文章目录
- 前言
-
- 一、什么是递归CTE?
- 二、递归CTE基础语法
- 三、入门案例:简单商品分类树查询
-
- [1. 表结构与测试数据](#1. 表结构与测试数据)
- [2. 需求:查询"家用电器"分类下的所有子分类(含层级标记)](#2. 需求:查询“家用电器”分类下的所有子分类(含层级标记))
- [3. 执行结果](#3. 执行结果)
- 四、进阶实战:多级分类商品汇总查询(含统计与筛选)
-
- [1. 核心业务需求](#1. 核心业务需求)
- [2. 表结构复用与补充说明](#2. 表结构复用与补充说明)
- [3. 完整递归CTE实现(含统计与筛选)](#3. 完整递归CTE实现(含统计与筛选))
- [4. 代码分步解析](#4. 代码分步解析)
- [5. 执行结果与验证](#5. 执行结果与验证)
- [6. 边界场景测试(无符合条件商品)](#6. 边界场景测试(无符合条件商品))
- 五、常见问题
-
- [1. 语法错误:"Recursive query aborted after 1001 iterations"](#1. 语法错误:“Recursive query aborted after 1001 iterations”)
- [2. 内存溢出:"out of memory"](#2. 内存溢出:“out of memory”)
- [3. 性能低下:全表扫描](#3. 性能低下:全表扫描)
- [4. 字段对齐错误:"Column count doesn't match value count at row 1"](#4. 字段对齐错误:“Column count doesn't match value count at row 1”)
- 六、执行步骤及生命周期
- 七、递归CTE适用场景与局限性
-
- [1. 适用场景](#1. 适用场景)
- [2. 局限性](#2. 局限性)
- 总结
前言
在数据库开发中,我们经常会遇到层级数据查询的场景,比如组织架构树、菜单权限树、关联关系链等。传统的查询方式需要通过多层嵌套或存储过程循环实现,代码繁琐且性能堪忧。MySQL 8.0 引入的递归CTE(公共表表达式),为层级数据查询提供了简洁高效的解决方案。本文将从基础概念出发,逐步深入递归CTE的语法、实战场景、常见问题与优化技巧,帮助你彻底掌握这一强大工具。
一、什么是递归CTE?
CTE是一种临时结果集,可在SQL语句中多次引用,分为非递归CTE和递归CTE两类。其中,递归CTE通过WITH RECURSIVE关键字定义,由"初始查询"和"递归查询"两部分组成,能够自动遍历层级数据,直到满足终止条件。
核心逻辑:递归CTE会重复执行"递归查询",将结果与"初始查询"的结果合并,直到递归查询返回空集,最终输出合并后的完整结果集。
二、递归CTE基础语法
递归CTE的语法结构严格遵循"初始层 + 递归层 + 终止条件"的模式,具体格式如下:
sql
WITH RECURSIVE cte_name (col1, col2, ...) AS (
-- 1. 初始层(锚点查询):定义递归的起始数据
SELECT col1, col2, ... FROM table_name WHERE condition
UNION ALL
-- 2. 递归层:引用CTE自身,定义层级遍历规则
SELECT cte.col1, t.col2, ...
