背景
k8s的学习环境(用kubeadm方式搭建),我也搭过几次了,但都有点问题。
要么在云服务器上弄,这个的问题是就只有一台轻量服务器,只能搭个单节点的;后来买了一台便宜的,所以就有了两台,但是不在一个zone,一个是广州,一个是成都,内网不通,感觉搭起来很麻烦,还没试过。
要么是在本机的虚拟机上搞(vmware或virtualbox这种),这种是没问题,就是笔记本性能一般,内存还得留着给idea、chrome这些,每次要学习实践一下,都得打开两台虚拟机,内存扛不住,也比较繁琐,久了就懒得实践了。
对我来说,最好的就是在公司的开发服务器上搭建(手里有些服务器的cpu、内存还比较闲),公司的服务器的问题在于,网络是完全的内网环境,拉取镜像是个问题,当然也可以申请外网,就是麻烦;而且,申请外网的时候,有一些困难,就是你今天申请了某个国内镜像源,过两天,这个镜像源就挂了/关了,又得重新申请,最近不就是一堆镜像源停止服务了吗。你说,我不访问镜像源,就申请docker官方镜像的外网权限行不行呢,结果,我发现,docker pull镜像的时候,竟然要访问一个被墙了的网站:https://production.cloudflare.docker.com
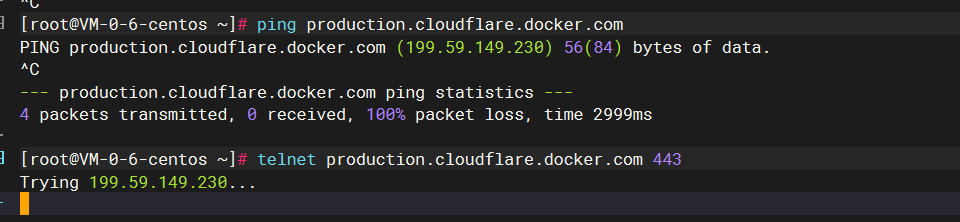
查了官方文档(https://docs.docker.com/desktop/allow-list/),pull的时候确实要访问这个地址,
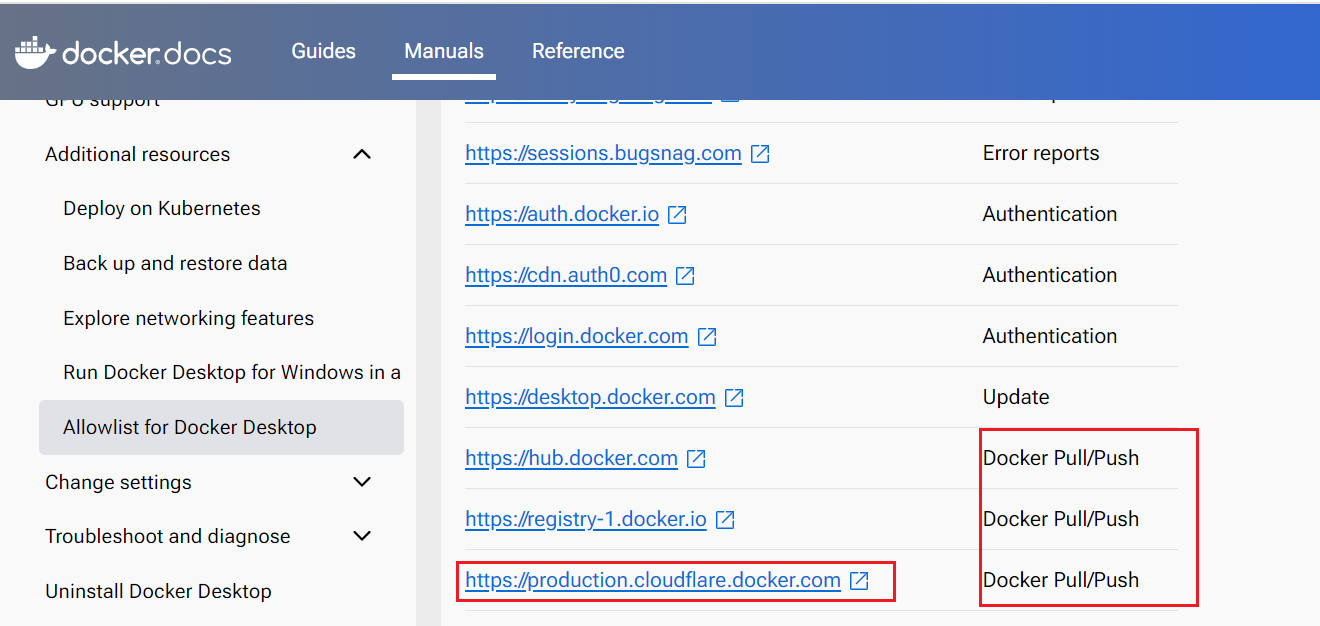
既然都没法访问,那我这网络就没法申请了。
当然,办法总比困难多,我这次采用的是最保险的方式,先找一台有网的机器,用kubeadm先搭建一次,把镜像弄下来之后,docker save的方式将镜像导出,然后离线传输到内网机器上,docker load就行了。
所以,我先讲讲,在有网的机器上,怎么利用kubeadm来搭建k8s集群。
另外,这种离线导入导出的方式是繁琐一些,后面我们慢慢再用其他方式,如自建镜像源等,来简化我们的使用;镜像问题的解决方式也很多,因为目前很多玩nas的,都受到影响了,因此,网上很多相关教程,我们参考着弄就行了。
服务器资源
因为是先讲讲正常机器,有外网的情况下的方式,所以我这边用virtualbox搞了两个干净的虚拟机,里面啥都没安装.
10.0.2.8 node4,准备作为主节点
10.0.2.9 node5,准备作为工作节点
操作系统都是centos 7.9。
重要组件的简单理解
容器编排理解
我个人理解,k8s负责的是容器编排,容器为什么需要编排呢?先说说最早的时候,我们怎么用docker的,我们n个服务加一堆中间件,当时经常要部署各种演示环境给客户演示啥的,就想着搞成个大的docker容器,把docker当虚拟机用,这样的话,代码架构、配置基本啥都不用改。
