今天要学习的有关Reid的论文是2019年提出的一篇名为:Beyond Scalar Neuron: Adopting Vector-Neuron Capsules for Long-Term Person Re-Identification.
论文链接:https://opus.lib.uts.edu.au/bitstream/10453/137156/4/Binder1.pdf
Code链接:https://github.com/Huang-3/Celeb-reID
大多数Reid的研究都聚集在人员几乎不会更换衣服的场景,也就是说针对人员来说,数据分布相似度是比较大的。但在一些场景中人员是有可能换衣服的,这里举个例子,比如在追寻一个嫌疑人,该嫌疑人在A场景穿的红色衣服,当他进入B场景后换了一件黑衣服,那么用传统的方法可能就不太行了。
因此这篇文章主要解决的问题 就是如何针对这种换装场景下也能实现行人重识别。
文章将传统的研究任务(同一个人不同角度但不会更换衣服)称为short-term ReID。将自己的研究称为long-term ReID。
文章的贡献有两点:
1.制作了"换装"数据集(Celeb-reid)用于行人重识别;
2.提出了vector-neuron(VN)capsules来代替传统的传统的标量神经元(SN);
注:文章指出,VN与SN相比只是多一个维度用来提取同一个人不同衣服的特征提取
为什么提出Celeb-reid数据集
文章指出,数据集收集方式往往有两种:
一种是收集非合作人的数据,另一种是收集受限环境内合作人的数据集。
显然第一种方法是好的(因为便利啊,随机收集),不过说打标签的时候需要标签人员根据一些特征(比如人脸)来判断是否为一个人,但如果人脸等信息看不清,就需要根据经验来标注是否为同一个ID(其实就是作者解释为什么想在网上找图片,这就是写作的艺术么?),而像Markt1501、CUHK03、VIPeR等就无法满足long-term,因为人员没有显著的变化(比如服饰)。
第二种收集方法说可以模拟一些极端情况,包括一些衣服的改变,但这种太有限了,比如ID就不会那么的多(其实这里也是说明为什么网上找图片的必要性)
因此!!Celeb-ReID数据集诞生了 ,然后还解释了一下为什么用名人的图像,这里我就不再多说(以后大家要是也是网上找图像制作自己的数据集可以学学人家这说法,说的有理有据)。该数据集有1052个ID,34186张图像,其中70%以上的图像都是具有不同的衣服。
Celeb-reid数据集说明
Celeb-reid数据集有1052个ID,34186张图像。图像的高宽比为2:1,图像大小为256x128.
Celeb-reid数据集说明如下:
|---------|----------|-------|---------|--------|
| split | training | query | gallery | total |
| #ID | 632 | 420 | 420 | 1,052 |
| #Images | 20,208 | 2,972 | 11,006 | 34,186 |
[数据集划分说明]
对应网盘链接:
百度网盘 请输入提取码 code:ix2j
图像示例如下:

当然文章也提供了一个轻量的数据集Celeb-reid-light:
| split | training | query | gallery | total |
|---|---|---|---|---|
| #ID | 490 | 100 | 100 | 590 |
| Images | 9021 | 887 | 934 | 10,842 |
网盘链接:
百度网盘 请输入提取码 code:14k5
为什么提出ReIDcaps
但人员的衣服等外观发生了改变,如果采用传统的Reid识别方法,可靠性会大大降低。这是为什么呢?因为当衣服改变,那么CNN提取的特征**(比如纹理特征和颜色特征)会很大的改变**,然后再计算特征距离的时候就会差距比较大,导致算法鲁棒性差。
而现如今大多数ReID网络都是针对衣服(外观)特征不会改变的场景下,这些方法在short-term中的性能是比较好的,但却不适合long-term。
也有一些研究试图去做一些不同类别之间的衣物变化,但是,并没有关注感知和区分同类中衣物大变化的能力。所以这些研究在Long-term是存在问题的。
