_id": 2002,"behavior": "select"}
{"user_id": 1003,"item_id": 2003,"behavior": "eat"}
验证MySQL数据
查看 MySQL 数据库,发现 test_flink 表已经有数据写入。

数据源
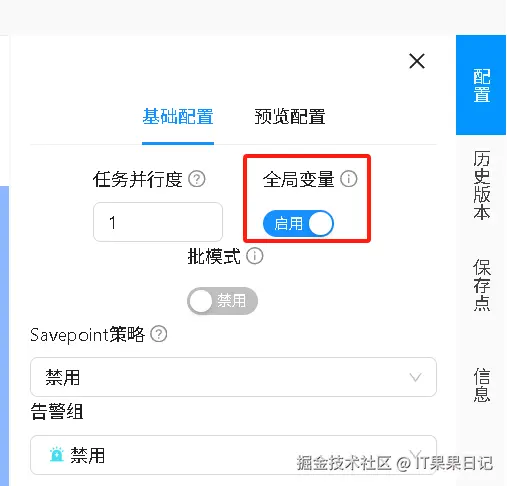
顶部菜单选择注册中心,左侧菜单选择数据源,右侧点击新建按钮,填写数据源信息如数据源名称、数据库用户名、数据库密码、数据库连接URL等。
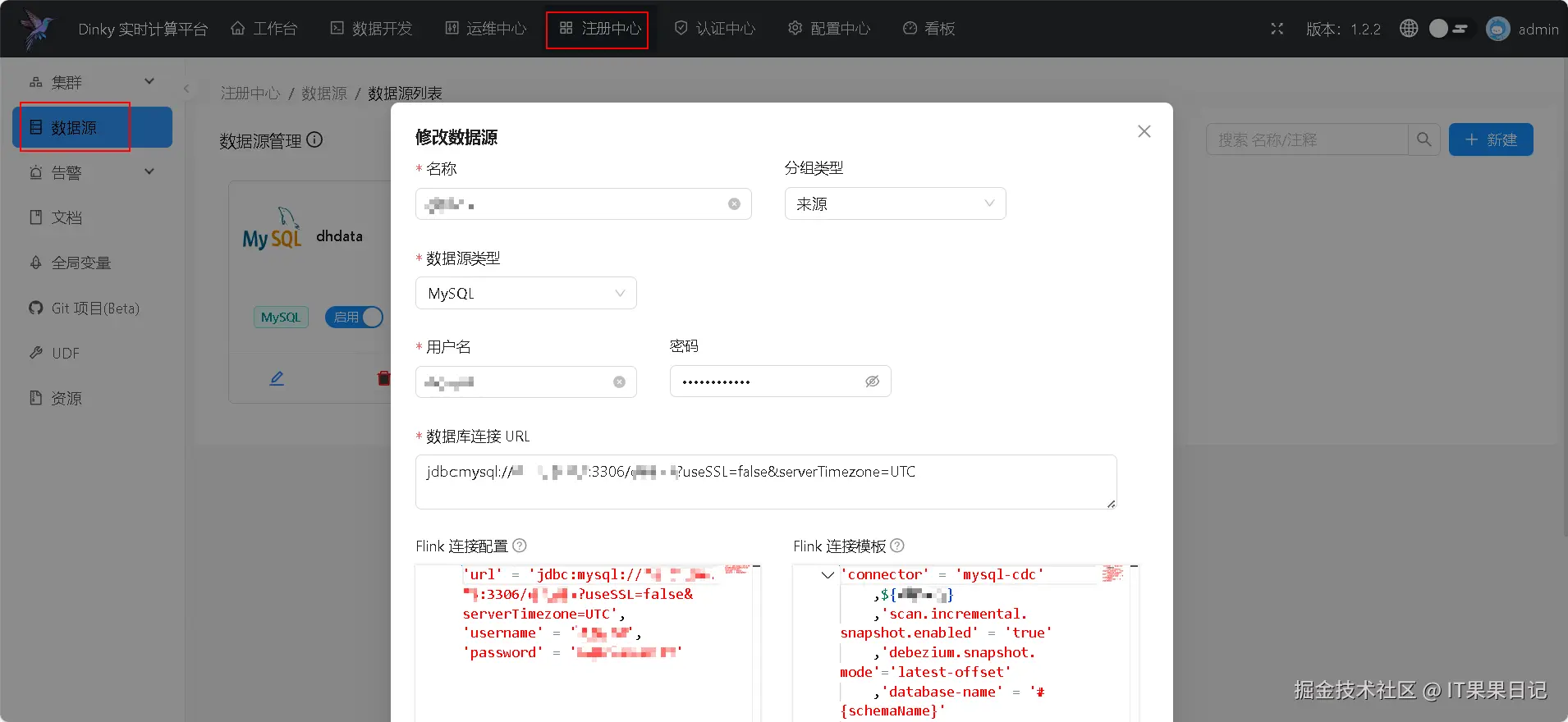
Flink连接配置信息可以用来用作全局环境变量,例如填写信息如下:
json
'url' = 'jdbc:mysql://<your_ip>:3306/<database>?useSSL=false&serverTimezone=UTC',
'username' = '<your_user>',
'password' = '<your_password>'以上信息可以用环境变量符号 ${db_source_name} 代替, db_source_name 是你的数据源名称, MysqlSink 就可以改成如下的写法。别忘了启动全局变量。
sql
CREATE TABLE MysqlSink (
`user_id` BIGINT,
`item_id` BIGINT,
`behavior` STRING,
`ts` TIMESTAMP,
PRIMARY KEY (`user_id`, `item_id`, `ts`) NOT ENFORCED -- 主键需与 MySQL 表一致
) WITH (
'connector' = 'jdbc',
'table-name' = 'test_flink', -- MySQL 表名
${db_source_name},
'sink.buffer-flush.interval' = '1s' -- 写入批次间隔(可选调优)
);UDF开发
本文只介绍基于python的udf开发,基于java或者scala的udf开发与其类似。
创建python环境
使用 conda 创建一个名为 flink_env 的新环境
bash
# 创建环境
conda create -p /opt/Anaconda3/envs/flink_env python=3.8 -y
# 激活环境
conda activate flink_env
# 安装flink
pip install apache-flink==1.19.2