FROM cte_name cte
JOIN table_name t ON cte.colX = t.colY
WHERE condition -- 3. 终止条件:控制递归停止(避免无限递归)
)
-- 4. 最终查询:使用CTE的结果集
SELECT * FROM cte_name;关键注意点:初始层和递归层返回的字段数量、字段类型必须完全一致,否则会报语法错误。
语法拆解
-
CTE名称与字段 :
cte_name为CTE的名称,括号内可选指定字段名,若不指定则默认使用初始层的字段名。 -
初始层(锚点):非递归查询,用于定义递归的起始数据,比如查询组织架构的根节点。
-
UNION ALL :用于合并初始层和递归层的结果集,注意不能用
UNION(会去重导致性能下降)。 -
递归层 :必须引用CTE自身(
cte_name),通过关联查询实现层级遍历,比如用父节点ID关联子节点ID。 -
终止条件 :递归层的
WHERE子句用于控制递归停止,比如限制递归深度、排除已遍历的节点。
三、入门案例:简单商品分类树查询
以电商平台"商品分类树"为例,演示递归CTE的基础用法------从根节点(一级分类)出发,查询所有层级的分类信息,包含层级关系标记。
1. 表结构与测试数据
sql
-- 商品分类表
CREATE TABLE product_category (
cat_id INT PRIMARY KEY COMMENT '分类ID',
cat_name VARCHAR(50) NOT NULL COMMENT '分类名称',
parent_cat_id INT COMMENT '父分类ID(根节点parent_cat_id为0)',
cat_level INT COMMENT '分类层级(1=一级,2=二级...,可通过递归自动计算,此处预留)',
is_enable TINYINT DEFAULT 1 COMMENT '是否启用(1=启用,0=禁用)'
);
-- 插入测试数据(三级分类)
INSERT INTO product_category (cat_id, cat_name, parent_cat_id, cat_level) VALUES
(1, '家用电器', 0, 1),
(2, '手机通讯', 0, 1),
(3, '冰箱', 1, 2),
(4, '空调', 1, 2),
(5, '智能手机', 2, 2),
(6, '功能手机', 2, 2),
(7, '十字对开门冰箱', 3, 3),
(8, '三门冰箱', 3, 3),
(9, '壁挂式空调', 4, 3),
(10, '柜式空调', 4, 3);
-- 商品表(关联分类)
CREATE TABLE product (
prod_id INT PRIMARY KEY COMMENT '商品ID',
prod_name VARCHAR(100) NOT NULL COMMENT '商品名称',
cat_id INT COMMENT '所属分类ID',
price DECIMAL(10,2) COMMENT '商品价格',
FOREIGN KEY (cat_id) REFERENCES product_category (cat_id)
);
-- 插入测试商品数据