而解决以上所说的传统的方法就是SN(标量神经元),为了可以适应于long-term,作者建议使用Vector-Neuron (VN) capsules结构的网络 1。SN和VN的区别可以看文末。在常见的卷积神经网络(CNNs)中,每个标量的值反映了神经元属于某个现有人员ID的可能性(比如在分类网络中用全连接+softmax来看是哪个人的ID)。但如果外观(衣服)发生了改变,那么这种方式就不太行了,作者受到了VN这篇文章的启发,用输出的第一个维度表示目标是否存在,第二个维度是目标的属性 。而对应到ReID任务中,第一个维度就是表示分类ID,第二个维度就是同一个ID的不同衣服。下图是论文中展示的SNs和VNs的不同:
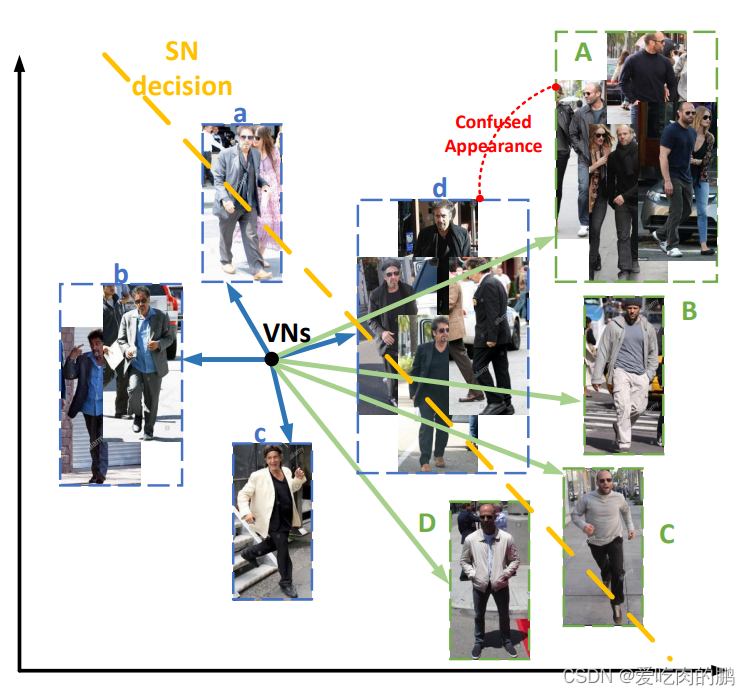
图中是两个人(两个ID),VN可以很好将两个人进行区别(即便是衣服不同),蓝色箭头为同个ID,绿色箭头为同一个ID,而SN会将不同的人相似服饰的ID搞混,比如d和A是两个ID,但由于都穿的相似的衣服,那么会识别错误。因此给这个网络取了一个名字叫"ReIDCaps"。
ReIDcaps网络结构
文章所提出的ReIDcaps主要有三个模块:
1. 特征提取模块:先用已经训练过的模型在图像上提取一些浅层特征,这些特征将会送入caps进行ID分类和其他特征的提取。
2. ID和穿着感知模块:使用caps层去进行分类和穿着属性 。ID分类主要通过VN输出向量的长度,每个人的着装信息是通过每个VN的方向来感知的。通过调整网络参数,使得相同ID的VN长度相近,不同ID的VN长度差异较大,从而实现ID的分类。VN的方向(Orientation)可以代表相同ID下不同衣物的类型。这意味着,即使两个人的ID相同,他们穿着的衣服可能不同,这时VN的长度可能相近但方向不同。网络通过学习这些方向信息,来区分相同ID下不同的衣物属性。
**3.**辅助模块,比如SEA和FSR。
完整的ReIDCaps网络结构如下:
结构说明:将图像送入CNN中(这里是DenseNet为例)进行特征提取,然后将得到特征图分成三部分进一步的处理,分支1是得到ID和dressing感知的,分支2和3对应的辅助模块SEA和FSR模块。(就是为了提高准确率,相当于作者把改进也放进去了,涨点用)。
网络结构代码在项目中的reid/models/dense1stream_capsule.py

(可以看到,DenseNet的输出为7x7x1024,只看第一个分支,采用2x2,步长为2的卷积核进行卷积 ,输出卷积为256,分成8组,这样每组就是32个通道,然后再进行reshape,而最后的输出上面可以看到是24,这里的24是将前面的P-Caps进行了一个维度映射,采用的方法为R-by-A (这里R-by-A的iter数取4),而行数为ID数量,也是分类数量。那么就是24xN,如果我们对每行的特征向量求模的大小那么就可以得到每个ID的概率,而这每个特征向量中的特征中也包含了衣服等一些特征属性)
网络定义代码如下:
python
class DenseNet(nn.Module):
def __init__(self, depth=121, num_feature=1024, num_classes=632, num_iteration=3, pretrained=False):
super(DenseNet, self).__init__()
self.depth = depth
self.base = models.densenet121(pretrained=pretrained)
self.seblock = SELayer(channel=num_feature, reduction=16) # SE注意力机制
self.classifer1 = Classifier(num_feature=num_feature, dropout=0.25, num_classes=num_classes) # 分类1
self.classifer2 = Classifier(num_feature=num_feature, dropout=0, num_classes=num_classes) # 分类2
# 主分支
self.primary_capsules = CapsuleLayer(num_capsules=8, num_route_nodes=-1, in_channels=num_feature, out_channels=32,
