目录
[3.1 创建矩阵乘法源码](#3.1 创建矩阵乘法源码)
[3.1.1 实验说明](#3.1.1 实验说明)
[3.1.2 实验步骤](#3.1.2 实验步骤)
[3.2 创建卷积和池化操作源码](#3.2 创建卷积和池化操作源码)
[3.2.1 实验说明](#3.2.1 实验说明)
[3.2.2 实验步骤](#3.2.2 实验步骤)
[3.3 创建Makefile文件并完成编译](#3.3 创建Makefile文件并完成编译)
[3.4 建立主机配置文件与运行监测](#3.4 建立主机配置文件与运行监测)
[4.1 矩阵乘法实验](#4.1 矩阵乘法实验)
[4.1.1 实验结果](#4.1.1 实验结果)
[4.1.2 结果分析](#4.1.2 结果分析)
[4.2 卷积实验](#4.2 卷积实验)
[4.2 1 实验结果](#4.2 1 实验结果)
[4.2.2 结果分析](#4.2.2 结果分析)
[4.3 池化实验](#4.3 池化实验)
[4.3.1 实验结果](#4.3.1 实验结果)
[4.3.2 结果分析](#4.3.2 结果分析)
[5.1 实验思考](#5.1 实验思考)
[5.2 实验总结](#5.2 实验总结)
一、实验目的
1.1 掌握简单的程序编写以及编译运行,集群 MPI 并行计算的配置以及加深对并行计算的了解。
1.2 实现在多台主机上编译运行矩阵乘法、卷积、池化的程序。
二、实验说明
华为鲲鹏云主机、openEuler 20.03 操作系统;
安装 mpich-3.3.2.tar.gz;
安装 OpenBLAS-0.3.8.tar.gz;
四台主机名称及ip地址如下:
122.9.37.146 zzh-hw-0001
122.9.43.213 zzh-hw-0002
116.63.11.160 zzh-hw-0003
116.63.9.62 zzh-hw-0004
三、实验过程
3.1 创建矩阵乘法源码
3.1.1 实验说明
随机生成大小为 1024 *1024 的矩阵作为输入,实现对应的矩阵乘法,矩阵乘法主要利用了矩阵划分方法,每一个工作节点的进程负责某一行和某一列的乘法,主节点则负责矩阵的划分以及分发到各个工作节点。
以下步骤均在 ecs-00-0001 上,以 zhangsan 用户执行。
3.1.2 实验步骤
执行以下命令,创建 matrix 目录存放该程序的所有文件, 并进入 matrix 目录(四台主机都执行)
mkdir /home/zhangsan/matrix
cd /home/zhangsan/matrix
然后输入vim gemm.cpp创建矩阵乘法源码gemm.cpp,部分代码如下
cpp
struct timeval start, stop;
if (rank == 0) {
randMat(m, n, leftMat);
randMat(n, k, rightMat);
randMat(m, k, resMat);
}
gettimeofday(&start, NULL);
mpi_sgemm(m, n, k, leftMat, rightMat, resMat, rank, worldSize, blas);
gettimeofday(&stop, NULL);
if (rank == 0) {
cout << "mpi matmul: "
<< (stop.tv_sec - start.tv_sec) * 1000.0 +
(stop.tv_usec - start.tv_usec) / 1000.0
<< " ms" << endl;
for (int i = 0; i < m; i++) {
for (int j = 0; j < k; j++)
if (int(resMat[i * k + j]) != n) {
cout << resMat[i * k + j] << "error\n";
exit(-1);
}
// cout << resMat[i * k + j] << ' ';
// cout << endl;
}
} 3.2 创建卷积和池化操作源码
3.2.1 实验说明
实现卷积计算操作,卷积核的大小为 4*4,卷积算法种类很多,在这里我们主要使用 img2col 算法来加速卷积算法,img2col 算法原理为利用数据的重排布把卷积转化为矩阵乘法。
基于乘法的程序实现池化计算操作,池化使用的 kernel 大小为 4*4,池化操作与卷积操作类似,更为简单,只需取每一个感受野内的最大值。
以下步骤均在 zzh-00-0001 上,以 zhangsan 用户执行
3.2.2 实验步骤
首先输入cd /home/zhangsan/matrix进行marix目录,然后输入vim conv.cpp创建卷积操作源码,代码输入结束后,点击esc案件退出编辑模式,输入:wq完成编辑并保存文件。
然后输入vim conv.cpp创建卷积操作源码,输入所提供的源码,代码输入结束后同上操作进行保存。部分代码如下所示:
cpp
nt m = atoi(argv[1]);
int n = atoi(argv[2]);
int img2col = atoi(argv[3]);
int xKernel = 3, yKernel = 3;
int xStep = 1, yStep = 1;
float *Img, *Conv;
struct timeval start, stop;
if (rank == 0) {
randMat(m, n, Img);
randMat(get_steps(xKernel, xStep, m), get_steps(yKernel, yStep, n),
Conv);
}控制台输入ls -l,可查看三个cpp文件是否创建保存成功。

3.3 创建Makefile文件并完成编译
首先四台主机都输入vim Makefile进人编辑模式,然后输入如下内容:
(注:需注意代码缩进)
bash
CC = mpic++
CCFLAGS = -O2 -fopenmp
LDFLAGS = -lopenblas
all: gemm conv pooling
gemm: gemm.cpp
${CC} ${CCFLAGS} gemm.cpp -o gemm ${LDFLAGS}
conv: conv.cpp
${CC} ${CCFLAGS} conv.cpp -o conv ${LDFLAGS}
pooling: pooling.cpp
${CC} ${CCFLAGS} pooling.cpp -o pooling ${LDFLAGS}
clean:
rm gemm conv pooling文件保存成功后输入"make"实现编译,正确编译后会得到如下三个可执行文件(预备实验四台主机均已经配置好OpenBLAS 环境):gemm、conv、pooling。
3.4 建立主机配置文件与运行监测
首先四台主机输入vim /home/zhangsan/matrix/hostfile进入文件编辑,输入如下内容:
zzh-hw-0001:2
zzh-hw-0002:2
zzh-hw-0003:2
zzh-hw-0004:2
然后输入vim run.sh创建并编写run.sh脚本,此处相比教程内容有所改动,具体内容如下:
bash
app=${1}
if [ ${app} = "gemm" ]; then
mpirun --hostfile hostfile -np ${2} ./gemm 4024 4024 4024 ${3}
fi
if [ ${app} = "conv" ]; then
mpirun --hostfile hostfile -np ${2} ./conv 4096 4096 ${3}
fi
if [ ${app} = "pooling" ]; then
mpirun --hostfile hostfile -np ${2} ./pooling 1024 1024
fi相较原内容改动之处在于矩阵乘法部分,我修改了参数的输入形式,将第四个参数设为命令行输入,而不是run.sh文件中设定(注:原参数默认为0,即不启用了img2col 操作),其他内容不做过多改动。
四、实验结果与分析
4.1 矩阵乘法实验
4.1.1 实验结果
首先在其中一台主机输入如下命令,执行对应程序,运行结果如下。
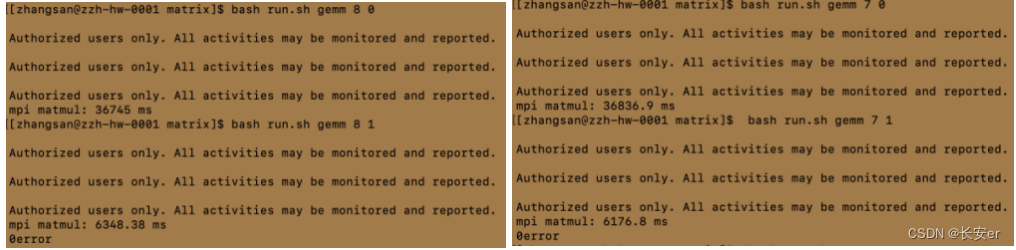
bash run.sh gemm 8 0 bash run.sh gemm 8 1
bash run.sh gemm 7 0 bash run.sh gemm 7 1
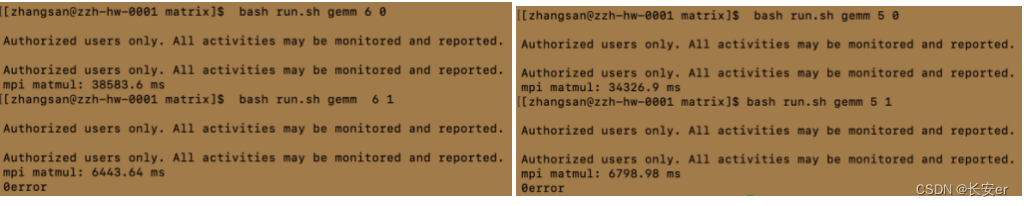
bash run.sh gemm 6 0 bash run.sh gemm 6 1
bash run.sh gemm 5 0 bash run.sh gemm 5 1
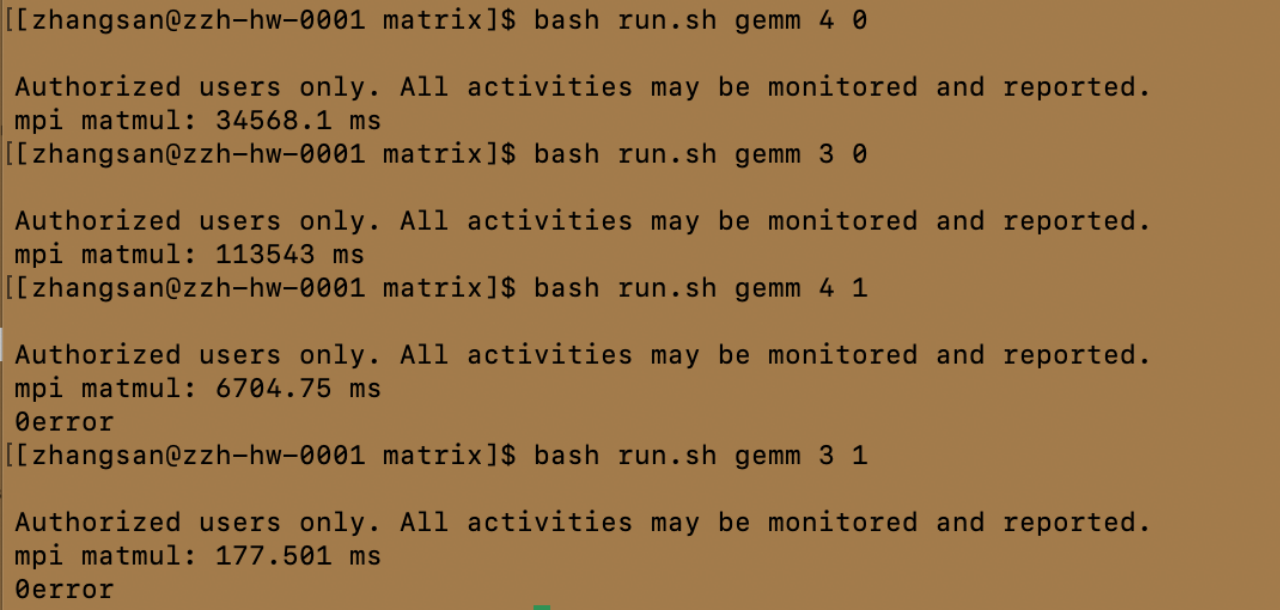
bash run.sh gemm 4 0 bash run.sh gemm 4 1
bash run.sh gemm 3 0 bash run.sh gemm 3 1
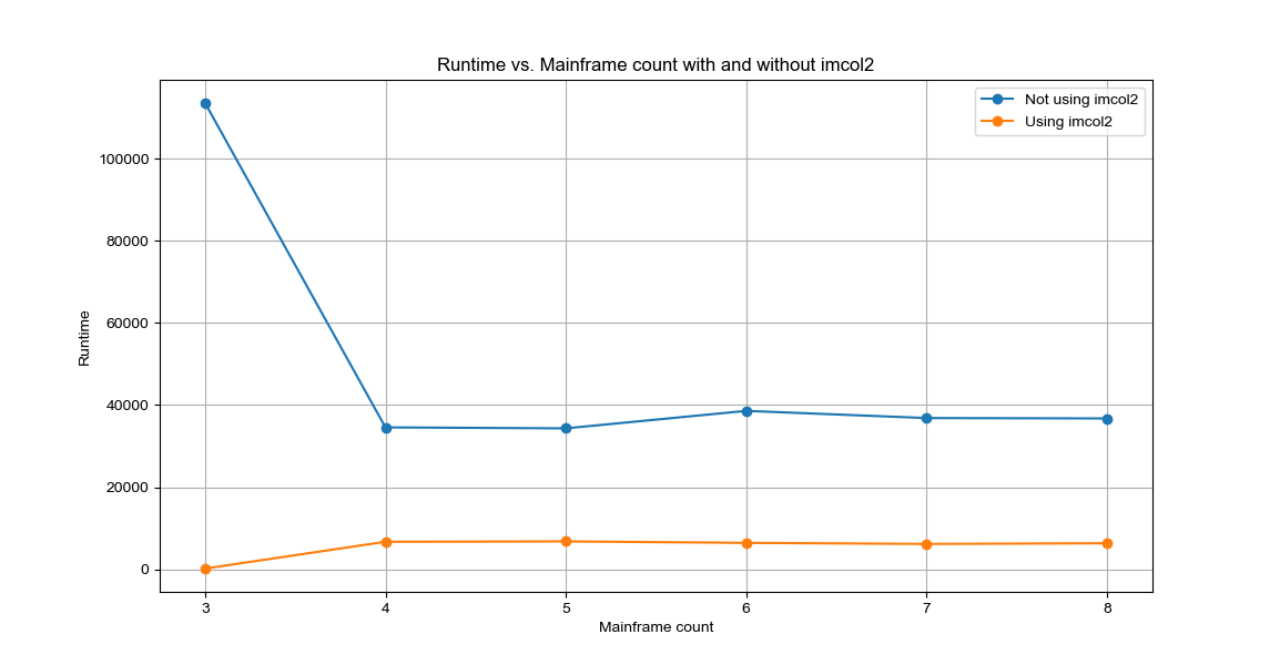
将这部分运行结果进行可视化,如下所示:
原教程run.sh文件对应的结果(处理机数量为1、2时的结果)

4.1.2 结果分析
①大致符合进程数越多,时间越短,符合并行计算的规律,但存在比较特别的现象,如进程数为5 的时候耗时34326ms(进程数为4的时候类似),而进程数为8的时候耗时却36745ms;
原因分析:
考虑负载均衡,在某些情况下,特定的数据分布和任务分配可能导致某些进程比其他进程执行更多的工作,从而导致负载不均衡。如果进程数为5时正好使得任务在各个进程之间能够更均匀地分配,那么可能会导致更好的性能表现。
考虑通信开销,通信开销可能随着进程数量的增加而增加,尤其是在进程数较多的情况下。当进程数为5时,可能刚好达到了一个性能的平衡点,使得通信开销相对较小,从而导致更短的执行时间。
②使用img2col 操作后,程序的执行速度均得到明显的提高;此情况下,更符合进程数越多,耗时越短的规律。
原因分析:img2col 操作会将输入图像转换为一个更大的矩阵,使得卷积操作可以转换为矩阵乘法,从而可以利用矩阵乘法的高效实现来加速计算。但其会增加内存消耗。
4.2 卷积实验
4.2 1 实验结果
注:受篇幅限制,仅展示处理机数量为1、4、8的结果
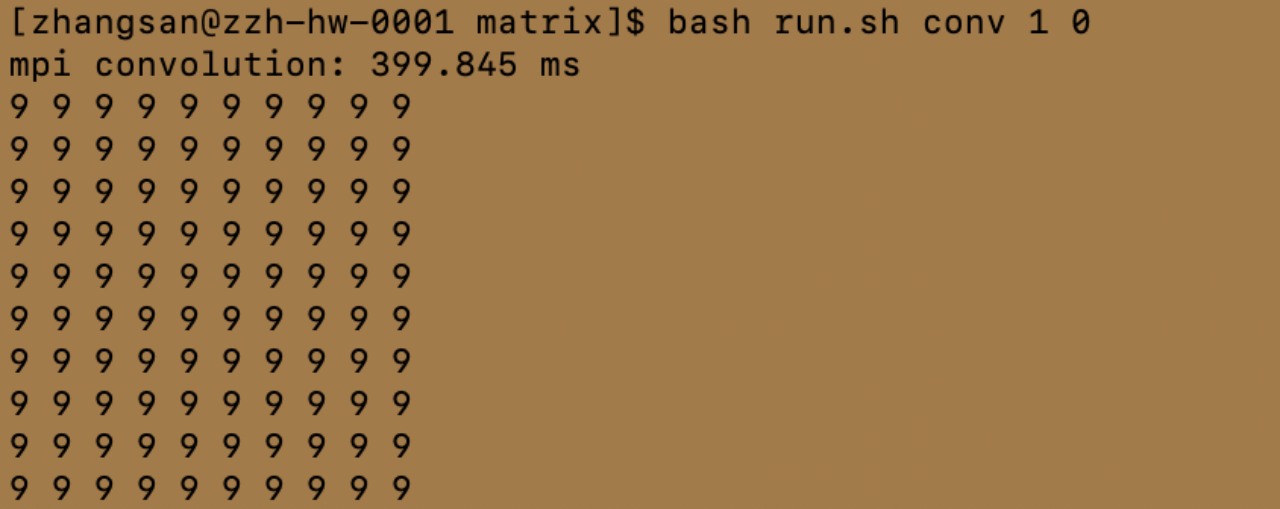
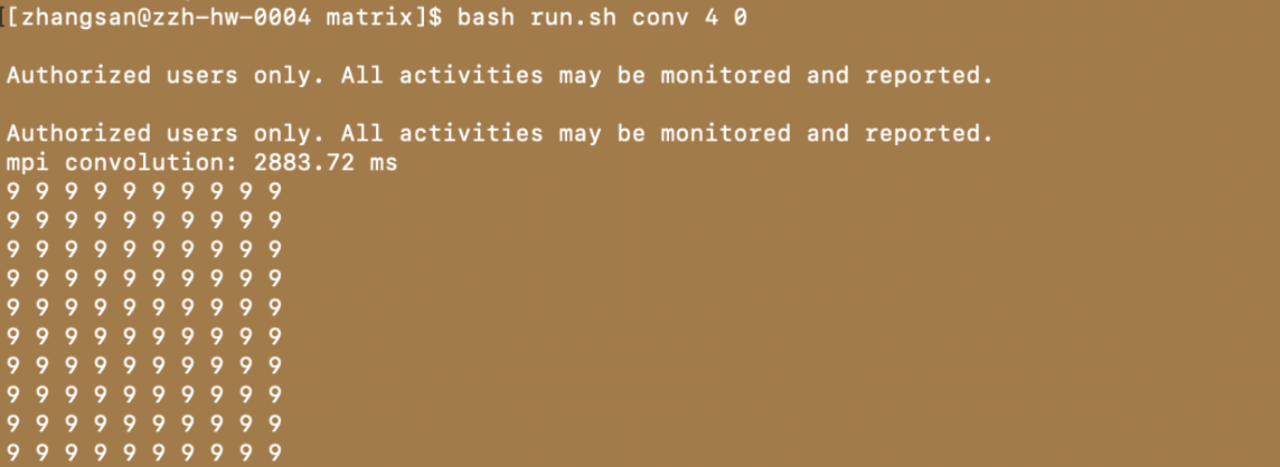
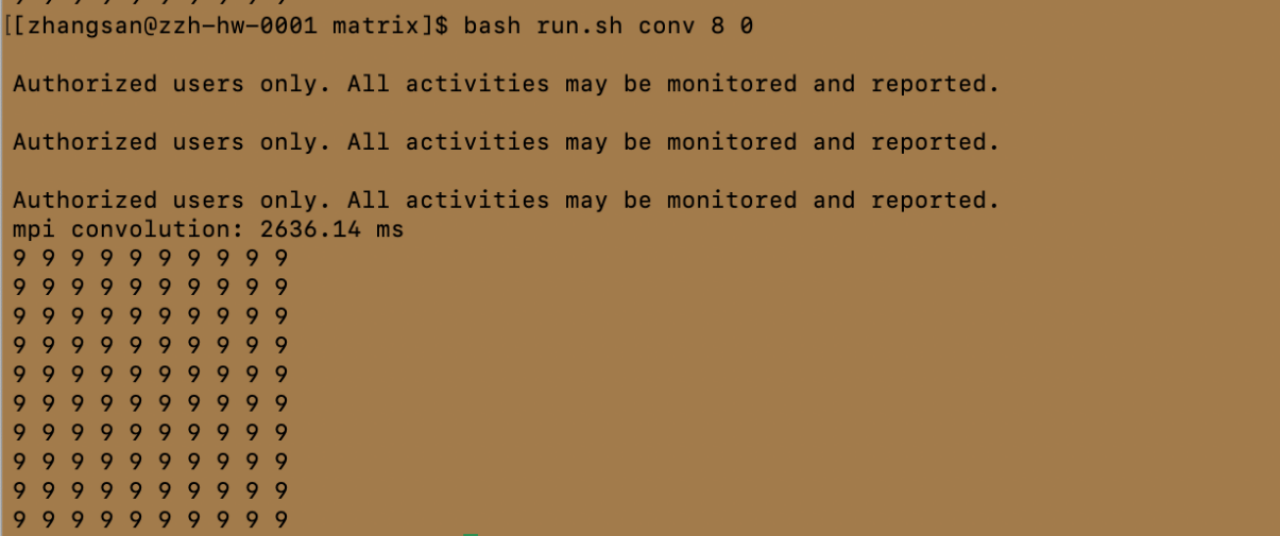
