Redis集群
Redis提供了持久化能力,保证了重启不会丢失数据;但Redis重启至完全恢复期间,缓存不可用。另外,对于高并发场景下,单点Redis服务器的性能不能满足吞吐量要求,需要进行横向扩展。此时,可通过搭建Redis集群解决如上两个问题。按照并发量和具体业务的要求,可以部署三种架构的集群:主从模式、哨兵模式、Cluster模式,以下分章节分别进行介绍。
1.Redis主从复制
1.1 流程介绍
主从复制的整体流程可用下图表示:
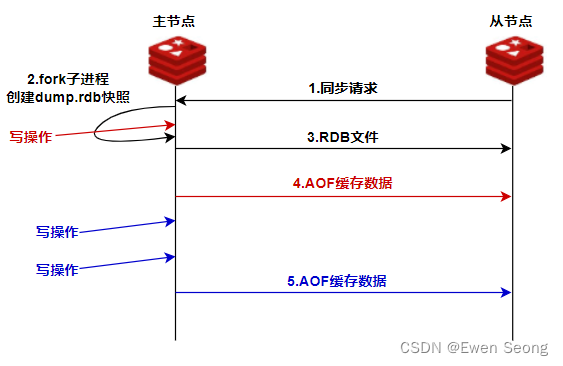
具体流程 :
【1】从节点向主节点发送PSYNC命令(旧版本Redis发送SYNC)建立连接;
【2】主节点收到PSYNC消息后,判断是否需要全量同步:第一次连接时触发全量同步,通过BGSAVE机制将内存快照保存为RDB文件中,并将RDB文件发送给从节点;否则,触发增量同步(如主从节点因网络等原因断开重连);
【3】从节点将数据清空后,将RDB文件的数据写入内存;
【4】此过程中主节点的累积的写操作以AOF文件的形式增量同步至从节点;
【5】之后,主节点的所有写操作,通过AOF文件以增量形式通知从节点。
总之,从节点第一次同步数据以RDB形式进行全量同步,后续以AOF形式进行增量同步。
1.2 环境搭建
在持久化文章中为快速搭建演示环境,使用了docker方式安装Redis;
本文中,为了方便搭建集群,使用二进制的方式运行Redis.
本地安装Redis:
shell
#下载和安装Redis
wget http://download.redis.io/releases/redis-5.0.4.tar.gz
tar xzf redis-5.0.4.tar.gz
cd redis-5.0.4
make
#启动redis(不指定配置文件时使用根目录下的redis.conf)
src/redis-server
#使用客户端连接
src/redis-cli
redis> set foo bar
OK
redis> get foo
"bar"
#使用客户端关闭redis
redis> shutdown说明:每运行redis-server一次,会创建一个独立的Redis进程,需要注意使用不同的配置文件,以防止端口冲突。
集群搭建:
搭建如下图所示的主从集群, 包含1个主节点以及两个从节点:主节点监听6001端口,从节点分别监听6002和6003端口。

step1: 准备redis.conf文件
为每个redis实例准备一份redis.conf文件
shell
#创建测试用例目录
mkdir -p /temp/slaveof/6001
mkdir -p /temp/slaveof/6002
mkdir -p /temp/slaveof/6003
#将redis根目录下的redis.conf复制到测试用例目录下
cp redis.conf /temp/slaveof/6001/
cp redis.conf /temp/slaveof/6002/
cp redis.conf /temp/slaveof/6003/
#修改监听的端口号
sed -i 's/6379/6001/g' /temp/slaveof/6001/redis.conf
sed -i 's/6379/6002/g' /temp/slaveof/6001/redis.conf
sed -i 's/6379/6003/g' /temp/slaveof/6001/redis.confstep2: 配置主从关系
在从节点6001和6002中执行
shell
slaveof 127.0.0.1 6001也可以在redis.conf文件中加入slaveof配置.