但是,主流的方式是,每个docker容器里面,只跑一个进程,如果按照这种模型来弄的话,就有点不好搞了,比如,服务A依赖中间件A,中间件A现在的地址变成了容器对外暴露的地址,那服务A肯定是需要改配置啥的,对于一套复杂的微服务系统来说,把一堆配置改对就不容易了,而且改了配置之后,是不是得重新测试下。
还有服务之间的依赖关系,比如服务A依赖服务B,启动过程中就要调服务B的接口这种,在这种容器模型下也是麻烦事。
docker自己也出了docker-compose,希望来解决服务之间的编排问题,这个东西,经常在简单的开源项目部署时,也时常看到(比如各种博客系统,前端+数据库之类的,就用docker-compose这种来搞)。
但是,docker-compose我感觉好像是解决不了复杂的容器间关系的编排。
举个例子,很多c和c++开发的程序,利用共享内存来通信,或者是利用system v的信号量、消息队列、共享内存通信的;还有用Unix Domain Socket通信的(比如docker cli和docker daemon间默认就是用这种方式通信),如果这些都要搞成一个容器一个进程,那容器间能支持这些共享内存、消息队列、unix domain socket的通信方式吗,即使是单机能支持了,跨主机又该怎么办?
所以,最终就是k8s中提出了pod的概念,pod是k8s中最小的调度单位,在一个pod中,里面的各个进程共享各种linux命名空间(Linux中的命名空间(namespaces)是一种轻量级的虚拟化技术,让进程看起来像是在自己的独立系统中运行,也就是说进程只能看到相同命名空间内的进程和资源,而看不到其他命名空间的资源),让在同一个pod中的进程,可以互相看到对方,可以互相通信,而且是以宿主机内核支持的任意方式进行通信(如上面提到的共享内存、Unix Domain Socket等)。
node agent之kubelet
K8S中,我以目前的认识来看,kubelet,算是一个相当重要的组件。它被安装在每一台node机器上,作为该node上的一个后台服务运行,对外提供api接口。
先看下官方解释:
The kubelet is the primary "node agent" that runs on each node. It can register the node with the apiserver.
kubelet是基础的node agent,运行每个node上,它可以注册node到api server。
The kubelet works in terms of a PodSpec. A PodSpec is a YAML or JSON object that describes a pod.
