一、背景介绍
伴随信息技术地迅猛发展和应用范围地逐步扩大,数据库已成为企业存储与管理数据的重要工具。但数据量激增以及用户访问需求的与日剧增,数据库性能也将面临巨大挑战。
好在数据库物理计划执行是解决数据库性能问题的重要手段之一,我们可以通过对数据库物理结构进行合理规划和优化,提高数据库的查询速度、降低存储空间的占用率,从而提高数据库整体性能。
二、物理计划基础概念
2.1 算子执行
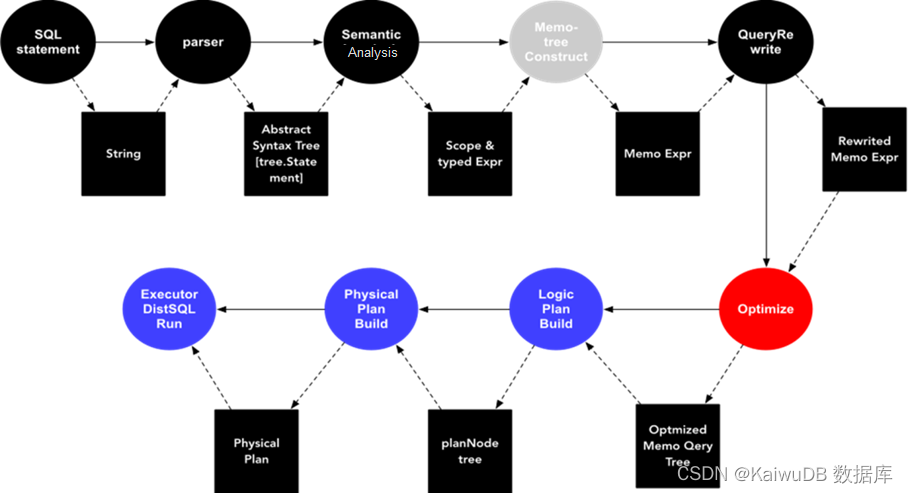
在数据库系统中,算子执行是指查询语句中的各种操作符(算子)实际执行的过程。数据库查询通常由一个或多个操作符组成,这些操作符包括选择、投影、连接、排序等,它们按照特定的顺序和方式执行来完成查询任务。以下是算子执行的常规过程:
- 解析查询语句
数据库系统首先会解析查询语句,识别其中的各种操作符和操作数,并构建查询执行计划(Query Execution Plan)。
- 查询优化
在执行计划构建过程中,数据库系统会进行查询优化,尝试找到最有效的执行计划以提高查询性能。其中会涉及到选择合适的索引、调整连接顺序、重新排列操作等优化策略。
- 执行计划生成
一旦查询优化完成,数据库系统会生成最终的执行计划,该计划描述了执行查询所需的具体步骤和顺序,以及每个步骤所需的算子。
- 算子执行