step3: 启动redis
shell
./redis-server /temp/slaveof/6001/redis.conf
./redis-server /temp/slaveof/6002/redis.conf
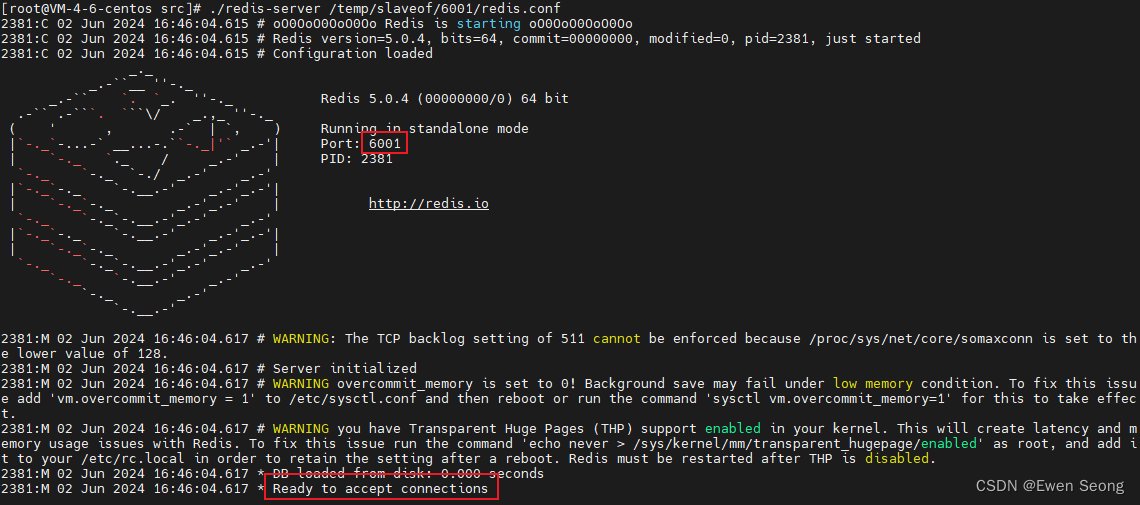
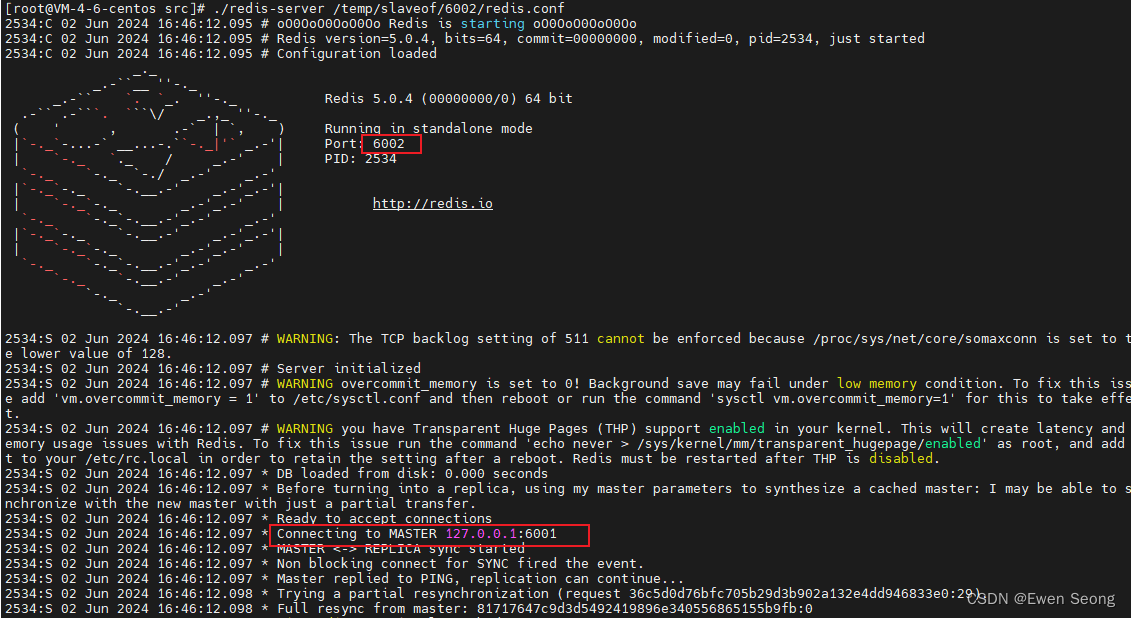
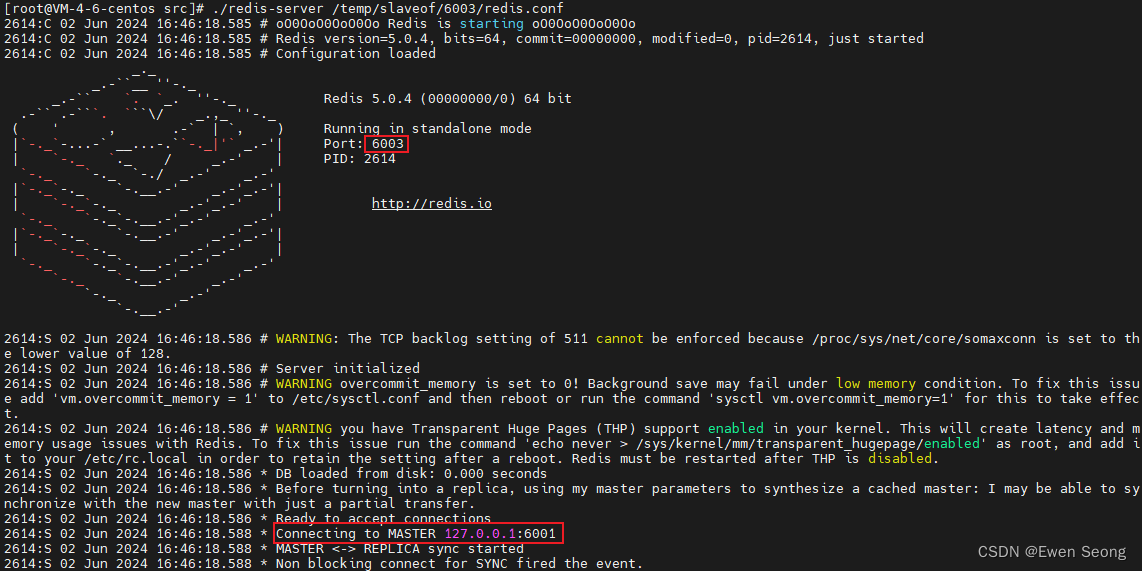
./redis-server /temp/slaveof/6003/redis.conf启动日志如下所示:
主节点6001, 接收6002和6003的连接请求:
从节点6002, 连接到6001:
从节点6003, 连接到6001:
step4: 读写数据
shell
#主节点写入数据
主节点6001:0>set key1 value1
"OK"
主节点6001:0>get key1
"value1"
#从节点读取数据,可以读取写入主节点的数据
从节点6002:0>get key1
"value1"
#从节点写数据,抛出异常
从节点6002:0>set key2 value2
"READONLY You can't write against a read only replica."说明:主节点可读写,从节点只读;主节点写入的数据,通过redis主从复制机制同步至从节点。
另外,从节点后也可以添加从节点,如下所示:

只需要将6003节点中redis.conf的slaveof 设置为6002节点,即将"slaveof 127.0.0.1 6001"修改为"slaveof 127.0.0.1 6002".