INSERT INTO product (prod_id, prod_name, cat_id, price) VALUES
(101, 'XX十字对开门冰箱', 7, 5999.00),
(102, 'XX三门冰箱', 8, 3299.00),
(103, 'XX壁挂式空调', 9, 2699.00),
(104, 'XX智能手机', 5, 4999.00),
(105, 'XX功能手机', 6, 599.00);2. 需求:查询"家用电器"分类下的所有子分类(含层级标记)
sql
WITH RECURSIVE category_tree AS (
-- 初始层:查询"家用电器"根节点(cat_id=1,parent_cat_id=0)
SELECT
cat_id,
cat_name,
parent_cat_id,
1 AS current_level, -- 标记当前层级(一级分类)
CAST(cat_name AS CHAR(200)) AS cat_path -- 记录分类路径(用于展示层级关系)
FROM product_category
WHERE cat_id = 1 -- 起始分类:家用电器
AND is_enable = 1
UNION ALL
-- 递归层:查询子分类,关联父分类ID
SELECT
pc.cat_id,
pc.cat_name,
pc.parent_cat_id,
ct.current_level + 1 AS current_level, -- 层级+1
CONCAT(ct.cat_path, '→', pc.cat_name) AS cat_path -- 拼接分类路径
FROM category_tree ct
INNER JOIN product_category pc
ON ct.cat_id = pc.parent_cat_id -- 父分类ID=子分类父ID
WHERE pc.is_enable = 1 -- 仅查询启用的分类
)
-- 最终查询:按层级排序,展示分类详情
SELECT
cat_id,
cat_name,
parent_cat_id,
current_level,
cat_path AS 分类路径
FROM category_tree
ORDER BY current_level, cat_id;3. 执行结果
| cat_id | cat_name | parent_cat_id | current_level | 分类路径 |
|---|---|---|---|---|
| 1 | 家用电器 | 0 | 1 | 家用电器 |
| 3 | 冰箱 | 1 | 2 | 家用电器→冰箱 |
| 4 | 空调 | 1 | 2 | 家用电器→空调 |
| 7 | 十字对开门冰箱 | 3 | 3 | 家用电器→冰箱→十字对开门冰箱 |
| 8 | 三门冰箱 | 3 | 3 | 家用电器→冰箱→三门冰箱 |
| 9 | 壁挂式空调 | 4 | 3 | 家用电器→空调→壁挂式空调 |
| 10 | 柜式空调 | 4 | 3 | 家用电器→空调→柜式空调 |
通过递归CTE,仅需少量代码就实现了多层分类的遍历,同时通过current_level和cat_path清晰标记了层级关系,相比传统嵌套查询优势显著。
四、进阶实战:多级分类商品汇总查询(含统计与筛选)
