一、先上结果(注:本文仅为兴趣爱好探究,请勿进行商业利用或非法研究,负责后果自负,与作者无关)
1、爬标题及其具体内容
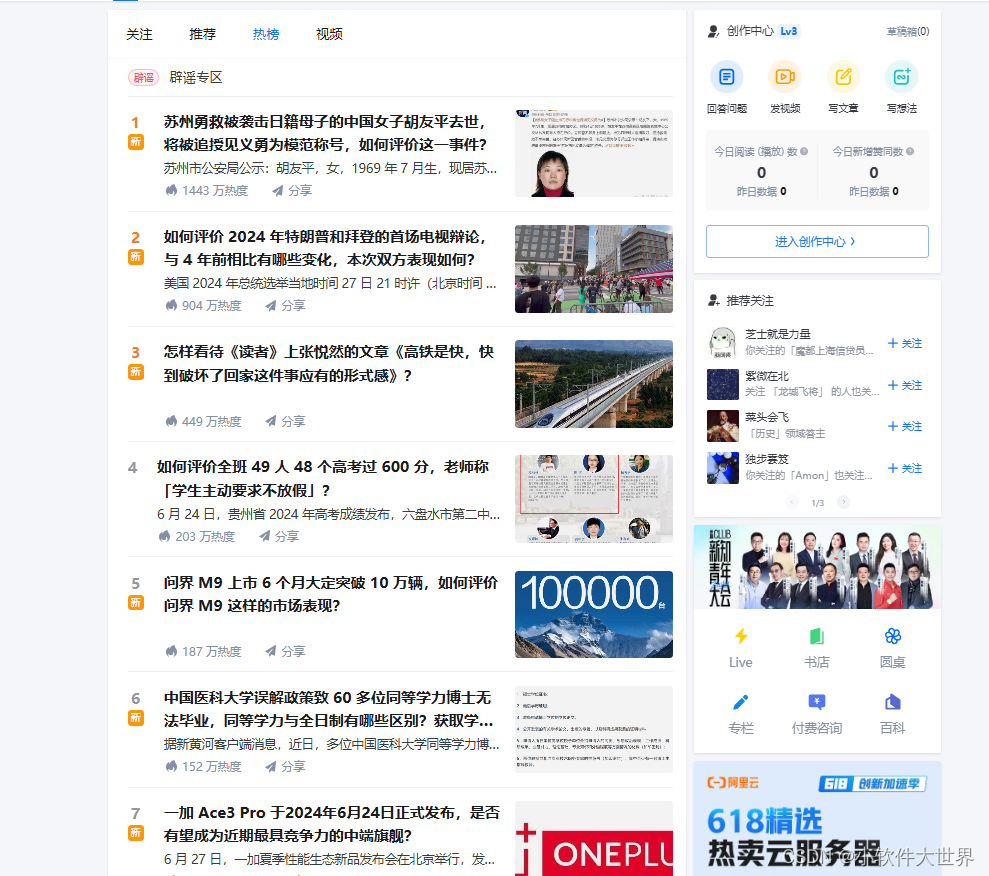

2、抓标题下的对应回答
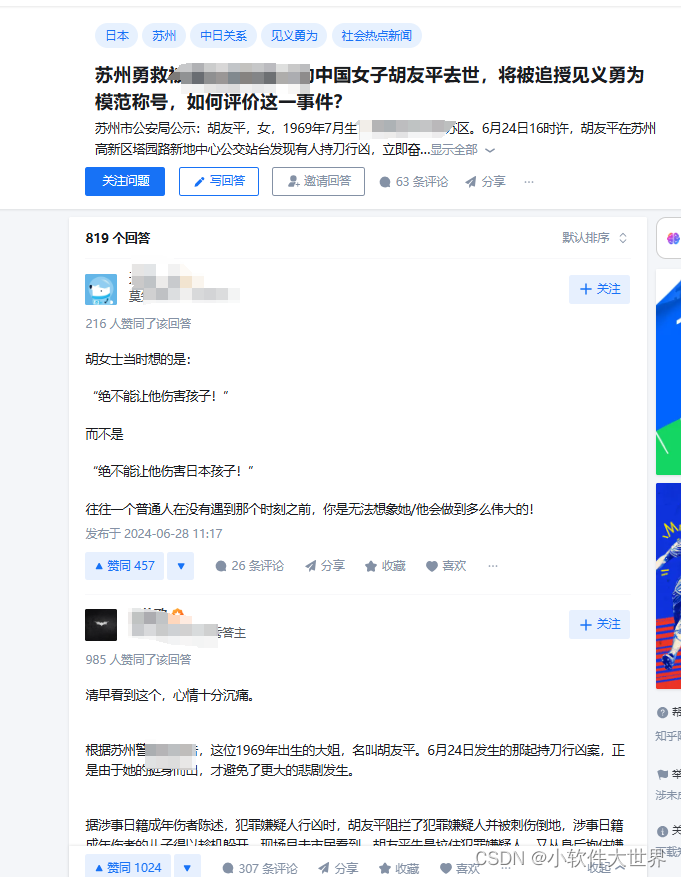
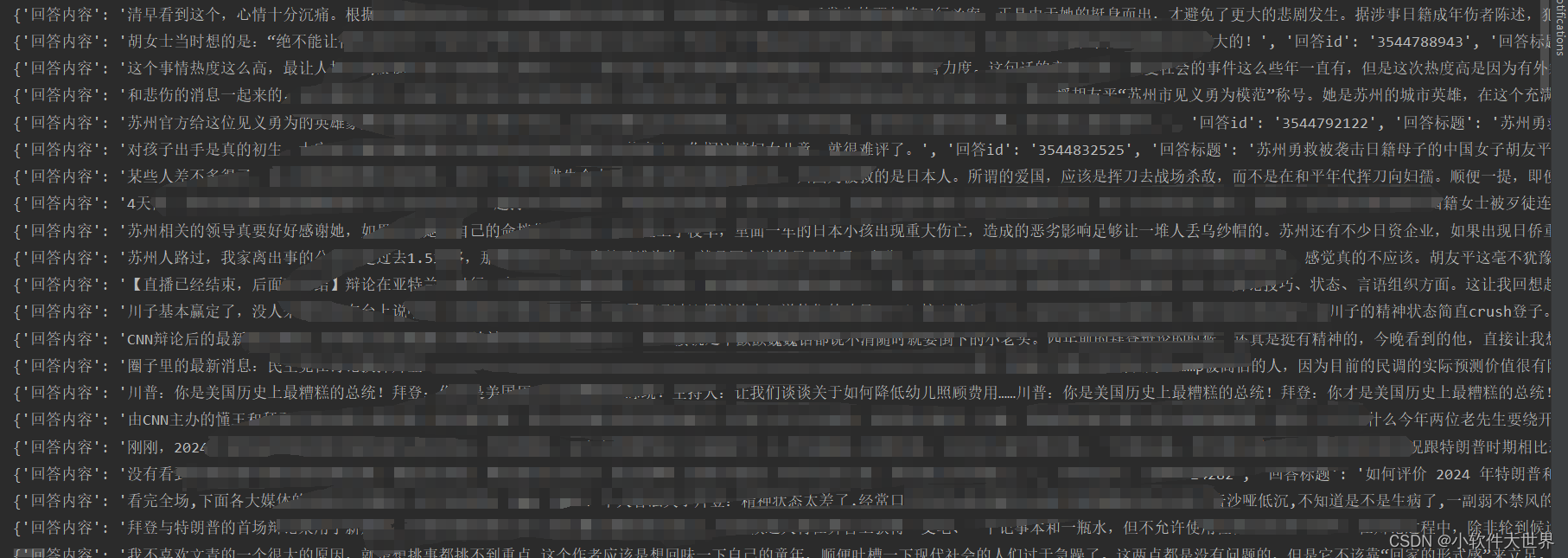