# 退出环境
conda deactivate这里还有一步就是添加 flink-python 的依赖包,由于在安装 dinky 的时候已经添加了,所以此步骤可以忽略。
bash
# 添加到 DINKY_HOME/extends/flink1.19/ 目录下
flink-python-1.19.2.jar配置flink的python环境
flink 配置文件在 FLINK_HOME/conf/config.yaml 路径下,修改其 env 节点,默认只有 java 配置的参数,如果要使用 python udf 需要添加 python 的解释器路径。我使用的是 conda 创建的名为 flink_env 的 python 环境。
yaml
env:
python:
executable: /opt/Anaconda3/envs/flink_env/bin/python3
client.executable: /opt/Anaconda3/envs/flink_env/bin/python3 # 指定虚拟环境中 Python 解释器的绝对路径
pythonpath: /opt/Anaconda3/envs/flink_env/lib/python3.8/site-packages
# dependencies: /opt/Anaconda3/envs/flink_env/lib/python3.8/site-packages # PyFlink 依赖库路径也可以在flink作业的开头指定
java
SET python.pythonpath = '/opt/Anaconda3/envs/flink_env/lib/python3.8/site-packages';
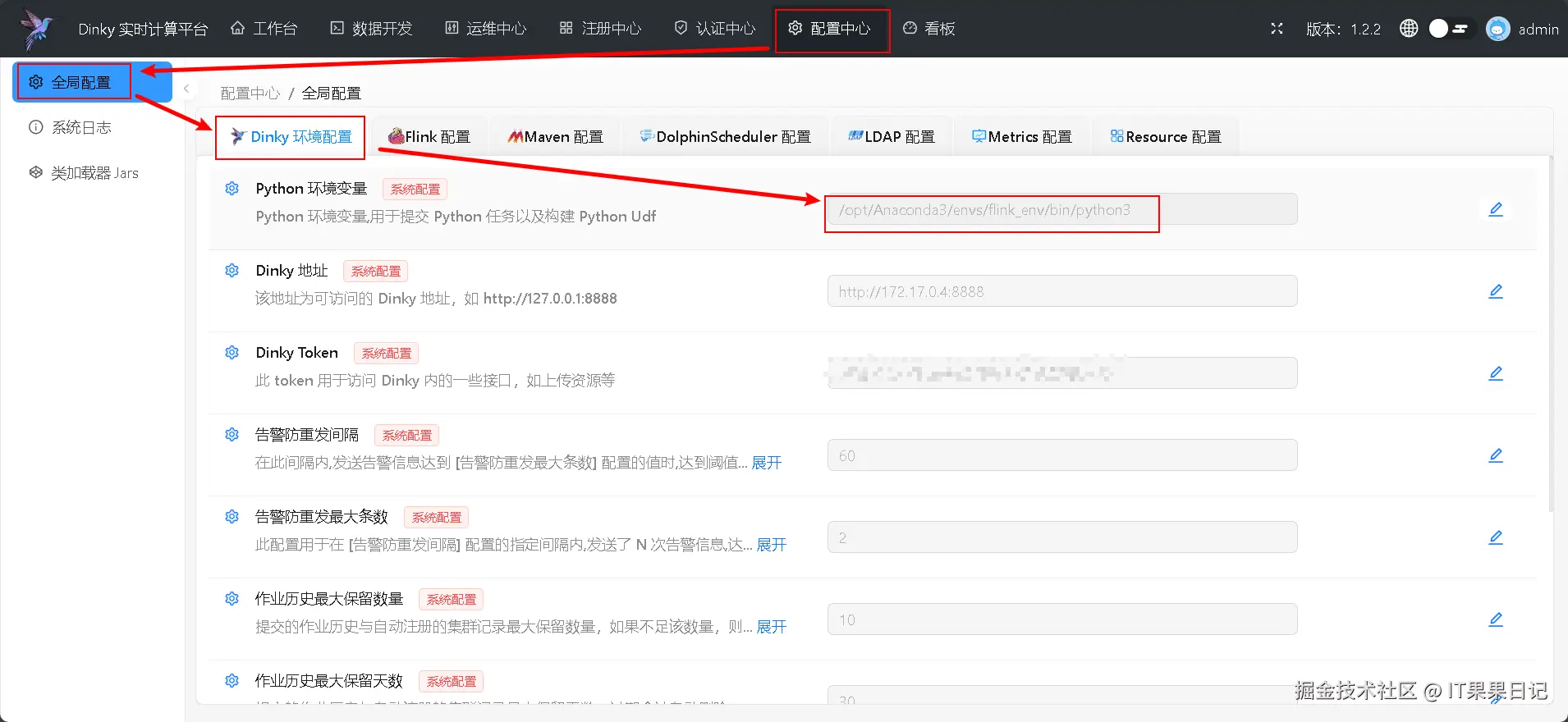
SET python.executable = '/opt/Anaconda3/envs/flink_env/bin/python';配置dinky的python环境变量
进入 dinky 界面,按照下图的访问路径对 Dinky 环境配置 中的 Python 环境变量 进行修改,改为和 flink 配置中的 python 解释器路径一样即可。
添加python udf代码
还是在 dinky web 界面中,访问 dinky>数据开发>创建作业 ,填写 python udf 作业 的信息,作业类型不再是 flink sql 而是 python 。选择 UDF 模板 可以自动生成 python udf 代码。类或方法名可以自定义一个 python udf 的函数名。模板默认有两种:
- UDF / python_udf_1
- UDF / python_udf_2