2.哨兵模式
主从模式的主节点和从节点固定,程序不能自动切换。当主节点宕机时,整个缓存将不可写,直到手动恢复主节点(或者将幸存的从节点设置为主节点)为止。
如章节1.2中存在 主节点(6001)和从节点(6002和6003), 如果主节点down机了,可以依次执行如下命令恢复环境:
shell
#不妨将6002设置为主节点
主节点6002:>slaveof no one
主节点6003:>slaveof 127.0.0.1 6002对于实际场景,显然不能通过手动方式去切换主从节点。哨兵模式的引入为其提供了一个解决方案,主从切换实现自动化。可以推断:哨兵需要具备识别主节点down机,从从节点选取主节点,调整节点的主次状态等三种能力。
2.1 流程介绍
在流程介绍之前,有必须关注一下主观离线和客观离线以及sentinel.conf(哨兵配置文件)中的配置项。
主观离线和客观离线:
哨兵与Redis主/从节点之间通过心跳保活,当哨兵发现某个节点超时未发心跳消息,认为这个节点离线,称为主观离线(主观怀疑,可能是网络问题,也可能离线了);此哨兵会询问其他哨兵该节点的状态信息,当足够数量的哨兵都主观认为Redis节点离线时,Redis客观离线(确实离线)。
配置项:
1 配置监听的主节点
sentinel monitor <master-name> <ip> <port> <quorum>master-name表示主节点名称-自定义; ip和port表示主节点的ip和端口;quorum为主观离线转转客观离线的标准。如sentinel monitor mymaster 127.0.0.1 6379 2表示:哨兵监听主节点(127.0.0.1:6379),当有2个哨兵主观认为主节点离线时,此节点被标记为客观离线。
2 配置主观离线时间
sentinel down-after-milliseconds <master-name> <milliseconds>milliseconds表示Redis节点的心跳超时时间。当心跳超时后,哨兵认为该节点主观离线。
如sentinel down-after-milliseconds mymaster 30000设置超时时间为30s.
3 配置通知脚本
当哨兵监听事件发生时,会调用配置的脚本,启动时需要保证该脚本存在。
sentinel notification-script <master-name> <script-path>
sentinel client-reconfig-script <master-name> <script-path>script-path为脚本的存放路径。配置notification-script时,有节点主观或者客观离线会触发;配置client-reconfig-script时,只有故障转移(主节点替换)时才会触发。
哨兵模式的工作流程如下:
1 哨兵启动后,与Redis的主从节点建立心跳连接机制;
2 哨兵每秒向Redis节点发送PING心跳消息,等待PONG心跳回复消息;
3 当哨兵超时(大于down-after-milliseconds)未收到节点信息时,将该节点标记为主观离线;
4 哨兵向其他哨兵发送请求,获取该节点的状态,如果超过quorum数量的哨兵认为该节点离线,将该节点标记为客观离线;
5 如果该节点为主节点,触发故障转义流程;
6 哨兵间会选举一个leader,用于主导故障转义流程;
7 哨兵leader根据条件从从节点中选出主节点A(127.0.0.1 6001);
8 将选出的节点设置为主节点(slaveof no one),将其他节点设置为该节点的从节点(slaveof 127.0.0.1 6001);
其中,哨兵leader选择主节点的条件如下:
(1)排除主观离线的节点;
(2)排除优先级(slave-priority)为0的节点;
(3)选择优先级最高的节点;
(4)优先级相同,选择复制偏移量最大的节点(与原master数据重合度更高);
2.2 环境搭建
在章节1.2 的基础上添加两个哨兵,如下图所示:
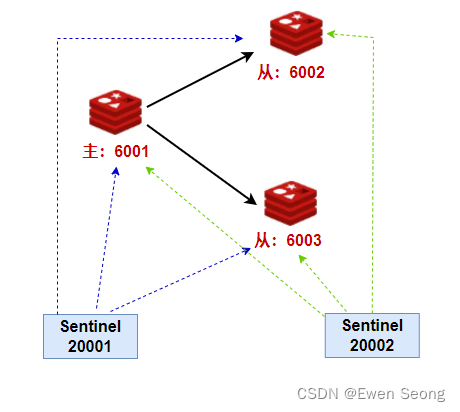
step1: 准备redis.conf文件
为每个哨兵准备一份redis.conf文件
shell
#创建测试用例目录
mkdir -p /temp/sentinel/20001
mkdir -p /temp/sentinel/20002
#将redis根目录下的sentinel.conf复制到测试用例目录下
cp sentinel.conf /temp/sentinel/20001/
cp sentinel.conf /temp/sentinel/20002/
#修改哨兵监听的端口号
sed -i 's/26379/20001/g' /temp/sentinel/20001/sentinel.conf
sed -i 's/26379/20002/g' /temp/sentinel/20002/sentinel.confstep2:添加哨兵的检测规则
shell
#设置监控的redis主节点的ip、port和quorum(当认为master主节点主观失联的哨兵数超过quorum,主节点客观失联)
sentinel monitor mymaster 127.0.0.1 6001 2
#主节点响应答哨兵的超时时间, 默认30秒
sentinel down-after-milliseconds mymaster 5000
# 故障转移的超时时间(r两次failover的间隔时间)
sentinel failover-timeout mymaster 60000同时修改工作目录和日志配置:
shell
pidfile "/temp/sentinel/20001/redis-sentinel.pid"
logfile ""
dir "/temp/sentinel/20001/tmp"step3:启动哨兵程序
shell
./redis-sentinel /temp/sentinel/20001/sentinel.conf
./redis-sentinel /temp/sentinel/20002/sentinel.conf启动日志如下所示:
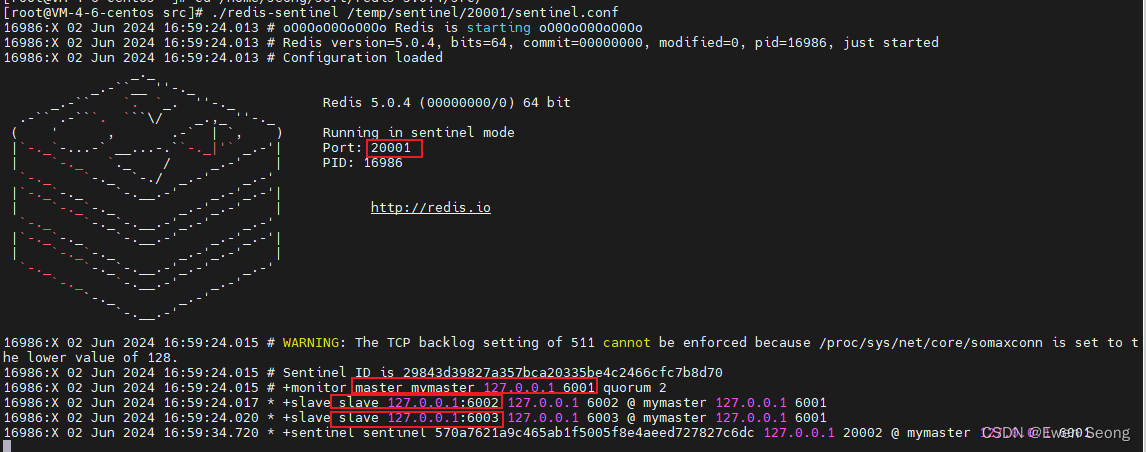
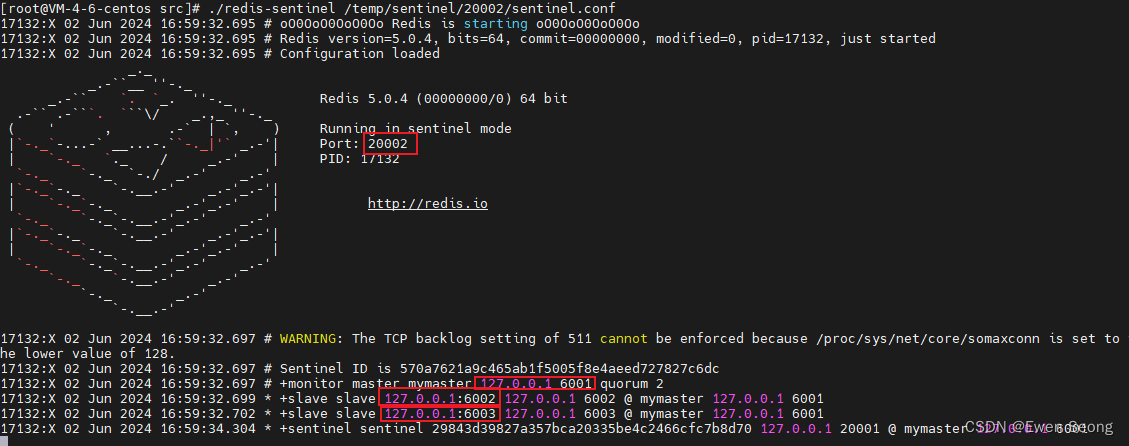
step4:重启主节点(以检测哨兵的反应)
(1) 通过info replication查看各个节点的状态:
shell
67-6001:0>info replication
"# Replication
role:master
connected_slaves:2
slave0:ip=127.0.0.1,port=6002,state=online,offset=424559,lag=1
slave1:ip=127.0.0.1,port=6003,state=online,offset=424559,lag=1
...
"
67-6002:0>info replication
"# Replication
role:slave
master_host:127.0.0.1
master_port:6001
...
"
67-6003:0>info replication
"# Replication
role:slave
master_host:127.0.0.1
master_port:6001
