引言:
在人工智能领域,谷歌一直是创新的先行者。最近,谷歌DeepMind团队在I/O Connect大会上发布了Gemma 2,这是其开源模型系列的最新力作,标志着AI技术的又一大步。
Gemma 2的前身,Gemma,已经因其轻量级和高性能获得了广泛的认可。随着技术的进步和需求的增长,Gemma 2应运而生,旨在提供更强大的性能和更广泛的应用场景。

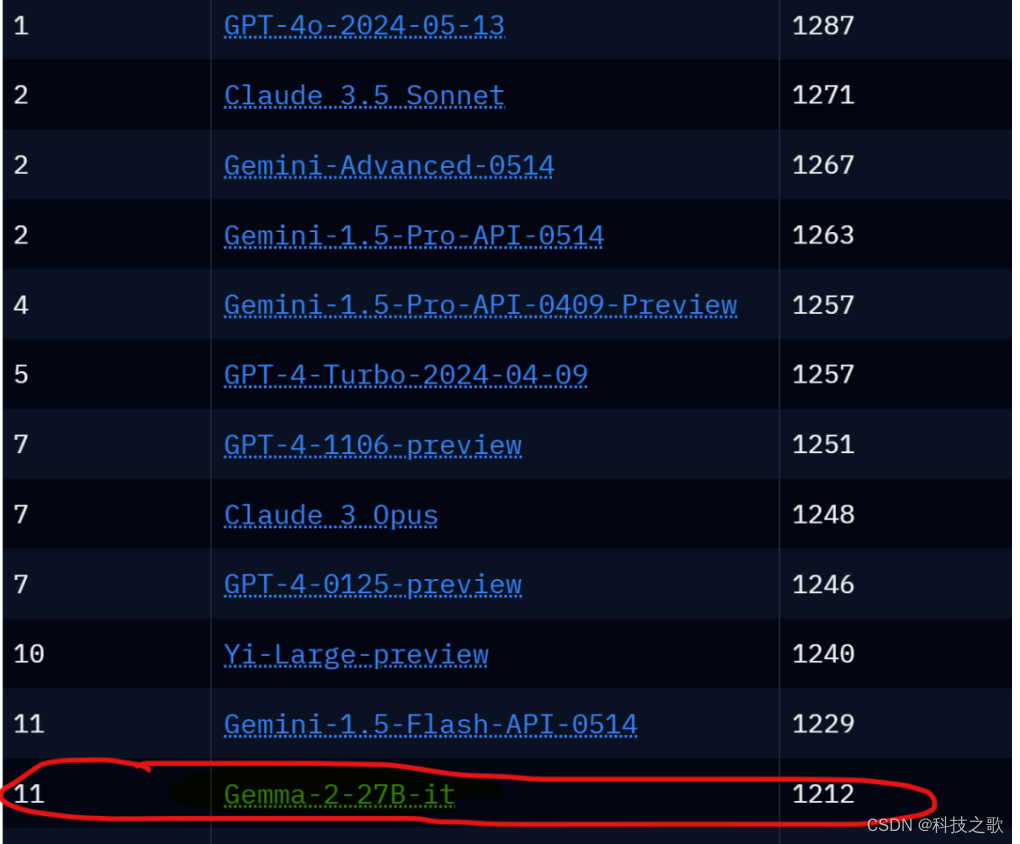
Gemma-2-27B-it在最新的Chatbot Arena排行榜上排名12,超越了Llama-3-70B-Instruct,成为目前最受欢迎的开源大模型。
Gemma 2概览:
Gemma 2以其90亿(9B)和270亿(27B)参数规模,成为业界关注的焦点。这一新一代模型不仅在性能上实现了飞跃,更在推理效率和安全性上做出了显著改进。特别值得一提的是,27B模型在训练了13T tokens后,展现出了与参数量为其两倍的模型相媲美的性能,同时在单个英伟达A100/H100 Tensor Core GPU或TPU主机上以全精度高效运行推理,大幅降低了部署成本。
主要特点如下:
- 参数量:分别为9B和27.2B,可以在消费级硬件上完美运行!
- 上下文窗口:与Llama-3一样,都是8K。
- 训练数据集: 27B模型采用了13T tokens的文本数据,9B模型采用了8T Tokens训练,涵盖了网页文本、代码和数学文本等。
- 知识库:Gemma-2的知识库截止到2024年6月,而Llama-3-70b-Instruct知识库为2023年12月。
- 许可证:采用Gemma许可,可以商用,但是需要满足一定条件,相比Apache2.0要严格一些。
性能与效率:
Gemma 2在性能上的卓越表现得益于其重新设计的架构,该架构采用了局部-全局注意力机制和分组查询注意力等先进技术,这些技术的应用显著提升了模型的效率和性能。此外,Gemma 2还采用了知识蒸馏技术,这是一种通过训练较小模型来模仿大型模型行为的方法,从而在保持较小模型尺寸的同时,实现了接近大型模型的性能。
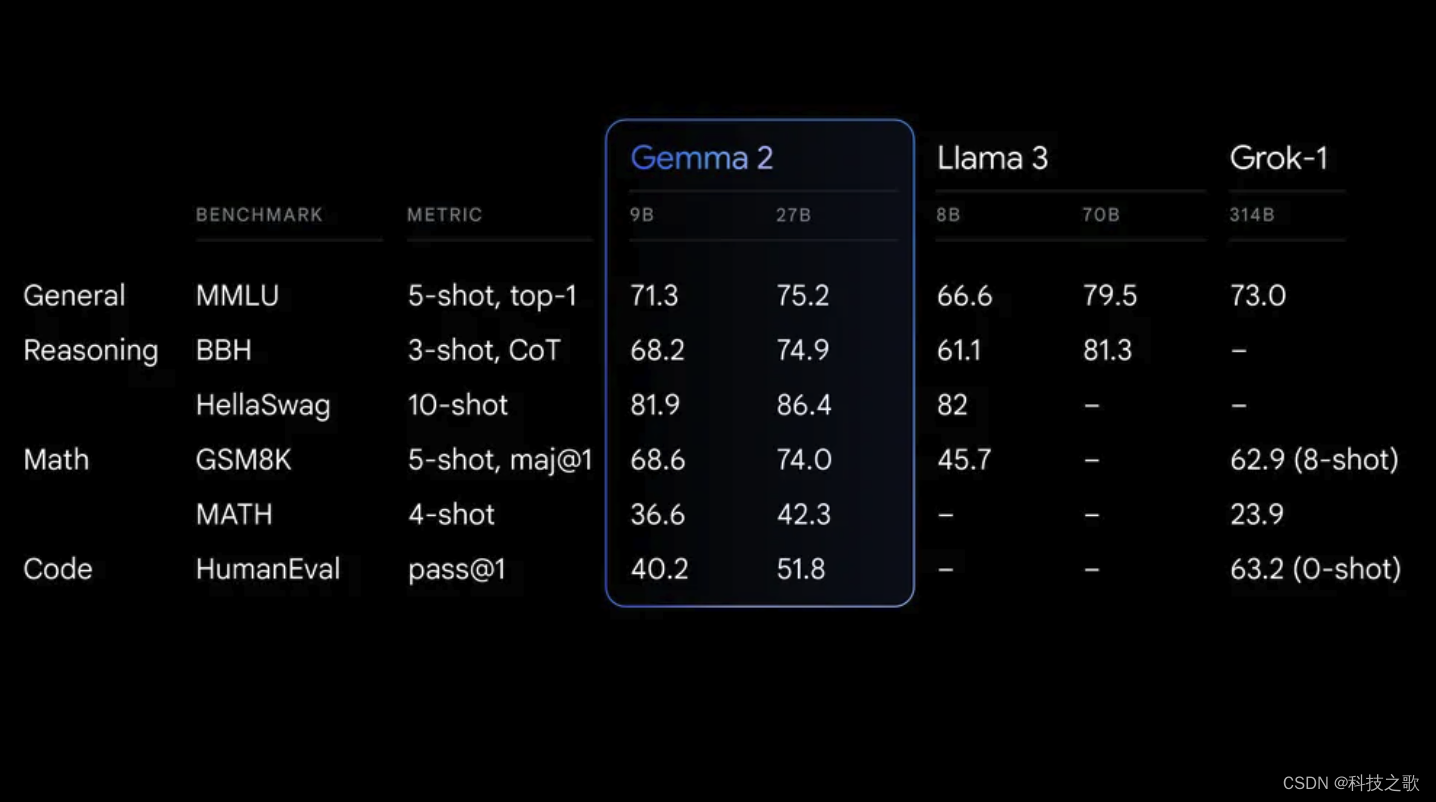
在Hugging Face的基准测试中,Gemma 2 27B的尺寸仅为Llama 3 70B的40%,训练数据量也少于Llama 3 70B的2/3,但性能却优于Qwen1.5 32B,与Llama 3 70B相比也仅有几个百分点的差距。

安全性与兼容性:
在AI模型的开发中,安全性始终是一个不可忽视的因素。谷歌对Gemma 2的安全性给予了高度重视,在训练过程中遵循了严格的内部安全流程,对数据进行了筛选,并针对一系列综合指标进行了测试和评估,以识别和减轻潜在的偏见和风险。此外,Gemma 2的商业友好许可和广泛的框架兼容性,使其能够轻松集成到各种AI工具和工作流程中。
部署与资源:
Gemma 2的设计考虑了开发者和研究人员的需求,提供了开放且易于访问的资源。从下个月开始,谷歌云客户将能够在Vertex AI上轻松部署和管理Gemma 2。同时,谷歌还提供了Gemma Cookbook,一系列实用示例和指南,帮助用户构建自己的应用程序并为特定任务微调Gemma 2模型。
Gemma 2的另一个显著特点是其广泛的框架兼容性。它与Hugging Face Transformers、JAX、PyTorch和TensorFlow等主要AI框架兼容,这使得开发者和研究人员能够根据自己的偏好和需求,选择合适的工具和工作流程来使用Gemma 2。此外,Gemma 2还经过了NVIDIA TensorRT-LLM的优化,可以在NVIDIA的加速基础设施上运行,进一步简化了部署过程。
你可以在 Hugging Chat 上与 Gemma 27B 指令模型聊天!查看此链接:
https://hf.co/chat/models/google/gemma-2-27b-it
模型测试:
1、脑筋急转弯测试

2、推理能力测试

3、中文写作能力测试

4、 中文知识测试

能够看出来在这四个方面,Gemma 2取得的表现都更加优秀,值得尝试!
结语:
Gemma 2的发布不仅是谷歌在AI领域的又一次技术突破,更是对开源社区的巨大贡献。通过提供高性能、高效率且安全的模型,谷歌正在推动AI技术的普及和应用,让更多人能够利用这些强大的工具来解决现实世界的问题。无论是在提高效率、降低成本,还是在推动技术创新和应用普及方面,Gemma 2都具有巨大的潜力。