数据库系统按照执行计划中描述的顺序逐步执行各个算子。每个算子通常都会对输入的数据进行一些处理,并生成输出,供下一个算子使用。
- 结果返回
最后,当所有算子执行完成后,数据库系统将返回执行结果给用户或者应用程序。
整个执行过程如图所示,通过下述步骤,数据库系统能够高效地执行各种复杂的查询,并返回用户所需的结果,优化算子执行过程是提高数据库性能的关键之一。
2.2 物理计划
在数据库管理系统中,物理计划是指将逻辑查询转换为一系列物理操作的执行计划。物理计划是针对数据库物理结构而言的,它决定了数据库访问方式、数据存储方式、数据传输方式等,这些因素都将对数据库性能产生非常大的影响。
物理计划是将逻辑查询转化为物理操作的执行计划。数据库中的各种组件,如执行器、扫描器、排序器、连接器、聚合器、索引、缓存和分区等,都是物理计划执行的基础概念。
三、KaiwuDB 物理计划
3.1 物理计划组成
KaiwuDB 是一个分布式数据库系统,其物理计划与传统的关系型数据库系统有所不同,因为它需要考虑分布式数据存储和处理的特点。KaiwuDB 的物理计划通常会涉及到以下几个方面:
- 数据分布和复制
KaiwuDB 将数据分布到不同的节点上,并通过数据复制确保数据的高可用性和容错性。因此在执行查询时,物理计划需要考虑到数据的分布情况,以及在哪些节点上复制了查询所需的数据。
- 分布式查询处理