...
"此时6001为主节点,6002和6003为从节点。
(2) 手动停止6001节点:
shell
67-6001:0>shutdown此时,6002和6003报错,连接主节点失败:

当哨兵检测到6001主节点宕机后,进行节点选举:

选举完成后,将结果通知给各节点。此时选择了6003作为主节点, 再次查看6003节点的信息:
shell
67-6003:0>info replication
"# Replication
role:master
connected_slaves:1
slave0:ip=127.0.0.1,port=6002,state=online,offset=459708,lag=0
...
"3.cluster集群
3.1 流程介绍
支持多个master节点,每个master节点可以有多个slave节点,master可写而slave只读;cluster集群自带故障转移能力,不需要配置哨兵。
没有中心节点,对数据进行分片存储,每个master节点存储不同的数据;当有master节点宕机时,不影响其他节点的读写。
Redis节点通过gossip协议建立集群。
gossip工作原理是节点间的信息交换:不断地信息交换,很快所有节点都会拥有集群的完整信息,如同流言散播。
gossip协议包括meet,ping,pong,fail等消息类型:meet用于加入集群,ping用于心跳和数据交换,pong用于ping和meet的返回消息;fail用于广播节点宕机。
集群内部通过分片机制,每个redis节点负责整体数据的一个子集,数据和节点之间存在映射关系。
因此,在数据和redis节点之间引入了哈希槽的概念:一个集群固定有16384(2^14-1)个槽位,每个Redis节点分配一段槽位范围(slot range),数据(key)经过哈希算法得到一个哈希槽(slot),算法为CRC16(key) % 16384,
从而确定所属节点。
由于每个节点只负责部分slot(数据库子集), 且slot可能发生前移,使得客户端请求变得复杂。
Cluster集群通过重定向机制解决该问题,重定向机制包括两个消息类型:MOVED和ASK。
当客户端将一个数据操作发送给Redis实例时,如果这个数据所在的slot不是由该Redis实例负责,
该实例会返回一个MOVED消息,如下所示:
(error) MOVED 12345 127.0.0.1:6001
表示客户端正在操作的数据的slot是12345,这个槽点在127.0.0.1:6001实例上。
当客户端请求的数据所在的slot正在前移至另一个Redis实例,
此时给客户端响应一个ASk消息,如下所示:
(error) ASK 12345 127.0.0.1:6002
表示客户端正在操作的数据的slot是12345,这个槽点正在前移到127.0.0.1:6002实例上。
另外,客户端自身也会维护一份槽与节点的映射关系,当客户端操作数据时,先计算键的哈希值并根据映射关系找到对应的节点,然后将数据请求发送给对应节点。
3.1 环境搭建
以章节1为基础,搭建一个三主三从的cluster集群。
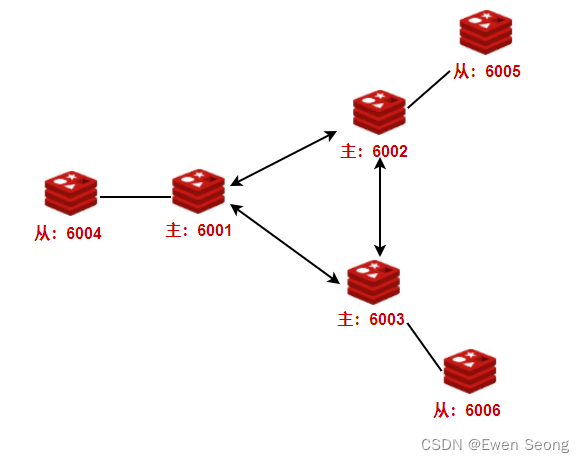
step1.准备配置文件
将/temp/slaveof/6001文件夹下的redis.conf配置文件复制6份, 并分别修改端口号为6001-6006:
shell
/temp/cluster/6001/redis.conf 中端口port修改为 6001
/temp/cluster/6002/redis.conf 中端口port修改为 6002
/temp/cluster/6003/redis.conf 中端口port修改为 6003