python_udf_1使用的是继承ScalarFunction类的方式;python_udf_2使用的是使用@udf注解标注函数的方式。建议使用python_udf_1模板,因为如果使用python_udf_2模板,同时udf代码逻辑需要申明多个函数,运行作业时可能会提交不成功。
python_udf_1
python_udf_1 模板需要添加flink-python的scala版本的依赖包,下载地址如下,添加到flink的$FLINK_HOME/lib目录下,以及dinky的$DINKY_HOME/extends/flink${flink_version}/ 目录下。
java
https://repo1.maven.org/maven2/org/apache/flink/flink-python_2.12/1.7.2/flink-python_2.12-1.7.2.jar 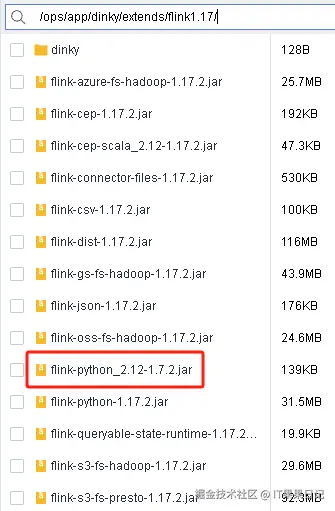
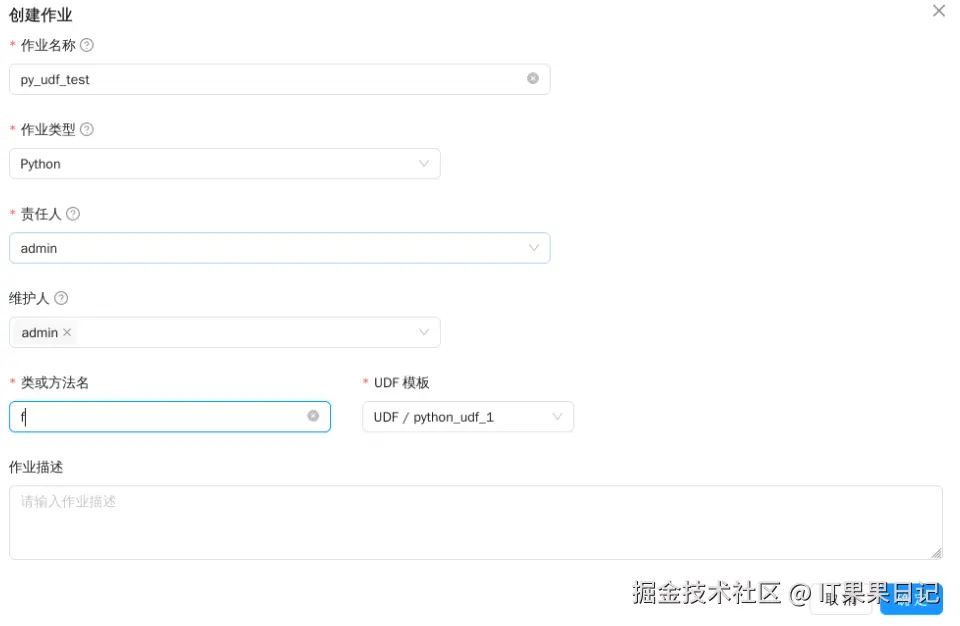
创建一个Python类型的作业,选择模板为UDF / python_udf_1 ,类或方法名一般填写f ,因为生成的模板里f是其默认的属性。
以下是一个SubString的简单udf示例,SubStringFunction函数是我自己添加的,其他的部分是模板自动生成的。
python
from pyflink.table import ScalarFunction, DataTypes
from pyflink.table.udf import udf
class f(ScalarFunction):
def __init__(self):
pass
def eval(self, variable):
return self.SubStringFunction(variable)
def SubStringFunction(self, variable1:str):
return 'this is python function: ' + variable1
f = udf(f(), result_type=DataTypes.STRING())保存后记得发布 此 udf ,否则调用时无法识别此 udf 。
python_udf_2
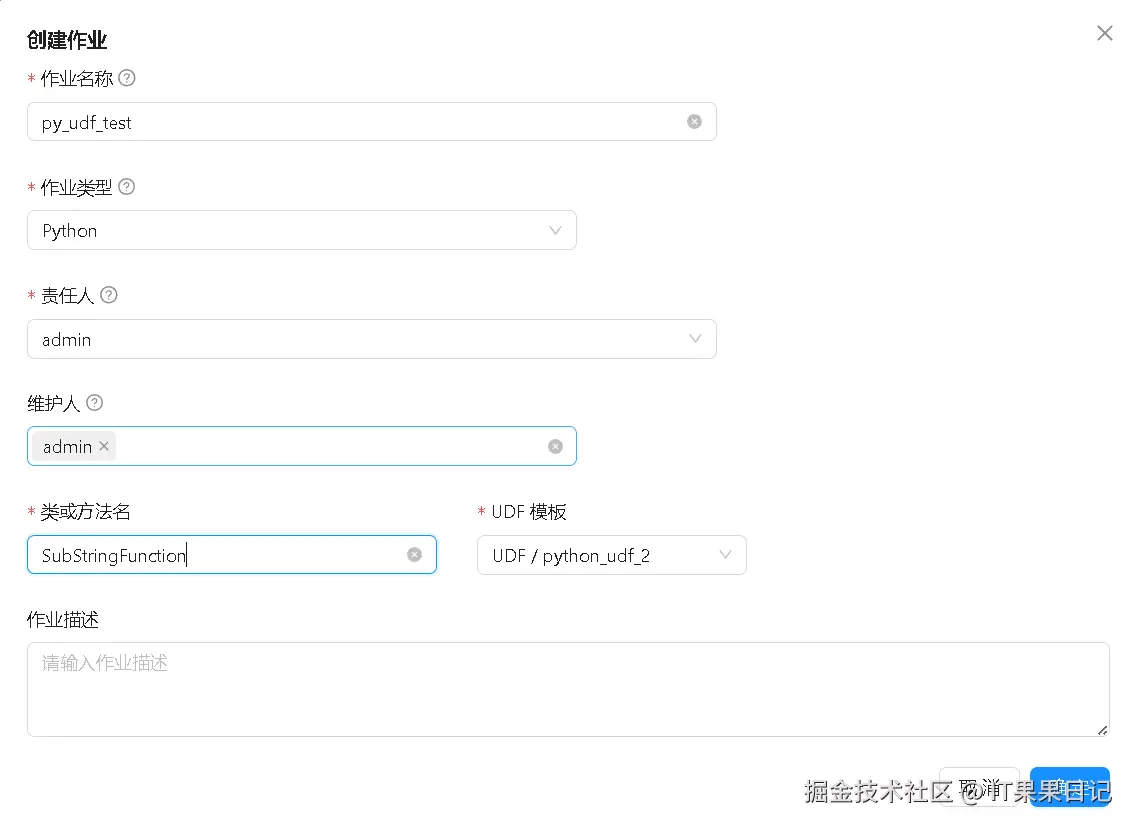
点击确定后可以在编辑区看到 SubStringFunction 函数的代码,可以自行修改。
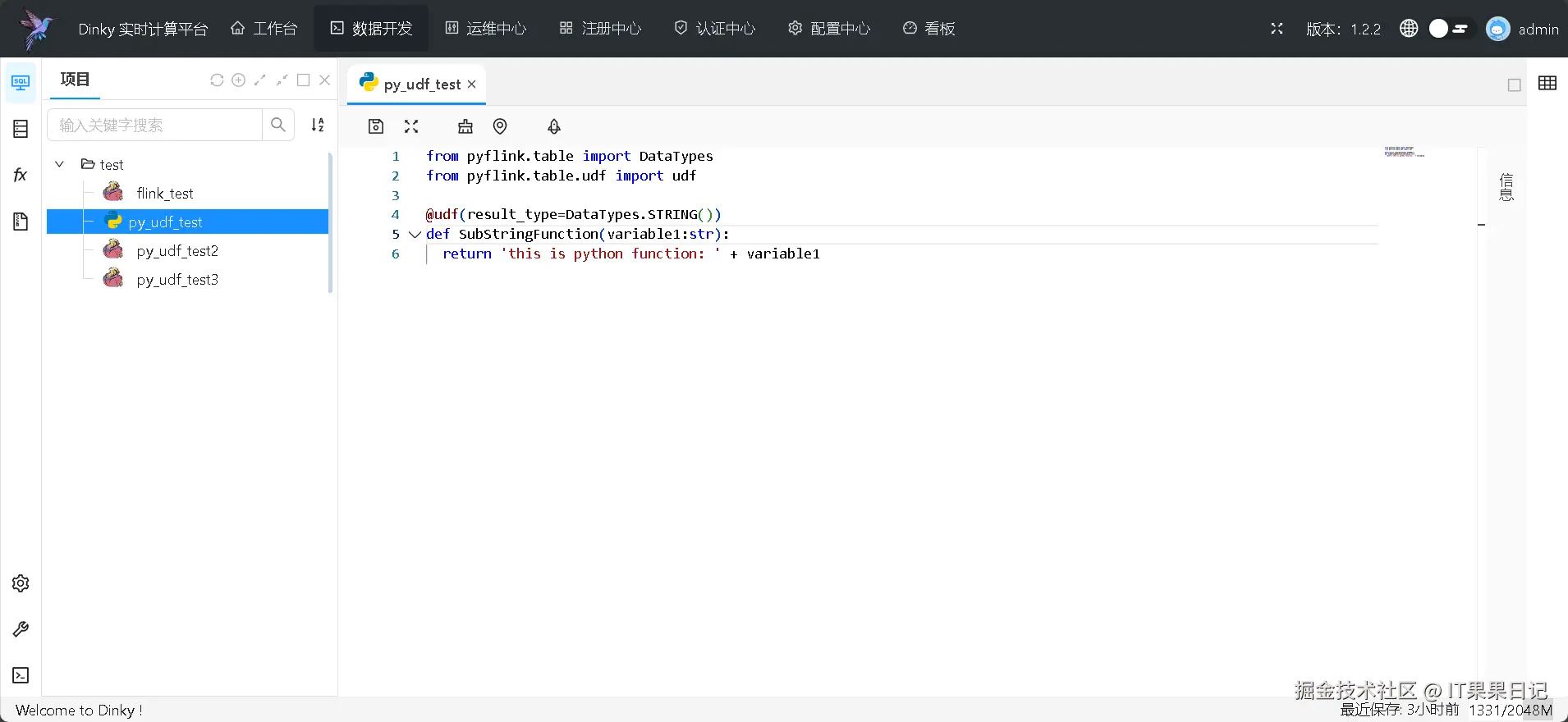
同样的,保存后记得发布 此 udf ,否则调用时无法识别此 udf 。
