全量同步
每天都将业务数据库中的全部数据同步一份到数据仓库
全量同步采用DataX
datax
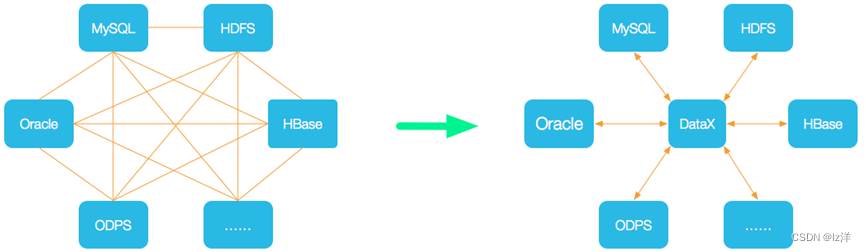
datax使用

执行
bash
python /opt/module/datax/bin/datax.py /opt/module/datax/job/job.json更多job.json配置文件在:
生成的DataX配置文件
bash
java -jar datax-config-generator-1.0-SNAPSHOT-jar-with-dependencies.jar增量同步
每天只将业务数据中的新增及变化数据同步到数据仓库。采用每日增量同步的表,通常需要在首日先进行一次全量同步。
增量同步采用Maxwell
Maxwell 监控MySQL数据,将自己伪装成MySQL的slave,实时监控MySQL的binlog日志,并将数据转化为json,之后发送给kafka等一些流数据处理平台。
要提前开启mysql的binlog

配置maxwell
maxwell首次开启为全量,之后为增量
全量:bin/maxwell-bootstrap --database gmall --table user_info --config config.properties
增量:bin/maxwell --config config.properties --daemon

如何解决数据漂移问题?
用户行为数据生成的时候一般会自带一个时间戳ts,通过flume拦截器,将body当中数据自带的ts时间戳写入header当中的timestamp,这样HDFS Sink在落盘调度时候就可以通过数据产生的时间来落盘了。
拦截器见:
启动脚本f2_log.sh编写资料见: