本篇为KMP技术的技术及实践系列文章的第二篇。在这篇技术文章中我们会以百人移动研发团队的工程化视角,探讨Kotlin Multiplatform的核心技术及优化。
Kotlin: 语言与编译
人们在用自然语言沟通时,内容可以不明确,甚至小的错误,而听的人仍然可能理解说的人想要说的内容。但电脑不同,电脑"只做被告知要做的事",无法理解程式设计者想要写的程式。语言的定义、编程以及编程输入的组合需完整定义程式执行时的外部特性。 而程序语言正是人类和计算机的桥梁, 顺着这个逻辑,我们把我们日常的编程工作和一些核心概念结合起来。
-
人控制计算机,所以编程语言是给人写的。那么自然就要符合人类的思维习惯,例如面向对象,函数式编程等。这也是为什么有那么多的编程语言的不同之处。
-
计算机世界只有0/1,而交付0/1对人类来说在现代实在太困难了,所以我们发明了了指令集架构,发明了汇编,发明了各种例如JVM的字节码。而这些也就是计算机所需要的输入。
-
人类的思维和计算机的所需要的输入之间有一个翻译的过程,这个过程就是编译器。编译器的目的就是把人类的思维翻译成不同level的计算机所需要的输入。
-
我们通过编程语言与计算机沟通,那么自然希望这个语言是一种扩展性强的,让我们不被语言语法本身所限制,通常对人类抽象层面越高的语言他们的表达能力反而更弱,这也是插件系统的重要性所在。插件主要的作用就是在不增加原语言复杂度的前提下扩展出更强的能力,当然并不是所有的语言都通过插件体系来实现核心能力(例如类似的compose&swiftui,前者是通过插件生态扩展能力,后者(虽然在swift5.9 之后支持了macro的插件体系)依然是通过为语言本身增加更多的表达能力来达成)
接下来我们就结合KMP从编程语言的角度来刨析实际工程化中的实践
语言(language)
默认可见性为public😭
可见性/Visibility modifiers(*https://kotlinlang.org/docs/visibility-modifiers.htm*l)在工程化上是一件至关重要的事,因为可见性的控制直接影响到了代码的复用性和维护性。Kotlin 的设计哲学是你不需要它时,它不会打扰你;你需要它时,它就在那里 。默认的 public 可见性体现了这一哲学,即不强制开发者在不需要时使用可见性修饰符。但是当Kotlin进化从JVM进化到Multiplatform后,针对不同平台的可见性就有自己的特点了。例如当链接到Native时,哪些符号需要做C/Objc binding ?例如编译到JS后什么需要导出到模块?这些都是需要开发者自己去考虑的。导致的结果就是有些是通过Kotlin自身的一些annotation例如@JsExport有些是通过编译器参数-Xexport-library来实现的。例如语言层面的Visibility叉乘无论是annotation还是编译参数的组合,这会要求开发者更多的感知这些语言层面的细节,从而违反了他原来的设计哲学。
编译器(compilers)
三个编译器
上文我们提到编译器的工作是交付计算机可以理解的输入,而大多数传统跨平台语言的做法主要有两种。1. 类似C++、Rust直接输出不同CPU架构的机器码。2. 类似Java、C#输出字节码,然后通过不同的Runtime来解释执行。前者的最大问题就是和原生平台的语言交互不畅,毕竟是两个层面的语言(例如JVM平台上通过JNI与Native交互),后者的问题就是性能问题,无论如何都是过了一层中间层。KMP在这的选型是通过三个编译器来实现的,分别是Kotlin-Jvm、Kotlin-Native、Kotlin-Js。可以直接输出原生平台的机器交付产物,在原生友好性与一致性之间达到了一个平衡点。优点的同时也一定会伴随痛点,例如不同平台的不同行为定义,经常需要通过在common代码中定义一些其他平台毫无关心的annotation来实现。

Kotlin/Native
-
${KOTLIN}/bin/kotlin-native是一个把Kotlin Code转化成不需要虚拟机从而直接运行在目标平台上的编译器。他主要包括了基于LLVM的Frontend的实现以及对Kotlin的标准库的Native实现。
-
${KOTLIN}/bin/cinterop是一个把C/ObjC语言的头文件转化成可被Kotlin/Native调用的 .klib 的工具。
-
${KOTLIN}/klib/platform是Kotlin/Native SDK中帮助开发者默认 binding 的所有平台能力,例如android/ndk ios/Foundation linux/posix等。
优点:
- 在这两个工具以及默认binding的情况下,我们发现在实际开发的工程化中,语言之间的互操作变得无比的流畅!
缺点:
-
由于平台的binding是放在kotlin中的,导致平台的能力层面与kotlin版本之间产生了绑定,例如ios/UIKit是内置在Xcode的,也变相产生了kotlin版本与Xcode版本之间的绑定。
-
由于编译到机器码的原因编译时间相对JVM较长,同时由于目前编译器层需要完整的依赖链,导致类似implementation deps这种特性无法实现。从而降低了增量编译速度,劣化了体验。
Kotlin/JS 😭
双向interop
由于Kotlin和TypeScript/JavaScript这两个语言在语言层面有非常大的差距,例如literal types(https://www.typescriptlang.org/docs/handbook/2/everyday-types.html#literal-types ) 在Kotlin中是没有对等的, 例如Long类型在标准库中是没有对应的JS类型的,例如Error的处理在两个语言中是完全不同的,这就导致了在Interop的时候需要通过大量的转换手段来解决这个问题。而社区上也并没有一个很好的解决方案。目前相对(基本不)可用的两个工具分别为dukat(https://github.com/Kotlin/dukat ) 和 karakum(*https://github.com/karakum-team/karakum*)。K/JS在B站目前主要用于鸿蒙,而鸿蒙自身也不太稳定,导致两个不稳定因素叠加更不可控。目前我们的做法就是基于 karakum 进行问题的修修补补,做到勉强可用。
产物缺少精准strip能力
在K/N中提供了类似-Xexport-library的能力供开发者决策toplevel模块的导出,从而基于这棵树来做unused strip。但是在K/JS中并没有这样的能力, K/JS会导出所有依赖树中声明为@JsExport的顶层模块的树,看似也是提供了Export的声明但其实是并无法解决问题。例如在不同variants的情况下针对相同模块有不同的依赖树, 例如a->b在项目A中需要导出a ,在项目B中需要导出b ,这就导致我们不得不在两个模块中同时声明JSExport而这会导致在A项目中看到不关心的b模块。又由于b模块作为了TopLevel会导出大量与A无关的体积代码。
同symbol name的冲突
- JsExport-declaration-name-clash-with-ES-modules(*https://youtrack.jetbrains.com/issue/KT-60140/MPP-JS-conflicting-JS-signatures-are-not-reported-and-invalid-JS-code-is-emitted*)
无法以同ir粒度的模块切分.d.ts
当前K/JS 的TS的生成是基于binary也即是一个产物一个.d.ts ,把Kotlin所有的模块合并在了一起,即使通过-Xir-per-module拆分了 .js 但是 .ts缺依然没拆分。导致K/JS 的复杂工程无法以模块的方式提供给其他前端项目使用(例如鸿蒙),只能以聚合产物的方式交付。
产物(artifacts)
klib
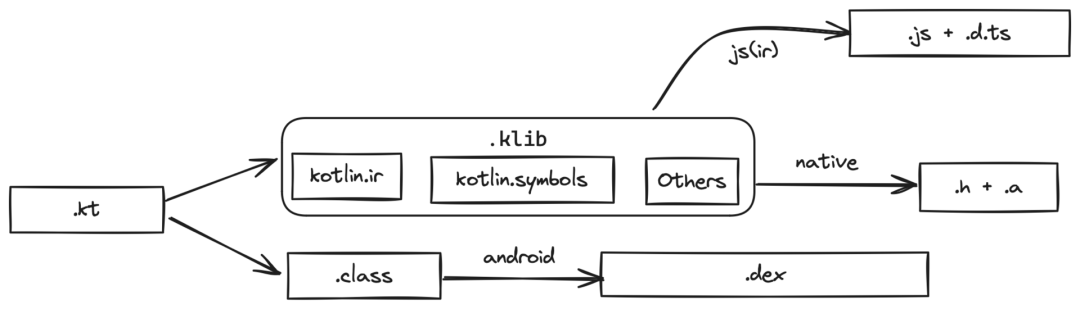
在KMP世界中和过去基JVM的的产物发生了一些变化,即定义了一种新的 lib 结构.klib 我们基本可以把.klib 对等为一组.class或者一个class.jar文件。不同的是.klib存放的是 Kotlin IR 的产物以及对应平台的产物,我们以skiko-iosarm64.klib 举例子
skiko.klib└── default # compiler/util-klib/src/org/jetbrains/kotlin/library/KotlinLibraryLayout.kt ├── ir # compiler/ir/serialization.common/src/KotlinIr.proto 当前kotlin编译产物类似.h+.a │ ├── bodies.knb │ ├── debugInfo.knd │ ├── files.knf │ ├── irDeclarations.knd │ ├── signatures.knt │ ├── strings.knt │ └── types.knt ├── linkdata # kotlin types 用于链接 & 代码索引提示等 │ ├── module │ ├── package_org │ │ └── 0_org.knm │ ├── package_org.jetbrains │ │ └── 0_jetbrains.knm │ ├── package_org.jetbrains.skia │ │ ├── 0_skia.knm │ │ └── 7_skia.knm │ ├── package_org.jetbrains.skia.icu │ │ ├── 0_icu.knm │ │ └── 1_icu.knm │ └── root_package │ └── 0_.knm ├── manifest ├── resources └── targets # 编译目标平台 └── ios_arm64 ├── included # native artifacts │ ├── libskia.a │ └── skiko-native-bridges-ios-arm64.a ├── kotlin └── native # .bc我们可以很明显看到一个问题,因为平台相关,所以交付的产物是区分 platform target的,所以Jetbrains的设计是通过gradle module(https://docs.gradle.org/current/userguide/publishing_gradle_module_metadata.html ) 中的variant来区分产物,这也导致了下载klib产物时我们必须遵守 gradle metadata 的协议,从而没法使用一些更通用的例如POM(*https://maven.apache.org/pom.html*)这样的规范。(在后文会提到我们不得已实现了一个基于Gradle的产物下载的bazel rule)
universal klib

在基于variants的情况下,往往我们需要下载(${platform target} + 1(meta)) * lib 个数的 klib ,又因为大多数klib其实并不像skiko那样有平台相关的产物, 所以很大一部分都是冗余的,在KotlinConf'24(*https://www.youtube.com/watch?v=Ar73Axsz2YA*)中也提到了这个问题。对于universal klib的后续launch,我们可以拭目以待。
插件(plugins)
我们可以从Kotlin/KEEP(https://github.com/Kotlin/KEEP )的proposals的数量看到其实Kotlin是一种对语法特别克制的语言。(可以通过与swift对比 swift/evolution(*https://github.com/apple/swift-evolution*) )。而Kotlin这么选择的的原因我个人认为是设计了KCP(Kotlin Compiler Plugin)插件系统 来进行语言层面能力的弥补。例如 compose compiler 之于 compose生态、 serialization之于序列化生态、 ksp之于代码生成生态等等。
KCP(Kotlin Compiler Plugin)
KCP的定位就是为Kotlin本身能力进行补充,所以他会与Kotlin编译器高度绑定,对ABI向前兼容会造成非常大的负担,这也是几乎所有的KCP插件(compose、serialization...)都是以Kotlin的版本作为版本号的原因。这就会造成大量的维护以及迭代更新成本。我们同时也可以看到在K2发布后,Jetbrains也做了些变化,例如把这些kcp compiler都merge到了kotlin/plugins 也是因为这一点。
KSP (Kotlin Symbol Processor)
由于KCP的问题,所以google为之开发了ksp生态, ksp的定位是为了解决KCP的问题,他是基于KCP的一个子插件,用来抽象一层稳定的API给开发者使用。在我们应用过程中会发现KSP的确能力非常强大,但是他有一个缺点,就是KSP会要求对应的子依赖进行完整编译,也就是说KSP Processor感知到的上下文是和程序开发者完全一致的。乍看其实这是一个非常好的优点,但是代价就是我们需要完整编译他的子依赖作为他的类似classpath传入。这个会导致一些特别糟糕的体验,例如至少编译一次,才能把KSP的结果(模块的编译输入)产出。
在这里我们开放一下脑洞,看一下隔壁Swift的Macros(https://docs.swift.org/swift-book/documentation/the-swift-programming-language/macros/ ) 。他是完全基于当前AST分析的,可以非常快速的生成, 当然代价就是丧失了感知依赖模块的能力。在我们的真实实践过程中,例如类Dagger2(*https://dagger.dev/*)的Swift实现,我们会发现是完全不会有任何问题的。我们通过Macros来做依赖注入的代码生成,通过Bazel自定义的rules来Collect所以需要依赖注入的Metadata,最后通过Codegen来生成依赖注入的代码。所以也畅想是否KSP生态可以进行这块的能力配置,为开发者提供更多的选择配置能力。
Gradle: 构建系统
由于上文提到的Kotlin核心层其实是一个相对low level的存在,从易用性和复杂度两个角度来看都是不适合直接被开发者所接触的。而KMP世界选择了Gradle这个构建工具来组织Kotlin的内核。接下去我们篇幅会从工程角度着重讨论Gradle这个构建工具及生态的一些实践及问题。
构建系统
构建系统(build system)的定义为从输入文件(代码、资源等)生成输出文件(可执行文件、库文件等)的一系列步骤的自动化构建过程。也是一个构建工具的最核心存在。看到这个定义,给定的输出得到给定的输入,我们可以很自然的联想到output = f(input) ,而构建过程一般都伴随着拆解和组合, 例如binary = package(link(compile(source))) ,compile典型的是各种编译器例如gcc、konanc,link典型的是各种链接器例如ld,package典型的是打包成apk、ipa等最终产物的过程。那么我们接下来看看Gradle是如何实现这个过程的(由于笔者比较熟悉Bazel(https://bazel.build/ )构建工具,会较多以Bazel举例子来说明问题), 我们先复习一下Gradle的build phases

我们可以看到在Gradle的构建过程中,他的设计核心是Task的依赖关系一个简单的带依赖的Gradle Task如下
tasks.register('hello') { doLast { println 'Hello world!' }}tasks.register('intro') { dependsOn tasks.hello doLast { println "I'm Gradle" }}回到我们刚才的output = f(input) ,我们可以看到Gradle的构建过程并没有还原最原本的被依赖任务的输出作为依赖他的任务的输入,而是变相通过了一种Dependency tree的方式描述这个关系。
这样的好处是把依赖关系从"强类型"变成了"弱类型",intro不需要关系hello具体交付什么只需要知道hello已经交付了他需要的东西。这样的设计带来的好处是简单易懂,但是也带来了一些问题。如何假设hello是没有sideEffects的?这些都是需要插件开发者自己去保证的。而在Bazel中,他是通过output = f(input)的方式同时通过starlark这个有限级语来限制SideEffects的产生, 从而实现的可靠编译,当然这样的取舍就是放弃了灵活的"弱类型"。
虽然Gradle也可以通过定义task.inputs & task.outputs来隐式的还原依赖关系从而还原依赖树,但是在复杂的带Variants(*https://docs.gradle.org/current/userguide/cross_project_publications.html#sec:variant-aware-sharing*)的情况下我们需要实现大量的Configuration以及在Tasks中通过Variants做逻辑分支判断。只是有通路,但是并没有从工具层面解决这个构建工具的核心问题。
以下是从编译工具角度看到的Gradle作为编译工具一些核心能力的缺失
一些核心能力的缺失
Toolchains
若我们需要实现一个函数例如 artifacts = compile(input_file) ,我们会很明显发现一个问题,他不怎么"functional"。因为很明显光一个input_file是远远不够的, 至少他还需要一个编译器例如fun compile(compile_c, input_file) ,当然我们普世的实践一般不会那么"functional",通常做法是通过一个更大的上下文来获取这些每个任务都需要的输入, 例如fun compile(input_file, context) { compile_c = context.get_compiler(KOTLIN_COMPILER)} 。在构建系统中,这些全局上下文的也即是Toolchains, 而在Gradle的世界里除了JVM作为一等公民的Toolchains是有直接支持的,其他所有的Toolchains很可惜都是没有的,这就导致了我们在构建过程中需要自己去维护这些全局上下文。例如检查环境,配置,安装环境等等。这导致的结果有两个。
-
在Initialization阶段过重的工作量(无效检查和运行)
-
不稳定的环境,导致在执行(Execution)阶段的千疮百孔
-
没有官方的支持,开发者自己实现的Toolchains往往是不可靠的良莠不齐(含社区中的一些gradle plugins)
在这里我们可以参考借鉴隔壁的bazel toolchains(*https://bazel.build/extending/toolchains*)
Platforms
Java是一门虚拟机语言,他的平台是非常稳定的,所以在Gradle中没有Platforms这个概念。但是在KMP&跨平台世界里,我们不得不面临交叉编译这个问题。而交叉编译需要针对不同平台环境的大量上下文做配置支持,例如需要为Host与Execution及Target上不同cpu类型、操作系统的近百种的组合情况做适配。我们举一个在Bazel世界非常典型的编译场景,我们的触发是一台Apple silicon的电脑,通过分布式编译把编译任务调度了一组Linux的X86Runner上,最终要编译一个Android的包, 那么对应的Host = Darwin arm64, Execution = Linux x86_64, Target = Android arm64。再叠加上文提到的Toolchains能力缺失,这个问题再一次被指数级放大。这只是一种组合关系,我们设想一下在Gradle世界中这件事几乎是不可能完成的,所以也可以同样借鉴隔壁的bazel platforms(*https://bazel.build/extending/platforms*)
Sandboxing
当我们在实现fun compile(input_file)的时候,如果在一个sandboxing的环境,我们就可以很好的保证这个函数的纯粹性,也就是说这个函数的输出只和输入有关。如果不在,我们需要写更多的corner case的处理逻辑,使得这个函数变得更加复杂。在处理输入时,如果input_file的同级目录存在一个另外一个文件,在clangc的默认行为是可以感知到那个文件的, 那么错误的include是否应该编译成功?在处理输出时,当我们没有正确的设置 -O他很有可能就污染了我们的工作仓库,从而让整个编译过程变的难以预测和问题追溯。这样我们也可以同样借鉴隔壁的bazel sandboxing(*https://bazel.build/docs/sandboxing*)
Task based dependency management
(基于任务的依赖管理)
在Gradle中,任务是构建的基本单元,任务之间的依赖关系是通过任务之间的依赖关系来实现的。这种方式的优点是简单易懂,但是有非常大的缺点, 他把f = f1(f2(f3(input))) 变成了 f = f1(f2(f3()))也既把所有任务的参数全部抹去了,通过依赖关系(递归顺序)来执行每个任务。这样导致的结果就是 所有的任务共享一个上下文(操作系统及一次Gradle build的Context),也同时意味着他们每个人都有能力破坏干预整个系统的行为。这就导致Gradle的构建过程充满了意外和不可预知性。(缓存错误,环境错误,环状依赖(非gradle task维度)等等) 同时这也是他无法实现上文提到的 #Platforms #Toolchains #Sandboxing的原因。至于哪个是因哪个是果,这个就见仁见智了,笔者的观点还是Gradle为了易用性牺牲了可靠性。
Directory based source set
(基于文件夹维度的源码集)
在Gradle的source set都是基于文件夹维度的,这个设计可能是从 javac 也是基于文件夹维度的编译器继承过来的。这个设计的优点是简单易懂,但是缺点也是显而易见的。比起文件,文件夹有更多的不可预测性,例如里面的深度,结构,决策真正参与编译的文件等等。如果我们是通过文件维度的可能也会更方便的实现基于文件输入的依赖管理,可惜这一切都是基于文件夹的。相对前者我认为基于文件夹的source set管理并不是什么问题,相反其实是一种进步,只是Gradle自身对此的处理bug较多,例如非 java 标准的source layout都会出现一些异常问题。例如我们碰到的为sourceset设置一个外部文件夹作为输入,在gradle cache的情况下他会无视对方文件夹的任何改动,依然命中cache。另外就是由于Bazel是基于文件的, 在展开Gradle project后也给我们造成一些不便之处。
Variants (Build variants / Feature Flags)
在Gradle世界中主要有两种处理变种的方式,一种是通过Build variants ,另一种是通过-D参数。由对应需要分叉的地方进行分叉。前者的一个问题是传染性,我们需要从更高的层面去控制这个变种,而且往往我们不会像android flavor那样去整个的分叉, 会因为一个很小的分叉需要写大量的configuration的resolve的逻辑。而后者的一个问题除了不可预知性(因为在运行阶段才决策)之外还有一个问题就是他缺少一些对编译系统自身的上下文例如前文提到的Platforms, 我们的variants往往其实是会结合目标上下文的一个逻辑变种,仅仅只有一个-D我们需要分散大量的和编译上下文相关的代码逻辑到各个build.gradle中,使得variants几乎不可控。
在这个上面,我个人认为Bazel做的也做的比较差,但是这里也提供bazel configuration-attributes(*https://bazel.build/docs/configurable-attributes*)作为参考
Kotlin Gradle plugin 和 KMP的开发体验
KGP
插件系统是社区对Gradle生态的扩展,在这一点上Gradle的插件系统是非常强大的,社区也是非常活跃的。无论是大厂背书的Kotlin Gradle Plugin、Android Gradle Plugin等等, 又或者是一些库支持的Compose Gradle Plugin、Serialization Gradle Plugin等等。这些插件都是为了扩展Gradle的能力,使得Gradle可以更好的适应不同的场景。也是Gradle生命力的核心体现。在这方面上简直吊打了其他友商。但是Gradle的插件系统有一点就是他是基于Java这种需要编译的语言,上文也提到过由于Gradle自身的很多设计原因,会要求插件开发者承担更多的工作, 也对插件质量有更高的要求,这就导致了插件的质量良莠不齐,往往我们写上plugins { xxx }}背后面临的大量的心智负担,特别是当plugins有问题时debug也相对麻烦。在这里如果有更轻量的脚本语言可能会有更好的体验。
KMP的开发体验
IDEA由于自己的插件系统很强大并没有绑定某个编译工具,可以很好的支持Gradle、Maven、Bazel等等。但是从目前社区的实践来看,也只有Jetbrains自家的插件是最好的,其他插件往往是不可靠的。例如Bazel的插件,就算在纯JVM上也有很大的问题,更别说其他平台的语言或者是Multiplatform了。虽然IDEA在使用过程中会有内存怪兽的现象,但是不得不承认,在研发体验 可用性角度上都完爆友商。上文提到的无论是编译系统,插件系统,对于一线研发而言基本都是不感知的,唯独IDEA是工作的日日夜夜的核心效率工具,我们在上文也可以看到, Gradle从工程化视角来看是有种种问题的,但是就因为是核心效率工具这一个原因,我们花了将近1/3的工作在适配Gradle之上。
KMP在工程化里的问题
Cache的不可信
虽然我们一直紧跟着Gradle的升级,目前我们也已经使用了Gradle8.4。我们依然会遇到大量的Build Cache的问题,例如上文提到的source set文件变更没有触发rebuild等。导致研发经常需要在本地研发环境进行clean build等操作。同时公司Android基于Gradle的构建的正式发布永远是clean build,而做对比公司iOS基于Bazel的构建(无论是Debug还是Release)永远是incremental build。
所有的build.gradle 都是通过标准模版统一输出,仅仅使用到了 KGP & AGP最新版本的标准配置,KAPT&KSP 等CodeGen任务全部静态展开,没有任何Side Effects任务。
环境(Toolchains)的不可信
目前bilibili在KMP上的实践,并不是通过Kotlin来实现平台的一切,而是依然会使用原来积累的模块,提供给KMP interop使用。这个问题极具加重了Gradle自身的缺点, 例如我们在鸿蒙的工具链中依赖了不少Node的环境,例如我们的iOS工程大量依赖了例如Swift buf Xcode等环境。这就导致了我们在Gradle的构建过程中需要大量的环境检查, 同时涉及到交叉编译(simulator_x86_64, simulator_arm64,ios_arm64)的interop等,这相当于猛攻Gradle的七寸,导致了例如K/N,K/JS的构建过程不可信。
最关键的是,在iOS体系中,相对Java所有的编译任务至少有5-10倍的编译时长的差距,作为跨平台依赖层,我们绝不可因为一个不可靠的编译,从而破坏iOS自身的增量编译(例如关闭发布时的增量编译)
Feature Flags的后置
(从编译时延后到运行时)
bilibili采取的是monorepo的项目组织,即不同个App都是一个仓库交付的,这也导致了我们构建过程会需要海量的Feature flag来控制编译行为。在历史经验中,由于我们Android项目是Gradle组织的,虽然有flavors但是依然会有一些App长期处于远远落后主干的情况出现,追其原因其实是业务诉求对条件编译的复杂度非常高,而Variants来实现条件编译太困难了。导致的另外一个问题是,很多研发同学会把Feature Flag搬到运行时,例如通过运行时来判断一些当前的环境从而走不同的逻辑分支,这样无论对工程化,而是App runtime来说都是一个问题。虽然我们的KMP工程复杂度规模并没有到这一步,但是从Android的经验来看这件事必定会发生,即我们需要一个更可用的编译期Feature Flags的能力。
不可预知的编译过程
由于Gradle的设计,每个Project自己的build.gradle是可以由研发自己书写的,而正如前文所提到的感知全文(Context)的问题,我们根本无法控制开发者的行为。因此我们需要大量的后验动作来保证整个编译过程的可靠性。可是只有在Gradle的build phases中提到的三个阶段中Initialization和Configuration完成后我们才可以确定Execution phase的图结构,在有了图结构之后 我们才可以做一些服务工程健康的工作,例如依赖检查(是否存在不合理的依赖),编译预测(某个模块的是否会造成更大的增量从而导致整个编译过程变慢)等等。然而这一切都是要在这两个阶段之后才可以做到。以我们公司的Android项目为例,在非增量情况下这两步往往需要数分钟之久的执行(不含下载),这会导致我们要把刚才提到的旁支检查链路通过插件等形式插入到主流程之中,从而拖慢整个的pipeline效率。
iOS上"一厢情愿"的推荐工作流
CocoaPods有着先发优势,在iOS的社区中有着较好的库支持的基础,所以KMP会选择通过CocoaPods来CInterop原生库以及通过CocoaPods中的XcodeProj来生成用来把KMP for iOS产物的XcodeEmbed工程。另一种方式是通过embedAndSignAppleFrameworkForXcode来通过Xcode的环境变量来把.framework 产物送进编译以及集成resource,重签等一系列工作。
无论哪种方式都有些一厢情愿,首先是CocoaPods他并不是苹果官方的推荐包管理方式,仅仅是出得早,而出得早自然也有一堆历史的负担,这里不展开细说,但是我们无论从社区上例如tuist XcodeGen struct Carthage, 亦或是一些商业公司自己自研的包管理工具,无疑例外都不会把CocoaPods放在首位。使得这条集成链路不可使用。
另外一种方式是通过embedAndSignAppleFrameworkForXcode ,这个方式是通过Xcode的环境变量来控制上下文, 严重假设了Xcode本身,例如bilibili就完全不使用xcodebuild,那么对应的上下文就完全失效了。同时他作为插在Xcode build phase的一个环节,对Xcode的日志等集成也不够友好,经常导致忙等,卡死等问题。
