纵览
Python处理Excel的方式--解压缩方式
在处理Excel中过程中,总是会遇到往已经存在的模板中填写特殊信息,一开始我使用的是常见的 openpyxl包,但是在我修改页眉中的字符时,发生页眉中的logo丢失现象,然后我就百度、ChatGPT搜索,最终找到了一种方法,那就是解压缩xlsx文件,然后修改内容,再进行压缩的方式实现修改内容的功能,利用的zipfile包,当然这个包应该是自带的吧,我使用的是Anaconda。
1、导包
其中部分包没有用到
python
import zipfile
import os
import shutil
from openpyxl import load_workbook
import pandas as pd2、对模板文件进行解压缩
python
# 模板Excel文件路径
excel_path = r'D:\MyPython\程序\模版.xlsx'
# 解压缩 Excel 文件
with zipfile.ZipFile(excel_path, 'r') as zip_ref:
zip_ref.extractall('excel_temp')3、对解压缩后文件层级进行介绍
运行上述代码,会在当前目录下,生成一个文件夹excel_temp,目录结构如下:
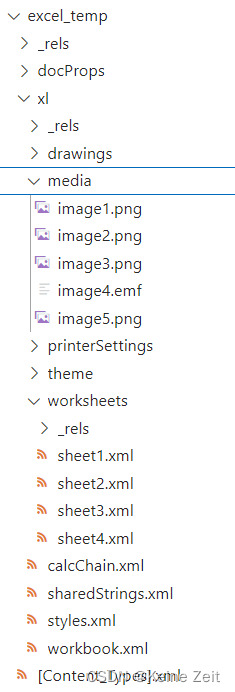
其中,主要关注的是xl文件夹里面的文件,文件内容意思如下:
| 路径 | 文件名 | 功能 |
|---|---|---|
| excel_temp/xl/ | sharedStrings.xml | Excel中的所有单元格内容,除页脚、页眉外,所有的信息都在这里 |
| excel_temp/xl/ | workbook.xml | sheetname修改位置 |
| excel_temp/xl/worksheets/ | styles.xml | 修改单元格的样式 |
| excel_temp/xl/worksheets/ | sheet?.xml | 页眉页脚修改区域修改位置,每个sheet对应1个文件 |
| excel_temp/xl/drawings/_rels/ | drawing1.xml.rels | 页眉页脚修改区域修改位置,每个sheet对应1个文件图片路径的,如果模板中已经存在图片的,如果想要换个图标,可以通过覆盖下面的图片就行 |
| excel_temp/xl/media/ | image?.png | 将新的文件覆盖掉对应的png文件就行,可以利用shutil.copy(替换图片路径,要被替换的路径) |
4、准备需要载入的数据
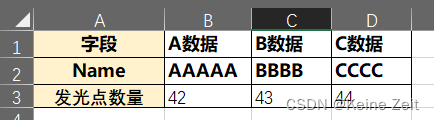
替换模板数据,最重要的是先将你要替换的数据整理好,然后再在模板中相应的位置挖空,填充就行,我的数据格式是excel,如下:A列是替换名称,B到D列是数据,然后运行代码会生成填入B、C、D对应的数据的三个文件;
5、模板挖坑
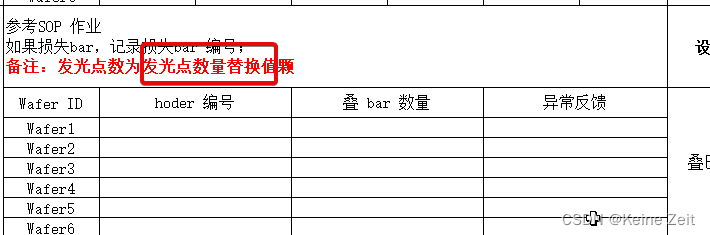
打开模板文件,将需要替换的位置成相应的字符,比如:现在我想要替换发光点数量,输入发光点数量替换值,这个可以根据自己实际情况更换;
6、运行替换代码
excel_path是模板路径,soure_file数据文件;
python
data_df = pd.read_excel(soure_file,sheet_name=0) #,usecols=[0,1]
# 将某一列(例如'index_column')设为索引
data_df.set_index('字段', inplace=True)
# 将DataFrame转换为字典
data_dict = data_df.to_dict()
# 删除值为NaN的键值对
data1_dict = {col: {index: value for index, value in data_dict[col].items() if pd.notna(value)} for col in data_dict}
# 修改页眉 文件
for keya in data1_dict.keys():
# 解压缩 Excel 文件
with zipfile.ZipFile(excel_path, 'r') as zip_ref:
zip_ref.extractall('excel_temp')
# 修改相关 XML 文件
content_path = 'excel_temp/xl/sharedStrings.xml'
workbook_path = 'excel_temp/xl/workbook.xml'
for fm in os.listdir('excel_temp/xl/worksheets'):
if '.xml' in fm:
with open(f'excel_temp/xl/worksheets/{fm}', 'r+') as f:
header_footer_xml = f.read()
for key,value in data1_dict[keya].items():
header_footer_xml = header_footer_xml.replace(key+'替换值', str(value))
f.seek(0)
f.write(header_footer_xml)
f.truncate()
# 修改内容 文件
with open(content_path, 'r+') as f:
header_footer_xml = f.read()
for key,value in data1_dict[keya].items():
header_footer_xml = header_footer_xml.replace(key+'替换值', str(value))
f.seek(0)
f.write(header_footer_xml)
f.truncate()
# 修改类似:sheetname 这样的字符
# 修改Sheetname文件
with open(workbook_path, 'r+') as f:
header_footer_xml = f.read()
header_footer_xml = header_footer_xml.replace("SHEETNAME", data1_dict[keya]['SheetName'].replace('/',''))