The kubelet takes a set of PodSpecs that are provided through various mechanisms (primarily through the apiserver) and ensures that the containers described in those PodSpecs are running and healthy.
kubelet主要和PodSpec打交道。PodSpec(pod规格)是一个yaml或者json,用来描述一个pod的详情。kubelet会通过各种方式来接收PodSpec(主要是通过apiserver),并确保PodSpec中描述的容器保持运行及正常。
https://kubernetes.io/docs/reference/command-line-tools-reference/kubelet/
这种架构呢,就和现在的很多日志、监控这类的架构很像,就是agent/server的架构,比如filebeat、Prometheus的node exporter,如果是在大厂,相信会看到更多各种自研的agent,这种的优势在于,agent的升级独立于业务服务的升级,如果你是agent的提供方,你要是搞了个sdk提供给业务方,那升级的事,你基本推不动,业务方用得好好的,为啥你agent要升级我就要升级,所以,这种agent架构很受欢迎,另外,本机的业务服务调用agent,也减少了网络调用,响应速度更快,这也是一个优势。
当然,我们说,agent相对于sdk方案,升级要容易,但也没有那么容易,agent承上启下,一方面作为server提供给业务服务,一方面作为client和agent的server方交互(不管是推还是拉),毕竟是多引入了一个组件,维护起来复杂得多。(像小公司,我就给sdk给业务方,sdk直连我的服务端,这样可以少维护一个agent,爽歪歪。)
kubelet也是这样的一个agent,一方面采集node机器的各类数据,上报给k8s的api-server;你可以这样想,kubelet作为这台node机器上的agent(代理人),要掌握这台机器上的各类情况,比如,基础资源情况(CPU、内存、磁盘、操作系统信息、内核版本、容器运行时的信息、kubelet版本、硬件情况如:是x86还是arm),另外,最终pod不也是在当前node上运行吗,那这些pod运行情况怎么样,pod的status、ip、启动时间、pod的事件,等各种数据,都需要上报。
另外,其实kubelet也不是说非得和api-server一起搭配使用,它自身也可以独立运行(具体可搜搜kubelet standalone),此时,它就不需要再上报这些各种数据给api server了。
kubelet作为server的一面
既然是一个server,那自然要处理请求。那要通过什么方式将请求发给kubelet呢?
kubelet启动时,可以配置很多参数,可以参见:
https://kubernetes.io/docs/reference/command-line-tools-reference/kubelet/
https端口10250
shell
--port int32 Default: 10250
The port for the kubelet to serve on. 这个接口主要是提供给api server调用的,协议为https。用途的话,主要有如下几项:
https://kubernetes.io/docs/reference/access-authn-authz/kubelet-authn-authz/
The connections from the API server to the kubelet are used for:
- Fetching logs for pods.
获取pod的日志- Attaching (usually through kubectl) to running pods.
附着到运行中的pod- Providing the kubelet's port-forwarding functionality.
端口转发功能
这个里面,具体有哪些api呢?
查阅了网上资料,发现文档没怎么提这块,主要有这么几种方式去了解:
-
看kubelet的源码;
-
有个开源项目,给kubelet做了个client,这里面列了一些api:
https://github.com/cyberark/kubeletctl/blob/master/API_TABLE.md
http端口10248
这个端口是使用kubeadm安装后,默认就打开了的。该端口就是暴露出来的一个health端口。
shell
--healthz-port int32 Default: 10248
The port of the localhost healthz endpoint (set to 0 to disable).
shell
[root@VM-12-4-centos ~]#curl localhost:10248/healthz
okhttp端口10255
这个端口功能类似于10250,只是10250是https的,也需要认证才能调用。而这个10255端口则不需要认证。
shell
--read-only-port int32 Default: 10255
The read-only port for the kubelet to serve on with no authentication/authorization (set to 0 to disable)我发现这个端口默认没开启,我是通过如下方式开启:
修改kubelet的默认配置文件:vim /var/lib/kubelet/config.yaml,在healthzPort行下增加如下行:
shell
healthzPort: 10248
readOnlyPort: 10255然后systemctl restart kubelet重启。
shell
[root@VM-12-4-centos ~]# curl localhost:10255/stats/summary
{
"node": {
"nodeName": "vm-12-4-centos",
"systemContainers": [
{
"name": "pods",
"startTime": "2024-06-12T14:26:01Z",
"cpu": {
"time": "2024-06-22T07:55:41Z",
"usageNanoCores": 184092381,
"usageCoreNanoSeconds": 65091327269653
},
"memory": {
"time": "2024-06-22T07:55:41Z",
"availableBytes": 1087467520,
"usageBytes": 1179738112,
"workingSetBytes": 1008148480,
"rssBytes": 835305472,
"pageFaults": 0,
"majorPageFaults": 0
}
},
...kubelet接收podSpec的方式
根据文档:https://kubernetes.io/docs/reference/command-line-tools-reference/kubelet/
接收podSpec的主要方式是通过api server,即上面提到的https端口:10250.
