计算机网络:网络层 - IPv4数据报 & ICMP协议
IPv4数据报
一个IPv4数据报,由首部和数据两部分组成:
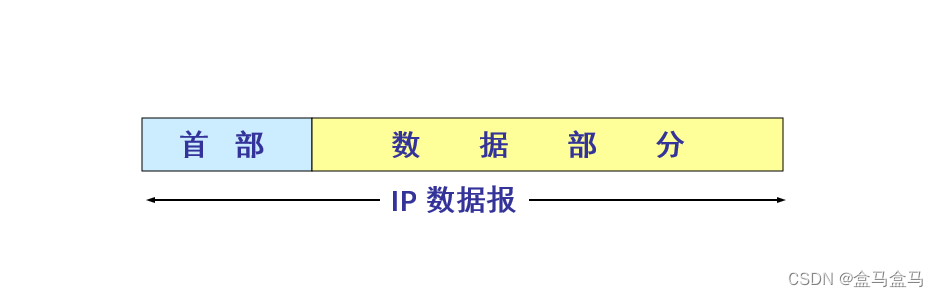
而首部又分为两部分:

上图中,首部又分为固定部分和可变部分,固定部分的长度为20 byte,而可变部分的长度在0 byte到40 byte之间。每一行占32 bit也就是4 byte。接下来就讲解这个首部各个字段的含义。
版本 : 首部长度 : 区分服务 : 总长度

- 版本
占4 bit,表示该IP数据报使用的版本,目前广泛使用的IP协议版本号为4。
- 首部长度
由于可变部分的存在,IPv4数据报的首部长度是不确定的,所以需要额外的字段来标识整个首部的长度。首部长度占4 bit,4 bit可以表示的最大数字为二进制1111,也就是15。但是IPv4数据报的最大长度为60 byte,这是4 bit好像不够用啊。
其实首部长度字段的值,是以4 byte为单位的,也就是说如果首部长度的值为15,表示有15 * 4 = 60 byte,这样4 bit刚好可以表示最大的首部长度。另外的,由于首部长度单位的限制,所以IPv4数据报首部的长度必须为四字节的整数倍。
- 区分服务
占8 bit,用于提供不同等级的服务,也就是说IPv4数据报的服务分了多个等级,可以通过该字段来选择不同等级。大部分情况下不使用这个字段。
- 总长度
占16 bit,指明首部和数据部分的总长度,单位为byte。由于只占16 bit,所以整个IPv4数据报总长度不超过665535 byte。当然一般来数据报的长度是数据链路层的MTU限制的。
标识 : 标志 : 片偏移
那么一个数据报的内容超过了MTU该怎么办?此时就要进行分片操作,将一个数据报分为多个小份的数据报。
假设现在有一个长度为3820 byte的数据报,首部长度为20 byte,现在MTU限制为1420 byte,那么我们就要把这个3820 byte的打数据报分片为多个小的数据报。
如下图:

我们把这个数据报分片为了三个小数据报,第一个数据报的长度为20 + 1400,第二个数据报的长度为20 + 1400,第三个数据报的长度为20 + 1000,其中20表示每个分片后数据报的首部。而分片的规则为:优先填满前面的数据报,而不是将数据平均分配到每个数据报中。
将一个数据报分片后,会产生以下问题:
- 接收方如何知道这些分片后数据报来源于同一个数据报
- 接收方如何知道自己是否收到了所有分片
- 接收方如何知道这些分片的顺序
IPv4数据报首部中的第二行字段,就是用来解决分片的问题的:

- 标识
占16 bit,这是一个计数器,用于区分不同的数据报,或者辨别相同的数据报。
比如说发送方前一个发送的数据报的标识 = 12345的数据报,那么发送方发送的下一个数据报的标识就应该是12345 + 1 = 12346。这样接收方就可以辨别出这是两个不同的数据报。
但是如果把一个数据报分片为多个数据报,那么分片出来的所有数据报,共用一个标识字段。此时接收方收到多个分片后,就可以判断出来这些分片原本属于同一个数据报。
- 片偏移
占13 bit,其用于指出一个数据报在分片后再原数据报中的相对位置。片偏移以8 byte为单位。
比如刚才的案例中:

对于分片1,其第一个字节为0,片偏移 = 0 / 8 = 0;
对于分片2,其第一个字节为1400,片偏移 = 1400 / 8 = 175;
对于分片3,其第一个字节为1800,片偏移 = 2800 / 8 = 350;
由于片偏移只能是整数,所以数据报总长度必须是8 byte的整数倍!
- 标志
占3 bit,三个比特位单独解析,从低位到高位分别是MF位,DF位,和保留位。其中保留位是保留给以后使用的,目前没有意义,保留位必须为0。
MF(More Fragment)位,用于表示该数据报后面还有没有分片。一个数据报被分片后,除去最后一个分片外,所有的分片的MF = 1,表示这个分片后还有分片;而最后一个分片的MF = 0,表示该分片已经是最后一个分片了。
MF位结合片偏移,可以用于确认是否接收到了所有的分片。当接收方接收到了MF = 0
的分片,就说明已经收到了末尾的分片,随后获取该分片的片偏移从而得知前面总共有多少数据,再检测自己之前收到的数据,就可以知道自己是否受到了所有分片了。
DF(Don't Fragment )位,该位表示一个数据报是否允许分片,如果DF = 0表示允许分片,如果DF = 1表示不允许分片。
=如果一个数据报的长度超过了MTU,并且DF = 1不允许分片,此时会直接丢弃这个数据报,并向上层发送错误信息,表示该数据报不能传递。
再回到这个案例:

接下来我画一个表格,表示这三个分片的各字段值,假设分片前标识 = 12345:
| 数据报 | 标识 | MF | DF | 保留位 | 片偏移 |
|---|---|---|---|---|---|
| 分片前 | 12345 | 0 | 0 | 0 | 0 |
| 分片1 | 12345 | 1 | 0 | 0 | 0 |
| 分片2 | 12345 | 1 | 0 | 0 | 175 |
| 分片3 | 12345 | 0 | 0 | 0 | 350 |
生存时间 : 协议 : 首部检验和

- 生存时间
占8 bit,又叫做TTL(Time TO Live),该字段由源主机设置,路由器每次转发时TTL要减一。当TTL = 0时,路由器不再转发该报文,而是将其丢弃,即生存时间到期了。
- 协议
占b bit,用于表示数据部分的内容使用了何种协议,常见协议字段取值如下:

- 首部检验和
占16 bit,用于检验数据报的首部是否发生错误,注意只检验首部,不会检验数据部分。
以下是计算 IP 数据报首部校验和的步骤:
- 将首部所有字段视为 16 位字,并进行二进制求和(简单来说就是把首部看为16比特一组)
- 对求和结果进行进位运算
- 对求和结果进行按位取反
举例:
假设一个 IP 数据报的首部如下:
| 字段 | 值 | 二进制 |
|---|---|---|
| 版本 | 4 | 0100 |
| 首部长度 | 5 | 0101 |
| 服务类型 | 0 | 0000 |
| 总长度 | 100 | 0000 0000 0110 0100 |
| 标识 | 1234 | 0000 0100 1011 0110 |
| 标志 | 0 | 000 |
| 片偏移 | 0 | 0 0000 0000 0000 |
| 生存时间 | 8 | 0000 1000 |
| 协议 | 6 | 0000 0110 |
| 首部校验和 | 0 | 0000 0000 0000 0000 |
| 源地址 | 192.168.1.1 | 1100 0000 1010 1000 0000 0001 0000 0001 |
| 目的地址 | 10.0.0.1 | 0000 1010 0000 0000 0000 0000 0000 0001 |
注意:上表中的首部检验和值是固定的,因为目前还在计算首部检验和,该字段在计算前视为0。
- 将首部所有字段视为 16 位字,并进行二进制求和:
cpp
0100 0101 0000 0000 [版本+首部长度+服务类型]
0000 0000 0110 0100 [总长度]
0000 0100 1011 0110 [标识]
0000 0000 0000 0000 [标志+片偏移]
0000 1000 0000 0110 [生存时间+协议]
0000 0000 0000 0000 [首部检验和]
1100 0000 1010 1000 [源地址前16位]
0000 0001 0000 0001 [源地址后16位]
0000 1010 0000 0000 [目的地址前16位]
0000 0000 0000 0001 [目的地址后16位]对以上所有数进行加法运算得到:
cpp
0001 0001 1101 1100 1010可以看到,我们原先的所有数都是16位,这里变成了17位,即发生了进位,此时就要进行第二步进位运算。
- 对求和结果进行进位运算:
cpp
0001 0001 1101 1100 1010拆出后16位:0001 1101 1100 1010,多出的位是0001,也就是1。对于进位,我们的处理方式为:将其重新加到后16位中。
也就是:
cpp
0001 1101 1100 1010
+
0000 0000 0000 0001结果为:
cpp
0001 1101 1100 1011注意:该部分在第二次计算后,有可能还会发生进位,此时要重复该过程,直到没有进位。
- 对求和结果进行按位取反:
最后把结果取反:
cpp
1110 0010 0011 0100这个值就是首部检验和。
接收方接收到数据报后,只需要以相同的方式进行计算,如果结算结果为0,说明首部没有发生错误。如果为非0,说明发生了错误,丢弃该报文。
流程图如下:

剩下的目的地址,源地址很好理解,不做讲解。
可变部分 : 填充字段

可选字段用来填入一些选项,可以用来支排错,测量等各种安全措施,但是实际上很少被使用。我们不过多讲解该字段。
对于填充,这是因为可选字段的长度不确定,而数据报的首部长度必须是4 byte的整数倍,这个填充字段,就是为了把可选字段填充到4 byte的整数倍的。
ICMP协议
ICMP(Internet Control Message Protocol,互联网控制报文协议)是 TCP/IP 协议族中的一个重要组成部分,它负责在网络设备之间传递控制信息,例如错误报告、状态信息等。
ICMP报文被封装在IP数据报的数据部分,但是其是属于IP层的协议,而不是高层协议
ICMP报文格式:

| 字段 | 长度 | 描述 |
|---|---|---|
| 类型 | 8 位 | 标识 ICMP 报文的类型,例如错误报告、查询等。 |
| 代码 | 8 位 | 对类型字段的进一步解释,例如错误的具体原因。 |
| 校验和 | 16 位 | 用于校验 ICMP 报文本身的完整性。 |
而第二行这个区域,会根据不同类型的报文,而有不同的格式。
ICMP报文主要分为两类:ICMP 差错报告和ICMP 询问报文
而这两个类型又被细分为更多的类型,在此我举例一部分:
- 终点不可达 :当主机或路由器不能交付数据报时,就向源点发送
终点不可达报文,再根据代码字段来描述更加具体的原因。

以上示例中,路由器R1受到数据报后,不知道如何转发,于是丢弃数据报,发送终点不可达。
- 源点抑制 :当主机或路由器因为阻塞而丢弃数据报时,就向源点发送
源点抑制报文

以上示例中,主机H2发送拥塞,丢弃报文后向源点发送源点抑制报文
- 时间超过 :当
IP数据报中的RTT减为0时,丢弃该数据报,向源点发送时间超过报文

以上示例中,数据报在经过R2时RTT = 0,,丢弃该数据报,向源点发送时间超过报文
- 参数问题 :当主机或路由接收到
IP数据报后,会检测其中的校验和字段,如果发现错误,就丢弃该报文,并向源点发送参数问题报文

以上示例中,当路由器R1收到IP数据报后,检测其中的校验和字段,如果发现首部出现错误,就丢弃该报文,并向源点发送参数问题报文
- 改变路由 :当主机或路由收到数据报后,发现可以通过更好的路线传送,就丢弃该报文,并向源点发送
改变路由报文

以上示例中,当路由器R1收到IP数据报后,发现可以通过R4更快传送,就丢弃该报文,并向源点发送改变路由报文。
以上只是一部分示例,以上全部示例中,各个类型的ICMP 差错报告报文对应的类型字段的值如下:
| 类型 | 终点不可达 | 源点抑制 | 时间超过 | 参数问题 | 改变路由 |
|---|---|---|---|---|---|
| 字段值 | 3 | 4 | 11 | 12 | 5 |
对于ICMP 询问报文,也有部分类型字段取值:
| 类型 | 回送请求/回答 | 时间戳请求/回答 |
|---|---|---|
| 字段值 | 8 / 0 | 13 / 14 |
对于询问报文,就不再举例了。
讲完了ICMP的首部,再来看看ICMP的数据部分,其实ICMP差错报告报文的数据部分格式也是固定的。
格式如下:
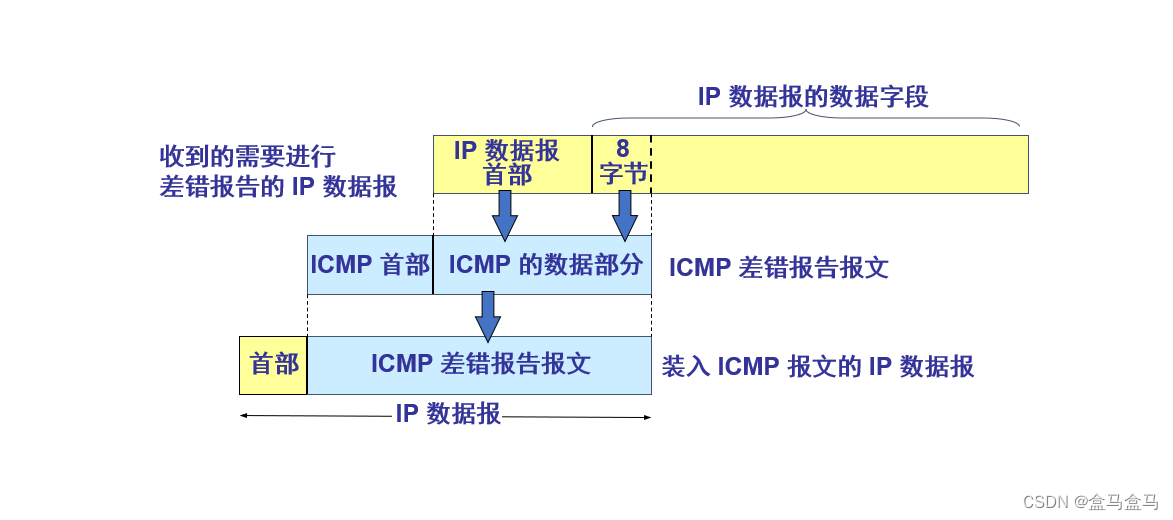
取出IP数据报的首部,以及数据部分的前八个字节,构成ICMP的数据部分。
主要是要在ICMP报文中体现一些重要信息,以便源点分析具体原因。而大部分重要信息都在首部中,所以存储了IP数据报的首部。另外的IP数据报的数据部分的前八个字节,还包含一些运输层端口相关信息,也被纳入ICMP的数据部分。