3、爬取对应一级评论


二、上流程
1、获取cookies(相信哥哥姐姐们都会得啦,F12抓一下便知)
2、获取标题的定位(大差不差用了基本的etree,根据路径找到对应的标签位置,因为有些具体的细节涉及商业,打了马赛哈)
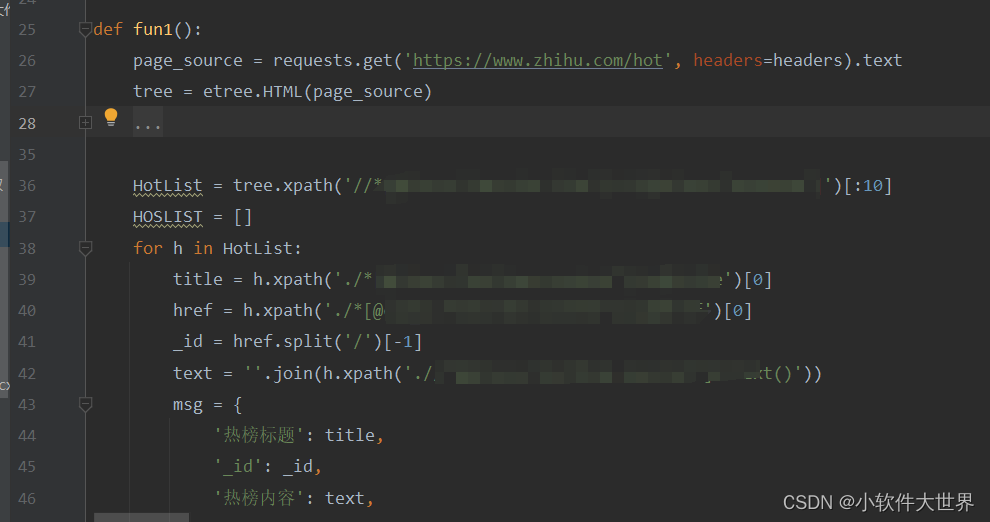
