目录
1.插入排序
基本思想:把一个待排数字按照关键码值插入到一个有序序列中,得到一个新的有序序列。
1.1直接插入排序
简介
直接插入排序即是直接把一个待排数字插入一个有序序列的这种插入排序方法。
这类似于打牌时插排的情况:
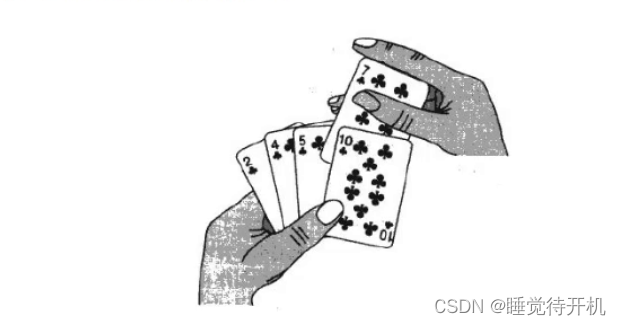
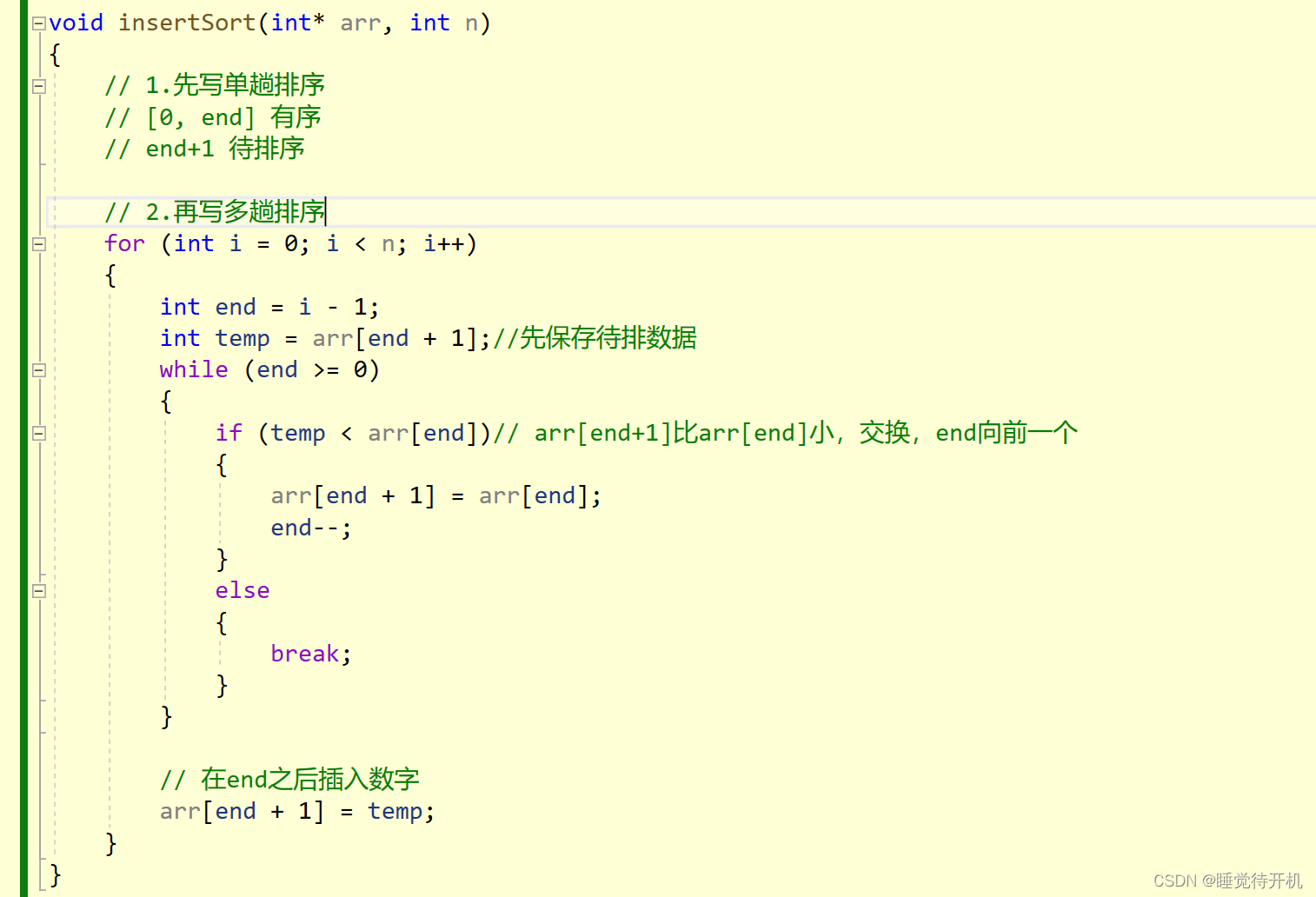
我们写直接插入排序应该先写好单趟插入排序再写完整体的插入排序。
代码
我们假设要排升序。
且假设0,end有序,让end+1的数字插入到有序序列当中。
单趟插入排序:
直接插入排序的单趟存在下面两种情况:

每个数的插入:

完整插入排序:
我们由单趟直接插入排序扩展到多趟的插入排序。
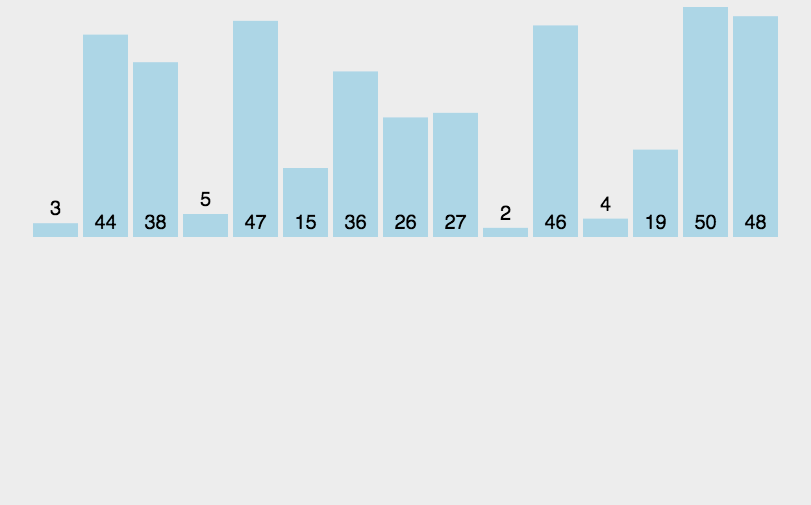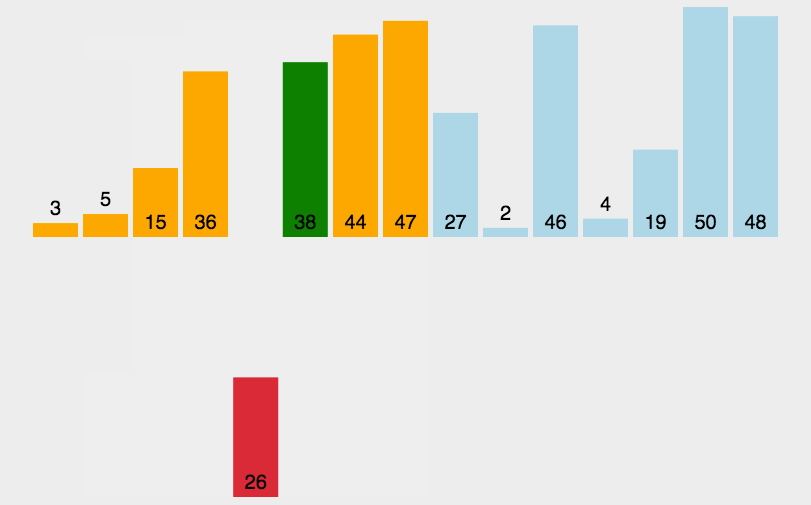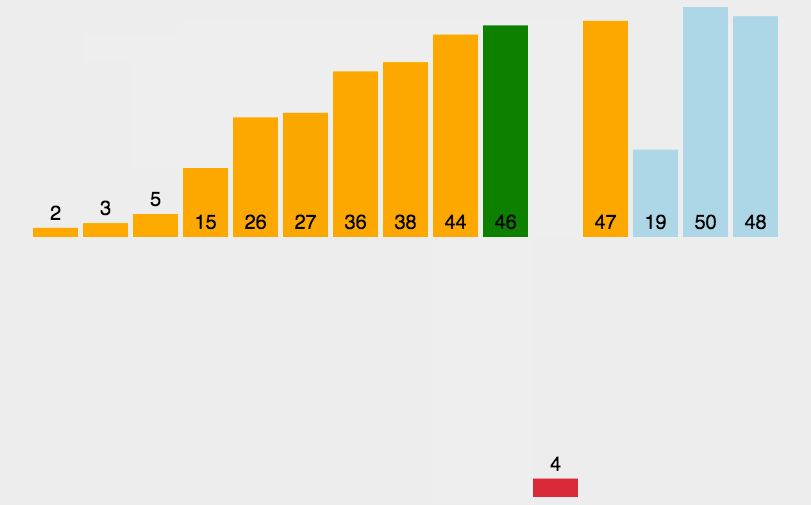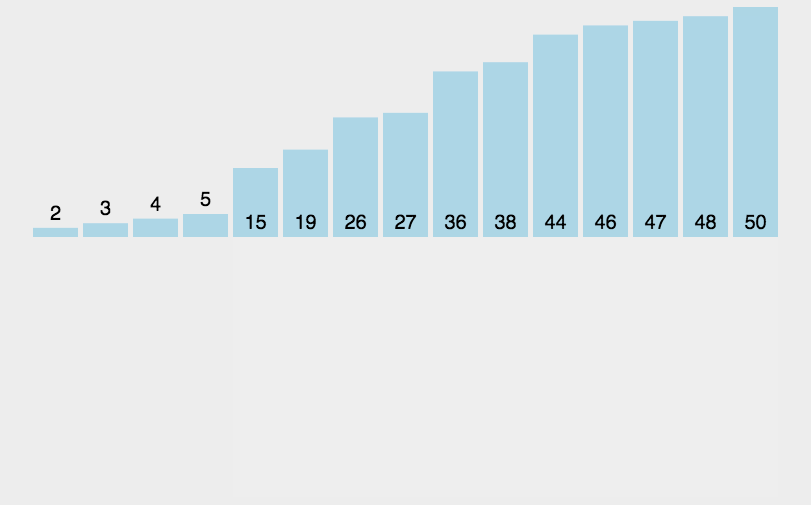
