从表中删除数据
从表中删除数据,也即是delete过程。
什么是表空间
表空间可以看做是InnoDB存储引擎逻辑结构的最高层,所有的数据都存放在表空间中。默认情况下,InnoDB存储引擎有一个共享表空间idbdata1,即所有数据都存放在这个表空间内。如果用户启用了参数 innodb_file_per_table,则每张表内的数据可以单独放到一个表空间内。
如果启用了 innodb_file_per_table 参数,需要注意的是每张表的表空间内存放的只是数据、索引和插入缓冲Bitmap页,其他类的数据,如回滚(undo)信息,插入缓冲索引页、系统事务信息,二次写缓冲(Double write buffer)等还是存放在原来的共享表空间内。这同时也说明了另一个问题,即使在启用了参数 innodb_file_per_table 之后,共享表空间还是会不断地增加其大小。
表数据存放
一个InnoDB表包含两部分, 即: 表结构定义和数据。
表结构定义
在MySQL 8.0版本以前, 表结构是存在以.frm为后缀的文件里。
从MySQL 8.0版本开始, 则已经允许把表结构定义放在系统数据表中了。 表结构定义占用的空间很小。
表数据
表数据既可以存在共享表空间里, 也可以是单独的文件。 这个行为是由参数innodb_file_per_table控制的:
- 这个参数设置为OFF表示的是, 表的数据放在系统共享表空间, 也就是跟数据字典放在一起。
- 这个参数设置为ON表示的是, 每个InnoDB表数据存储在一个以 .ibd为后缀的文件中。
从MySQL 5.6.6版本开始, 它的默认值就是ON了。
规范:建议你不论使用MySQL的哪个版本, 都将这个值设置为ON。 因为, 一个表单独存储为一个文件更容易管理, 而且在你不需要这个表的时候, 通过drop table命令, 系统就会直接删除这个文件。 而如果是放在共享表空间中, 即使表删掉了, 空间也是不会回收的。
清理表数据的方式有以下几种:
1)drop table:删除整个表,回收表空间;若表数据独立存放,则直接删除对应.ibd文件。
2)delete from table:只是把记录/数据页标记为"可复用",但磁盘文件的大小是不会变。
3)truncate table:相当于drop+create。
数据删除流程
问1:使用delete删除表中的记录时,表空间没有被回收,为什么?
数据页存放在文件中,假设数据页中的一些记录被使用delete删除了,这时数据页并不会真正的删除这些记录,而是把这些记录标记为删除,即被标记删除的位置可以被复用。如果数据页上的所有记录都被删除了,则可以复用整个数据页。但是磁盘上,文件不会变小。
问2:记录的复用和数据页的复用有什么区别?
假设要删掉记录R4,InnoDB引擎只会把R4记录标记为删除。如果之后要再插入一个ID在300和600之间的记录时,可能会复用这个位置。但如果插入的是一个ID是800的行, 就不能复用这个位置了。
而当整个数据页中的记录都被删除时(整个页从B+树里面摘掉),可以复用到任何位置。 以下图为例, 如果将数据页page A上的所有记录删除以后, page A会被标记为可复用。 这时候如果要插入一条ID=50的记录需要使用新页的时候, page A是可以被复用的。
如果相邻的两个数据页利用率都很小, 系统就会把这两个页上的数据合到其中一个页上, 另外一个数据页就被标记为可复用。
执行delete命令后,这些可以复用,而没有被使用的空间,看起来就像是"空洞"。
实际上, 不止是删除数据会造成空洞, 插入数据、更新数据也会。
1)插入数据造成空洞
如果数据是按照索引递增顺序插入的, 那么索引是紧凑的。 但如果数据是随机插入的, 就可能造成索引的数据页分裂。假设下图中page A已经满了, 这时我要再插入一行数据, 会怎样呢?