3、获取回答内容

4、获取评论内容
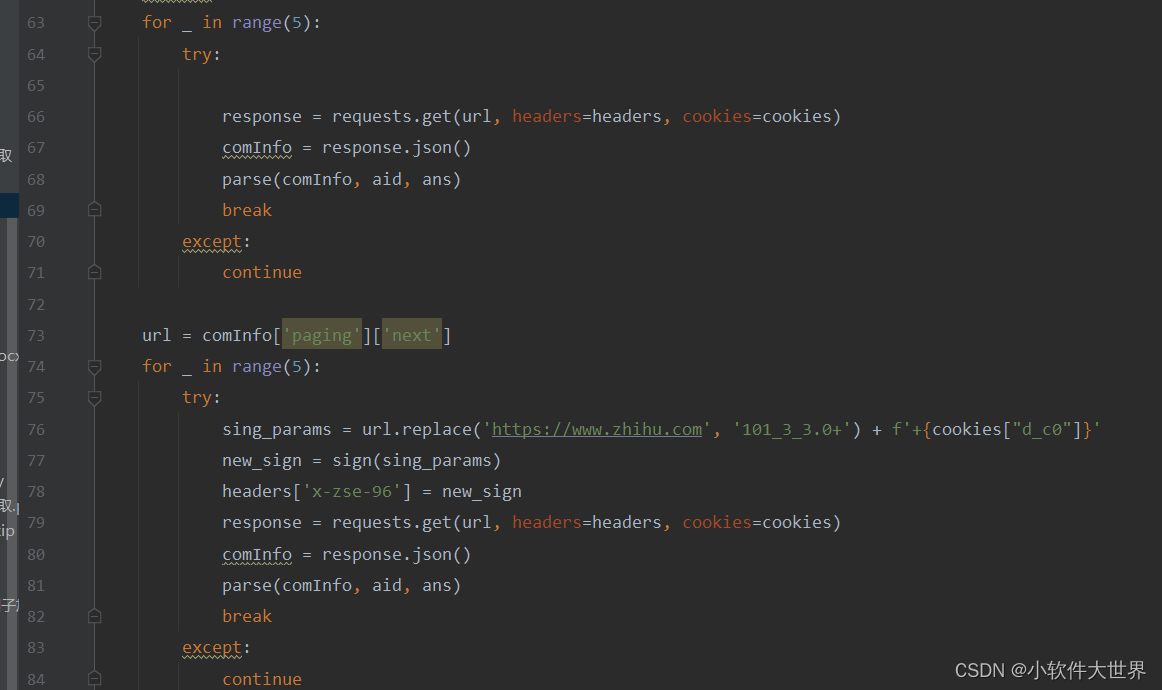
5、最后获得结果
【做了一些补环境和逆向,具体的哥哥姐姐们可以详细研究下,文章只是简单写了一些,能完成基本的想要的任务,想要源码的哥哥姐姐们,可以私信或者评论区小留言哈,微偿哦,看到会给对应答复,谢谢大家支持,以后还会陆续更新新的内容】