垃圾回收 & 浏览器事件循环
垃圾回收
垃圾回收,又称为:GC(garbage collection)
GC 就是负责回收内存里不使用的垃圾。一般的高级语言里面会自带 GC,比如 Java、Python、JavaScript 等,也有无 GC 的语言,比如 C、C++ 等,那这种就需要手动管理内存了。
JavaScript 引擎是如何发现并清理垃圾的呢
- 引用计数 x(不常用,了解即可)
- 标记清除
- 标记压缩(标记整理)
引用计数算法
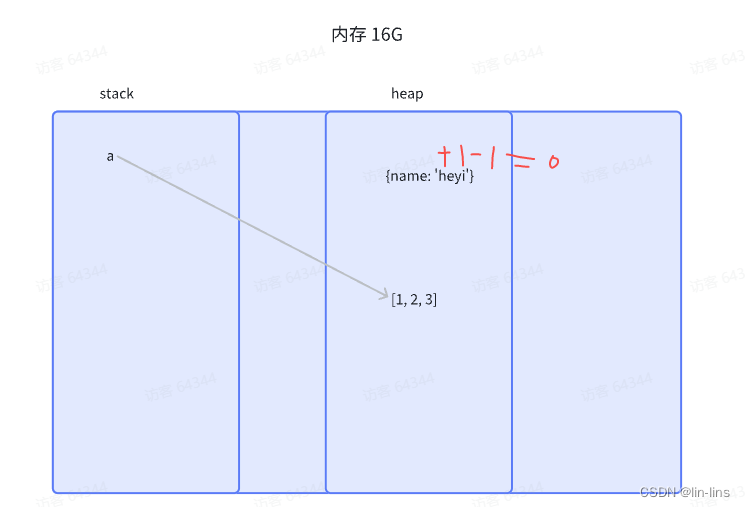
它的策略是跟踪记录每个变量值被使用的次数
- 当声明了一个变量并且将一个引用类型赋值给该变量的时候这个值的引用次数就为 1
- 如果同一个值又被赋给另一个变量,那么引用数加 1
- 如果该变量的值被其他的值覆盖了,则引用次数减 1
- 当这个值的引用次数变为 0 的时候,说明没有变量在使用,这个值没法被访问了,回收空间,垃圾回收器会在运行的时候清理掉引用次数为 0 的值占用的内存
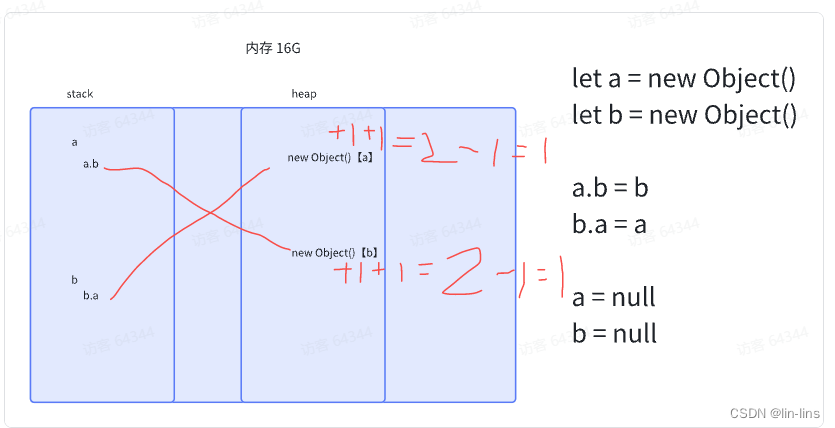
这个算法最怕的就是循环应用,还有比如 JavaScript 中不恰当的闭包写法。
javascript
function test(){
let A = new Object()
let B = new Object()
A.b = B
B.a = A
}
优点
引用计数算法的优点我们对比标记清除来看就会清晰很多,首先引用计数在引用值为 0 时,也就是在变成垃圾的那一刻就会被回收,所以它可以立即回收垃圾
而标记清除算法需要每隔一段时间进行一次,那在应用程序(JS脚本)运行过程中线程就必须要暂停去执行一段时间的 GC,另外,标记清除算法需要遍历堆里的活动以及非活动对象来清除,而引用计数则只需要在引用时计数就可以了
缺点
引用计数的缺点想必大家也都很明朗了,首先它需要一个计数器,而此计数器需要占很大的位置,因为我们也不知道被引用数量的上限,还有就是无法解决循环引用无法回收的问题,这也是最严重的
标记清除(mark-sweep)算法
标记清除(Mark-Sweep),目前在 JavaScript引擎 里这种算法是最常用的,到目前为止的大多数浏览器的 JavaScript引擎 都在采用标记清除算法。
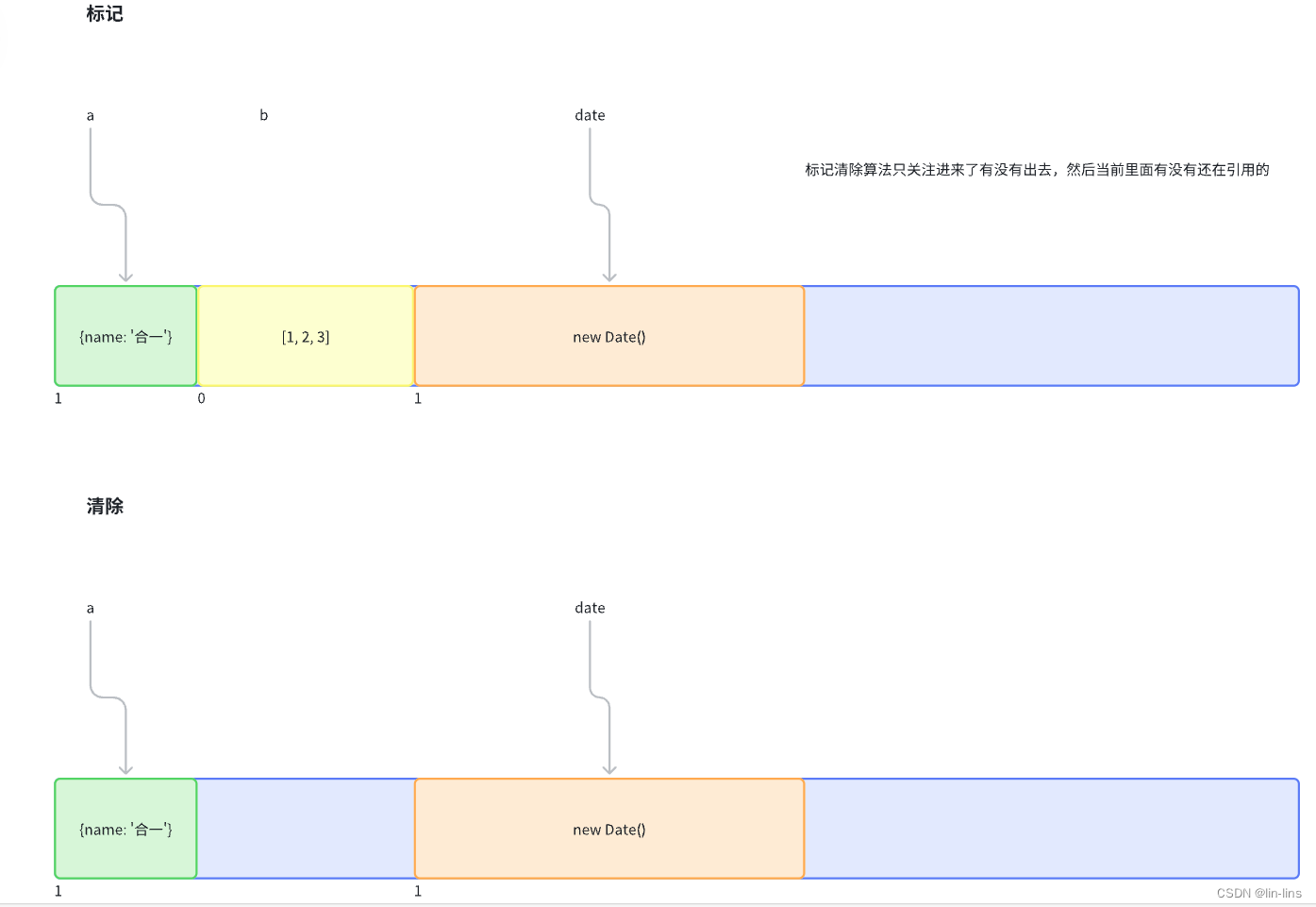
此算法分为 标记 和 清除 两个阶段,标记阶段即为所有活动对象做上标记,清除阶段则把没有标记(也就是非活动对象)销毁
引擎在执行 GC(使用标记清除算法)时,需要从出发点去遍历内存中所有的对象去打标记,而这个出发点有很多,我们称之为一组 根 对象,而所谓的根对象,其实在浏览器环境中包括又不止于 全局Window对象、文档DOM树
整个标记清除算法大致过程就像下面这样