bilibili的优化及实践

KMP有一整套基于Gradle的完整生态,虽然很不想......但是我们还是要面对一些工程化中不可解决的问题......从而自己造一套轮子......(就像当年不争气的xcodebuild那样,我们需要的不是自行车而是战车)
我们会发现KMP的核心层(Kotlin Core)是非常健壮且完善的,在编译工具的生态建设方面,还有改进空间,特别是在支持大型企业级大规模、多团队协作的项目时。同时Gradle的设计也更多的从易用性的角度出发,而牺牲了工程的上限。所以 我们的选择是直面Kotlin-Core层,为其重新做一层面向开发者的编译工具(Bazel)的封装, 从而解决我们碰到的KMP Gradle插件和 Gradle 本身设计的问题。通过这种封装,希望改善跨平台开发工程结构,减少百万行工程规模的(KMP+原生代码)构建时间,同时提供更加稳定和可靠的构建过程。
在上文 Kotlin Gradle plugin 和 KMP的开发体验(*http://uat-kntr.bilibili.co/docs/kmp-core.html#KMP的开发体验*) 中有提到我们最不可割舍的就是IDEA与Gradle的集成时的研发体验,同时又因为我们Android项目是用Gradle组织的, 我们并不想通过产物的方式集成(虽然产物的方式集成可以解耦编译系统之间环境耦合,但是会大幅度增加代码的碎片化和代码切片同步的问题),所以我们完整实现了一个由Bazel组织且可自行编译的KMP工程,同时也实现了一套Bazel to Gradle的秒级转化工具,从而使得我们可以在IDEA中使用Gradle的研发体验, 同时可以作用于 iOS.bazel 和 Android.gradle 和 KMP.bazel 的CI体系。
构建系统替换为Bazel
相对Gradle插件生态而言,Bazel的Rules生态只能说惨不忍睹,唯一相对可用的rules_kotlin 也仅仅只能服务于kotlin.jvm,并且未对kmp的能力做任何支持。所以我们的主要工作就在建设这些rules之上
取
- kmp.ci 全量开启incremental build (含所有模块的三个平台编译 + 三个平台的产物编译dry run) 平均控制在1分钟内

- 灵活的Feature flags
kmp 模块(RPC,日志,图片,AB等等)通过各种feature flags分别支持原平台的provider能力注入,由kt实现的default注入,mock app等多种变化,使得kmp仓库独立运行成为可能
- 静态化的编译过程
所有build.gradle自动生成中没有任何DSL配置之外的动态化能力。DSL只有KGP及AGP。可随时应对上游KMP生态发生的变更。同时由于bazel query的高性能做到快速针对研发workspace的自定义配置。从而加速优化IDEA sync等缓慢的体验问题
- 更优的双向interop能力
无需对CInterop或者反向集成平台书写额外任何配置(只需书写对应语言的$Language_library ),通过Bazel aspect 自动化生成每个平台的双向interop bridge层,节省大量的boilerplate config的工作
舍
-
Gradle的plugin生态 对于社区上的大量的Gradle Kotlin生态的插件,我们需要去解刨出他内部的核心实现,例如 KSP KCP,通过更low level的层来接入。对于非Kotlin生态的插件,我们需要阅读实现后重新用Bazel进行包裹
-
学习曲线 由于替换了构建工具,配置需要从build.gradle转成 BUILD.bazel。虽然.bazel 远比 .gradle简洁,但是碍于生态,IDE等问题,书写较为困难(无法在IDEA体系里写,需要在vscode中通过bazel插件来高亮) 同时对于Bazel rules开发需要接受远比gradle体系更多的知识,从而导致rules的开发曲线较为陡峭
-
Bazel自身的缺陷 我们在上面《取》中说到了通过Bazel解决掉的Gradle问题,但同样Bazel自身也有一些问题。
-
静态化, Bazel的高效其实是通过他的静态化换来的,而静态化会出现一些问题,例如apple_support(https://github.com/bazelbuild/apple_support )在macos下的cctoolchains是假设在xcode存在的情况下的, 而单纯的Android开发是没有对应环境的,而在bazel.WORKSPACE 中我们是没有办法为他们set不同的toolchains,虽然apple_support 正在实现通过command line tools来实现CCToolcahins ,但是我们可能并没有等他的条件
-
与Kotlin-Core生态的融合,Bazel会要求输入输出是绝对明确的,然而Kotlin-Core中很多任务是暧昧的,即产物是什么是有可能不一样的。在这种情况下Bazel去兼容他们是相对复杂的。例如KSP任务,他的产物大概率是可有可无的
付出
-
对Kotlin-Core的能力复原 (KAPT,KCP,KSP,OPTIN,Multiplatform,...)
