爬虫的概念:
爬虫是一种自动化信息采集程序或脚本,用于从互联网上抓取信息。 它通过模拟浏览器请求站点的行为,获取资源后分析并提取有用数据,这些数据可以是HTML代码、JSON数据或二进制数据(如图片、视频)。爬虫的用途广泛,包括但不限于收集数据、信息调查、刷流量与参与秒杀活动等。
爬虫在法律上是合法的,像菜刀一样,只要不拿来砍人就不违法。
爬虫的矛与盾
反爬机制
门户网站,可以通过制定相应的策略或者技术手段,防止爬虫程序进行网站数据的爬取。
反反爬策略
爬虫程序可以通过制定相关的策略或者技术手段,破解门户网站中具有的反爬机制,从而可以获取门户网站中相关的数据。
robots.txt协议
君子协议,指定网站中哪些数据可以被爬虫爬取,哪些数据不可以被爬取。防君子不防小人,只是一个协议。
一个简单的小爬虫程序
from urllib.request import urlopen
url = "http://www.baidu.com"
resp = urlopen(url)
with open("mybaidu1.html", mode="w", encoding="utf-8") as f:
f.write(resp.read().decode("utf-8"))
print("over!")爬取百度的源代码并保存到mybaidu1.html文件中,执行结束返回over!
得到的文件:

web请求过程分析
服务器渲染:在服务器那边直接把数据和HTML整合在一起,同一返回给浏览器。
就是客户端发送请求,服务端直接把请求内容返回过来,在源代码可看见请求内容。
客户端渲染:第一次只返回一个html骨架,第二次才返回数据。
客户端发送请求,但服务端只给一个html骨架,客户端再通过请求要数据,服务端才会发送数据,源代码看不到数据。
HTTP协议
协议: 就是两个计算机之间为了能够流畅的进行沟通而设置的一个君子协定.常见的协议有TCP/IPSOAP协议,HTTP协议,SMTP协议等等.
HTTP协议,Hyper Text Transfer Protocol(超文本传输协议)的缩写,是用于从万维网(WWW:Worid Wide Web)服务器传输超文本到本地浏览器的传送协议,直白点儿,就是浏览器和服务器之间的数据交互遵守的就是HTTP协议.
HTTP协议把一条消息分为三大块内容.无论是请求还是响应都是三块内容:
请求:
1 请求行 ->请求方式(get/post) 请求url地址 协议
2 请求头 ->放一些服务器要使用的附加信息(可能包含反爬)
3 请求体-> 一般放一些请求参数
响应
1 状态行 -> 协议 状态码 200 302 404 500
2 响应头-> 放一些客户端要使用的一些附加信息
3 响应体 -> 服务器返回的真正客户端要用的内容(HTML,json)等
在后面我们写爬虫的时候要格外注意请求头和响应头,这两个地方一般都隐含着一些比较重要的内容.