- 垃圾收集器在运行时会给内存中的所有变量都加上一个标记,假设内存中所有对象都是垃圾,全标记为0
- 然后从各个根对象开始遍历,
把不是垃圾的节点改成1 - 清理所有标记为0的垃圾,销毁并回收它们所占用的内存空间
- 最后,把所有内存中对象标记修改为0,等待下一轮垃圾回收
优点
标记清除算法的优点只有一个,那就是实现比较简单,打标记也无非打与不打两种情况,这使得一位二进制位(0和1)就可以为其标记,非常简单
缺点
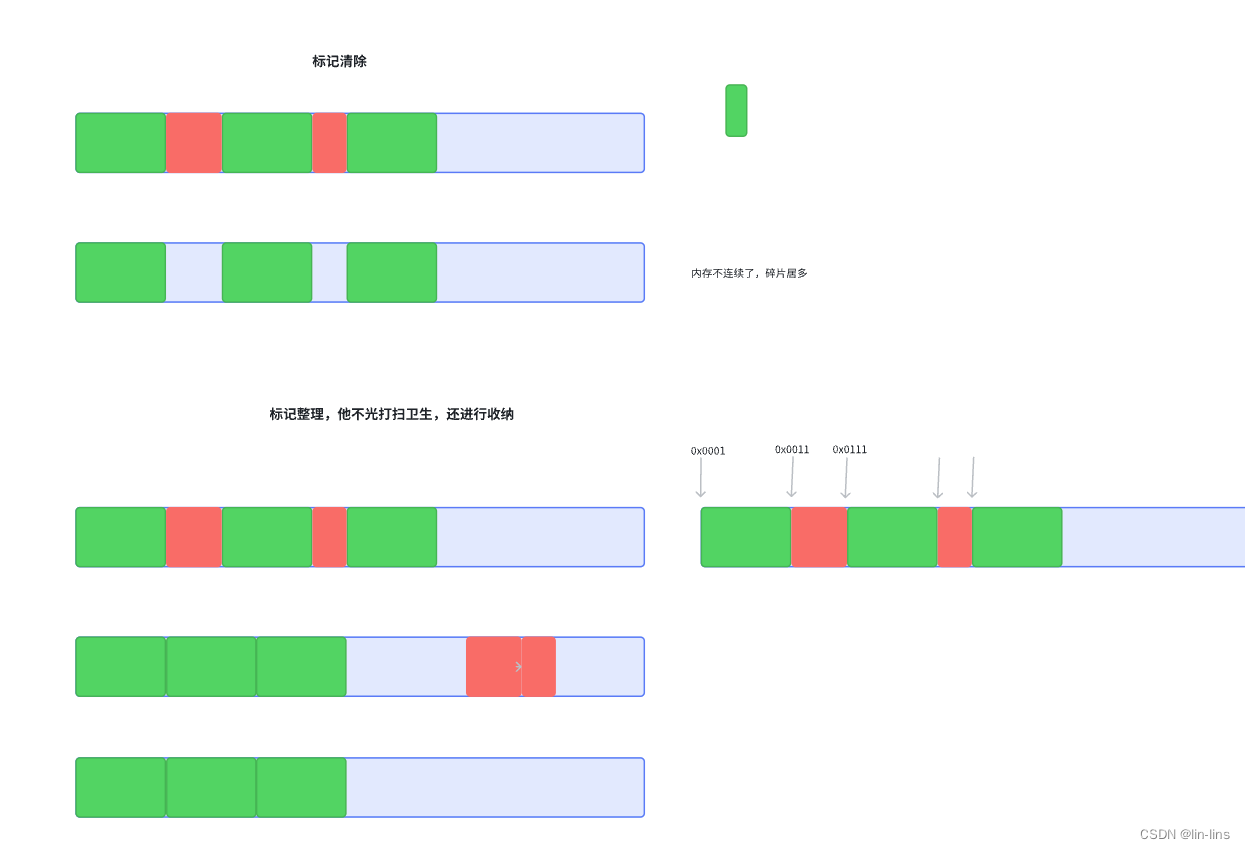
标记清除算法有一个很大的缺点,就是在清除之后,剩余的对象内存位置是不变的,也会导致空闲内存空间是不连续的,出现了 内存碎片(如下图),并且由于剩余空闲内存不是一整块,它是由不同大小内存组成的内存列表,这就牵扯出了内存分配的问题
假设我们新建对象分配内存时需要大小为 size,由于空闲内存是间断的、不连续的,则需要对空闲内存列表进行一次单向遍历找出大于等于 size 的块才能为其分配(如下图)
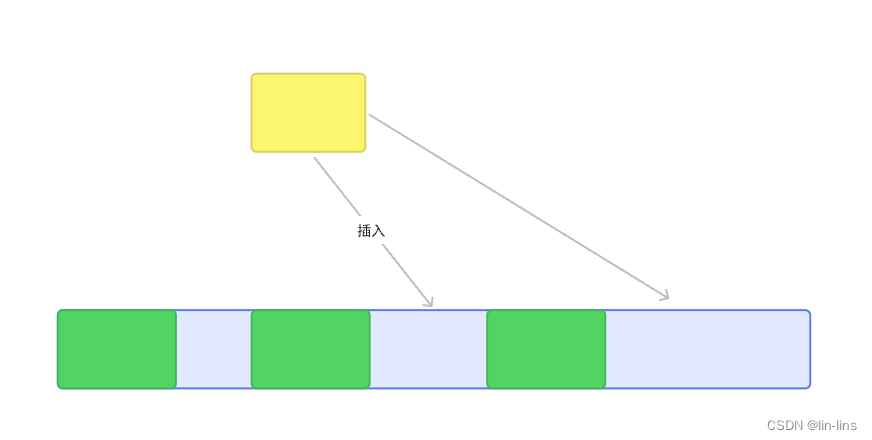
那如何找到合适的块呢?我们可以采取下面三种分配策略
First-fit,找到大于等于 size 的块立即返回Best-fit,遍历整个空闲列表,返回大于等于 size 的最小分块Worst-fit,遍历整个空闲列表,找到最大的分块,然后切成两部分,一部分 size 大小,并将该部分返回
这三种策略里面 Worst-fit 的空间利用率看起来是最合理,但实际上切分之后会造成更多的小块,形成内存碎片,所以不推荐使用,对于 First-fit 和 Best-fit 来说,考虑到分配的速度和效率 First-fit 是更为明智的选择
综上所述,标记清除算法或者说策略就有两个很明显的缺点
- 内存碎片化,空闲内存块是不连续的,容易出现很多空闲内存块,还可能会出现分配所需内存过大的对象时找不到合适的块
- 分配速度慢,因为即便是使用 First-fit 策略,其操作仍是一个 O(n) 的操作,最坏情况是每次都要遍历到最后,同时因为碎片化,大对象的分配效率会更慢
标记整理(Mark-Compact)算法
归根结底,标记清除算法的缺点在于清除之后剩余的对象位置不变而导致的空闲内存不连续,所以只要解决这一点,两个缺点都可以完美解决了
标记整理(Mark-Compact)算法 就可以有效地解决,它的标记阶段和标记清除算法没有什么不同,只是标记结束后,标记整理算法会将活着的对象(即不需要清理的对象)向内存的一端移动,最后清理掉边界的内存
内存管理
- 标记清除算法,不会整理,当空闲区比较大的时候,效率快。
- 标记整理算法,会整理,改变活着的对象的内存地址,每次都在移动,比较麻烦。
所以在浏览器引擎中一般是结合俩种算法。分为新生代和老生代,新生代用标记清除,老生代用标记整理。
V8 的垃圾回收策略主要基于分代式垃圾回收机制,V8 中将堆内存分为新生代和老生代两区域,采用不同的垃圾回收器也就是不同的策略管理垃圾回收