基于入门案例的商品分类场景,升级为更贴近实战的需求------从指定分类出发,递归查询其所有子分类下的商品,同时统计每个分类的商品数量、最低价格、最高价格,支持按价格区间筛选商品,最终输出结构化的分类-商品汇总信息。
1. 核心业务需求
-
以"冰箱"分类(cat_id=3)为起点,递归查询其所有子分类(三级分类:十字对开门冰箱、三门冰箱);
-
汇总每个分类下的商品信息:商品数量、最低价格、最高价格、平均价格;
-
筛选条件:仅统计价格≥3000元的商品;
-
输出结果需包含:分类ID、分类名称、分类层级、分类路径、商品统计信息、子分类列表(可选);
-
处理边界场景:分类下无符合条件商品时,统计字段显示0或NULL,并标注"无符合条件商品"。
2. 表结构复用与补充说明
复用入门案例中的product_category(商品分类表)和product(商品表),无需额外创建表;补充说明:商品表中已包含cat_id(关联分类)和price(价格)字段,可直接用于关联统计。
3. 完整递归CTE实现(含统计与筛选)
sql
WITH RECURSIVE category_tree AS (
-- 步骤1:递归查询"冰箱"分类下的所有子分类(含自身)
SELECT
cat_id,
cat_name,
parent_cat_id,
1 AS current_level,
CAST(cat_name AS CHAR(200)) AS cat_path,
CAST(cat_id AS CHAR(100)) AS cat_id_path -- 记录分类ID路径,用于后续子分类列表拼接
FROM product_category
WHERE cat_id = 3 -- 起始分类:冰箱
AND is_enable = 1
UNION ALL
SELECT
pc.cat_id,
pc.cat_name,
pc.parent_cat_id,
ct.current_level + 1 AS current_level,
CONCAT(ct.cat_path, '→', pc.cat_name) AS cat_path,
CONCAT(ct.cat_id_path, ',', pc.cat_id) AS cat_id_path
FROM category_tree ct
INNER JOIN product_category pc
ON ct.cat_id = pc.parent_cat_id
WHERE pc.is_enable = 1
),
-- 步骤2:统计每个分类下符合条件的商品信息(价格≥3000元)
product_statistics AS (
SELECT
c.cat_id,
c.cat_name,
c.current_level,
c.cat_path,
c.cat_id_path,
COUNT(p.prod_id) AS prod_count, -- 商品数量
IFNULL(MIN(p.price), 0) AS min_price, -- 最低价格(无数据时为0)
IFNULL(MAX(p.price), 0) AS max_price, -- 最高价格(无数据时为0)
IFNULL(ROUND(AVG(p.price), 2), 0) AS avg_price, -- 平均价格(保留2位小数)
