1. 问题描述
产品:我要对订单列表页做一个分页功能,每页10条数据,商家可以根据金额过滤订单
技术:好的,我写一个sql实现分页,x表示偏移页数,自测limit 10,10耗时200ms:
sql
SELECT * FROM `order` WHERE `amount` > 0 limit x,10;功能演示时,产品点击第1000万页,页面因为接口超时空白,查看sql耗时10000ms
技术:(汗流浃背)这么简单的sql怎么会超时,amount也加了普通索引...
2. 相关知识点
2.1 MySQL索引通过B+树结构存储
B+树特点:内部节点包含x个元素,标识子树最大值;叶子结点通过指针串联;
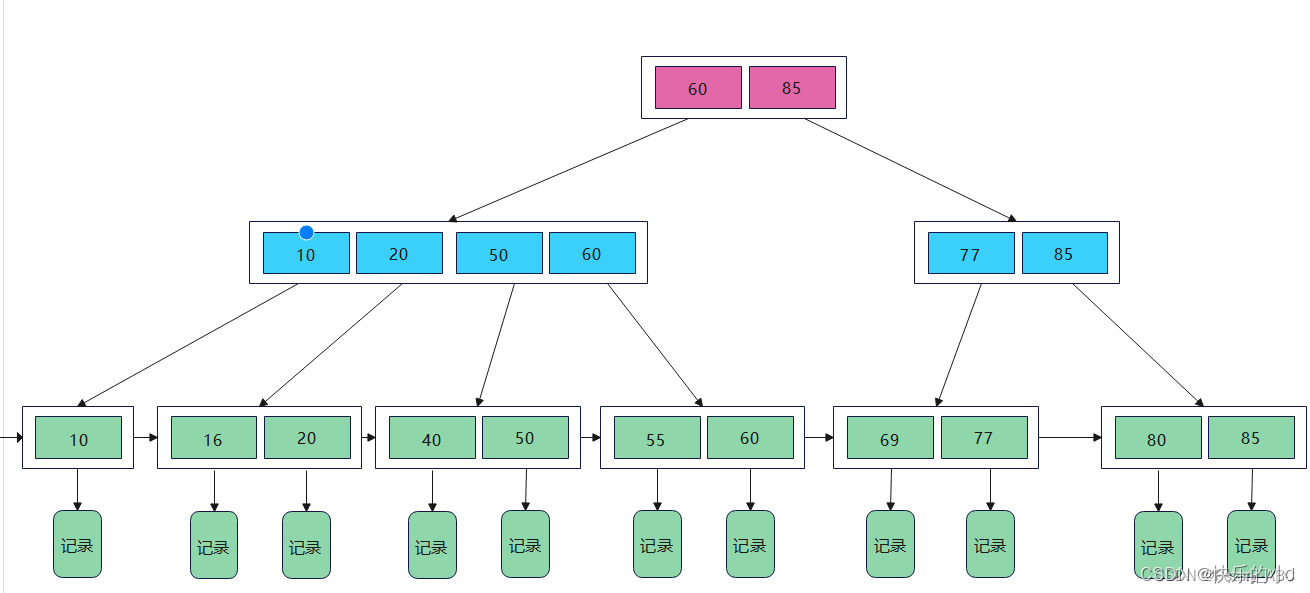
2.2 MySQL索引分为聚簇索引和非聚簇索引
(1)聚簇索引就是主键索引,一个数据表只能有一个聚簇索引,聚簇索引树的叶子结点是一条记录;
(2)非聚簇索引可以是唯一索引、普通索引等,非聚簇索引树的根节点存储主键id
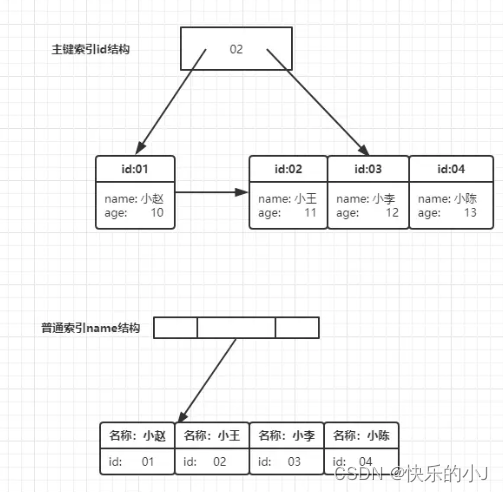
2.3 回表
通过非聚簇索引查找主键信息,再通过聚簇索引查找数据集的情况,称为回表
3. 原因分析
sql
SELECT * FROM `order` WHERE `amount` > 0 limit x,10;由于amount添加的是普通索引,每次执行该sql时
(1)筛选amount非聚簇索引树,拿到x+10(?)个主键id
(2)从聚簇索引树拿到相关数据
(3)筛选目标位置的10行返回
该过程需要回表x行数据,效率很低
4. 优化方法
sql
SELECT * FROM `order` WHERE id in
(SELECT id FROM `order` WHERE `amount` > 0 LIMIT x,10);(1)括号内部分仅检索非聚簇索引树,查找x+10(?)个主键id(与3节的第一步相同)
(2)拿到指定位置的10个主键id
(3)外层查询仅检索聚簇索引树,查找10行数据返回
仅需回表10条数据,good