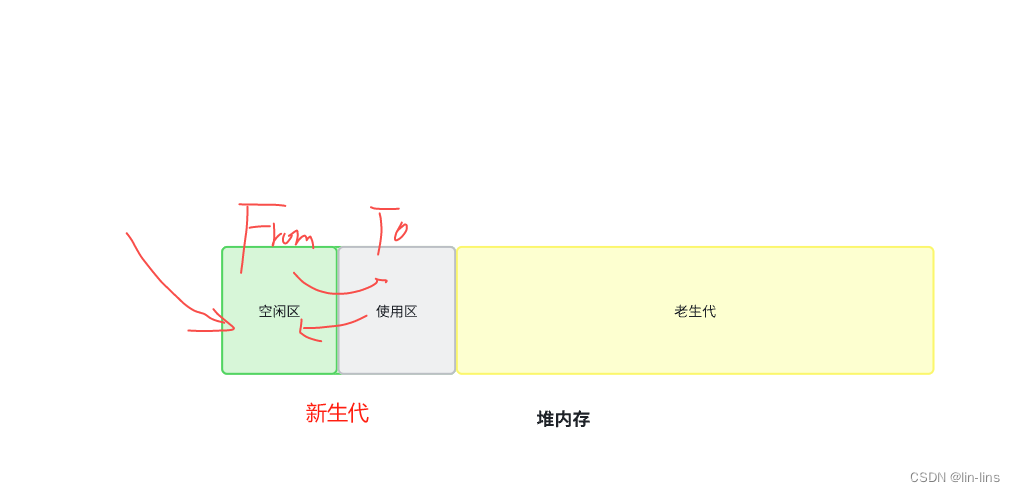
新生代内存管理:
1、当新加入对象时,它们会被存储在使用区(新生代的使用区From)
2、当使用区块写满时,对使用区进行标记,将活着的对象(标记为1的对象)移动到空闲区(To)。
3、清除使用区
4、将使用区和空闲区互换(活着的对象又在使用区了)
如果一个对象经过多次(5次以上)复制后依然存活,那么它将被认为是生命周期较长的对象,且会被移动到老生代中进行管理
或当空闲区的空间使用占比超过25%,或者超大对象(空闲区的空间占用超过了25%)那么这个对象会被直接晋升到老生代空间中。
老生代内存管理:
不同于新生代,老生代中存储的内容是相对使用频繁并且短时间无需清理回收的内容。这部分我们可以使用标记整理进行处理。
从一组根元素开始,递归遍历这组根元素,遍历过程中能到达的元素称为活动对象,没有到达的元素就可以判断为非活动对象
清除阶段老生代垃圾回收器会直接将非活动对象进行清除。
总结:
分代式机制把一些新、小、存活时间短的对象作为新生代,采用一小块内存频率较高的快速清理,而一些大、老、存活时间长的对象作为老生代,使其很少接受检查,新老生代的回收机制及频率是不同的,可以说此机制的出现很大程度提高了垃圾回收机制的效率
面试常问
1. 怎么理解内存泄漏
2. 怎么解决内存泄漏,代码层面如何优化?