-- 标记是否有符合条件的商品
CASE WHEN COUNT(p.prod_id) > 0 THEN '有符合条件商品' ELSE '无符合条件商品' END AS prod_status
FROM category_tree c
LEFT JOIN product p
ON c.cat_id = p.cat_id
AND p.price >= 3000 -- 筛选条件:价格≥3000元
GROUP BY c.cat_id, c.cat_name, c.current_level, c.cat_path, c.cat_id_path
),
-- 步骤3:(可选)拼接每个分类的子分类列表(用逗号分隔)
category_child_list AS (
SELECT
parent.cat_id AS parent_cat_id,
parent.cat_name AS parent_cat_name,
GROUP_CONCAT(child.cat_id SEPARATOR ',') AS child_cat_ids,
GROUP_CONCAT(child.cat_name SEPARATOR ',') AS child_cat_names
FROM category_tree parent
LEFT JOIN category_tree child
ON parent.cat_id = child.parent_cat_id
GROUP BY parent.cat_id, parent.cat_name
)
-- 步骤4:最终关联查询,输出完整结果
SELECT
ps.cat_id,
ps.cat_name,
ps.current_level AS 分类层级,
ps.cat_path AS 分类路径,
ps.prod_count AS 商品数量,
ps.min_price AS 最低价格,
ps.max_price AS 最高价格,
ps.avg_price AS 平均价格,
ps.prod_status AS 商品状态,
IFNULL(ccl.child_cat_ids, '') AS 子分类ID列表,
IFNULL(ccl.child_cat_names, '') AS 子分类名称列表
FROM product_statistics ps
LEFT JOIN category_child_list ccl
ON ps.cat_id = ccl.parent_cat_id
ORDER BY ps.current_level, ps.cat_id;4. 代码分步解析
本次实现采用"多CTE嵌套"模式,将复杂需求拆分为4个步骤,逻辑清晰且易于维护:
步骤1:category_tree(递归查询分类树)
核心功能:从"冰箱"分类(cat_id=3)出发,递归查询所有子分类,同时记录current_level(层级)、cat_path(分类名称路径)、cat_id_path(分类ID路径)。其中,cat_id_path用于后续拼接子分类列表,避免二次递归。
步骤2:product_statistics(商品统计)
核心功能:关联分类树和商品表,按分类分组统计商品信息。关键处理:
-
用
LEFT JOIN关联商品表,确保无商品的分类也能被保留; -