KaiwuDB 支持将查询分布到不同的节点上并行执行,以提高查询的性能。物理计划会涉及到如何将查询分解为多个子查询,并将这些子查询发送到不同的节点上执行,然后将结果合并。
- 数据传输和网络通信
由于数据存储在不同的节点上,KaiwuDB 的物理计划需要考虑如何在节点之间传输数据,并且需要最小化网络通信的开销。
- 分布式索引和统计信息
KaiwuDB 支持分布式索引和统计信息,物理计划会根据索引和统计信息来选择最优的查询执行路径,以提高查询的性能。
- 节点资源管理
在执行查询时,KaiwuDB 的物理计划需要考虑每个节点的资源利用情况,以避免节点过载或资源不均衡导致的性能问题。
总体来说,KaiwuDB 的物理计划与传统的关系型数据库系统类似,但在处理分布式数据存储和查询处理时有所不同。优化 KaiwuDB 的物理计划通常需要考虑到分布式环境下的特殊情况,以确保查询在整个集群中的高效执行。
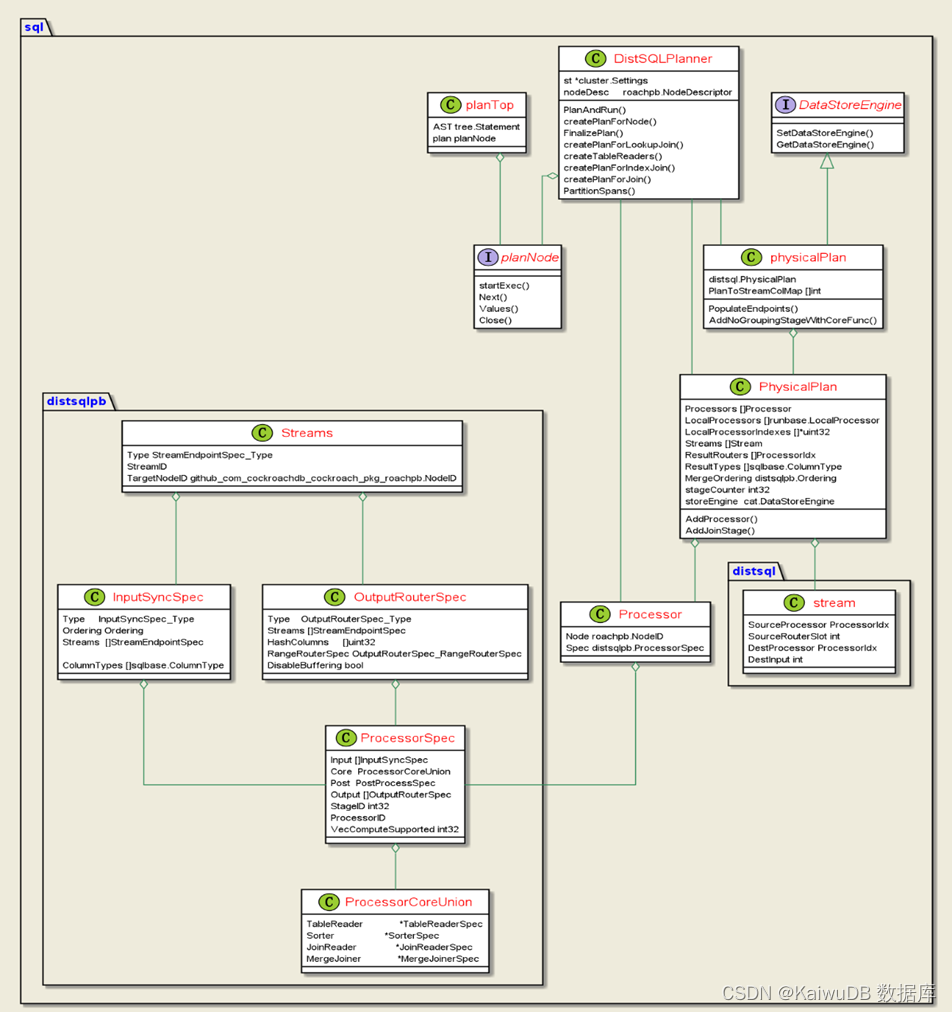
3.2 KaiwuDB 物理计划构造类图
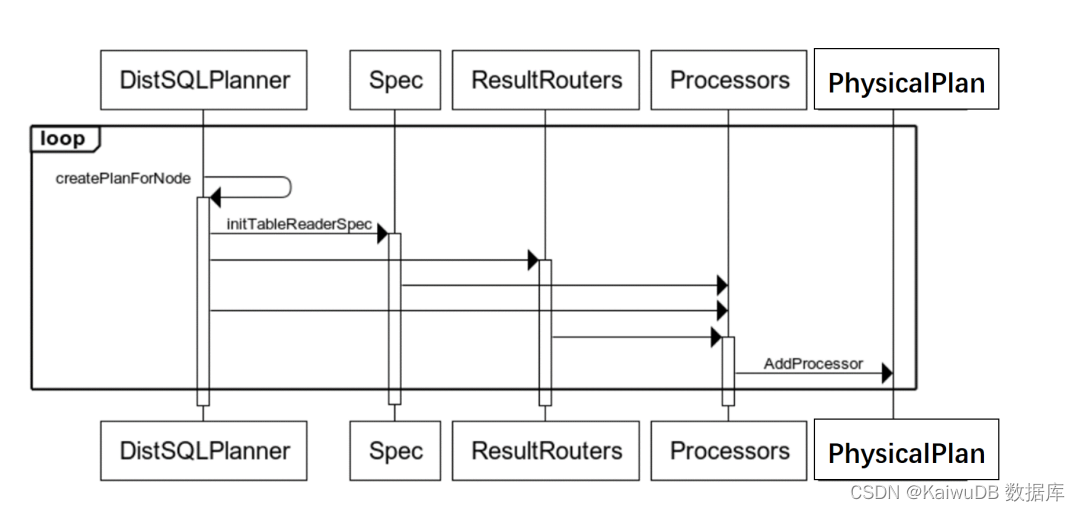
3.3 KaiwuDB 物理计划生成时序图
四、KaiwuDB 物理计划样例
样例 1