- 减少查找
javascript
var i, str = ""
function packageDomGlobal() {
for(i = 0; i < 1000; i++) {
str += i
}
}
// 第二种情况。我们采用局部变量来保存保存相关数据
function packageDomLocal() {
let str = ''
for(let i = 0; i < 1000; i++) {
str += i
}
}- 减少变量声明
javascript
// 第一种情况,循环体中没有抽离出值不变的数据
var test = () => {
let arr = ['czs', 25, 'I love FrontEnd'];
for(let i = 0; i < arr.length; i++){
console.log(arr[i]);
}
}
// 第二种情况,循环体中抽离出值不变的数据
var test = () => {
let arr = ['czs', 25, 'I love FrontEnd'];
const length = arr.length;
for(let i = 0; i < length; i++){
console.log(arr[i]);
}
}- 使用 Performance + Memory 分析内存与性能
浏览器事件循环
JavaScript 特性,单线程,异步实现(队列)
宏任务
注意:源码里没有宏任务这个概念,宏任务是口头的一种概念,源码里宏任务是任务
可以将每次执行栈执行的代码当做是一个宏任务
- I/O
- setTimeout
- setInterval
- setImmediate
- requestAnimationFrame
微任务
源码里有微任务队列概念
当宏任务执行完,会在渲染前,将执行期间所产生的所有微任务都执行完。
执行新的宏任务之前,微任务队列是空的
- process.nextTick
- MutationObserver
- Promise.then catch finally
整体流程
- 取出一个宏任务(通常第一个是全局执行栈),执行内容
- 执行过程中如果遇到微任务,就将它添加到微任务的任务队列中
- 宏任务(里的同步任务)执行完毕后,立即执行当前微任务队列中的所有微任务(依次执行)
- 当前宏任务执行完毕,接收下一个宏任务
- 循环以上过程
事情循环就是不断的重复这些阶段,直到事件任务里没有任务为止
实例:
javascript
Promise.resolve().then(() => {
// 微任务1
console.log('Promise1')
setTimeout(() => {
// 宏任务2
console.log('setTimeout2')
}, 0)
})
setTimeout(() => {
// 宏任务1
console.log('setTimeout1')
Promise.resolve().then(() => {
// 微任务2
console.log('Promise2')
})
}, 0)
// p1 s1 p2 s21、全局执行栈,遇见微任务1,加入微任务执行栈.遇见宏任务1,加入宏任务栈,全局执行栈的同步任务完成。
2、检查微任务队列,执行微任务1,打印console.log('Promise1'),遇见宏任务2,加入宏任务栈。微任务1执行完毕。微任务队列空
3、去宏任务,接收新宏任务1,开始执行,打印console.log('setTimeout1'),遇见微任务2,加入微任务执行栈,宏任务1同步任务完成。
4、检查微任务队列,执行微任务2,打印console.log('Promise2'),微任务2执行完毕。微任务队列空
5、去宏任务,接收新宏任务2,开始执行,打印console.log('setTimeout2'),宏任务2执行完毕
6、检查微任务队列,空,检查宏任务队列,空,执行完毕。
来一道更复杂些的题目
javascript
console.log('stack [1]');
setTimeout(() => console.log("macro [2]"), 0);
setTimeout(() => console.log("macro [3]"), 1);
const p = Promise.resolve();
for(let i = 0; i < 3; i++) p.then(() => {
setTimeout(() => {
console.log('stack [4]')
setTimeout(() => console.log("macro [5]"), 0);
p.then(() => console.log('micro [6]'));
}, 0);
console.log("stack [7]");
});
console.log("macro [8]");
// 请说出答案
/* Result:
stack [1]
macro [8]
stack [7], stack [7], stack [7]
macro [2]
macro [3]
stack [4]
micro [6]
stack [4]
micro [6]
stack [4]
micro [6]
macro [5], macro [5], macro [5]