筛选条件
p.price ≥ 3000写在JOIN条件中,而非WHERE子句,避免过滤掉无符合条件商品的分类; -
用
IFNULL函数处理统计字段的NULL值,确保输出统一(无数据时为0); -
通过
CASE语句标记prod_status,提升结果可读性。
步骤3:category_child_list(拼接子分类列表)
核心功能:基于分类树结果,按父分类分组,用GROUP_CONCAT拼接子分类的ID和名称,形成"子分类列表"字段,适配前端下拉选择或详情展示需求。
步骤4:最终关联查询
核心功能:关联统计结果和子分类列表,输出完整的业务字段,按层级和分类ID排序,确保结果有序且结构化。
5. 执行结果与验证
| cat_id | cat_name | 分类层级 | 分类路径 | 商品数量 | 最低价格 | 最高价格 | 平均价格 | 商品状态 | 子分类ID列表 | 子分类名称列表 |
|---|---|---|---|---|---|---|---|---|---|---|
| 3 | 冰箱 | 1 | 冰箱 | 2 | 3299.00 | 5999.00 | 4649.00 | 有符合条件商品 | 7,8 | 十字对开门冰箱,三门冰箱 |
| 7 | 十字对开门冰箱 | 2 | 冰箱→十字对开门冰箱 | 1 | 5999.00 | 5999.00 | 5999.00 | 有符合条件商品 | ||
| 8 | 三门冰箱 | 2 | 冰箱→三门冰箱 | 1 | 3299.00 | 3299.00 | 3299.00 | 有符合条件商品 |
结果验证:所有分类均被正确递归,统计字段准确(冰箱分类下2件商品,价格均≥3000元),子分类列表拼接正常,无数据字段(如三级分类的子分类列表)显示为空字符串,符合业务需求。
6. 边界场景测试(无符合条件商品)
若修改筛选条件为"价格≥6000元",执行上述SQL后,结果如下(关键字段变化):
| cat_name | 商品数量 | 最低价格 | 商品状态 |
|---|---|---|---|
| 冰箱 | 0 | 0 | 无符合条件商品 |
| 十字对开门冰箱 | 0 | 0 | 无符合条件商品 |
| 三门冰箱 | 0 | 0 | 无符合条件商品 |
边界场景处理有效:无符合条件商品时,统计字段显示0,prod_status准确标记,避免了NULL值导致的前端展示问题。
五、常见问题
在使用递归CTE时,容易遇到语法错误、性能问题、内存溢出等问题,以下是高频问题的解决方案。
1. 语法错误:"Recursive query aborted after 1001 iterations"
原因:递归深度超过MySQL默认限制(默认1000层),或存在递归闭环。
解决方案:
-
添加深度限制:在递归层添加
level <= N(N根据业务调整,建议不超过100); -
阻断闭环:添加路径校验(如上文的
path字段); -
临时调整配置:
SET max_recursion_depth = 5000;(会话级,不建议全局调整)。
2. 内存溢出:"out of memory"
原因:递归结果集过大,或递归层关联过多表导致内存占用激增。
解决方案:
-
提前过滤:递归层仅保留必要字段,过滤