另外的方式为:
File: Path passed as a flag on the command line. Files under this path will be monitored periodically for updates. The monitoring period is 20s by default and is configurable via a flag.
通过命令行传递的路径。在这个路径下的会被监控,周期性地检查更新。每20s检查一次。
HTTP endpoint: HTTP endpoint passed as a parameter on the command line. This endpoint is checked every 20 seconds (also configurable with a flag).
http接口:通过命令行传递,每20s检查一次。
这里,文件这种方式,咱们后面还会提到。在用kubeadm初次安装k8s集群时,k8s的服务端组件(api-server、etcd等,为啥自己就启动了),其实就是kubeadm在指定目录下(默认为/var/lib/kubelet/config.yaml中的staticPodPath: /etc/kubernetes/manifests),生成了api-server、etcd这几个组件的podSpec,然后kubelet就根据这些podSpec自动创建了对应的pod。
我们通过kubeadm的文档,也能确认这一点:
Generate static Pod manifests for control plane components
Kubeadm writes static Pod manifest files for control plane components to /etc/kubernetes/manifests. The kubelet watches this directory for Pods to be created on startup.
为控制面的组件(即k8s的服务端组件)生成静态的pod manifest,生成的文件存放在/etc/kubernetes/manifests。kubelet监测这个目录,来生成对应的pod。
CRI
CRI全称:Container Runtime Interface (CRI),可以理解为一套标准接口,为的就是k8s和具体的容器解耦,这套接口就是:如果容器的具体实现方,想要通过CRI接口来和k8s交互,就需要实现这套接口。
说白了就是定标准。
这些在各行各业的案例太多了,比如各汽车制造商给用户提供的接口基本都差不多,方向盘、油门、刹车;在java领域,它定义了一套自己的java虚拟机规范,各个厂商可以自由按照规范来实现。
这套接口长啥样呢?这套接口是用protobuf定义的,
https://github.com/kubernetes/cri-api/blob/c75ef5b/pkg/apis/runtime/v1/api.proto
主要包含两类接口,运行时接口和镜像相关接口
shell
// Runtime service defines the public APIs for remote container runtimes
service RuntimeService
// ImageService defines the public APIs for managing images.
service ImageService 运行时相关接口,也包含了CURD:
shell
// CreateContainer creates a new container in specified PodSandbox
rpc CreateContainer(CreateContainerRequest) returns (CreateContainerResponse) {}
// StartContainer starts the container.
rpc StartContainer(StartContainerRequest) returns (StartContainerResponse) {}
rpc StopContainer(StopContainerRequest) returns (StopContainerResponse) {}
rpc RemoveContainer(RemoveContainerRequest) returns (RemoveContainerResponse) {}
// ListContainers lists all containers by filters.
rpc ListContainers(ListContainersRequest) returns (ListContainersResponse) {}
// ContainerStatus returns status of the container. If the container is not
// present, returns an error.
rpc ContainerStatus(ContainerStatusRequest) returns (ContainerStatusResponse) {}也有执行类接口:
shell
// ExecSync runs a command in a container synchronously.
rpc ExecSync(ExecSyncRequest) returns (ExecSyncResponse) {}
// Exec prepares a streaming endpoint to execute a command in the container.
rpc Exec(ExecRequest) returns (ExecResponse) {}
// Attach prepares a streaming endpoint to attach to a running container.
rpc Attach(AttachRequest) returns (AttachResponse) {}
// PortForward prepares a streaming endpoint to forward ports from a PodSandbox.
rpc PortForward(PortForwardRequest) returns (PortForwardResponse) {}也有统计类的接口:
shell
// ContainerStats returns stats of the container. If the container does not
// exist, the call returns an error.