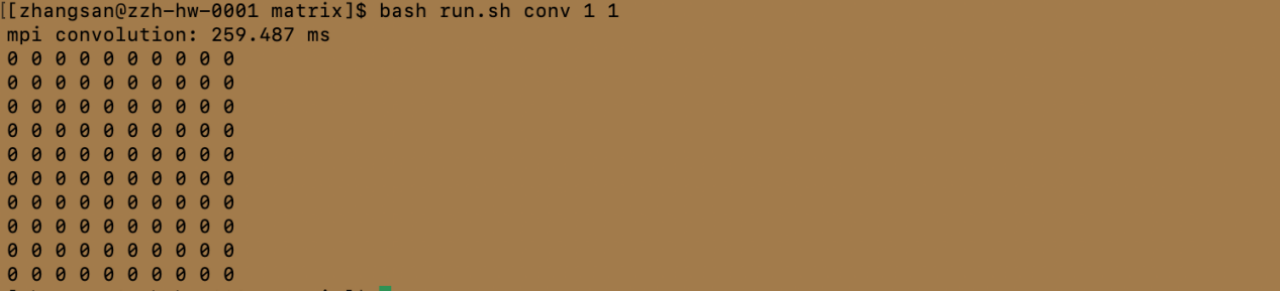
conv 后面的 1-8 数字表示启动处理的进程数量。最后面的 0 表示 vanilla convolution kernel,1 表示 img2col kernel。
4.2.2 结果分析
当进程数为1时,整个计算可能在单个处理器上运行,并且没有额外的通信开销,因此耗时很短是正常的。当进程数增加到2时,可能出现了额外的通信开销,以及在数据分割和合并过程中产生的开销,导致整体耗时增加。随着进程数继续增加,可能出现了更好的并行效果,减少了每个进程的工作量,同时也减少了通信开销,因此整体耗时下降。
4.3 池化实验
4.3.1 实验结果
将上述运行结果进行可视化
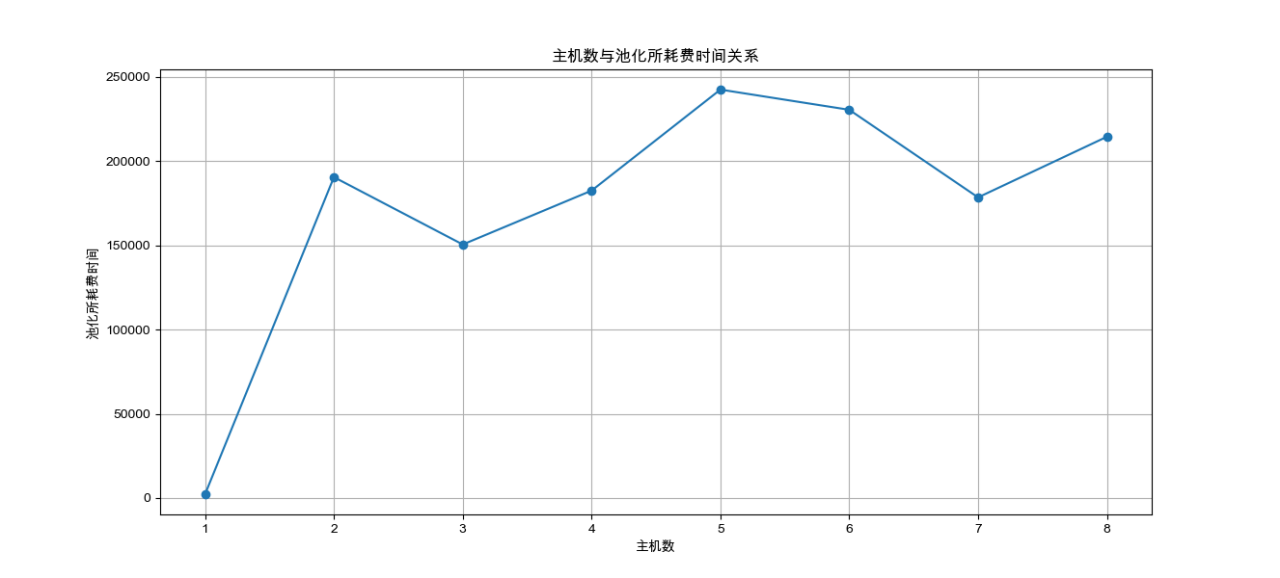
4.3.2 结果分析
①处理机为1时耗时短:这可能是因为当只有一个处理机时,没有通信开销,所有的计算都在单个处理机上完成,因此耗时最短。
②处理机为2时耗时变长:这可能是由于几个原因造成的:
通信开销:当处理机数量增加时,需要在处理机之间进行数据交换,这会引入通信开销。
负载不均衡:如果任务分配不均匀,一些处理机可能需要等待其他处理机完成工作,导致整体耗时增加。
资源争用:两个处理机可能在争用某些共享资源,如内存或I/O,这可能导致效率降低。
③随着处理机数量增加,耗时继续下降或者产生波动:这表明随着更多的处理机加入,任务可以更有效地分配,并且可能有更多的资源可供使用,从而减少了等待时间和通信开销。但是,这种下降并不是线性的,因为随着处理机数量的增加,通信开销和协调复杂性也可能增加,因此会产生一定的波动。
五、实验思考与总结
5.1 实验思考
1.如何添加 C、C+头文件以及库路径加入环境变量?