NULL、空字符串等无效数据; -
延迟关联:将非必要的多表关联(如名称补全、HIT关联)延迟到最终处理层,减少递归层数据量;
-
改用临时表:若结果集极大,用"临时表 + 循环"替代递归CTE,将数据写入磁盘而非内存。
3. 性能低下:全表扫描
原因:关联字段未加索引,导致递归层每次查询都全表扫描。
解决方案:
-
给关联字段加索引:如B表的
source_id、rel_type字段,添加复合索引idx_b_source_rel (source_id, rel_type); -
覆盖索引:将递归层需要的字段(如
rel_id、rel_name)纳入索引,减少回表查询。
4. 字段对齐错误:"Column count doesn't match value count at row 1"
原因:初始层和递归层返回的字段数量或类型不一致。
解决方案:
-
严格检查两层查询的字段数量,确保完全一致;
-
统一字段类型:比如初始层
level为INT,递归层也必须是INT。
六、执行步骤及生命周期
1.执行时序
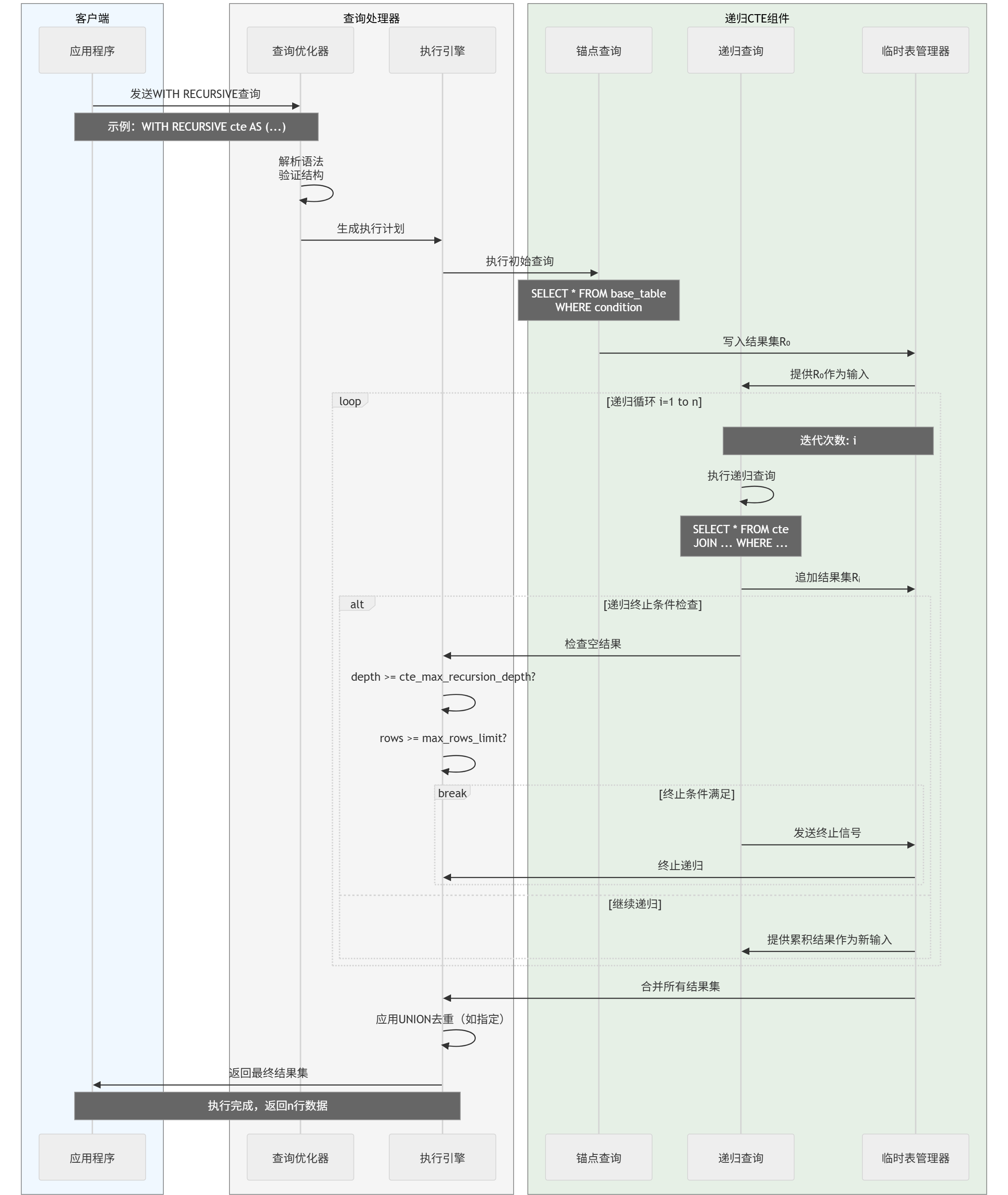
执行时序图展示了CTE从查询提交到结果返回的完整交互流程:客户端发送查询后,查询优化器解析并生成执行计划,执行引擎首先执行锚点查询生成初始结果集,随后驱动递归查询进行迭代循环,每次迭代基于前次结果生成新数据集并检查终止条件,最终通过临时表管理器合并所有结果集,应用去重操作后返回给客户端。
2.生命周期
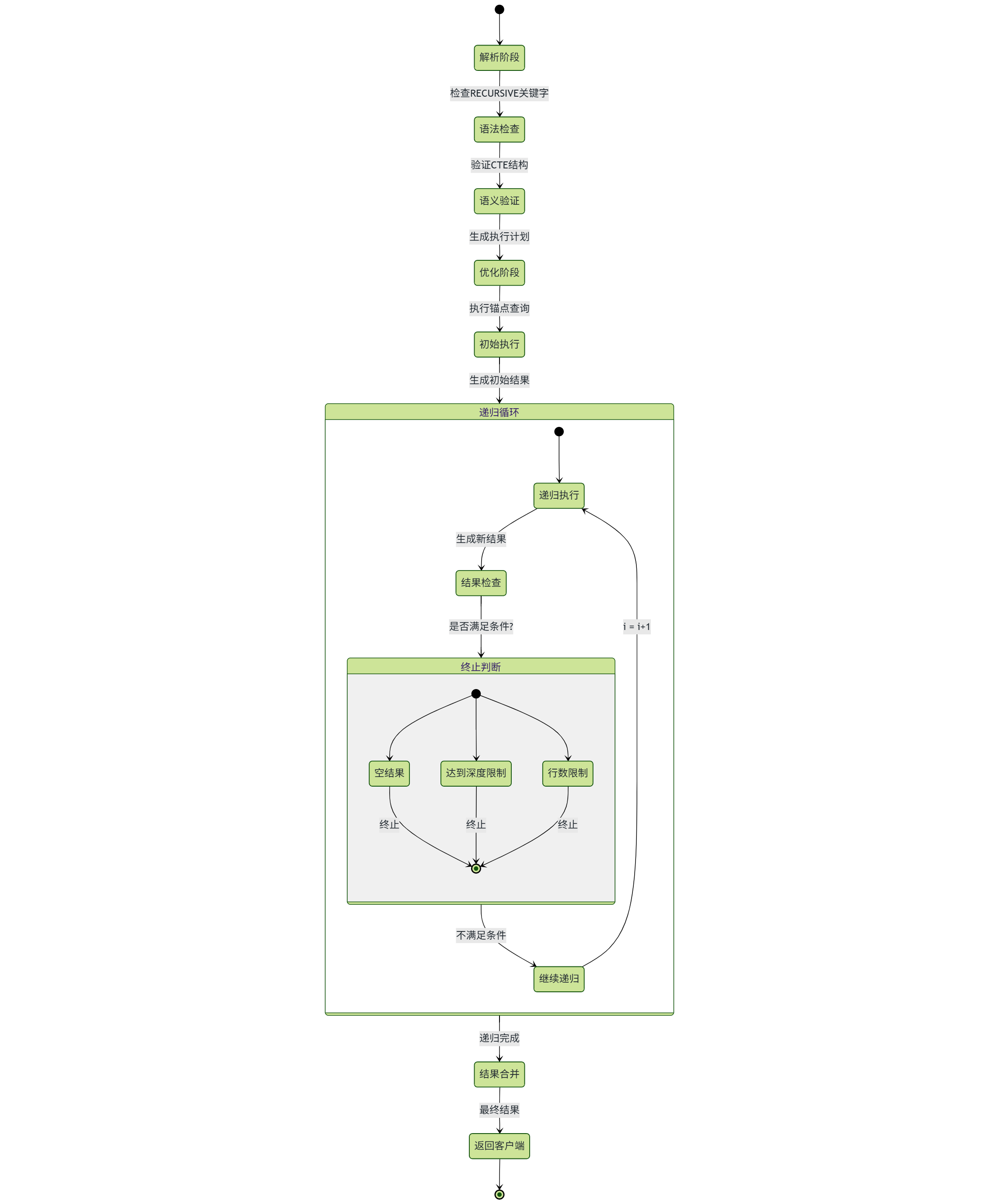
递归CTE生命周期图中以状态机形式描述了查询从解析到结束的完整状态流转:始于查询解析阶段的语法验证,经过查询优化生成执行计划,进入初始化执行准备临时数据,核心阶段是递归循环执行,通过迭代计数器控制递归深度并检查终止条件,最后在结果合并处理阶段聚合所有中间数据,完成格式化后返回最终结果,整个生命周期清晰划分了解析、优化、执行和结果处理四个关键阶段。
七、递归CTE适用场景与局限性
1. 适用场景
-
层级数据查询:组织架构、菜单树、分类树等;
-
关联关系遍历:如本文的多类型关联链查询;
-
数字序列生成:如生成1-100的连续数字(
WITH RECURSIVE nums AS (SELECT 1 n UNION ALL SELECT n+1 FROM nums WHERE n<100))。
2. 局限性
-
版本限制:仅支持MySQL 8.0+,5.x版本需用存储过程替代;
-
内存依赖:结果集过大会导致内存溢出,不适合超大规模层级数据;
-
复杂度高:多表关联+复杂逻辑时,可读性和维护成本上升。
总结
MySQL递归CTE通过"初始层 + 递归层"的简洁结构,彻底解决了传统层级查询的繁琐问题,大幅提升了代码可读性和开发效率。在实际应用中,需重点关注"闭环防护""深度控制""索引优化"三个核心点,避免出现性能和内存问题。
对于简单层级查询,递归CTE是最优选择;对于超大规模或极端复杂的场景,可结合临时表、缓存等方案优化。掌握递归CTE的核心逻辑和避坑技巧,能让你在处理层级数据时游刃有余。
小提示:使用递归CTE时,建议先通过SELECT COUNT(*)测试结果集大小,再逐步完善业务逻辑,避免直接执行导致内存溢出。