以一个简单的物理计划为例,该计划表示为两个表 T1 和 T2 的 Join,Join 的等值关系为 T1.k=T2.k,T1 和 T2 的数据都分布在 3 个节点,表示为如下图:
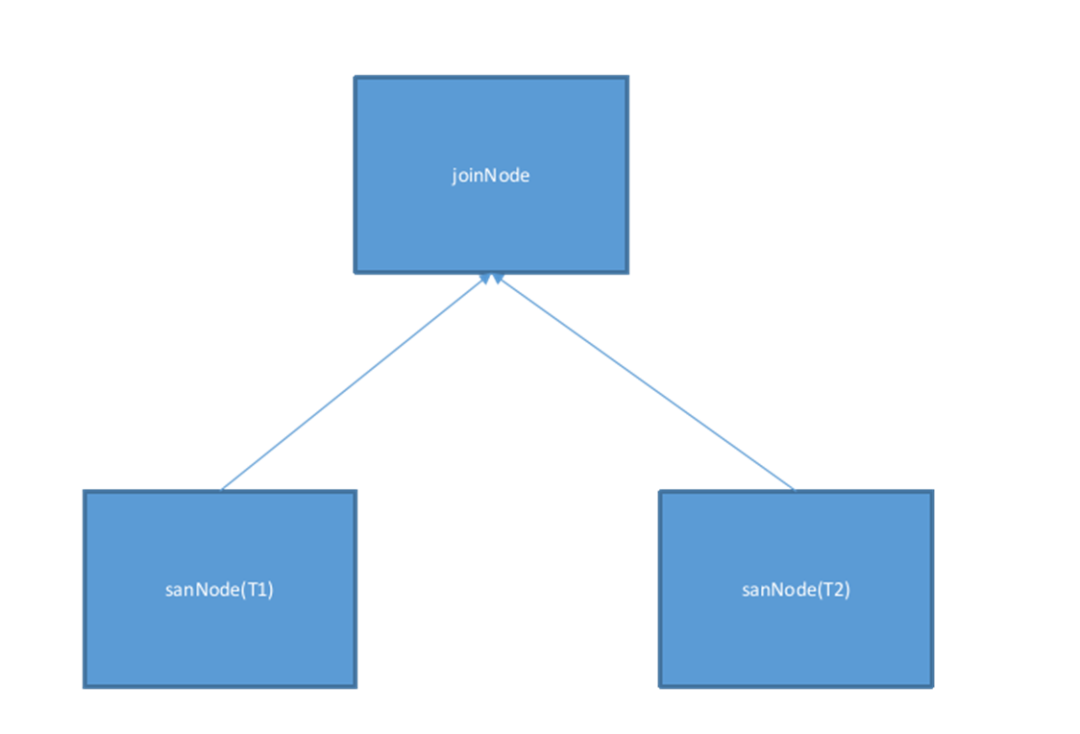
物理计划会确认数据的分布信息,设置每一个 Tablereader 算子的 Filter、Projection 等操作,最终将生成的几个 Tablereader 加入到物理计划当中。
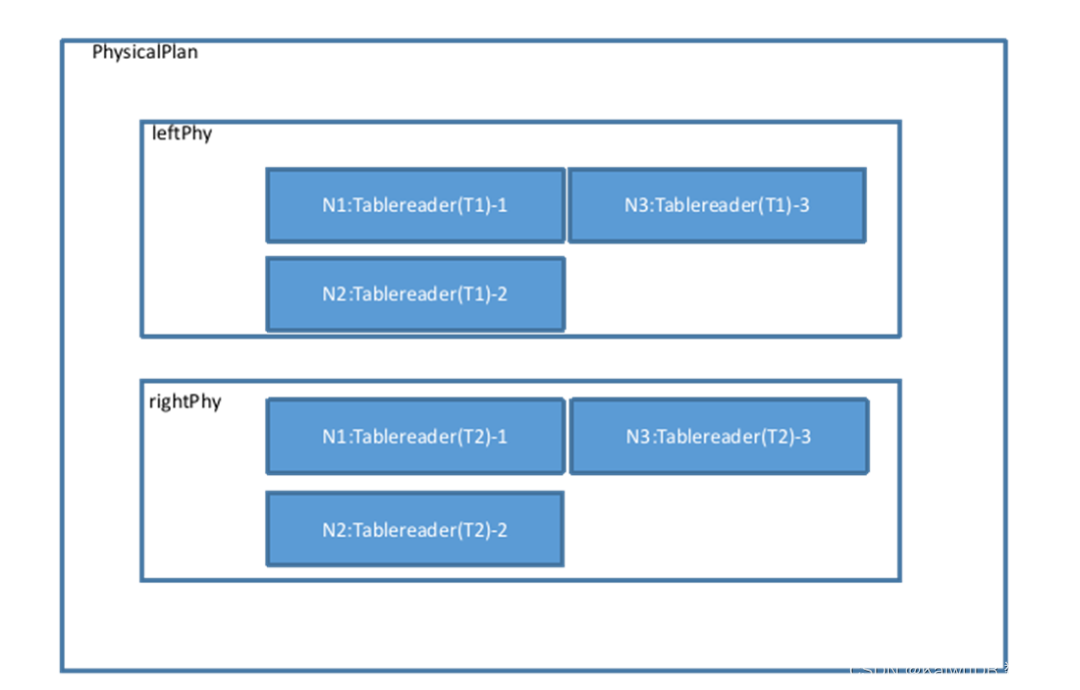
将左右计划进行合并:

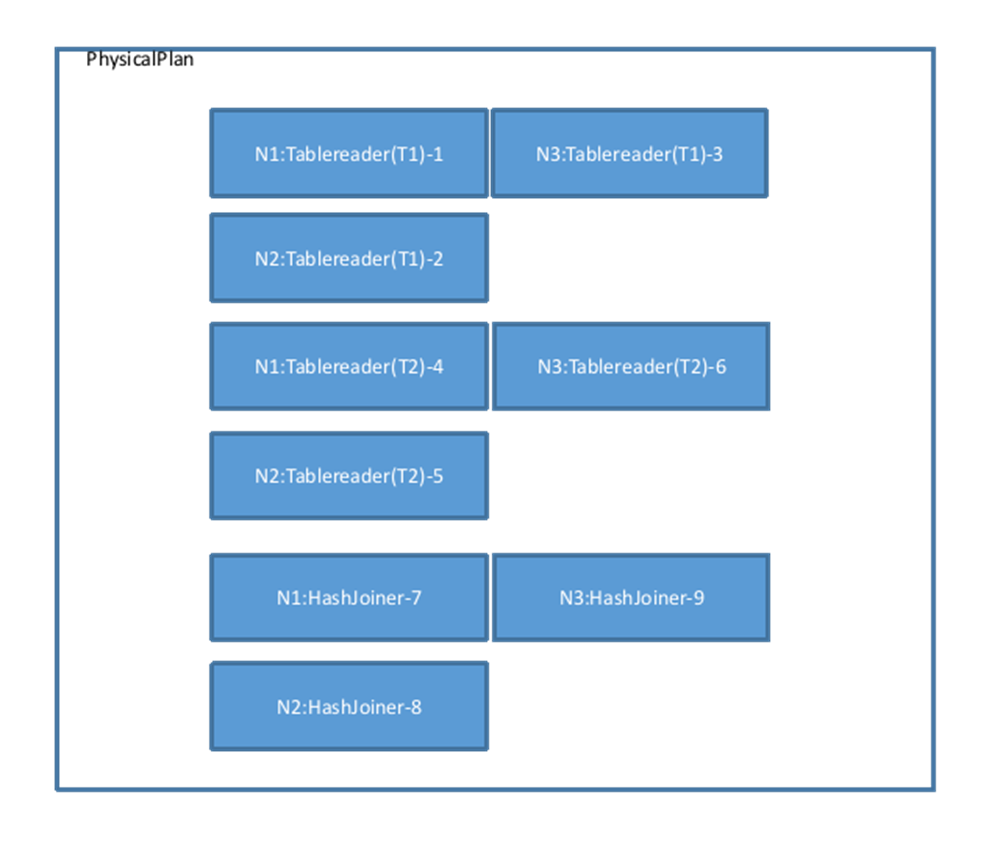
findJoinProcessorNodes 函数决定在几个节点做 Join 操作,这里的 Tablereader 算子是 3 节点,所以 Join 算子也会对应构建 3 个节点,因此这里会调用 AddJoinStage 生成 3 个 HashJoiner(不考虑其他 Join 算法的情况下),并且将其左右算子(这里指代图中的 6 个 Tablereader)的 Output 类型改为 OutputRouterSpec_BY_HASH(意味着执行时需要跨节点 Hash 重分布),物理计划视图变为如下图所示:
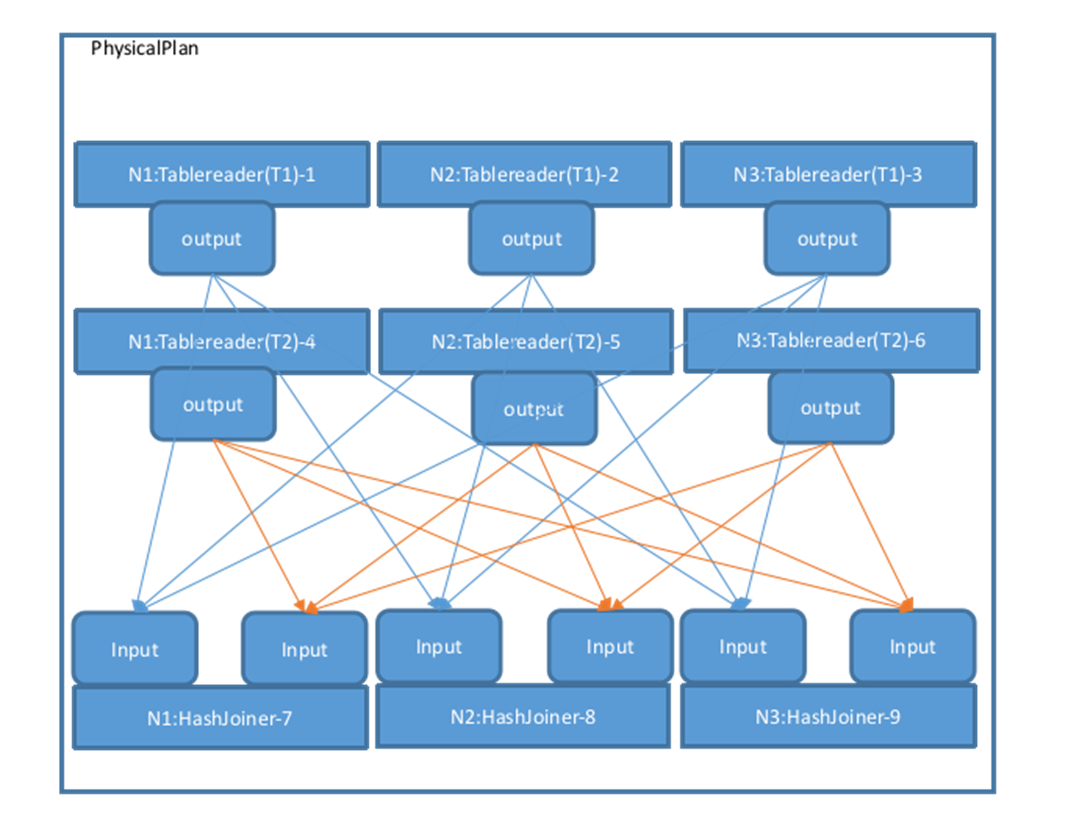