rpc ContainerStats(ContainerStatsRequest) returns (ContainerStatsResponse) {}
// ListContainerStats returns stats of all running containers.
rpc ListContainerStats(ListContainerStatsRequest) returns (ListContainerStatsResponse) {}CRI实现之docker
先来讲重量级的实现:docker。docker曾经也是风头无两,可惜最终在容器编排领域,还是拜下阵来,现在只能安心地当一个容器运行时。
k8s刚开始的时候,只集成了一个容器实现,那就是docker。后来,准备引入另一个实现:rkt的时候,发现了问题,这样会导致k8s和特定的容器运行时紧密耦合,这样要求集成方要同时理解k8s和容器实现,要求很高,另外,容器运行时出现了bug,也需要k8s跟着进行发版修复。
2016年,k8s引入了CRI这一套接口,在这之后,kubelet只和CRI打交道,不再和具体的容器实现打交道。这样的话,就要求容器运行时需要实现CRI,但是,比如docker,docker的诞生早于CRI,docker当然也不是不能改,但当时k8s和docker公司正在激烈竞争,docker公司肯定不会配合k8s来实现CRI接口。(https://www.aquasec.com/cloud-native-academy/container-security/container-runtime-interface/)
所以,k8s自己在kubelet的进程代码中,写了个适配层:dockershim,相当于将kubelet的CRI请求转换为对docker的请求。
这样一套适配层,维护起来也是不轻松的,终于,在Kubernetes 1.20版本(2020年12月8日),Dockershim被标记为过期(https://kubernetes.io/blog/2020/12/02/dont-panic-kubernetes-and-docker/),并将在后续的版本被正式弃用。
2022年4月,k8s发布了1.24,在这个版本中,kubelet中移除了dockershim这个适配层,意味着,kubelet无法将CRI请求转发给docker了。(https://kubernetes.io/blog/2022/04/07/upcoming-changes-in-kubernetes-1-24/)
官方给出的建议是,切换到其他支持CRI接口的容器运行时,比如:containerd、CRI-O、Mirantis Container Runtime(docker的商业版本)。
如果你就是想用docker作为容器运行时怎么办呢,只能说,东方不亮西方亮。k8s团队不想维护这个适配层了,那就只能其他人来了。其他人是谁呢,就是docker公司的人。docker公司如果真的不开发这么一个适配层出来,那损失的用户应该也不少,迫于压力,docker公司开发了一个叫cri-dockerd的适配层,这个适配层服务,实现了CRI接口,将CRI请求转为对docker的请求。
这个cri-dockerd的项目介绍如下:
https://mirantis.github.io/cri-dockerd/about/motivation/
Mirantis and Docker have agreed to partner to maintain the shim code standalone outside Kubernetes, as a conformant CRI interface for the Docker Engine API. This means that you can continue to build Kubernetes based on the Docker Engine as before, just switching from the built in dockershim to the external one.
Mirantis(docker的商业化公司吧)和docker同意独立于k8s,合作维护适配层代码,为docker提供CRI适配。这意味着你可以继续像之前一样在k8s中使用docker,只需要从内置的dockershim切换为外置的cri-dockerd。
所以,要继续使用docker的话,要先安装docker、再安装cri-dockerd,就可以了。
CRI实现之containerd
containerd 是一个开源的容器运行时,最初是作为 Docker 项目的一部分开发的。它由 Docker 公司于 2017 年开源,并移交给了 CNCF(Cloud Native Computing Foundation)管理。
在目前的docker版本中(当前为2024年6月),你安装了docker engine后,底层依然有containerd进程,只是不确定这个containerd进程和开源的版本是否一致,还是已经分叉。
反正目前来说,containerd已经成为了k8s重要的一个容器运行时。它的优点在于,它比docker更轻量,它只关注容器运行时,而你要用docker的话,不仅重一些,还要搞个适配层:cri-dockerd服务。
但是咋说呢,docker目前还是比较习惯,后续再来捣鼓这个吧。其他容器运行时,CRI-O等,就先不介绍了。
总结
本来是想记录下安装的,结果发现,在部署之前,最好把组件间的关系讲一下,便于在安装时知其然,就没收住。
下篇再讲安装吧。我也是新学这个,肯定有说的不对的地方,还请帮忙多指正。