Apache Paimon系列之:Append Table和Append Queue
- [一、Append Table](#一、Append Table)
- [二、Data Distribution](#二、Data Distribution)
- 三、自动小文件合并
- [四、Append Queue](#四、Append Queue)
- 五、压缩
- [六、Streaming Source](#六、Streaming Source)
- [七、Watermark Definition](#七、Watermark Definition)
- [八、Bounded Stream](#八、Bounded Stream)
一、Append Table
如果表没有定义主键,则默认为追加表。
您只能以流式方式将完整记录插入到表中。此类表适合不需要流式更新的用例(例如日志数据同步)。
sql
CREATE TABLE my_table (
product_id BIGINT,
price DOUBLE,
sales BIGINT
);二、Data Distribution
默认情况下,append table没有bucket的概念。它的作用就像一个 Hive 表。数据文件放置在分区下,可以在其中重新组织和重新排序以加快查询速度。
三、自动小文件合并
在流式写入作业中,如果没有bucket定义,则writer中不会进行压缩,而是使用Compact Coordinator扫描小文件并将压缩任务传递给Compact Worker。在流模式下,如果在flink中运行insert sql,拓扑将是这样的:
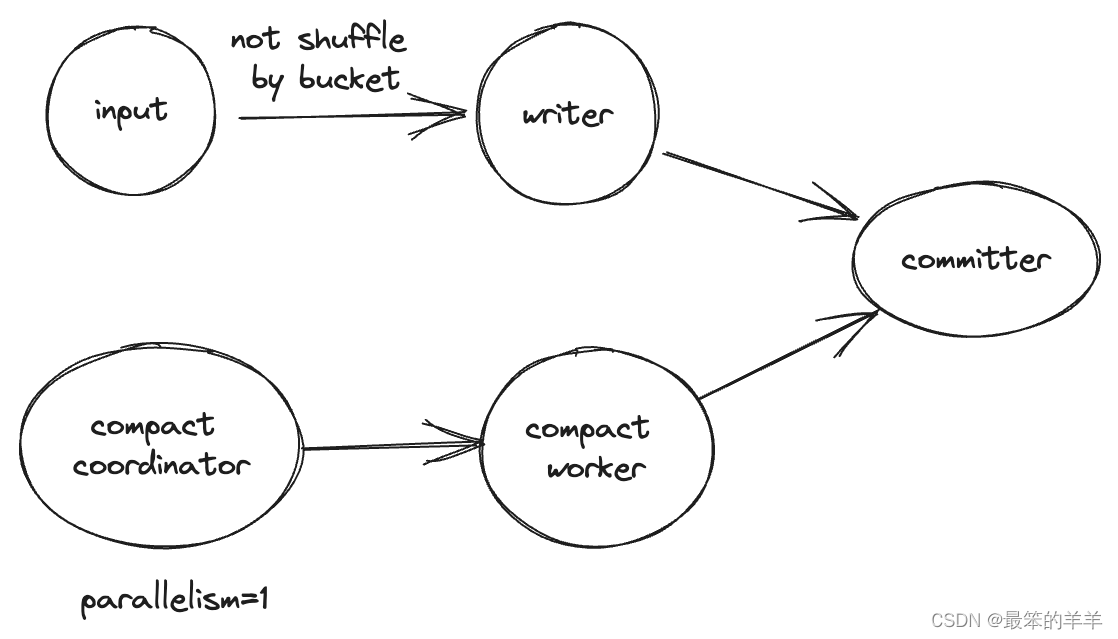
不用担心反压,压实永远不会反压。
如果将 write-only 设置为 true,Compact Coordinator 和 Compact Worker 将在拓扑中删除。
自动压缩仅在 Flink 引擎流模式下支持。您还可以通过 paimon 中的 flink 操作在 flink 中启动压缩作业,并通过 set write-only 禁用所有其他压缩。
四、Append Queue
在这种模式下,您可以将append table视为一个由bucket分隔的队列。同一个桶中的每条记录都是严格排序的,流式读取会严格按照写入的顺序将记录传输到下游。使用此模式,不需要进行特殊配置,所有数据都会以队列的形式放入一个桶中。您还可以定义bucket和bucket-key以实现更大的并行性和分散数据。
sql
CREATE TABLE my_table (
product_id BIGINT,
price DOUBLE,
sales BIGINT
) WITH (
'bucket' = '8',
'bucket-key' = 'product_id'
);五、压缩
默认情况下,sink节点会自动进行compaction来控制文件数量。以下选项控制压缩策略:
| Key | Default | Type | Description |
|---|---|---|---|
| write-only | false | Boolean | 如果设置为 true,将跳过压缩和快照过期。此选项与专用紧凑作业一起使用。 |
| compaction.min.file-num | 5 | Integer | 对于文件集 f_0,...,f_N,满足 sum(size(f_i)) >= targetFileSize 触发追加表压缩的最小文件号。该值避免了几乎完整的文件被压缩,这是不划算的。 |
| compaction.max.file-num | 50 | Integer | 对于文件集 f_0,...,f_N,触发追加表压缩的最大文件数,即使 sum(size(f_i)) < targetFileSize。该值可以避免挂起太多小文件,从而降低性能。 |
| full-compaction.delta-commits | (none) | Integer | 增量提交后将不断触发完全压缩。 |
六、Streaming Source
目前仅 Flink 引擎支持流式源行为。
Streaming Read Order
对于流式读取,记录按以下顺序生成:
- 对于来自两个不同分区的任意两条记录
- 如果 scan.plan-sort-partition 设置为 true,则首先生成分区值较小的记录。
- 否则,将先产生分区创建时间较早的记录。
- 对于来自同一分区、同一桶的任意两条记录,将首先产生第一条写入的记录。
- 对于来自同一分区但两个不同桶的任意两条记录,不同的桶由不同的任务处理,它们之间没有顺序保证。
七、Watermark Definition
您可以定义读取 Paimon 表的水印:
sql
