bug出现背景
集群产生的日志要求traceId不重复,使用雪花算法生成traceId
报错形式如下
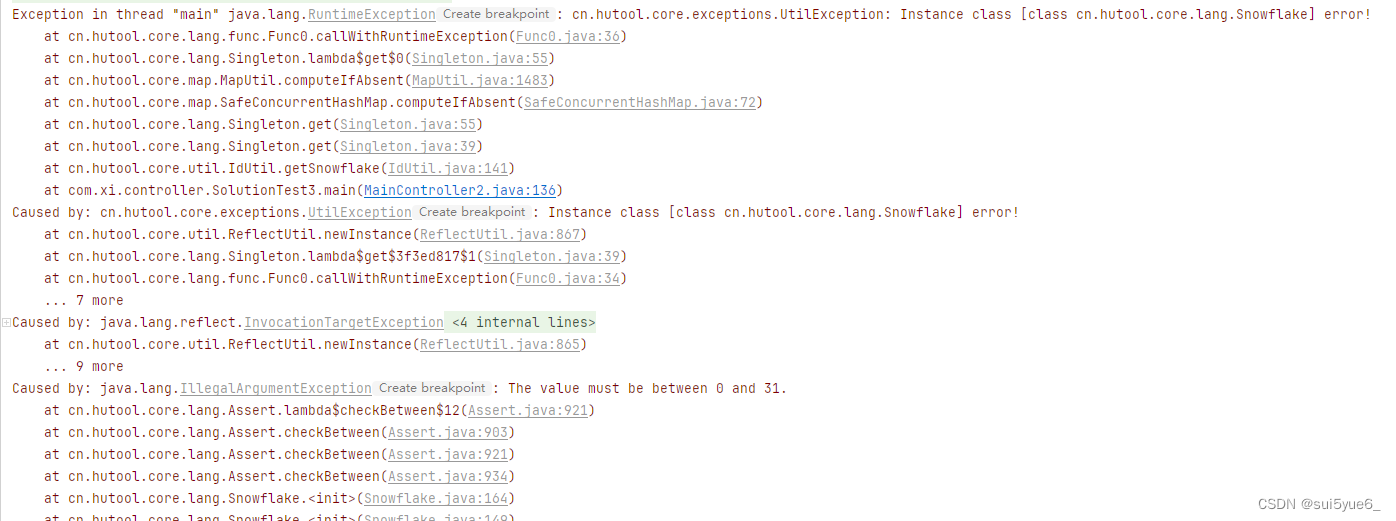
为什么本地无法复现测试环境的bug
因为bug的出现本身就是概率性的事件
代码如下
public static Long workId = Long.parseLong(String.valueOf(NetUtil.getLocalhostStr().hashCode() + new Random().nextInt(99999))) % 31;这里取hashCode后的数字加上99999数字,可能会越界变成负数,因为这里的workId需要在0到31之间就不被满足
测试复现
public static void main(String[] args) {
for (int i = 0; i < 100000; i++) {
Long workId = Long.parseLong(String.valueOf(new Random().nextInt(Integer.MAX_VALUE) + new Random().nextInt(99999))) % 31;
if (workId < 0) {
System.out.println(workId);
}
}
}如果有人想到用abs做解决方案的话,会有一种极端情况如下
雪花算法的用法
第一种
每次都用工具创建实例,再去生成
java
return IdUtil.getSnowflake(workId, centerId).nextIdStr();第二种
用工具创建snowflake单例,id每次用单例中生成
java
// 静态变量
public static Snowflake snowflake = IdUtil.getSnowflake(workId, centerId);
return snowflake.nextIdStr();第一反应,第一种创建的方式是错误的。两个实例对于雪花id的创建是不会有加锁限制的。
源码分析
java
这里是使用Singleton创建
public static Snowflake getSnowflake(long workerId, long datacenterId) {