f.seek(0)
f.write(header_footer_xml)
f.truncate()7、压缩文件
将修改后的文件,重新压缩,并且删除临时文件夹excel_temp
python
# 重新压缩 Excel 文件
with zipfile.ZipFile(data1_dict[keya]['Name'].replace('/','')+'.xlsx', 'w') as zip_ref:
for folder_name, subfolders, filenames in os.walk('excel_temp'):
for filename in filenames:
file_path = os.path.join(folder_name, filename)
arcname = os.path.relpath(file_path, 'excel_temp')
zip_ref.write(file_path, arcname)
# 删除临时文件夹
shutil.rmtree('excel_temp')8、生成文件
运行完成后,会在当前目录下生成对应的文件,如果你想要放在其他路径可以修改data1_dict[keya]['Name'].replace('/','')+'.xlsx'这个位置的代码,利用os.path.join()进行路径拼接即可。
9、完成代码
文件存在关键信息,我就不展示了,代码如下:
python
import zipfile
import os
import shutil
from openpyxl import load_workbook
import pandas as pd
# 修改页眉 文件
def get_file(excel_path, soure_file):
data_df = pd.read_excel(soure_file,sheet_name=0) #,usecols=[0,1]
# 将某一列(例如'index_column')设为索引
data_df.set_index('序列', inplace=True)
# 将DataFrame转换为字典
data_dict = data_df.to_dict()
# 删除值为NaN的键值对
data1_dict = {col: {index: value for index, value in data_dict[col].items() if pd.notna(value)} for col in data_dict}
for keya in data1_dict.keys():
# 解压缩 Excel 文件
with zipfile.ZipFile(excel_path, 'r') as zip_ref:
zip_ref.extractall('excel_temp')
# 修改相关 XML 文件
content_path = 'excel_temp/xl/sharedStrings.xml'
workbook_path = 'excel_temp/xl/workbook.xml'
for fm in os.listdir('excel_temp/xl/worksheets'):
if '.xml' in fm:
with open(f'excel_temp/xl/worksheets/{fm}', 'r+') as f:
header_footer_xml = f.read()
for key,value in data1_dict[keya].items():
header_footer_xml = header_footer_xml.replace(key+'替换值', str(value))
f.seek(0)
f.write(header_footer_xml)
f.truncate()
# 修改内容 文件
with open(content_path, 'r+') as f:
header_footer_xml = f.read()
for key,value in data1_dict[keya].items():
header_footer_xml = header_footer_xml.replace(key+'替换值', str(value))
f.seek(0)
f.write(header_footer_xml)
f.truncate()
# 修改类似:这样的字符
# 修改Sheetname文件
with open(workbook_path, 'r+') as f:
header_footer_xml = f.read()
header_footer_xml = header_footer_xml.replace("SHEETNAME", data1_dict[keya]['SheetName'].replace('/',''))
f.seek(0)
f.write(header_footer_xml)
f.truncate()
# 重新压缩 Excel 文件
with zipfile.ZipFile(data1_dict[keya]['产品类别'].replace('/','')+'.xlsx', 'w') as zip_ref:
for folder_name, subfolders, filenames in os.walk('excel_temp'):
for filename in filenames:
file_path = os.path.join(folder_name, filename)
arcname = os.path.relpath(file_path, 'excel_temp')
zip_ref.write(file_path, arcname)
# 删除临时文件夹
shutil.rmtree('excel_temp')
excel_path = r'D:\MyPython\程序\Nan_Czy\流程单自动生成\模版.xlsx'
soure_file = r'D:\MyPython\程序\Nan_Czy\流程单自动生成\关键信息清单.xlsx'
get_file(excel_path, soure_file)10、可能遇到的问题
- 读取文件存在问题,需要在对应位置加上:
encoding='utf-8'; - 打开文件失败,肯定是替换的字符存在问题,需要一一排查;
结语
好的,本次遇到的问题已经解决并且记录下来了,希望能够帮助你!