比如:
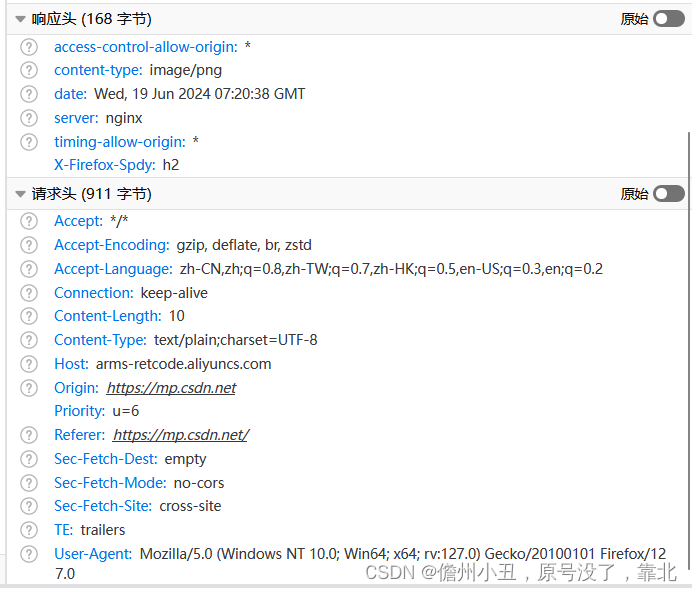
请求头中最常见的一些重要内容(爬虫需要):
1.User-Agent:请求载体的身份标识(用啥发送的请求)
2.Referer: 防盗链(这次请求是从哪个页面来的?反爬会用到)
3.cookie:本地字符串数据信息(用户登录信息,反爬的token)
响应头中一些重要的内容:
1.cookie: 本地字符串数据信息(用户登录信息,反爬的token)
2.各种神奇的莫名其妙的字符串(这个需要经验了,一般都是token字样,防止各种攻击和反爬)
requests模块
pip install requests #执行命令安装
使用:
get请求
响应状态200,响应没有问题。
print(resp.text),查看网页内容,也就是源代码
