文章目录
概述
- 动机
(1)不仅要在实验室中部署机器学习分类器,也要在现实世界中部署;实际应用
(2)分类器对噪声具有鲁棒性和在"大多数情况下"有效是不够的。
(3)想要鲁棒的分类器用来对付用户愚弄分类器的输入;面对人类的恶意
(4)特别适用于垃圾邮件分类、恶意软件检测、网络入侵检测等。 - 攻击 AI
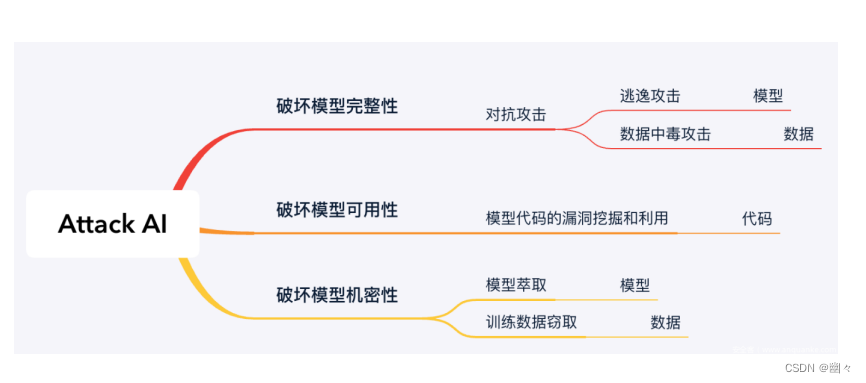
上图描述了一些攻击 AI 的方式以及后果。
(1)对抗攻击会导致破坏模型完整性;
(2)漏洞挖掘和利用会导致破坏模型可用性;
(3)模型萃取和数据窃取会导致破坏模型机密性。 - 逃逸攻击
指攻击者在不改变目标机器学习系统的情况下,通过构造特定输入样本以完成欺骗目标系统的攻击 - 投毒攻击
攻击者通过篡改训练数据或添加恶意数据来影响模型训练过程,最终降低其在预测阶段的准确性。
攻击
对抗性攻击的目的
对抗性攻击的目的是通过在原始图像中添加人眼无法察觉的扰动,使得模型的预测结果出错。
攻击的损失函数
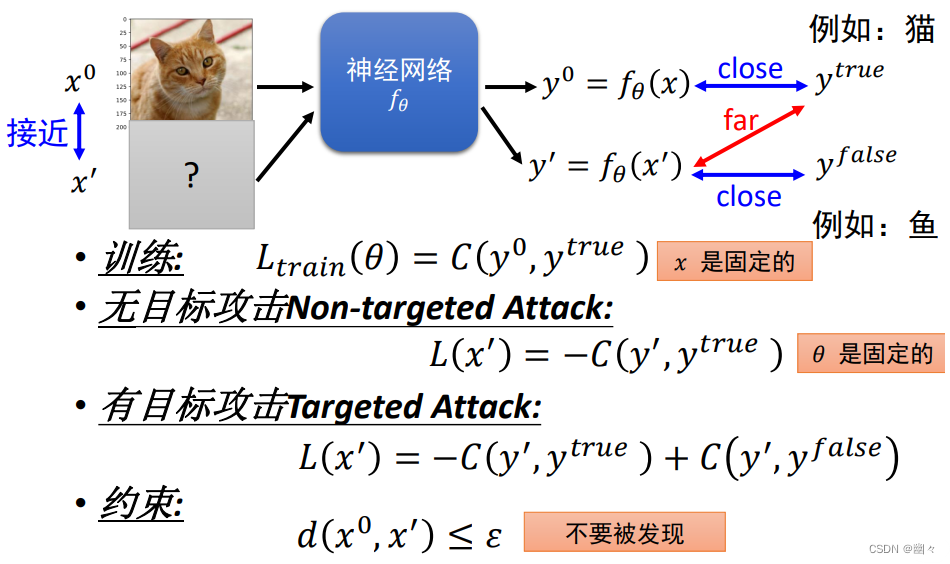
- 训练损失: L t r a i n ( θ ) = C ( y 0 , y t r u e ) L_{train}(\theta)=C(y^0,y^{true}) Ltrain(θ)=C(y0,ytrue)。这个公式表示训练神经网络的损失函数,其中 y 0 y^0 y0 是神经网络对原始输入 x 0 x^0 x0 的输出, y t r u e y^{true} ytrue 是该输入的真实标签
例如,猫。 C C C 衡量 y 0 y^0 y0 和 y t r u e y^{true} ytrue 之间的差异。 - 无目标攻击损失: L ( x ′ ) = − C ( y ′ , y t r u e ) L(x')=-C(y',y^{true}) L(x′)=−C(y′,ytrue)。在这种情况下, y ′ y' y′ 是对 x ′ x' x′ 的输出。无目标攻击的目的是使 y ′ y' y′ 偏离 y t r u e y^{true} ytrue,即使预测与真实标签差异增大。因此我们取负的 C C C,最大化估计差异。