-
对Gradle resolve能力的复原 (rules_gradle_external)
-
对KGP的能力的复原 (rules_kotlin_mobile)
-
对其他生态能力的复原 (compose.resource.compiler,...)
值得吗?
从上文我们可以看到,由于Bazel生态的不太给力,我们的Bazel化工作量是不小的,我自己作为这个项目的发起及负责人其实也是有很多犹豫和纠结的。在项目早期我自己也多次在复刻实现Gradle生态的一些能力时质疑自己的决策,是不是只是因为我在舒适区更了解Bazel而已?重复再干一遍是不在自high?
但是随着这些一次性得付出的工作的逐渐完成,逐渐我也打消了顾虑。
-
极限优化本身就是破坏再重组的过程,我们的目标是为了更好的工程化,而不是为了更简单的KMP化
-
很多不可解的或者需要等待社区解决的一个round trip的问题我们都有了解决的能力
-
我们顺便也解决的Android工程长期存在的一些问题(例如增量编译,依赖版本管理,Gradle Initialization缓慢等)
而把Kotlin-Core的能力重新组织的过程也更进一步让我理解了KMP的核心,兼容Gradle更让我从原理上理解了Gradle的设计,从而在两个前沿的构建系统中取长补短。而无疑选择一个上限更高的构建系统,牺牲很小一部分社区生态是划得来的。
对KMP生态的展望
Kotlin-Native 实现implementation deps
当前种种原因,K/N下其实是不存在impl deps这个能力的,所以模块依赖都是穿透的。这个会导致很严重地依赖穿透问题。虽然我们目前通过魔法绕过了这个问题,但是依然希望官方通过正经的方式来解决。
Kotlin-Native 以Kotlin模块的维度拆分
Native模块
当前K/N的最终产物是链接在一起的,这也一样会导致不必要的incremental build的问题。同时也会让对应平台的调用侧感知到太多的不需关注的东西。这块我们目前也没有解决方案,只能希望官方可能在为Swift做interop的契机下,把K/N对平台的可见从链接后的产物拆到每个独立模块
Kotlin-Native 增强debugging能力
当前K/N的产物中debug info都是绝对路径,这会导致lldb在调试的时候找不到对应的源码,同时也会对分布式缓存/编译造成影响。目前我们通过指定source-map来擦除掉了我们自己代码的路径信息,但是依然解决不了官方产物的那些问题,也希望后续可以擦除抑或是发布编译的source-map
Kotlin.LSP
目前Kotlin的LSP能力是集成在Kotlin源码内部的,这对生态例如基于VSCode的KMP开发并不友好,虽然商业因素较多,但是还是畅想下希望有朝一日可以更多的开放出来
总结
本文从一个较大规模的工程化的视角来解读分析了KMP的构建系统,插件系统,IDEA集成等等问题,并且提出了我们的解决方案。同时也对KMP生态的未来做了一些展望。在Kotlin-core这一章节提到的所有问题也都已在issue tracker中记录,也希望尽早被得到解决。也希望给到面临相同问题的开发者得到一些解决思路。
后续B站会持续继续输出关于KMP技术的技术及实践的深度文章,也会持续关注跨平台技术的发展,希望能够在这个领域有更多的交流。下一篇会是关于当前bilibili的App矩阵与KMP技术的落地实践,敬请期待。