kernel_size=2, stride=2, num_iterations = num_iteration)
self.digit_capsules = CapsuleLayer(num_capsules=num_classes, num_route_nodes=32 * 3 * 3, in_channels=8,
out_channels=24, num_iterations = num_iteration)
def forward(self, x, output_feature=None):
x = self.base.features(x) # densenet121特征提取 x shape [bs,1024,7,7]
# 辅助模块2
y = F.avg_pool2d(x, x.size()[2:]) # shape [bs,1024,1,1]
y = y.view(y.size(0), -1) # shape [bs,1024]
if output_feature == 'pool5': # 检测的时候用,训练不用
y = F.normalize(y)
return y
y = self.classifer1(y) # shape [bs, 632] 训练期间ID 632个
# 辅助模块1
y2 = self.seblock(x) # senet shape [bs,1024,7,7]
y2 = F.avg_pool2d(y2, y2.size()[2:]) # shape [bs,1024,1,1]
y2 = y2.view(y2.size(0), -1) # shape [bs,1024]
y2 = self.classifer2(y2) # shape [bs, 632]
# 主分支
z = self.primary_capsules(x) # shape [1,288,8]
z = self.digit_capsules(z).squeeze().transpose(0, 1) # shape [24,632]
classes = (z ** 2).sum(dim=-1) ** 0.5 # 计算模长 shape(24)
classes = F.softmax(classes, dim=-1)
return classes, y, y2 # 主分支,y是FSR分支,y2是SeNet分支因为有三个分支,所以也有三个loss。这个就是ID loss(三个ID loss)。公式中的是一个平衡参数,通过实验验证,取0.5效果比较好。

其中的损失函数采用的是Margin Loss(另外两个损失函数均采用的交叉熵),公式如下:
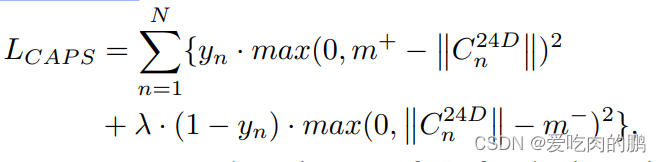
其中,表示的是输入图像
(x是第几个图,n是第几个ID)是否存在,取0或者1(这里感觉有些像YOLO的obj loss),这里的意义应该是可以加快收敛速度,
是0.5,
和
是控制
的长度。如果ID表示的是
,那么希望
的长度越长(也就是表示预测为当前ID的概率越大),这里的
,
.对应的代码如下:
python
class CapsuleLoss(nn.Module):
def __init__(self):
super(CapsuleLoss, self).__init__()
def forward(self, images, labels, results):
left = F.relu(0.9987 - results, inplace=True) ** 2
right = F.relu(results - 0.0013, inplace=True) ** 2
margin_loss = labels * left + 0.5 * (1. - labels) * right
margin_loss = margin_loss.sum()
return margin_loss / images.size(0)forward部分,images是传入的图像,labebls是一个one-hot形式的label,results是模型预测的输出。
ID & Dressing Perception模块
作者提出使用VN中的Capsule来学习衣物的改变,上面提到了经过CNN特征提取后,需要进行ID分类,而VN中有两个维度,一个是ID的分类,另一个维度是衣服属性(两个caps,一个叫P-Caps,一个叫C-Caps)。其实该部分就是结构图上的第一个分支。
P-Caps和C-Caps分别指什么?