在Linux系统中,添加C或C++头文件以及库文件到环境变量通常涉及如下步骤:
①确定头文件和库文件的位置:
首先,需要确定C或C++头文件和库文件存放在哪个目录下。通常这些文件位于/usr/include、/usr/local/include或某个特定安装目录下。
②编辑环境变量:
环境变量C_INCLUDE_PATH和CPLUS_INCLUDE_PATH分别用于指定C和C++的头文件路径,而LD_LIBRARY_PATH用于指定库文件的路径。
③使用export命令:
可以通过export命令来设置环境变量。以想添加/usr/local/myapp/include到C和C++的头文件路径为例,可以使用以下命令:
export C_INCLUDE_PATH=$C_INCLUDE_PATH:/usr/local/myapp/include
export CPLUS_INCLUDE_PATH=$CPLUS_INCLUDE_PATH:/usr/local/myapp/include
④将环境变量添加到配置文件:
为了使这些更改永久生效,需要将上述export命令添加到你的shell配置文件中,如.bashrc、.profile或.zshrc。打开配置文件,添加上述命令,然后保存并重新加载配置文件:
source ~/.bashrc
通过这些步骤,可以将C或C++头文件和库文件的路径添加到环境变量中,从而确保编译器和链接器能够找到它们。
2.矩阵乘法与卷积运算、池化运算有什么关系?
①矩阵乘法与卷积运算的关系:
·卷积核(Convolutional Kernel):在卷积神经网络(CNN)中,卷积运算使用小的矩阵(通常称为卷积核或滤波器)来提取图像中的局部特征。这些卷积核本质上是权重矩阵。
·局部特征提取:卷积运算通过将卷积核与输入数据(如图像)的局部区域进行矩阵乘法来计算。这相当于在输入数据的局部区域内应用了一个线性变换。
②矩阵乘法与池化运算的关系:
·池化窗口:池化运算,如最大池化或平均池化,通常使用一个固定大小的窗口在输入数据上滑动,这个窗口可以看作是一个矩阵。
·降维:池化运算的目的是降低数据的空间维度,减少计算量,并使特征检测更加鲁棒。池化窗口在输入数据上滑动时,对窗口内的数据进行某种形式的矩阵乘法(如求和或取最大值)。
·非线性变换:与卷积运算不同,池化运算通常不涉及权重学习,而是一种确定性的非线性变换。然而,池化窗口内的操作(如求和或比较)可以看作是一种特殊的矩阵乘法。
5.2 实验总结
本实验在先前实验所建立的并行计算环境基础上进一步展开,成功实现了基础矩阵操作、卷积运算和池化运算。通过配置hostfile文件,实验成功扩展至八节点的处理机集群,旨在深入研究并行计算环境下的性能表现。
实验结果表明,随着处理机数量的增加,程序的并行化程度得到提升,从而显著降低了整体的执行时间。然而,值得注意的是,尽管并行化带来了性能上的普遍提升,但在某些特定情况下,由于通信开销的增加,其效率可能不如传统的串行计算。通过本次实验,我不仅掌握了基础的程序编写、编译及运行技能,还对集群MPI并行计算的配置有了深入的理解,并加深了对并行计算原理及其应用的认识。
END~