CREATE TABLE t (
`user` BIGINT,
product STRING,
order_time TIMESTAMP(3),
WATERMARK FOR order_time AS order_time - INTERVAL '5' SECOND
) WITH (...);
-- launch a bounded streaming job to read paimon_table
SELECT window_start, window_end, COUNT(`user`) FROM TABLE(
TUMBLE(TABLE t, DESCRIPTOR(order_time), INTERVAL '10' MINUTES)) GROUP BY window_start, window_end;给定的代码创建了一个名为"t"的表,它包含了三个列:"user"(BIGINT类型),"product"(STRING类型),和"order_time"(TIMESTAMP类型,精确到毫秒)。它还为"order_time"列定义了一个水印(WATERMARK),表示事件的时间戳早于水印的事件被认为是延迟事件,可以被丢弃。
在创建表之后,该代码启动了一个有界的流作业来读取"t"表中的数据。它使用TUMBLE函数将数据按照"order_time"列分组为固定大小的滚动窗口,窗口大小为10分钟。window_start和window_end表示每个窗口的起始和结束时间戳,COUNT函数用于计算每个窗口内不同用户的数量。结果按照window_start和window_end进行分组。
您还可以启用 Flink Watermark 对齐,这将确保没有源/拆分/分片/分区将其水印增加得远远超出其他部分:
| Key | Default | Type | Description |
|---|---|---|---|
| scan.watermark.alignment.group | (none) | String | 一组用于对齐水印的源。 |
| scan.watermark.alignment.max-drift | (none) | Duration | 在我们暂停从源/任务/分区进行消耗之前,对齐水印的最大漂移。 |
八、Bounded Stream
Streaming Source 也可以是有界的,您可以指定 scan.bounded.watermark 来定义有界流模式的结束条件,流读取将结束,直到遇到更大的水印快照。
快照中的水印是由writer生成的,例如,您可以指定kafka源并声明水印的定义。当使用此kafka源写入Paimon表时,Paimon表的快照将生成相应的水印,以便您在流式读取此Paimon表时可以使用有界水印的功能。
sql
CREATE TABLE kafka_table (
`user` BIGINT,
product STRING,
order_time TIMESTAMP(3),
WATERMARK FOR order_time AS order_time - INTERVAL '5' SECOND
) WITH ('connector' = 'kafka'...);
-- launch a streaming insert job
INSERT INTO paimon_table SELECT * FROM kakfa_table;
-- launch a bounded streaming job to read paimon_table
SELECT * FROM paimon_table /*+ OPTIONS('scan.bounded.watermark'='...') */;这段代码包含了几个步骤:
- 创建一个名为"kafka_table"的表,该表包含了三个列:"user"(BIGINT类型),"product"(STRING类型),和"order_time"(TIMESTAMP类型,精确到毫秒)。它还为"order_time"列定义了一个水印(WATERMARK),表示事件的时间戳早于水印的事件被认为是延迟事件,可以被丢弃。该表的连接器(connector)被指定为"kafka",意味着数据将从Kafka中读取。
- 启动一个流式插入作业。这个作业将从"kafka_table"中选择所有的数据,并插入到名为"paimon_table"的表中。
- 启动一个有界的流作业来读取"paimon_table"表中的数据。该作业将返回"paimon_table"表中的所有数据。注释中的"scan.bounded.watermark"选项可以指定有界流作业的水印,用于确定数据的处理范围。
- 总的来说,这段代码创建了一个从Kafka读取数据的表,并通过流式插入将数据插入到另一个表中。然后,通过有界流作业从目标表中读取数据。