然后调用 MergeResultStreams 按照节点数量将 T1 和 T2 的各 3 个 Tablereader 连接到各个 HashJoiner 的左右两端,有向箭头表示 Stream,起于一个算子的 Output,终于另一个算子的 Input,物理计划视图如下,图中的 Output 类型均为 OutputRouterSpec_BY_HASH:
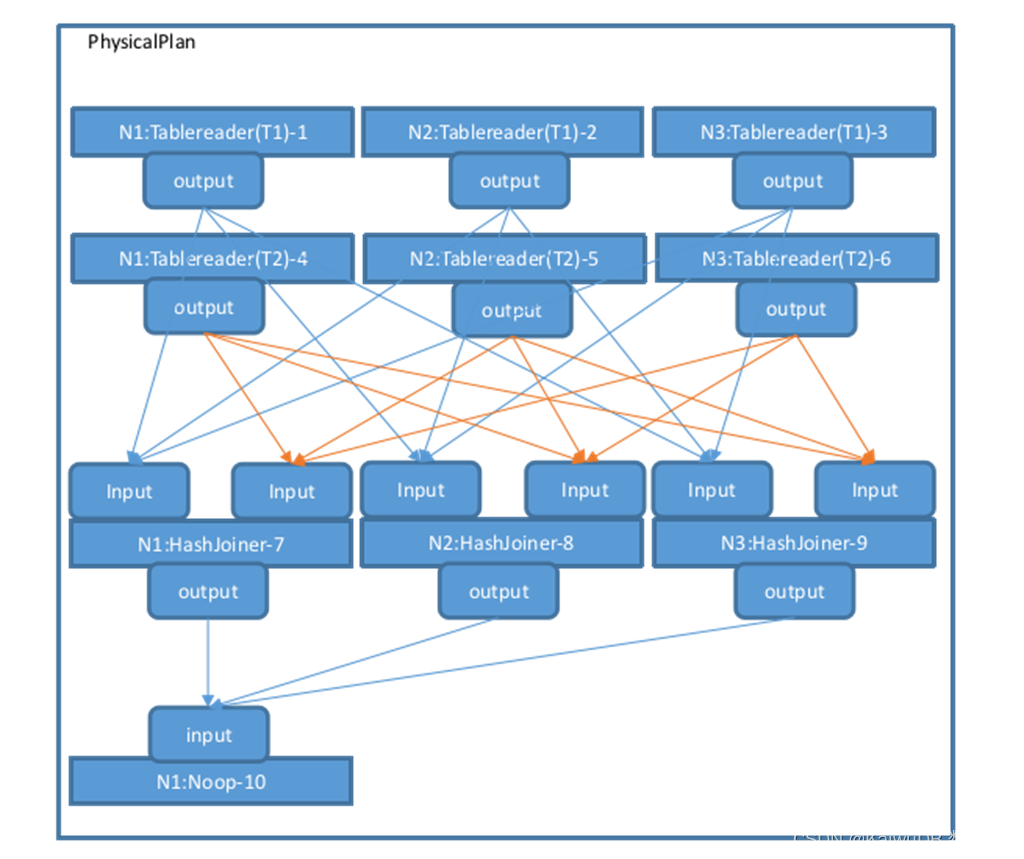
createPhysPlan 函数生成了物理计划的整体拓扑,FinalizePlan 函数还会在已有的物理计划基础上增加一个 Noop 算子,用于汇总最终的执行结果,然后设置每个算子的 Input 和 Output 所关联的 StreamID,以及 Stream 的类型(StreamEndpointSpec_LOCAL 或者 StreamEndpointSpec_REMOTE,Stream 如果连接相同节点的算子为 StreamEndpointSpec_LOCAL,否则为 StreamEndpointSpec_REMOTE)。在执行完 createPhysPlan-->FinalizePlan 后,整体的物理计划便构建完成,如下图所示:
样例 2
我们将通过以下 SQL 语句来介绍物理计划的生成:
select max(height),class from heights join students on heights.id=students.id group by class having class in(1,2) order by max(height) desc limit 2
该查询语句的 PlanNode 如下图所示:
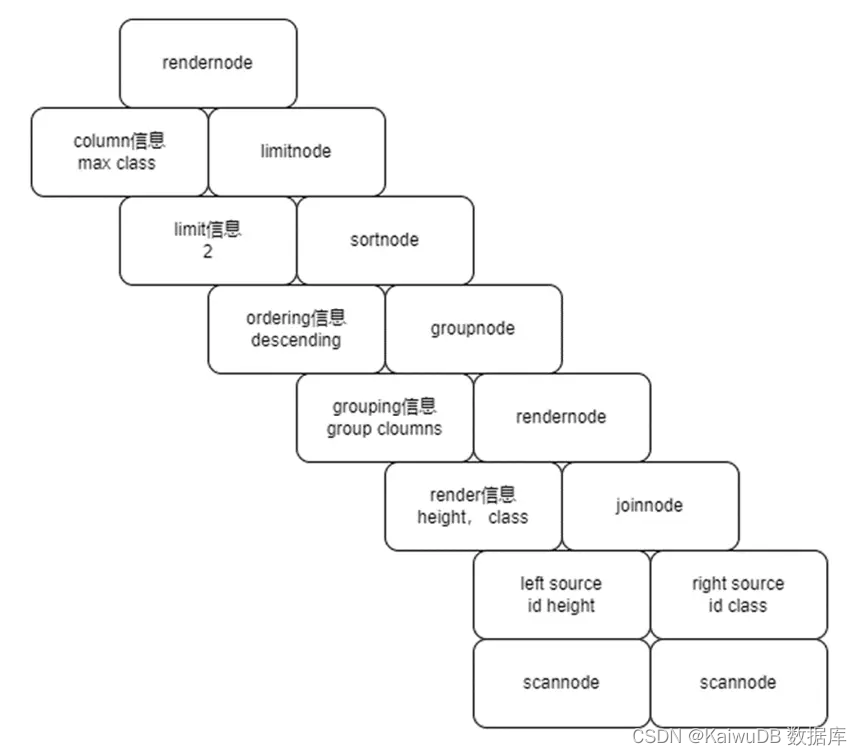
以上述 PlanNode 为例,其最下层为两个 ScanNode,分别是对 heights 和 students 的一个全表扫描,其结果会返回给上层的 JoinNode,JoinNode 会将两张表做 Join 生成一张虚拟表,里面有两张表中的所有列。
其上层的 RenderNode 会对这张虚拟表进行查询,筛选出 height 列和 class 列,GroupNode 会对 class 列进行 group 处理,并对 class 作 max 聚合。然后, SortNode 对 GroupNode 处理过的 max 聚合结果进行排序,LimitNode 对结果作相应的操作。最后,最上层的 RenderNode 对结果进行查询,筛选出 max(height) 列和 class 列。以上即为该 PlanNode 的详细信息。