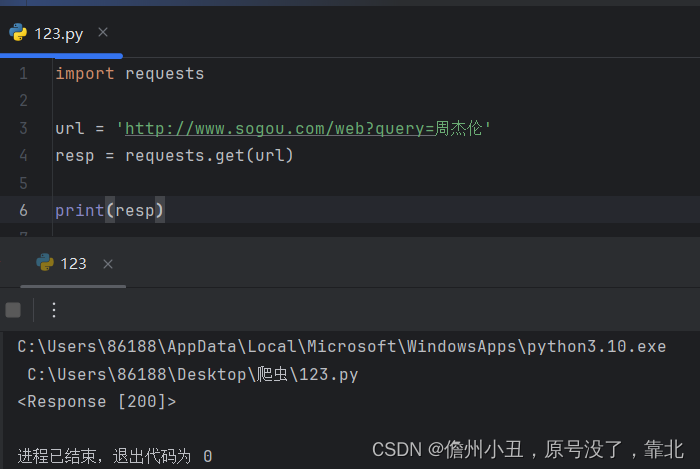
import requests
url = 'http://www.sogou.com/web?query=周杰伦'
resp = requests.get(url)
print(resp)
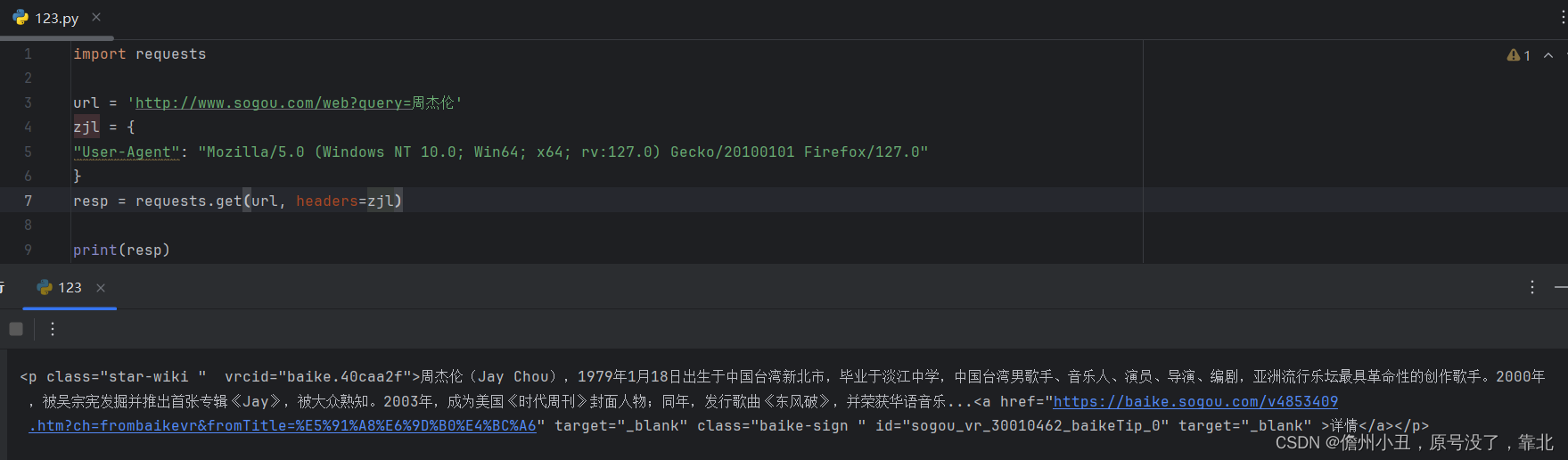
print(resp.text)但是返回这样:

检测到是爬虫程序,一个简单的反爬机制。
需要让服务端认为我们是正常用户,用到UA头来伪造自己的身份。

|------------|----------------------------------------------------------------------------------|