/temp/cluster/6004/redis.conf 中端口port修改为 6004
/temp/cluster/6005/redis.conf 中端口port修改为 6005
/temp/cluster/6006/redis.conf 中端口port修改为 6006step2.配置为集群模式
在redis.conf文件中添加配置项:
cluster-enabled yesstep3.启动所有节点
shell
./redis-server /temp/cluster/6001/redis.conf
./redis-server /temp/cluster/6002/redis.conf
./redis-server /temp/cluster/6003/redis.conf
./redis-server /temp/cluster/6004/redis.conf
./redis-server /temp/cluster/6005/redis.conf
./redis-server /temp/cluster/6006/redis.confstep4.创建集群
shell
./redis-cli --cluster create --cluster-replicas 1 \
127.0.0.1:6001 \
127.0.0.1:6002 \
127.0.0.1:6003 \
127.0.0.1:6004 \
127.0.0.1:6005 \
127.0.0.1:6006结果如下所示:
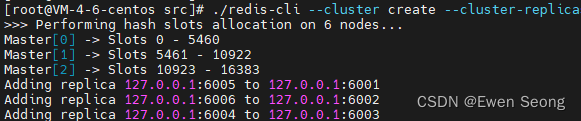
此时,主节点为6001,6002,6003, 对应从节点分别为6005,6006,6004.
step5.查看集群节点状态
使用info replication命令查看6001-6005主从节点的状态。
6001节点:
shell
127.0.0.1:6001> info replication
# Replication
role:master
connected_slaves:1
slave0:ip=127.0.0.1,port=6005,state=online,offset=434,lag=1
master_replid:1b684bf671a34b36f80422b41a39eb887f0c15e0
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:434
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:434显示6001为主节点,6005为其从节点。
6005节点:
shell
127.0.0.1:6005> info replication
# Replication
role:slave
master_host:127.0.0.1
master_port:6001
master_link_status:up
master_last_io_seconds_ago:8
master_sync_in_progress:0
slave_repl_offset:546
slave_priority:100
slave_read_only:1
connected_slaves:0
master_replid:1b684bf671a34b36f80422b41a39eb887f0c15e0
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:546
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:546