return (Snowflake)Singleton.get(Snowflake.class, new Object[]{workerId, datacenterId});
}
使用到这里先去get,如果get到直接返回,没有get到,就反射创建对象
public static <T> T get(Class<T> clazz, Object... params) {
Assert.notNull(clazz, "Class must be not null !", new Object[0]);
String key = buildKey(clazz.getName(), params);
return get(key, () -> {
return ReflectUtil.newInstance(clazz, params);
});
}
// 存储实例的地方
private static final SafeConcurrentHashMap<String, Object> POOL = new SafeConcurrentHashMap();
public static <T> T get(String key, Func0<T> supplier) {
return POOL.computeIfAbsent(key, (k) -> {
return supplier.callWithRuntimeException();
});
}也就是说,hutool工具snowflake开发的时候已经考虑到有 水平不怎么高的程序员使用,而进行了代码上的兜底。上面的单例对象也可以借鉴学习
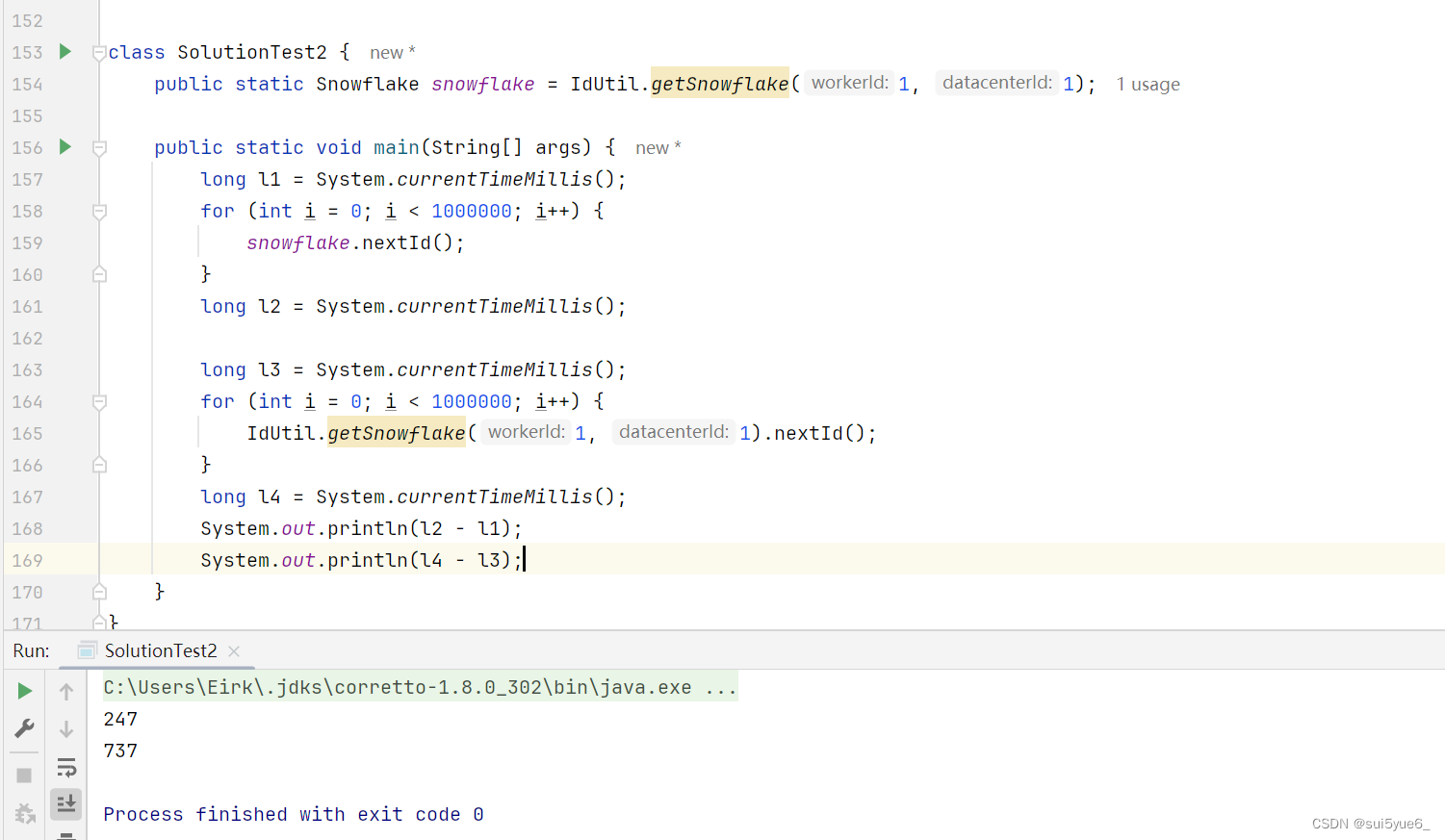
性能上也没有实质性的差距
上面hutool如何保证两个线程都初始创建对象的时候的绝对单例
SafeConcurrentHashMap 这个map是自己封装的
重写了 computeIfAbsent
为啥封装一个静态的mapUtil
public V computeIfAbsent(K key, Function<? super K, ? extends V> mappingFunction) {
return MapUtil.computeIfAbsent(this, key, mappingFunction);
}没有找到类似双重检查锁的代码。。。。到这里结束吧