注册udf
注册 udf 就是在某个 flink sql 作业 脚本中加一段注册的代码,这样就可以在 sql 中调用 udf 函数。
还是使用上文中的 flink sql 作业 作为示例,根据udf使用的是哪个模板来决定在作业代码开头添加对应的注册代码:
sql
-- python_udf_1模板
create function sb_p as 'py_udf_test.f' language PYTHON;
-- python_udf_2模板
create function sb_p as 'py_udf_test.SubStringFunction' language PYTHON;如图所示,创建了一个别名为 sb_p 的函数,该函数引用的是 py_udf_test 这个 udf 的 SubStringFunction 函数。注意, py_udf_test 必须和 flink_test 作业在一个目录下面,不然会引用不到。
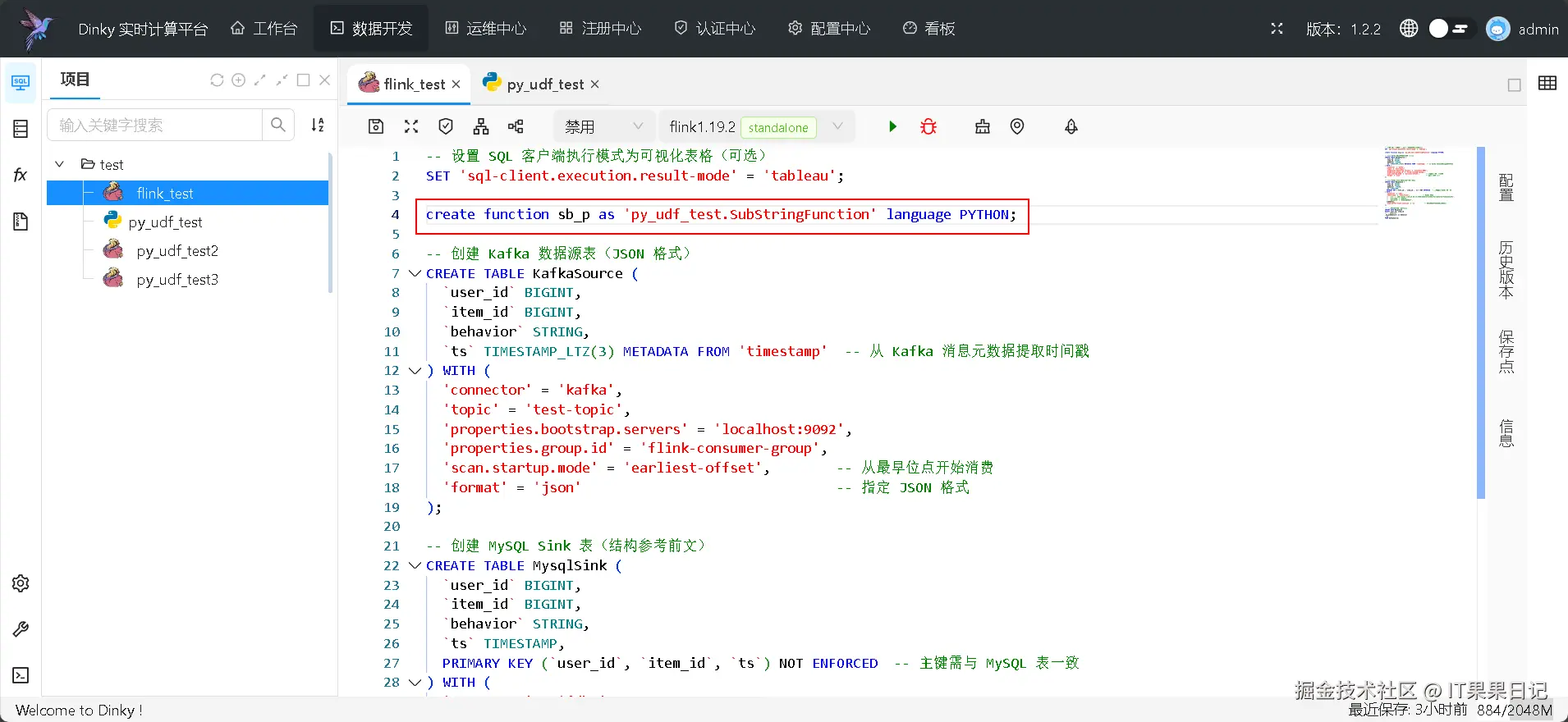
调用udf
将上文中的 insert 语句做一下修改:
sql
-- 在select behavior字段时,给behavior字段包上一层sb_p函数的调用
INSERT INTO MysqlSink
SELECT user_id
, item_id
, sb_p(behavior) as behavior
, ts
FROM KafkaSource;执行一下 flink_test 作业,依然是从 kafka 读取数据到 mysql , test_flink 的数据变成了如下图所示:

Catalog管理
Flink 提供四种 Catalog
- GenericInMemoryCatalog
- JdbcCatalog
- HiveCatalog
- 用户自定义的Catalog
Dinky 提供两种 Catalog
Session会话级别的CatalogMysql Catalog
如果在 Dinky 实时计算平台开发,推荐采用 Flink 原生的 HiveCatalog 或者 Dinky 的 Mysql Catalog。这两种是可以持久化元数据信息的。本文仅介绍Dinky 的 Mysql Catalog 。
Mysql Catalog 的元数据信息会保存到 Mysql 数据库表里,表信息解释如下:
| 元数据表 | 表中文名称 |
|---|---|
| metadata_database | 元数据schema信息 |
| metadata_table | 元数据table信息 |
| metadata_database_property | schema属性信息 |