- 有目标攻击损失: L ( x ′ ) = − C ( y ′ , y t r u e ) + C ( y ′ , y f a l s e ) L(x')=-C(y',y^{true})+C(y',y^{false}) L(x′)=−C(y′,ytrue)+C(y′,yfalse)。有目标攻击的目的是使 y ′ y' y′ 更接近一个错误的估计 y f a l s e y^{false} yfalse,不同与无目标,有目标攻击多了"目的地"
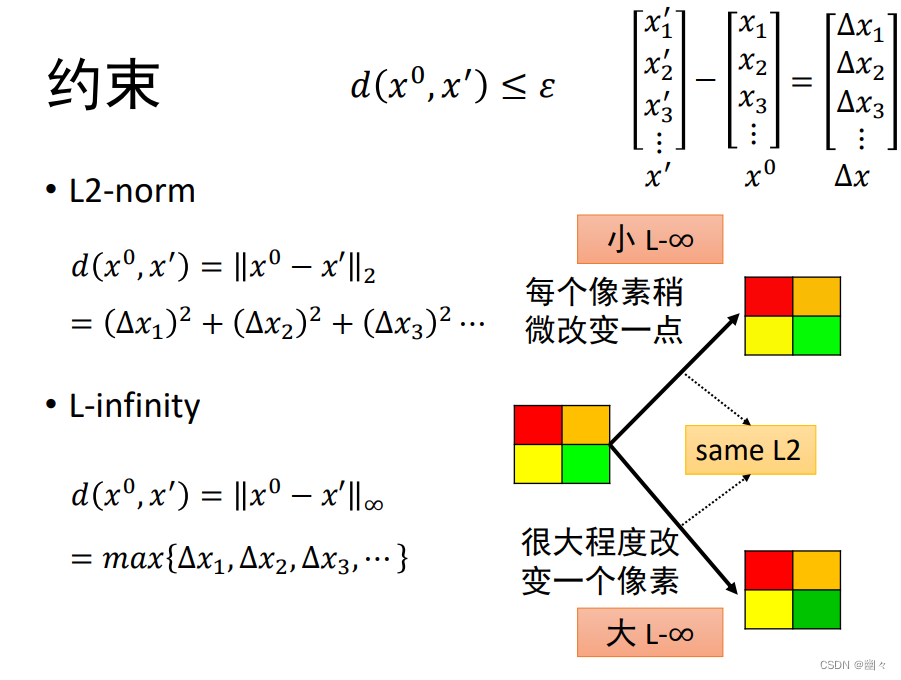
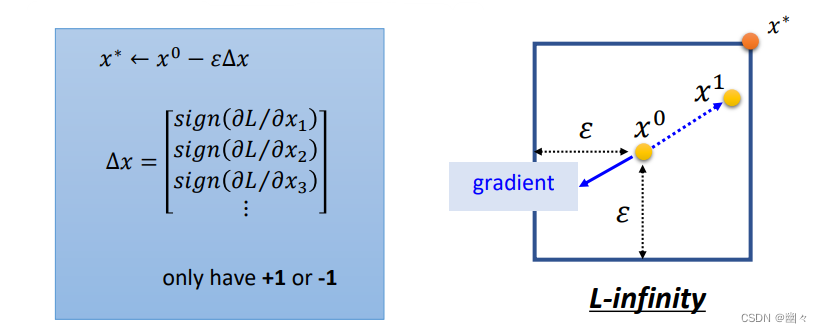
例如,把猫的图片分类为鱼。第一项 − C ( y ′ , y t r u e ) -C(y',y^{true}) −C(y′,ytrue) 希望输出值远离真实标签、第二项 C ( y ′ , y f a l s e ) C(y',y^{false}) C(y′,yfalse) 希望输出接近错误标签。 - 约束: d ( x 0 , x ′ ) ≤ ϵ d(x^0, x') \le \epsilon d(x0,x′)≤ϵ。具体如下图,右上角展示了 x ′ x' x′ 和 x 0 x^0 x0 之间的距离 Δ x \Delta x Δx。图中下方展示了两种衡量距离的方法。 L 2 − L2- L2− 范数和 L − ∞ L-\infty L−∞ 范数。
如何攻击
就像训练一个神经网络,但是网络参数 θ \theta θ 被 x ′ x' x′替代。

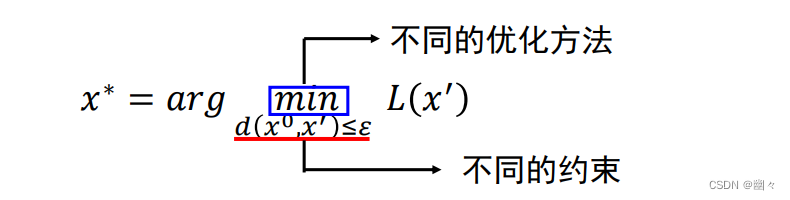
- x ∗ = a r g min d ( x 0 , x ′ ) ≤ ϵ L ( x ′ ) x^*=arg \min_{d(x^0, x') \le \epsilon} L(x') x∗=argmind(x0,x′)≤ϵL(x′),这个公式指:在约束条件下 d ( x 0 , x ′ ) ≤ ϵ d(x^0, x') \le \epsilon d(x0,x′)≤ϵ
原始输入与扰动图像之间的距离不超过ϵ下,找到使 L ( x ′ ) L(x') L(x′) 最小的 x ′ x' x′。 - 由此可以看出,在对抗性攻击种,我们的目标是:希望生成一个扰动图像,在这个扰动图像接近原始图像且满足约束条件的前提下,最小化损失。