- P-Caps(Primary Capsules) :主要胶囊层。这一层负责从输入的特征中提取和表示基础的特征信息,这些信息是后续分类和识别的基础。在论文中,P-Caps层可能用于提取与ID和衣物属性相关的初步特征。(我这里的理解就是P-Caps只是起个名字而已,其实就是特征层)
- C-Caps(Classification Capsules):分类胶囊层。这一层在P-Caps层的基础上,进一步对特征进行分类和识别。在ID和衣物属性的识别中,C-Caps层负责根据P-Caps层提取的特征,给出最终的分类结果。(我这里的理解就是特征向量,shape为24xN,每行的模值表示该ID的概率)
网络的训练
作者指出,网络的训练采用pytorch,没有改变网络设计,但分别为短期和长期重识别(re-ID)场景使用了两种不同的训练策略。作者认为,对于长期重识别,新模型需要产生更多的可学习参数来适应关于衣物变化的额外信息。因此,当它被应用于没有衣物变化的相对简单的短期重识别案例时,可能会导致一定的过拟合问题。
对于长期重识别场景,我们在ImageNet预训练的DenseNet-121中设置初始学习率为1e-4,在DenseNet输出之后的新层中设置初始学习率为1e-3,将这种训练策略称为TS1 。为了缓解过拟合问题,对于短期重识别场景,我们在通用SN网络上预训练了主干网络(DenseNet-121)。在ReIDCaps中采用了在SN上训练的DenseNet-121主干网络。在SN训练的DenseNet-121中,初始学习率设置为1e-5,在新层中设置为1e-4。将这种训练策略命名为TS2。(总结为对于VN和SN网络设置了不同的学习参数,分别将两个实验命名为TS1和TS2)。
对于以上两种场景(TS1和TS2),所有输入图像在训练前都被调整为224×224的大小 ,并随机翻转 。训练过程中使用了Adam 随机优化算法,其参数设置为β1 = 0.9,β2 = 0.999。学习率在训练40个周期后降低10倍 ,并在第50个周期后停止训练(就是训练了50个epoch)。对于Celeb-reID、Celeb-reID-light、Market1501和DukeMTMC-reID这四个数据集,训练ID的数量(N)分别为632、490、751和702。
在测试中,会将平均池化后的1024D的特征向量用于计算query和gallery中两个图像的欧式距离来判断两个人的相似性。使用mAP、Rank进行评估。
测试
作者对于他所提出的ReidCaps网络的测试分了两部分,一个是对于行人全身的测试,另一个是将人体分块进行测试(这也是文章最终所得到的评价指标 ),将身体分别分为三部分和两部分。对身体分块效果如下:

第一张 是全身图,第二张是分成三部分,第三张图是分成两部分。这么做的原因是更细粒度的进行比较。
对于粗粒度而言(没有获取获取身体部位信息),评价指标如下:
|-----------------|----------|-----------|-----------|
| | Celeb-reID |||
| | mAP | rank-1 | rank-5 |
| ReIDCaps (Ours) | 9.8% | 51.2% | 65.4% |
对于细粒度(获取身体部位信息)
|-----------------|-----------|-----------|-----------|
| | Celeb-reID |||
| | mAP | rank-1 | rank-5 |
| ReIDCaps (Ours) | 15.8% | 63.0% | 76.3% |
参考资料
1 Sara Sabour, Nicholas Frosst, and Geoffrey E Hinton. Dynamic routing between capsules. In Proc. Adv. Neural Inf. Process. Syst. (NIPS), pages 3856--3866, 2017.
论文总结
介绍了一种在长期情况下进行人物再识别(re-ID)的新方法,特别是在个体更换衣物的情况下。论文的主要贡献和关键点总结如下:
1.Celeb-reID 数据集的引入
- 作者引入了一个新的大规模数据集,名为 "Celeb-reID",专门用于长期 re-ID 任务。该数据集包含 1,052 个 ID 和 34,186 张图片,是目前最大的针对衣物变化问题的数据集。
- Celeb-reID 数据集中的图片来自于网络上的名人街拍,确保了环境的多样性和高衣物变化度。
2.向量神经元胶囊(VN 胶囊)
- 论文提出采用 VN 胶囊取代传统的标量神经元(SN)用于 re-ID 任务。
- VN 胶囊提供了一个额外的维度,可以编码衣物变化,增强了模型在外观变化情况下识别个体的能力。
- VN 胶囊中的向量长度表示实体(人物)存在的可能性,而向量的方向编码了诸如衣物之类的属性。
3.ReIDCaps 网络:
- 论文引入了一种名为 "ReIDCaps" 的新网络架构,结合了 VN 胶囊。
- 网络还集成了软嵌入注意力(SEA)和特征稀疏表示(FSR)机制以提升性能。
- ReIDCaps 在有衣物变化的场景中相较于现有的最先进方法显示了显著的改进
个人认为,该文章最大的贡献就是贡献了数据集,作者开源的项目代码有些问题,经过个人修改可以正常运行代码,需要的可以私聊(有偿) 。
SN和VN的区别
1.输出形式不同
**·**SN(Scalar Neuron)的输出是一个标量,也就是输出的为"置信度"或者说是"概率"。
**·**VN的输出是一个向量形式,包括实体的位置、角度、纹理等信息。向量的模长可以表示为概率。
2.关注的焦点不同
**·**SN只关注目标是否存在,也就是答案为"是"或"否"
**·**VN不仅仅关注目标是否存在,还会有其他的属性
3.辅助模块:辅助模块用于进一步提高从我们的ReIDCaps模块中学习到的特征的区分性。
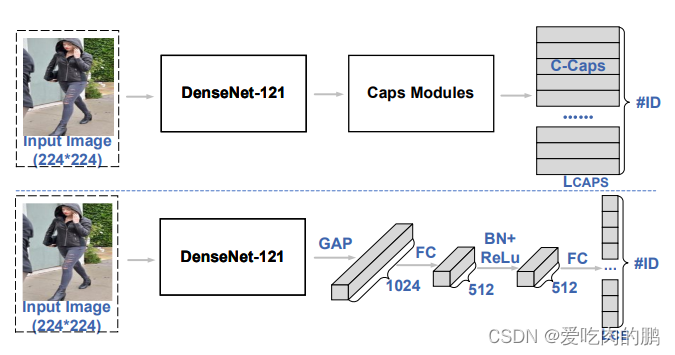
VN网络和SN网络基本结构如下图,上面一行是VN,下面一行是SN,SN网络和VNbackbone是一样的,均采用了DenseNet,只是DenseNet的输出后的处理是有区别的, 对于VN而言,需要经过caps模块,得到的输出shape应该是24xN(N表示为多少个ID),用这种方式代替了全连接层,用向量长度(模值)表示可能为哪个ID。
对于SN而言,DenseNet的输出先经过平均池话后再经过FC层、BN、ReLu等最后用FC进行输出。