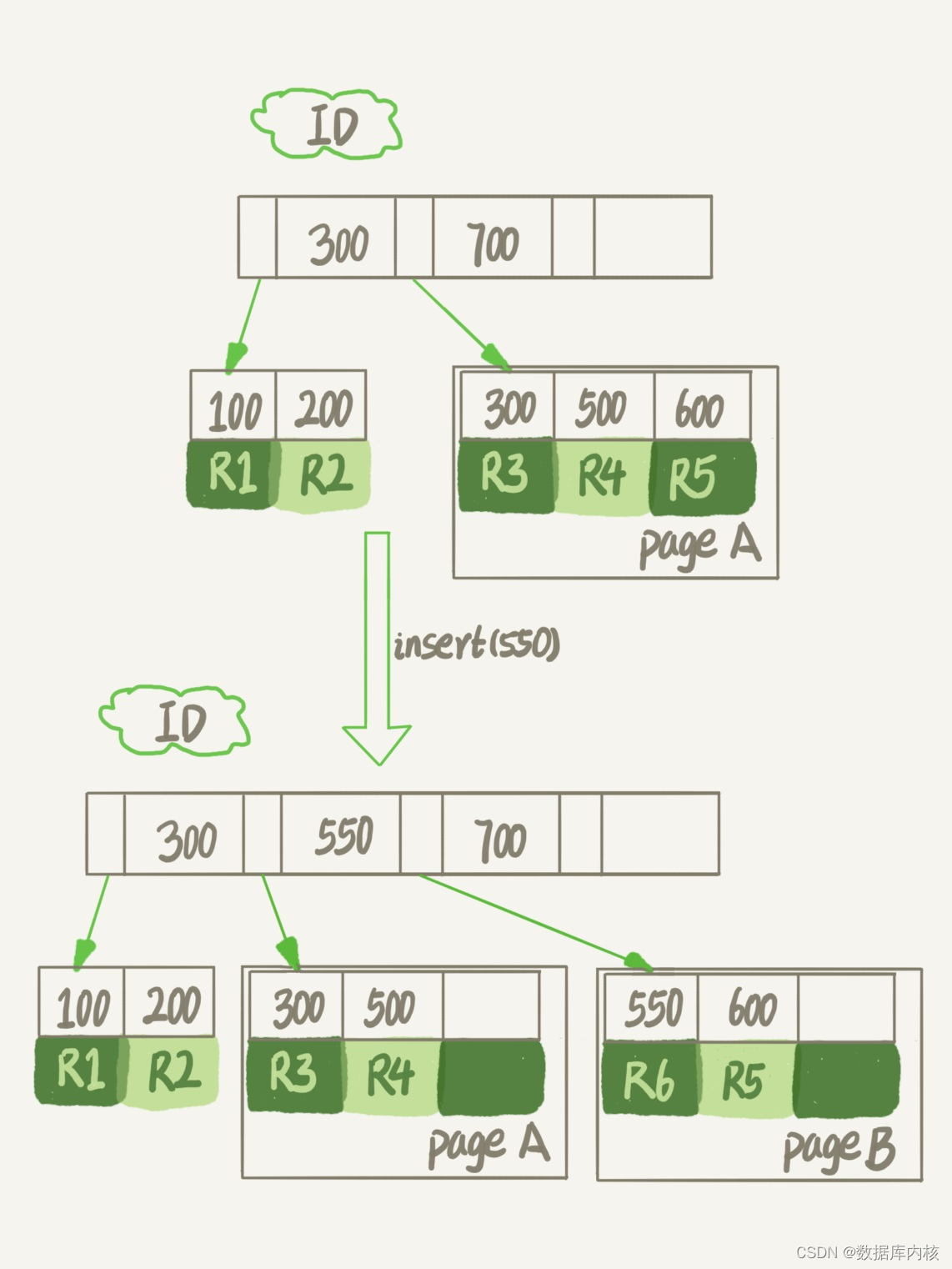
可以看到, 由于page A满了, 再插入一个ID是550的数据时, 就不得不再申请一个新的页面page B来保存数据了。 页分裂完成后, page A的末尾就留下了空洞(注意: 实际上, 可能不止1个记录的位置是空洞) 。
2)更新数据造成空洞
更新索引上的值, 可以理解为删除一个旧的值, 再插入一个新值。 不难理解, 这也是会造成空洞的。
问:如何去掉这些空洞?