接着会通过 createPlanForNode 函数对 PlanNode 进行解析生成物理计划。该函数是一个递归函数,会通过 PlanNode 的类型来构建相应的物理计划。
以上述查询语句为例,该 PlanNode 会层层递归先执行 ScanNode 的构建函数 createTableReaders;接着,通过 initTableReaderSpec 新建 Tablereader 的 Spec;随后,通过逻辑计划传下来的 PlanNode 得到算子的 Filter 和 Limit;然后,通过 MakeExpression() 构造物理计划的 Filter 并将 Filter 和 Limit 传入 Post 中。
最后,通过 planCtx 的 isLocal 判断是否是分布式读取计划。
- 若是,则构建 SpanPartition 数组,在各个节点读取 Table 的值;
- 若否,则单读取本地数据即可。
具体流程如下图所示:

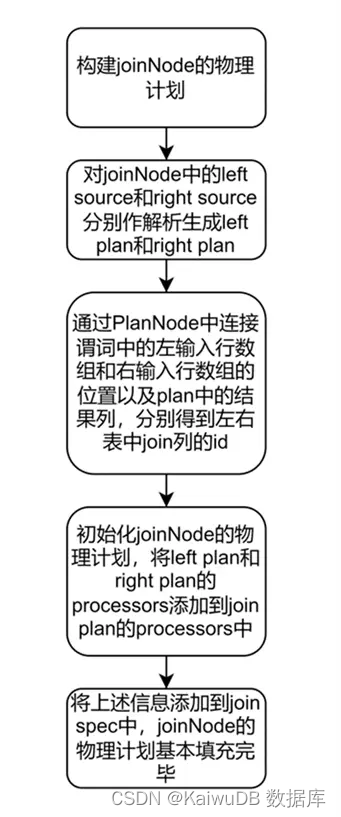
在构建完 left ScanNode 和 right ScanNode 的计划后得到 rightPlan 和 leftPlan, leftPlan 和 rightPlan 执行 MergePlans() 合并左右计划,将左右计划的 Processor 和 Stream 等信息合并。
之后判断是否为分布式执行的步骤与上面的判断方法类似。最后再判断 leftMergeOrd.Columns 是否等于 nil。
- 若是,则构建 hashjoinspec;
- 若否,则构建 mergejoinspec。
执行 AddjoinStage() 将 joinProcessor 添加到指定的节点上去并将左右 Output 连接到这些 Processor 中,JoinNode 也就处理完毕了,基本流程如下图。依次处理 RenderNode , GroupNode , SortNode 等,将相应算子信息添加到物理计划中。
五、总结
执行器在执行之前需要充分的计划做支撑,查询计划分为 LogicPlan 逻辑计划和 PhysicalPlan 物理计划(分布式计划)。
逻辑计划的数据结构为二叉树,由 AST 经过语义解析、 RBO 和 CBO 后生成,每个节点表示一个对应的关系操作(如关系运算连接,在逻辑计划中会转换为实际的 Join 算法,比如 HashJoin、MergeJoin、LookuopJoin)。
逻辑计划构建完成后,开始物理计划的构建,根据数据分布情况将逻辑计划进行垂直方向拆分,对应的逻辑计划节点转换为特定算子(Processor),算子之间通过 Stream 进行连接,整个物理计划的拓扑结构为一个有向无环图,之后便开始计划的执行。