问:数组位置0处可以存数据个数吗?
特殊情况下可以,但是不建议。

分析
最坏情况:O(N^2)
最好情况:O(N)
结论:直接插入排序适合基本有序的序列排序,不适合逆序排序。
插入排序在基本有序的情况下,时间复杂度接近O(N),因而直接插入排序比较适合于基本有序的序列排序。
但是,一旦碰到逆序的序列,时间复杂度直接到了O(N^2)。
1.2直接插入对比冒泡排序
与直接插入排序相似思路的是冒泡排序
简介
略。
代码
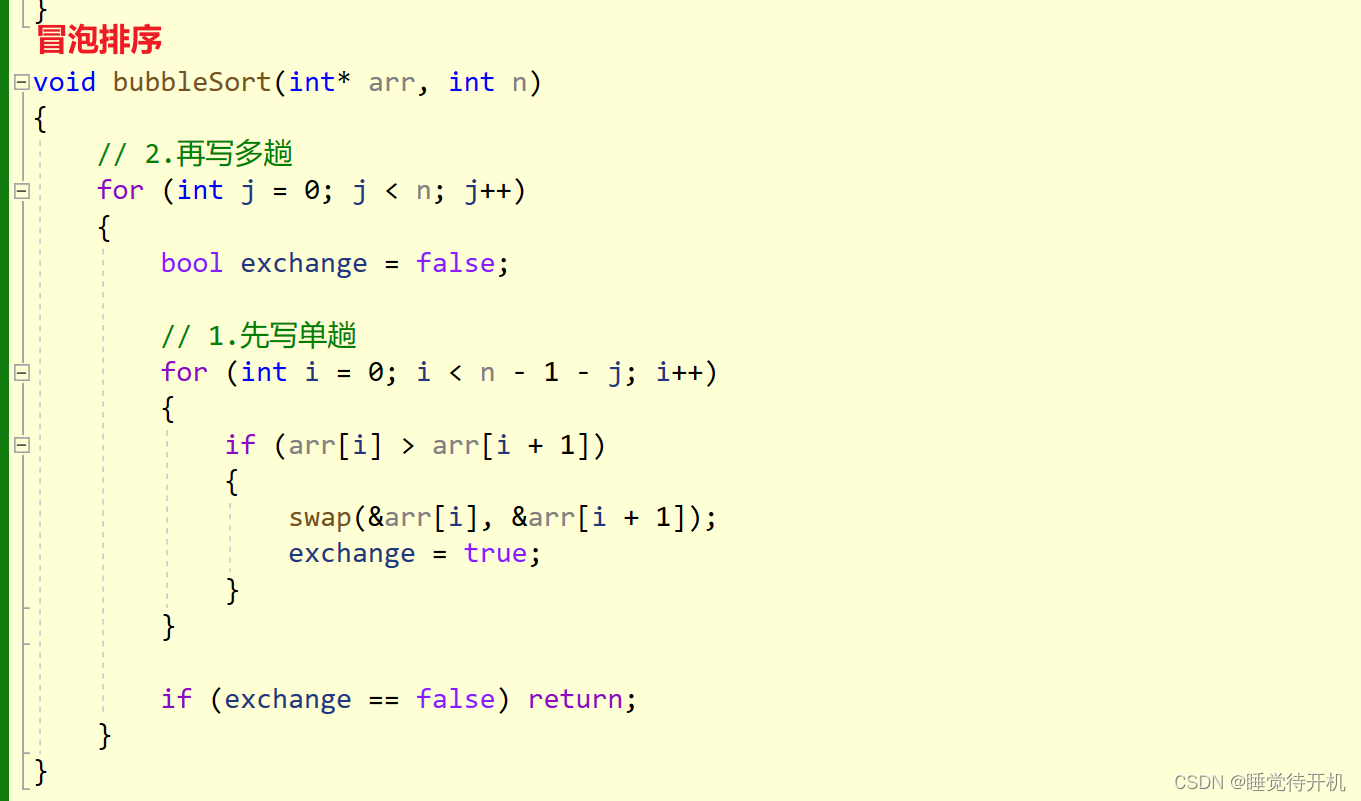
对比分析(直接插入排序与冒泡的复杂度效率区别)
最好的时间复杂度:O(N)
最差的时间复杂度:O(N^2)
冒泡排序与直接插入排序是一个量级的。但是仍然还有一些细微区别:
c
void TestOP()
{
srand(time(0));
const int N = 10000;
int* a1 = (int*)malloc(sizeof(int) * N);
int* a2 = (int*)malloc(sizeof(int) * N);
int* a3 = (int*)malloc(sizeof(int) * N);
int* a4 = (int*)malloc(sizeof(int) * N);
int* a5 = (int*)malloc(sizeof(int) * N);
int* a6 = (int*)malloc(sizeof(int) * N);
int* a7 = (int*)malloc(sizeof(int) * N);
for (int i = 0; i < N; ++i)
{
a1[i] = rand();
a2[i] = a1[i];
a3[i] = a1[i];
a4[i] = a1[i];
a5[i] = a1[i];
a6[i] = a1[i];
a7[i] = a1[i];
}
int begin1 = clock();
insertSort(a1, N);
int end1 = clock();
int begin2 = clock();
//ShellSort(a2, N);
int end2 = clock();
int begin3 = clock();
//SelectSort(a3, N);
int end3 = clock();
int begin4 = clock();
//HeapSort(a4, N);
int end4 = clock();
int begin5 = clock();
//QuickSort(a5, 0, N - 1);
int end5 = clock();
int begin6 = clock();
//MergeSort(a6, N);
int end6 = clock();
int begin7 = clock();
bubbleSort(a7, N);
int end7 = clock();
printf("InsertSort:%d\n", end1 - begin1);
printf("ShellSort:%d\n", end2 - begin2);
printf("SelectSort:%d\n", end3 - begin3);