也就是说, 经过大量增删改的表, 都是可能存在空洞的。 所以, 如果能够把这些空洞去掉, 就能达到收缩表空间的目的。
而重建表,就可以达到这样的目的。
重建表
重建表的意义在于回收表空间,使得表的存储结构更加紧凑;
那么表又是如何重建的呢?
假设有一个表A,需要做空间收缩,把表中存在的空洞去掉,具体过程如下:
1)新建一个与表A结构相同的表B;
2)按照主键ID递增的顺序,把数据一行一行地从表A里读出来再插入到表B中;
3)把表B作为临时表, 数据从表A导入表B的操作完成后, 用表B替换A, 从效果上看, 就起到了收缩表A空间的作用。
MySQL可以使用如下命令重建表:
sql
alter table A engine=InnoDB;MySQL5.6之前版本重建表示意图:
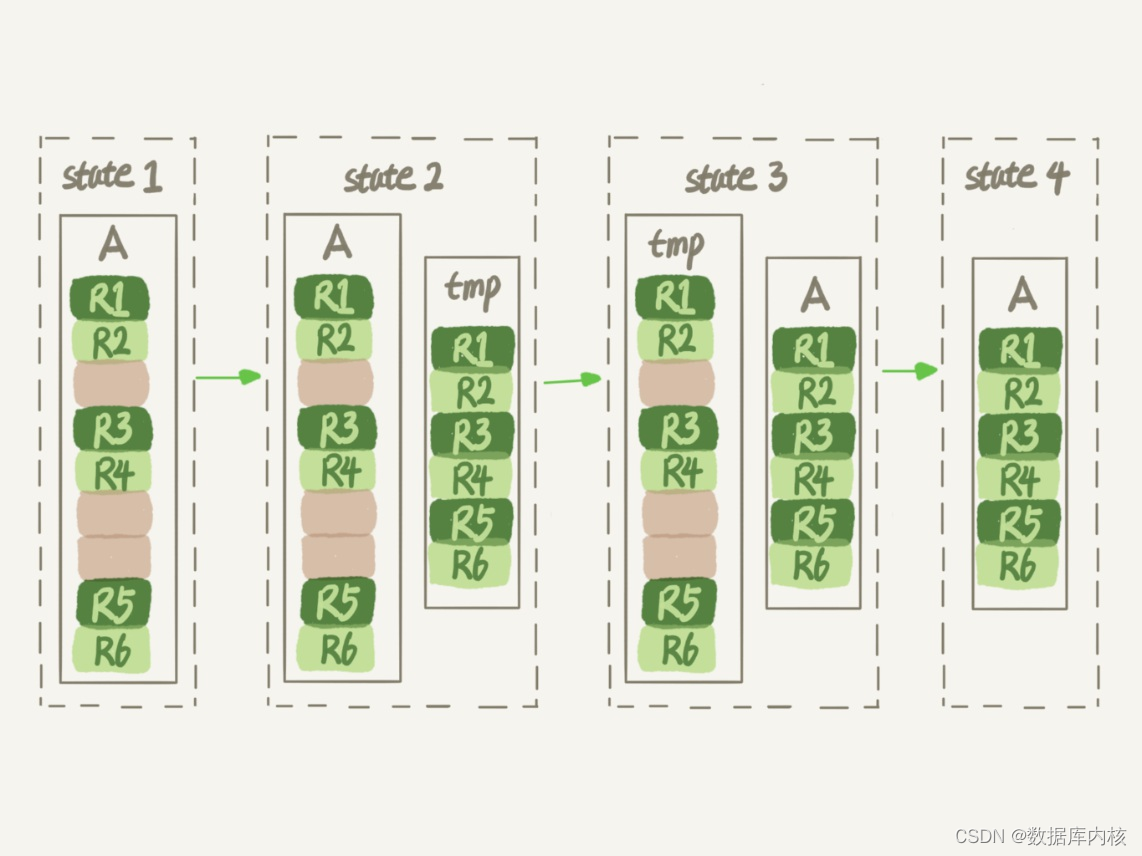
显然, 花时间最多的步骤是往临时表插入数据的过程, 如果在这个过程中, 有新的数据要写入到表A的话, 就会造成数据丢失。 因此, 在整个DDL过程中, 表A中不能有更新。 也就是说, 这个DDL不是Online的。(MySQL5.6之前版本)
在MySQL 5.6版本开始引入的Online DDL, 对这个操作流程做了优化。引入了Online DDL之后, 重建表的流程:
1)建立一个临时文件,扫描表A主键的所有数据页;
2)用数据页中表A的记录生成B+树,存储到临时文件中;
3)生成临时文件的过程中,将所有对A的操作记录在一个日志文件(row log)中,对应的是图中state2的状态;
4)临时文件生成后,将日志文件中的操作应用到临时文件,得到一个逻辑数据上与表A相同的数据文件,对应的就是图中state3的状态;
5)用临时文件替换表A的数据文件;
MySQL5.6之后版本重建表示意图:
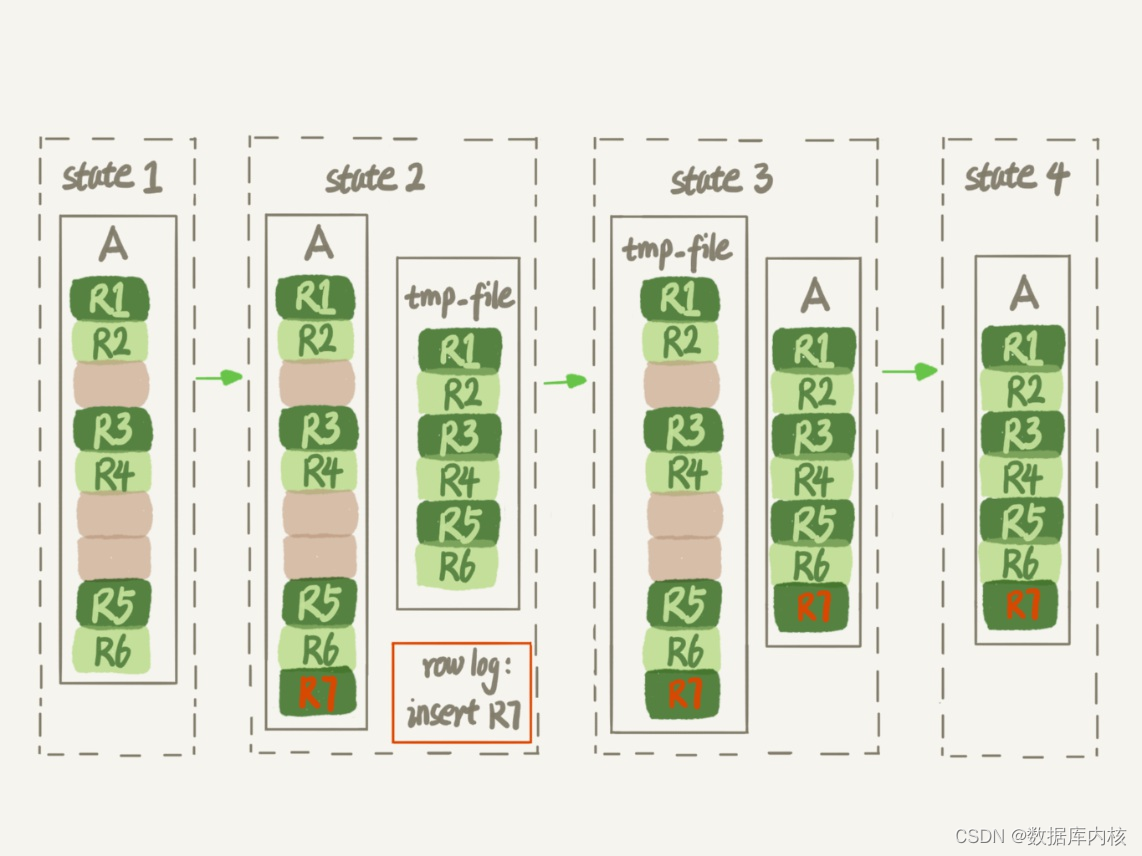
由于日志文件的存在,允许对表A做增删改操作。 这也就是Online DDL名字的来源,所谓Online,即对表进行DDL操作的同时,允许对该表进行增删改操作(DML)。
Online DDL过程需要加MDL锁(元数据锁),过程如下:
1)拿MDL写锁;
2)降级成MDL读锁;
3)真正做DDL;
4)升级成MDL写锁;
5)释放MDL锁;
之所以加写锁,是为了等待加读锁的DDL或DML完成;退化为读锁,是为了不阻塞DML语句的执行;
注1:
- mysql
- mysql >= 5.6,改进重建表过程,允许Online DDL。
注2:重建表的过程最耗时的是拷贝数据,因而该过程中允许DML,将会获得比较多的收益;这也是Online DDL的意义;
注3:对于大表进行重建表的操作消耗较大的CPU和IO,因而需要考虑在业务不繁忙的情况下进行;为保证安全,可以使用gh-ost工具;
Copy和Inplace
copy和inplace是重建表的两种策略,重建表默认使用的是inplace。
可以通过如下命令显示指定重建表的策略:
sql
alter table t engine=innodb, ALGORITHM = inplace;
alter table t engine=innodb, ALGORITHM = copy;问1:copy和inplace有什么区别?
1)copy的含义:当使用ALGORITHM=copy的时候, 表示的是强制拷贝表, 对应的流程就是上一小节第一张图的操作过程。
2)inlace的含义:在上一小节第二张图中,把表A重建出来的数据存放在"tmp_file"里的, 这个临时文件是InnoDB在内部创建出来的。 整个过程都是在InnoDB内部完成。对于server层来说, 没有把数据挪动到临时表, 是一个"原地"操作, 这就是"inplace"名称的来源。所谓inplace,是索引创建在原表上直接进行,而表数据依然需要数据拷贝;区别在于:
- 拷贝过程不记录undo log和redo log;
- 二级索引是有序的,可以按顺序加载;
- 无需Change Buffer,因为对于二级索引没有随机写操作;
问2:如果你有一个1TB的表, 现在磁盘间是1.2TB, 能不能做一个inplace的DDL呢?
答:不能。
因为, tmp_file也是要占用临时空间的。我们重建表的这个语句alter table t engine=InnoDB, 其实隐含的意思是:
sql
-- 重建表
alter table t engine=innodb, ALGORITHM=inplace;问3:inplace跟Online是不是就是一个意思?
答:不是。只是在重建表这个逻辑中刚好是这样而已。
比如, 如果我要给InnoDB表的一个字段加全文索引, 写法是:
sql
alter table t add FULLTEXT(field_name);这个过程是inplace的, 但会阻塞增删改操作, 是非Online的。
如果说这两个逻辑之间的关系是什么的话, 可以概括为:
- DDL过程如果是Online的, 就一定是inplace的;
- 反过来未必, 也就是说inplace的DDL, 有可能不是Online的。 截止到MySQL 8.0, 添加全文索引(FULLTEXTindex) 和空间索引(SPATIAL index)就属于这种情况。
问4:使用optimize table、 analyze table和alter table这三种方式重建表有什么区别?
1)从MySQL 5.6版本开始, alter table t engine = InnoDB(也就是recreate) 默认的就是上一小节第二张图的流程了。
2)analyze table t 其实不是重建表, 只是对表的索引信息做重新统计, 没有修改数据, 这个过程中加了MDL读锁。
3)optimize table t 等于recreate+analyze。
问5:假设现在有人碰到了一个"想要收缩表空间,结果适得其反"的情况,看上去是这样的:
一个表t文件大小为1TB;
对这个表执行 alter table t engine=InnoDB;
发现执行完成后,空间不仅没变小,还稍微大了一点儿,比如变成了1.01TB。
你觉得可能是什么原因呢 ?
答:
1)这个表本身就已经没有空洞了,比如刚做过一次重建表操作。且在重建表的时候,InnoDB不会把整张表占满,每个页留了1/16给后续的更新用,所以重建之后,文件就反而变大了。
2)重建过程中,存在DML执行,因而在row log重新应用时,又产生了空洞。