| User-Agent | Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:127.0) Gecko/20100101 Firefox/127.0 |
这是我的UA头。
在请求里面加入一个headers,它的内容是UA。
post请求
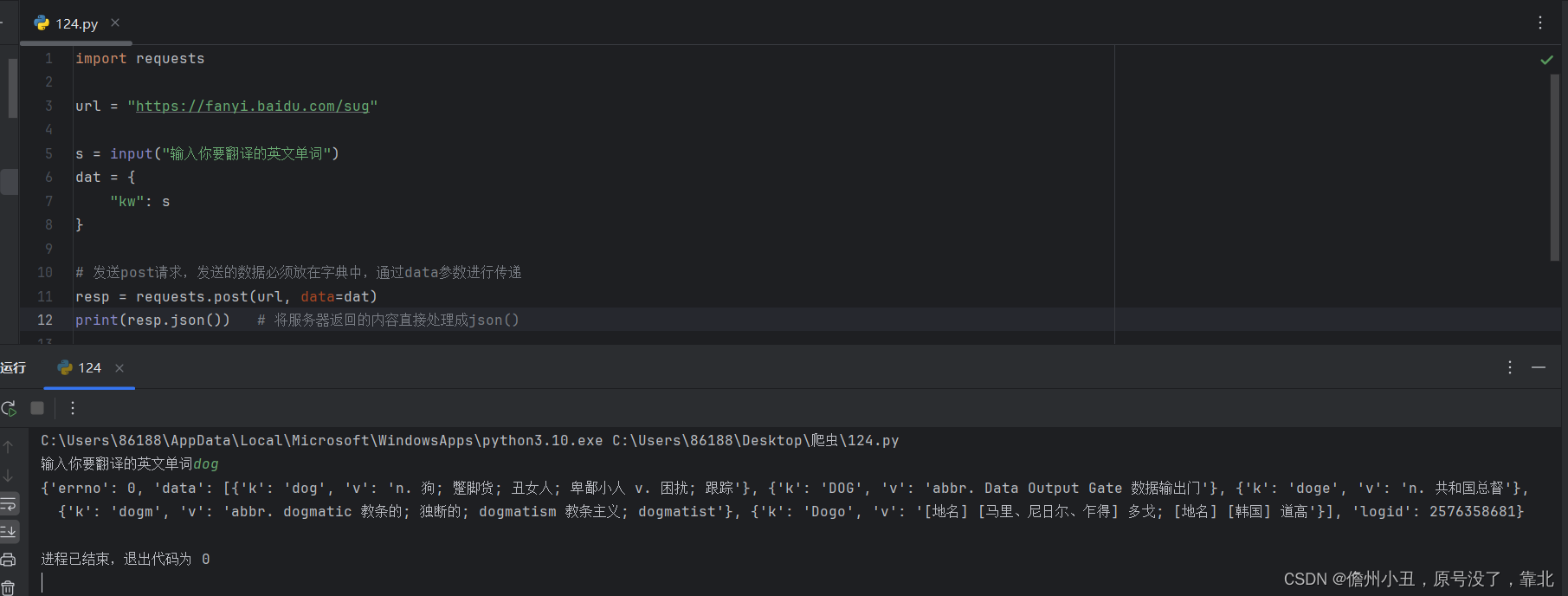
实例三
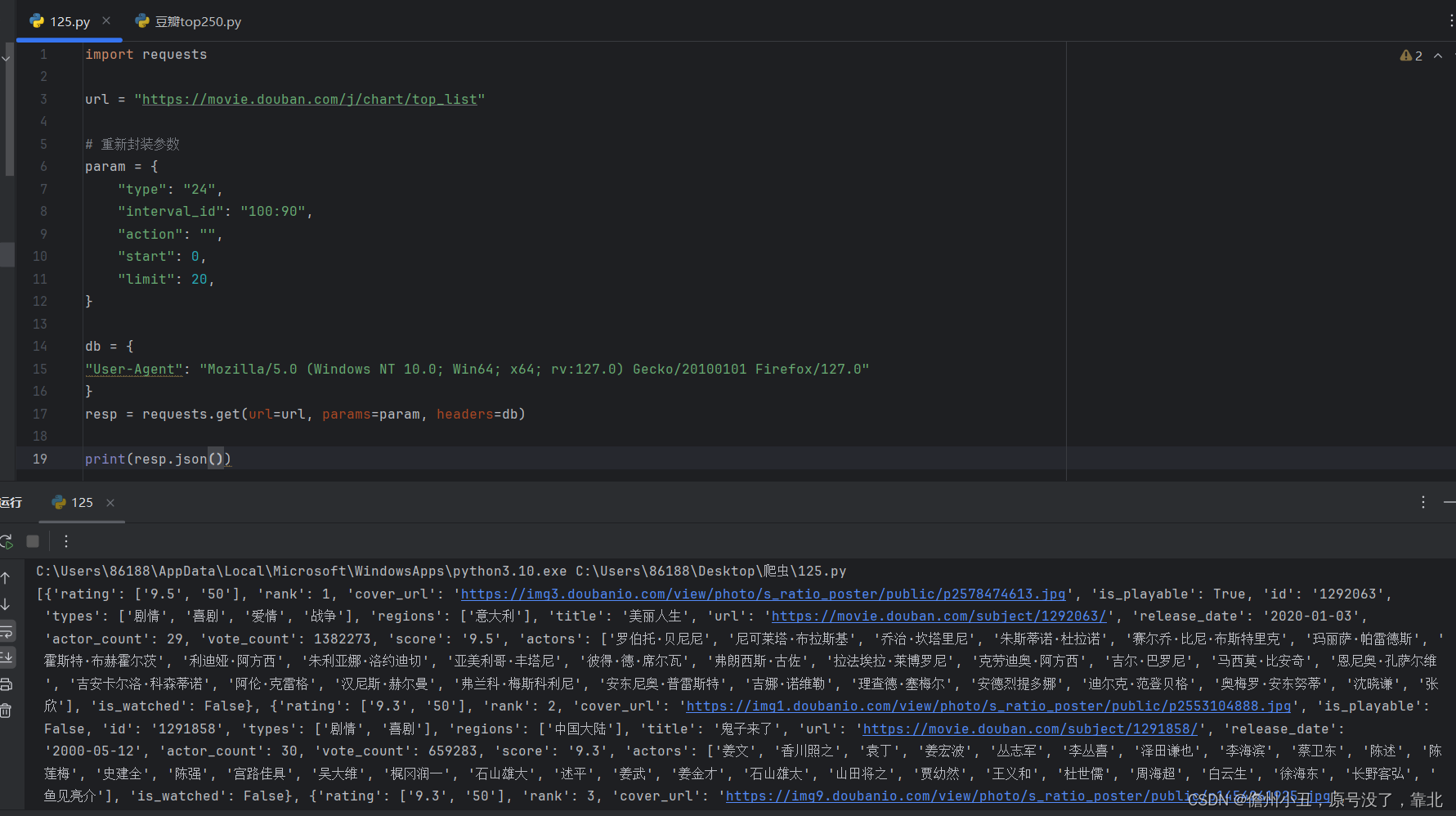
爬取豆瓣电影的网址
https://movie.douban.com/typerank?type_name=%E5%96%9C%E5%89%A7&type=24&interval_id=100:90&action=
由于太长了,写的不好看,进行封装.