| metadata_table_property | table属性信息 |
| metadata_column | 数据列信息 |
| metadata_function | UDF信息 |
添加Mysql Catalog依赖
将 $DINKY_HOME/extends/flink1.19/dinky 下的 dinky-catalog-mysql-1.19-1.2.2.jar 文件复制到 $FLINK_HOME/lib 下
bash
dinky-catalog-mysql-1.19-1.2.2.jar创建 Mysql Catalog 语法
sql
create catalog my_catalog with(
'type' = 'dinky_mysql',
'username' = 'dinky',
'password' = 'dinky',
'url' = 'jdbc:mysql://127.0.0.1:3306/dinky?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&useSSL=false&zeroDateTimeBehavior=convertToNull&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true'
);
use catalog my_catalog;注意!目前的版本只支持固定的 Catalog 名称: my_catalog 。
参数 type 可以是以下几种:
- dinky_mysql
- dinky_postgresql
- generic_in_memory
参数 username 、password 和 url 是 dinky 所在数据库的信息。
创建一个 Flink Sql 作业来执行上述脚本。然后就可以在查看界面看到创建的 Catalog 。虽然我们创建的是名为 my_catalog 的 catalog ,但是由于 type 参数是 dinky_mysql ,所以 dinky 会将其名字改为 my_catalog_dinky_mysql ,如下图右侧红框处(左侧红框处的禁用要改成DefaultCatalog) 。
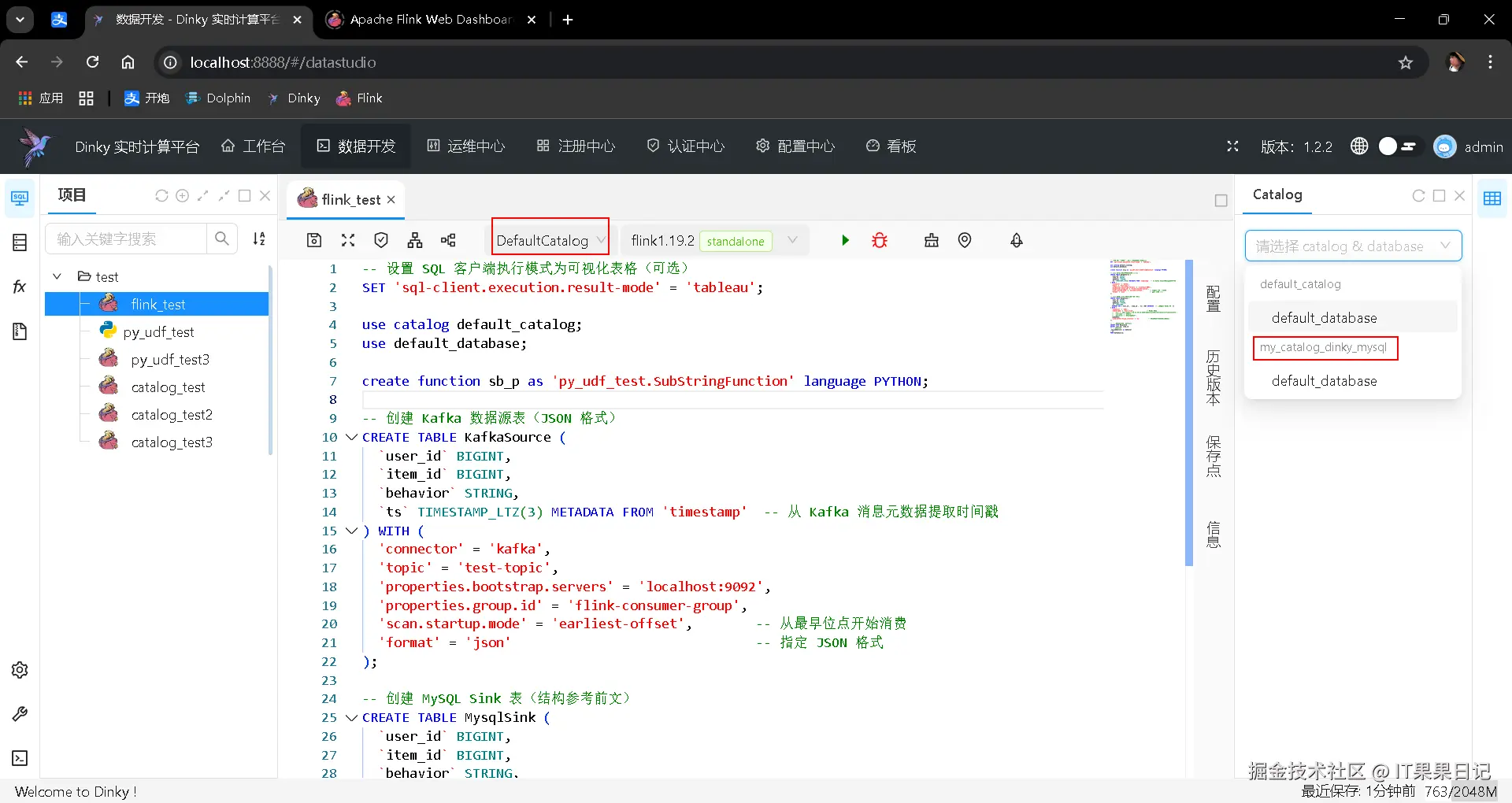
还是借前文 Flink 作业的示例来介绍一下持久化catalog之后,Flink作业是如何工作的?
放开了Catalog禁用之后,执行同样的作业脚本,会发生什么?
上图中看以看到Catalog里已经保存了KafkaSource表、MysqlSink表和udf函数sb_p 。
如果重复执行会发生什么?
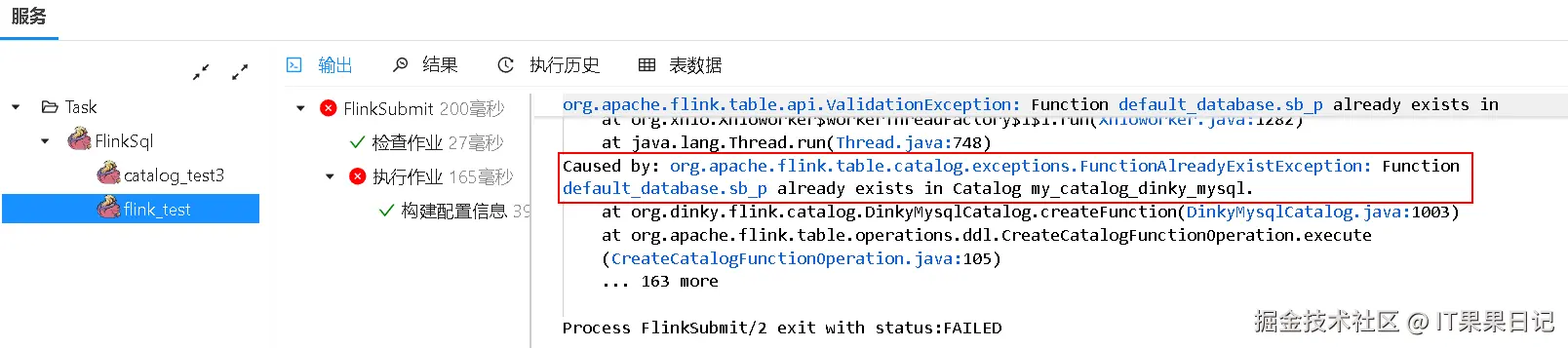
控制台日志会输出报错信息,提示Catalog my_catalog_dinky_mysql中已经存在函数sb_p 。所以我们修改一下代码,将注册函数的语句加一个关键字**TEMPORARY** 。它的意思是这个函数是临时的。
sql
create TEMPORARY function sb_p as 'py_udf_test.SubStringFunction' language PYTHON;再次执行,依然报错,如下图
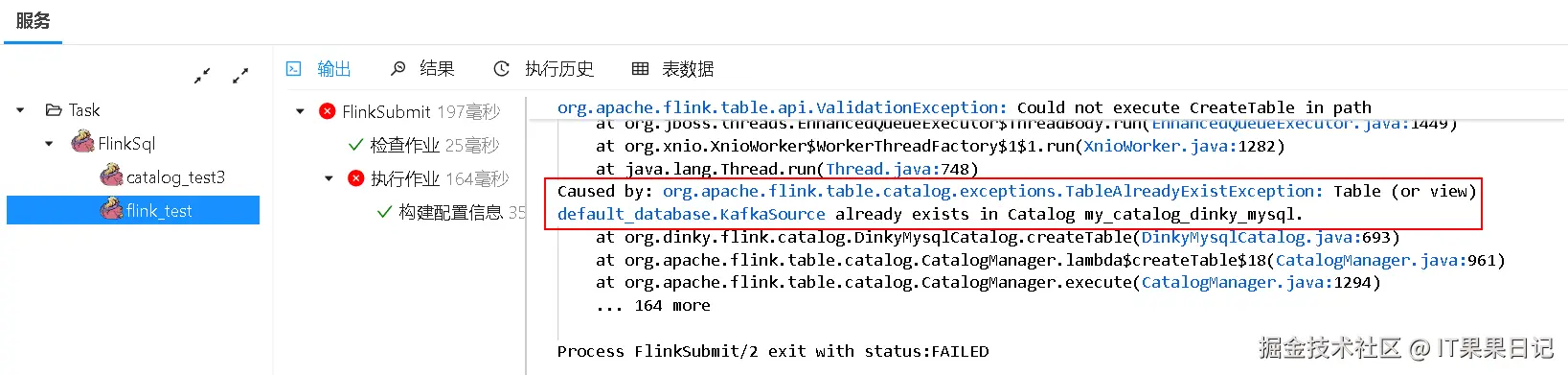
日志提示Catalog my_catalog_dinky_mysql中已经存在表KafkaSource 。所以在 Mysql Catalog 里因为持久化的原因,执行作业不再需要重复执行ddl语句,直接执行dml语句就好了。
将建表语句注释掉以后,执行成功。

我们还可以试下使用default_catalog来重复执行作业会发生什么?
sql
# 在作业脚本开头加上两行代码,指定使用 default_catalog
use catalog default_catalog;
use default_database;即使重复执行作业依然不会报错。这是因为default_catalog的生命周期是会话级别的,并不会持久化元数据信息。
其他DDL语法
sql
-- 删除 CATALOG
-- DROP CATALOG [IF EXISTS] catalog_name;
drop catalog if exists my_catalog_dinky_mysql;
-- 删除 DATABASE
-- DROP DATABASE [IF EXISTS] [catalog_name.]db_name [ (RESTRICT | CASCADE) ];
DROP DATABASE IF EXISTS my_catalog_dinky_mysql.default_database;
-- 删除表
-- DROP [TEMPORARY] TABLE [IF EXISTS] [catalog_name.][db_name.]table_name;