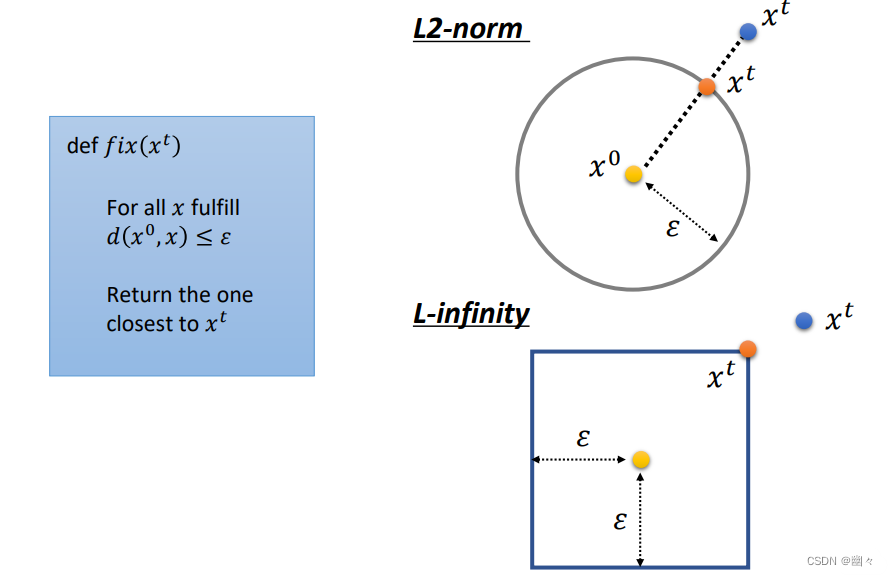
最小化损失L(x')在上面的有目标攻击和无目标攻击中,都体现为C更大,即更加偏离真实标签,攻击的效果越好。 - 下方展示了 f i x ( x t ) fix(x^t) fix(xt)中距离的计算方法。
FGSM
FGSM 全称 Fast Gradient Sign Method,快速梯度逐步算法。
黑盒与白盒
-
在前面的攻击中,我们固定网络参数 θ \theta θ 而寻找最优的输入 x ′ x' x′。如果攻击时,我们需要知道 θ \theta θ,那么这就叫做白盒攻击。
-
白盒攻击需要 θ \theta θ,那么如果我们不公布(绝大多数 API 都不提供网络参数),是否安全呢?
不会,因为存在黑盒攻击。
-
在黑盒攻击中:
(1)如果我们有目标网络的训练数据,可以使用这些数据训练一个代理网络 (proxy network)。这个代理网络模仿目标网络的行为,攻击者可以在代理网络上进行对抗样本生成,然后将这些对抗样本应用于目标网络。
用目标的网络数据生成网络,在网络上模拟,然后在模拟网络上生成AE(对抗性样例)。(2)如果我们没有目标网络的训练数据,则需要获取一些目标网络的输入和预测输出,以此来构建代理网络,然后进行和训练数据生成代理网络后一样的攻击。
和(1)的区别就是,是用目标网络的输入和预测输出生成的代理网络。
真实世界的攻击
单像素攻击
防御
对抗性攻击无法通过正则化,dropout 和模型集成来防御。
防御可以分为两种:主动防御和被动防御。
被动防御
在不修改模型的情况下找到攻击图像。
- 去噪
除非对手不知道去噪的存在,否则还是可能受到白盒攻击。 - 随机化
(1)如果攻击者不知道随机化存在,则效果最佳;
(2)如果知道,由于随机模式过多,防御依然有效。 - 梯度掩码/隐藏
治标不治本,本质是提高了攻击者搞清楚弱点的难度,模型本身稳定性并未提高。
主动防御
训练一个对对抗性攻击具有鲁棒性的模型。
- 对抗训练
这种方法对训练目标算法 A 有效,但对未被训练的目标算法 B 无效。 - 防御性蒸馏
(1)通过梯度生成的对抗性样例攻击性降低;
(2)随蒸馏温度提升,对抗性样例生成困难,提升模型鲁棒性;
(3)对黑盒攻击无能为力;
(4)仅适用于基于概率分布的 DNN 模型。