6月中旬,智源研究院旗下的 FlagEval 大模型评测平台发布最新榜单:在有标准答案的"客观评测"中,GPT-4 以76.11分在闭源大模型中排名第一;Doubao-Pro(豆包大模型)以75.96分排名第二,同时也是得分最高的国产大模型;其后依次是 ERNIE 4.0、Baichuan3、Moonshot-v1。在开放问答等"主观评测"中,Doubao-Pro 同样排名第二,得分超过 GPT-4o 和 GPT-4。
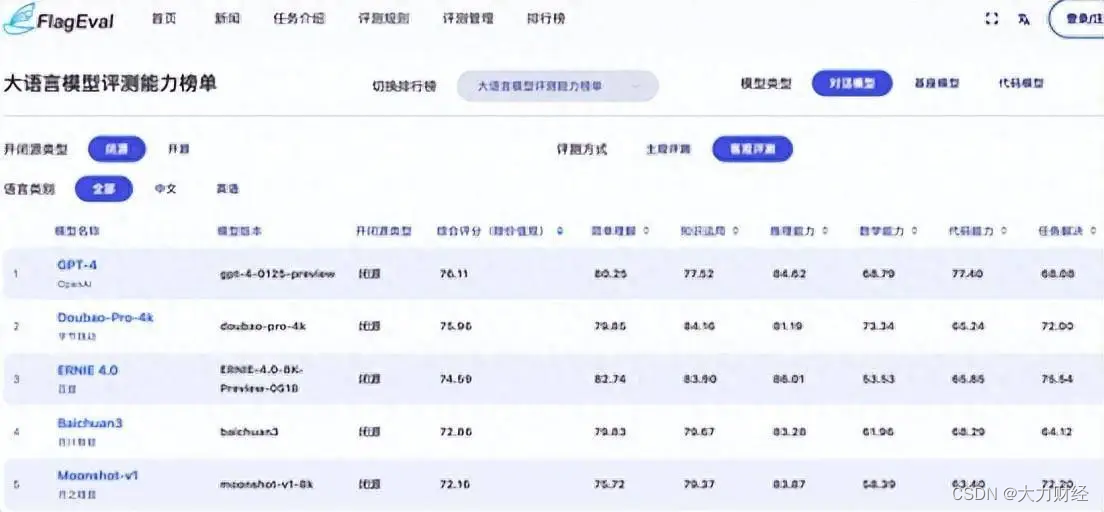
图:豆包大模型在 FlagEval 客观评测中获综合评分第二(2024年6月)
FlagEval 大模型评测平台由智源研究院与多个高校团队共建,以人类认知能力的发展阶梯为基准,对齐大模型所能达到的认知水平。FlagEval 构建了大量原创的非公开评测集,确保评测质量和公正性。自2023年6月上线以来,FlagEval 已完成了1000多次覆盖全球大模型的评测。
Doubao-Pro 是由字节跳动自主研发的大语言模型,于5月15日正式发布。本期 FlagEval 大模型排行榜,是豆包大模型在公开评测中的首次亮相。
测试成绩显示,豆包大模型的数学能力、知识运用、任务解决等多项能力在客观评测和主观评测中都有着出色表现。其中,知识运用和数学能力得分排名客观评测第一、主观评测前三,任务解决测试得分在主客观评测中均排名前三。
数学能力是评估大模型是否"聪明"的一个重要维度。此前,复旦大学自然语言处理实验室就2024 年高考数学题对13家主流大模型产品进行评测,豆包的数学高考新课标 II 卷答题获得最高分,客观题正确率达到 74.66%,成绩优于GPT-4o及国内多款大模型产品。
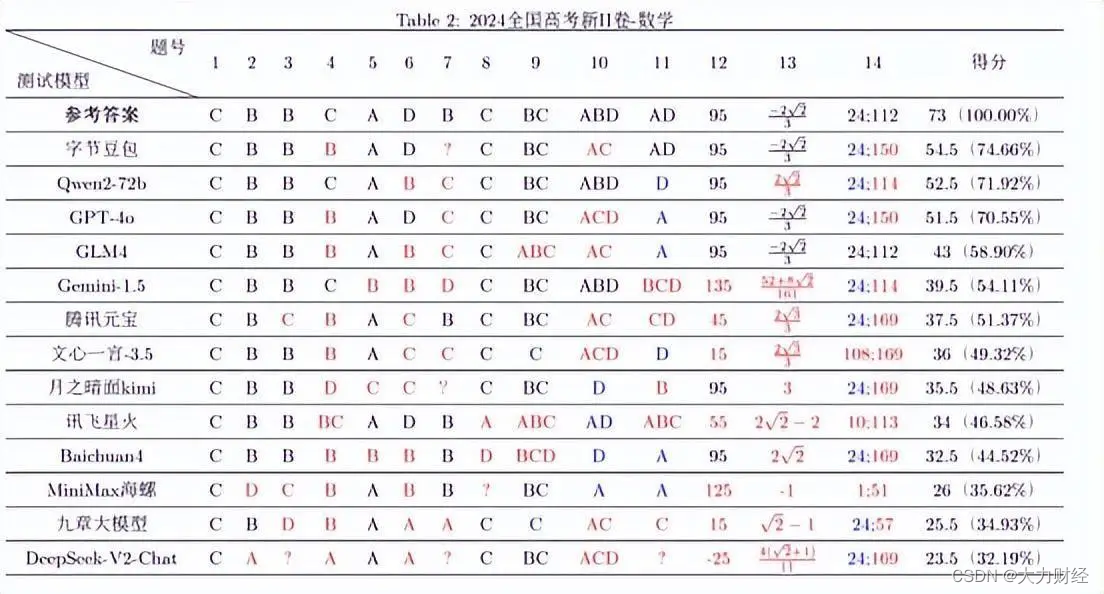
图片来源:复旦NLP实验室公众号
据悉,豆包大模型是国内使用量最大、应用场景最丰富的大模型之一,日均处理 token 达到千亿级。其同名AI对话助手"豆包",在苹果APP Store和各大安卓应用市场的AIGC类应用中下载量排名第一。目前,豆包大模型正在通过字节跳动旗下的火山引擎向企业市场开放服务,已经与OPPO、荣耀、小米、三星、华硕等智能终端厂商建立合作。