DROP TABLE IF EXISTS my_catalog_dinky_mysql.default_database.KafkaSource;
DROP TABLE IF EXISTS my_catalog_dinky_mysql.default_database.MysqlSink;
-- 删除视图
-- DROP [TEMPORARY] VIEW [IF EXISTS] [catalog_name.][db_name.]view_name;
-- 删除 FUNCTION
-- DROP [TEMPORARY|TEMPORARY SYSTEM] FUNCTION [IF EXISTS] [catalog_name.][db_name.]function_name;
DROP FUNCTION IF EXISTS my_catalog_dinky_mysql.default_database.sb_p;
-- 创建 catalog
create catalog my_catalog with(
'type' = 'dinky_mysql',
'username' = 'dinky',
'password' = 'dinky',
'url' = 'jdbc:mysql://127.0.0.1:3306/dinky?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&useSSL=false&zeroDateTimeBehavior=convertToNull&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true'
);Catalog小结
至此,我们可以总结一下,在执行dinky作业的时候有以下几种场景:
- 如果
Catalog选择了"禁用",则每次运行都需要提前建表; - 如果
Catalog选择了DefaultCatalog,那么Catalog默认使用的是my_catalog,即多次运行只需要建一次表; - 如果
Catalog选择了DefaultCatalog,且在作业代码中指定了catalog,例如use catalog default_catalog;,则每次运行都需要提前建表。
此外,本文介绍的Mysql Catalog 属于dinky 自带的,其性能比不上Hive Metastore ,而且对一些主流的数据分析引擎如trino ,在适配性上也是不如Hive 的。所以如果数据量不大且数据分析业务并不复杂,可以考虑更加轻量的Mysql Catalog ,否则还是老老实实使用Hive和Hadoop吧。
集成DolphinScheduler
创建令牌
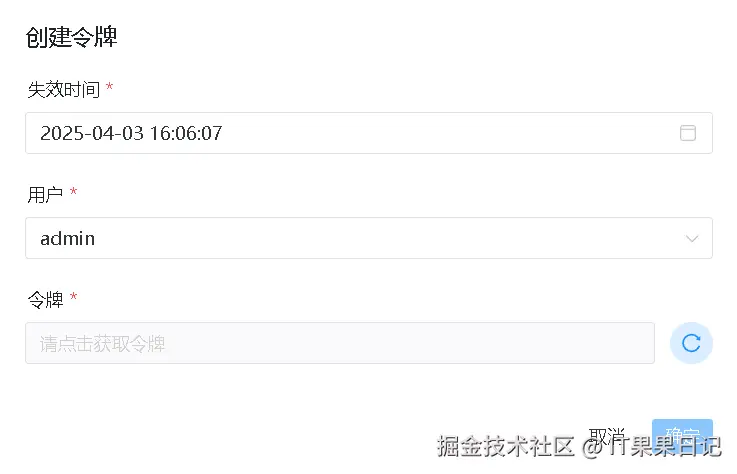
登录到 dolphinscheduler ,进入顶部菜单 安全中心 ,点击左侧菜单 令牌管理
点击创建令牌按钮,在弹出框中选择用户,注意失效时间一定重新选择,否则一会就失效了。
配置令牌
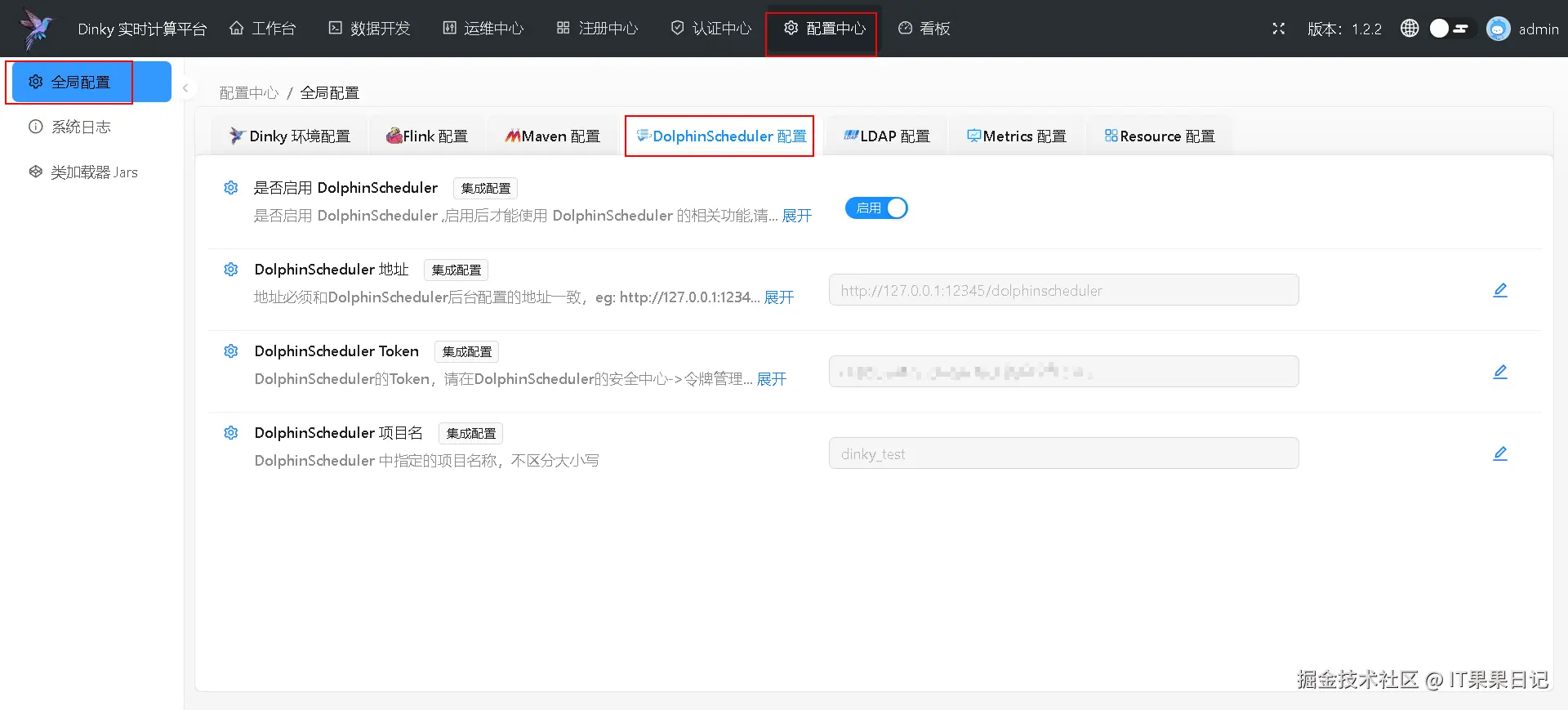
重新回到 dinky 页面,进入顶部菜单 配置中心 ,点击左侧菜单 全局配置 ,选择 DolphinScheduler 配置 标签页,启用开关,按照提示填写 DolphinScheduler 相关信息,特别是 Token 一栏要填写刚才在DolphinScheduler 里创建的令牌。
发布和推送
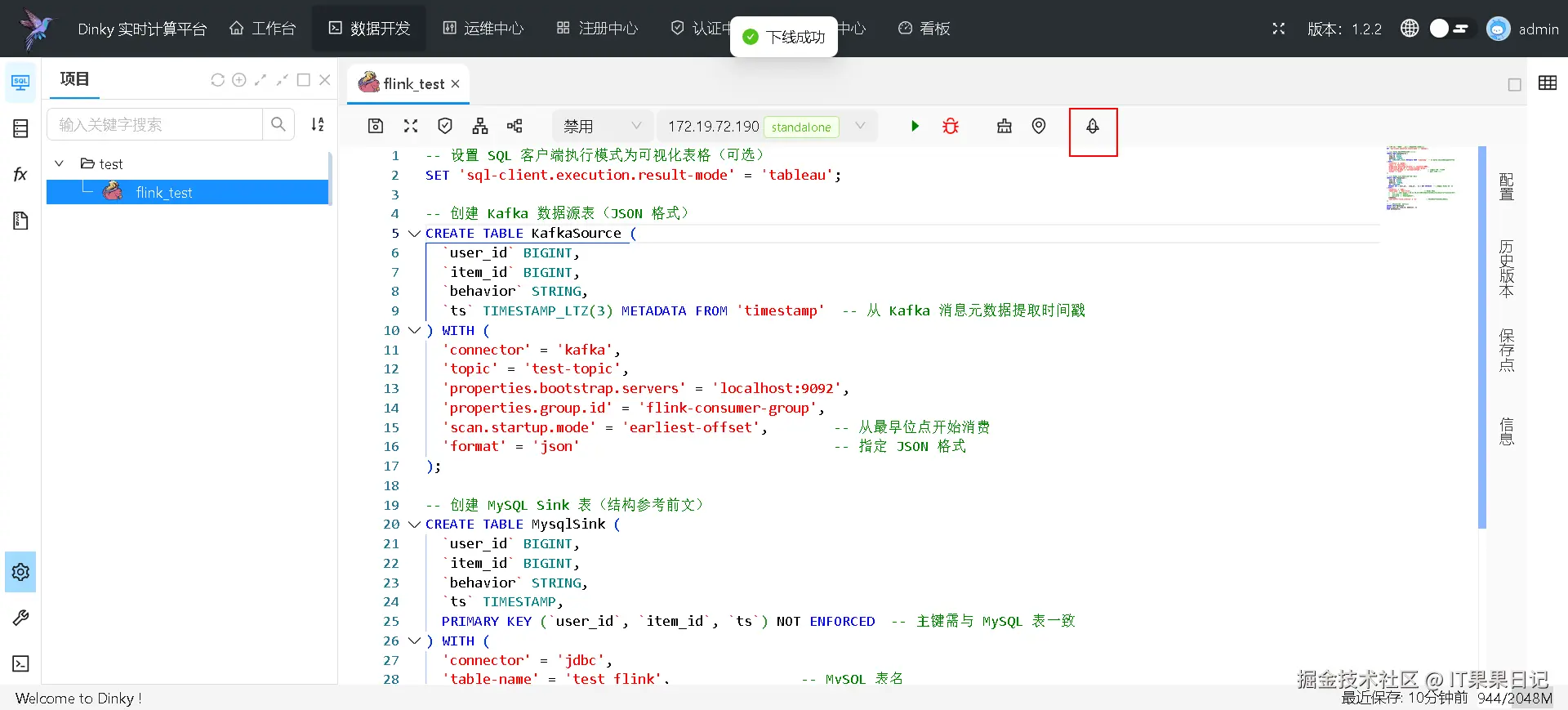
进入 数据开发 界面,点击 发布 按钮,然会会出现一个 推送 按钮,再点击推送按钮
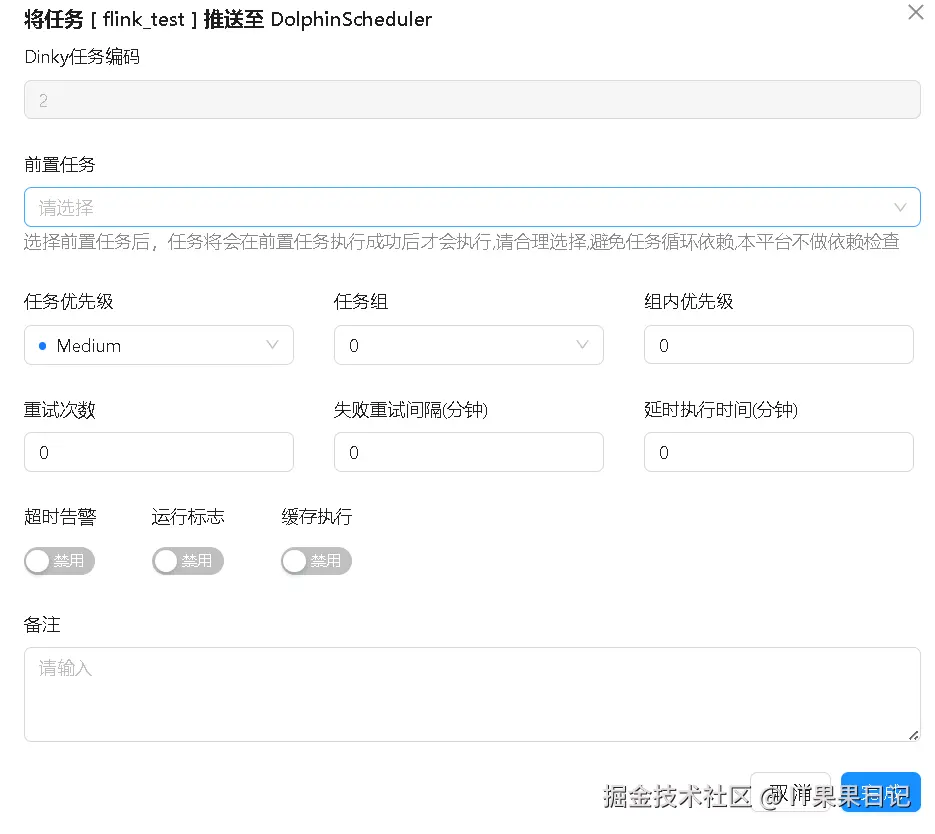
在弹出框内填写推送信息
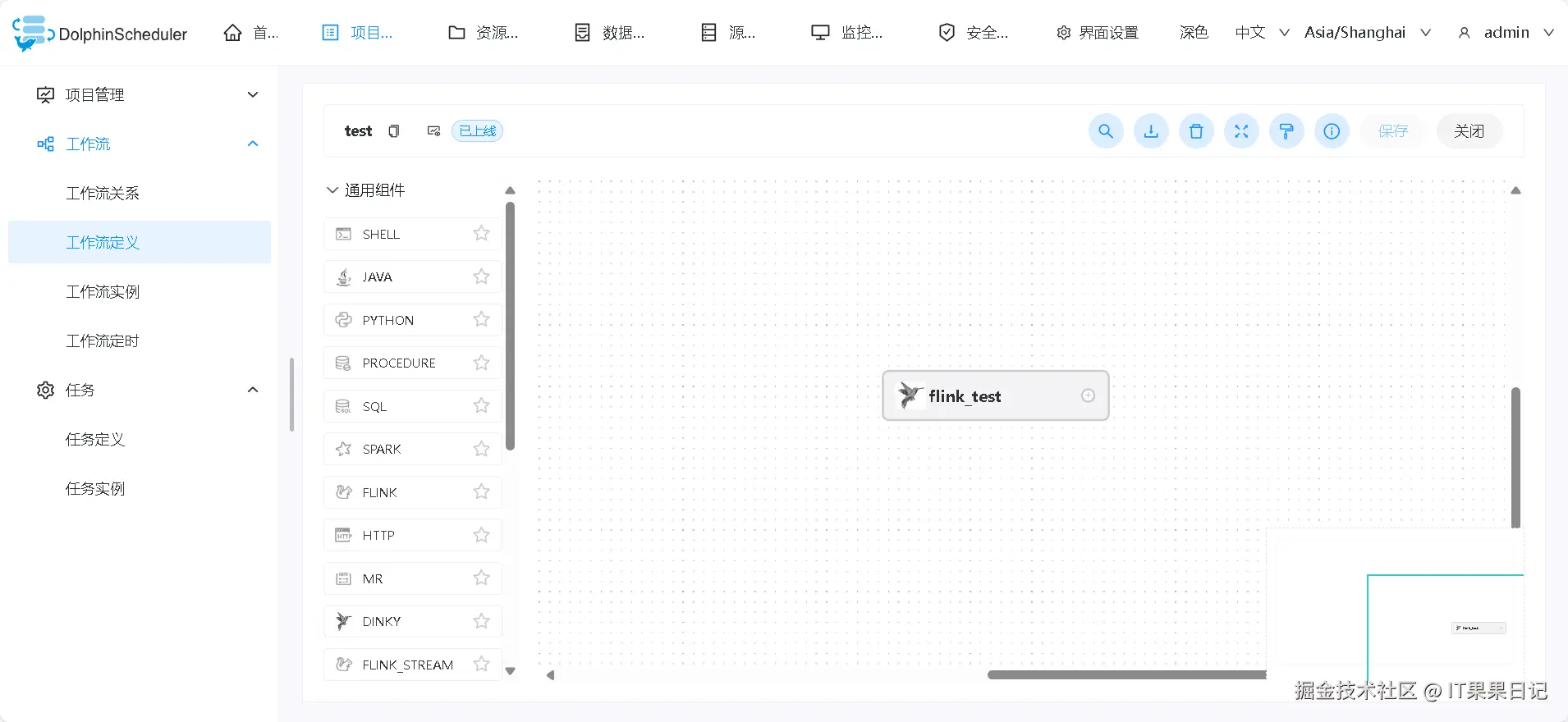
进入 DolphinScheduler ,项目列表会出现一个新的项目,项目名称和在 dinky 中配置的一样,我的是叫做 dinky_test 。进入dinky_test项目可以看到一个叫做 test 的工作流定义, test 名称对应的是 dinky 项目的目录名称。
进入 test 工作流,可以看到 flink_test 名称的 dinky 任务。