printf("HeapSort:%d\n", end4 - begin4);
printf("QuickSort:%d\n", end5 - begin5);
printf("MergeSort:%d\n", end6 - begin6);
printf("BubbleSort:%d\n", end7 - begin7);
free(a1);
free(a2);
free(a3);
free(a4);
free(a5);
free(a6);
free(a7);
}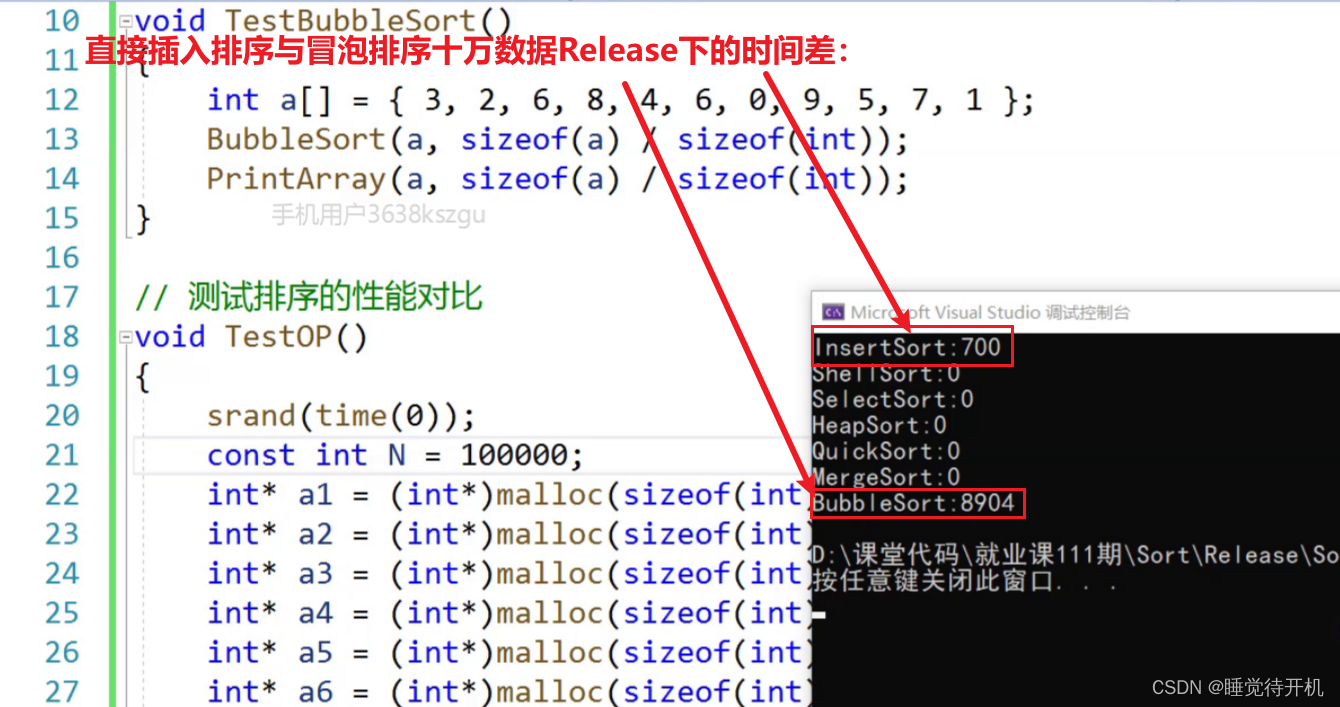
为什么会造成这种差异呢?
原因在于,冒泡排序每次单趟一定走n-1-i次(假设这是第i趟排序)。
但是,直接插入排序每次单趟一定小于或者等于走n-1-i次(假设这是第i趟排序),只有逆序情况下才与冒泡等价。
1.3希尔排序
简介
希尔排序就是先进行预排序,再进行排序的插入排序。
- 预排序(让序列接近有序)
- 直接插入排序
代码


分析
希尔排序时间复杂度是O(N^1.3)
EOF