【实战场景】记一次UAT jvm故障排查经历
开篇词:
故障背景是客服中心通话历史分表4季度,单表200w+,查询一年的数据量,大分页(查询第20w页的10条数据)查询多次,tomcat卡死,一段时间后,后台其他定时任务,kafaka消费线程恢复正常,tomcat web容器依旧高cpu,具卡无比。
干货篇:
1.查看系统资源使用情况
top -H -p 49339
解释:查看进程49339进程的实时系统资源使用情况,"-H"表示查看进程中所有线程资源占用情况; "-p"指用来指定具体进程号
2.将十进制进程号转成十六进制
printf "%x \n" 49339
解释:转换的目的是让这个线程ID能和jstack输出的线程ID匹配上,因为jstack输出的是十六进制的线程ID
3.使用jstack工具监视进程的垃圾回收情况
jstat -gc 49339 3 5
解释:通过jstat工具查看jvm 垃圾回收情况,"-gc"指定要监视的内容为垃圾回收情况;"3"每隔三秒输出一次监视结果;"5"一共输出5次监视结果。
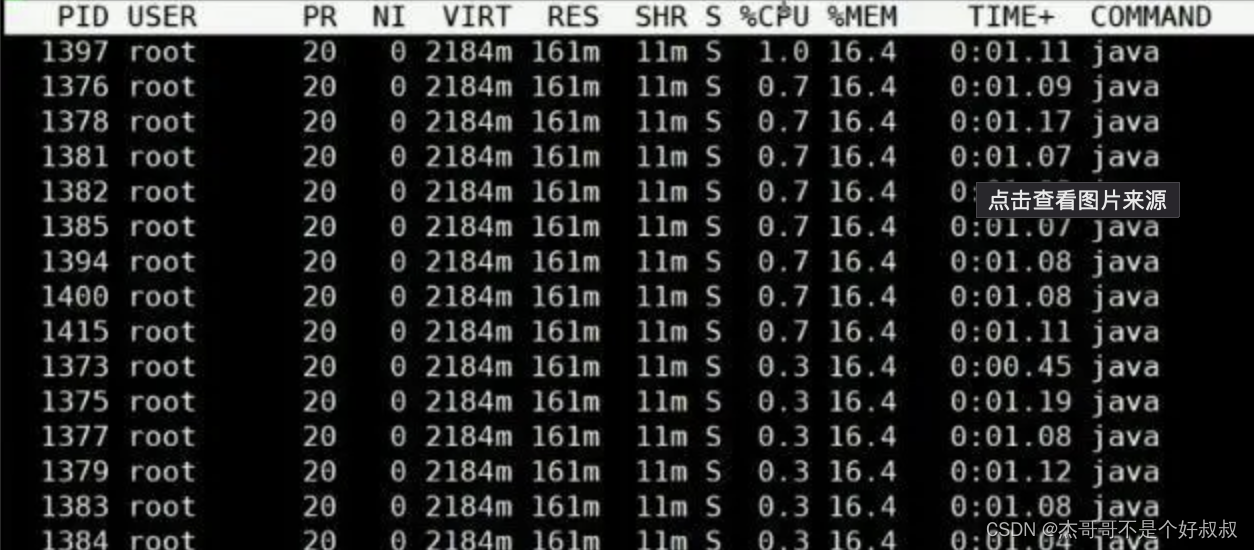
其中各参数代表的含义:
- S0C (Survivor space 0 capacity):第一个幸存区(Survivor space)的容量(以字节为单位)。幸存区用于存放垃圾收集后存活的对象。
- S1C (Survivor space 1 capacity):第二个幸存区的容量(以字节为单位)。在大多数 JVM 实现中,幸存区有两个,用于在不同的垃圾收集周期之间切换。
- S0U (Survivor space 0 utilization):第一个幸存区当前已使用的空间大小(以字节为单位)。
- S1U (Survivor space 1 utilization):第二个幸存区当前已使用的空间大小(以字节为单位)。
- EC (Eden space capacity):Eden 区的容量(以字节为单位)。Eden 区是 Java 堆的一部分,用于存放新生成的对象。
- EU (Eden space utilization):Eden 区当前已使用的空间大小(以字节为单位)。
- OC (Old space capacity):老年代(Old Generation)的容量(以字节为单位)。老年代用于存放存活时间较长的对象。
- OU (Old space utilization):老年代当前已使用的空间大小(以字节为单位)。
- MC (Metaspace capacity):元空间(Metaspace,Java 8 引入以替代永久代)的容量(以字节为单位)。元空间用于存放类的元数据。
- MU (Metaspace utilization):元空间当前已使用的空间大小(以字节为单位)。
- CCSC (Compressed class space capacity):压缩类空间(Java 8+ 中使用)的容量(以字节为单位)。这个空间用于存放类的元数据,但与元空间分开管理。
- CCSU (Compressed class space utilization):压缩类空间当前已使用的空间大小(以字节为单位)。
- YGC (Young GC count):年轻代垃圾收集的次数。
- YGCT (Young GC time):年轻代垃圾收集所花费的总时间(以秒为单位)。
- FGC (Full GC count):完全垃圾收集(Full GC,也称作老年代垃圾收集)的次数。
- FGCT (Full GC time):完全垃圾收集所花费的总时间(以秒为单位)。
- GCT (Total GC time):垃圾收集所花费的总时间(以秒为单位),包括年轻代和完全垃圾收集的时间。
请注意,具体的输出参数可能会因 JVM 的版本和配置(如是否启用了压缩指针等)而有所不同。此外,对于 JDK 11 及更高版本,元空间(Metaspace)取代了永久代(PermGen space),因此相关的参数(如 PC 和 PU)在较新版本的 JVM 中不再出现。
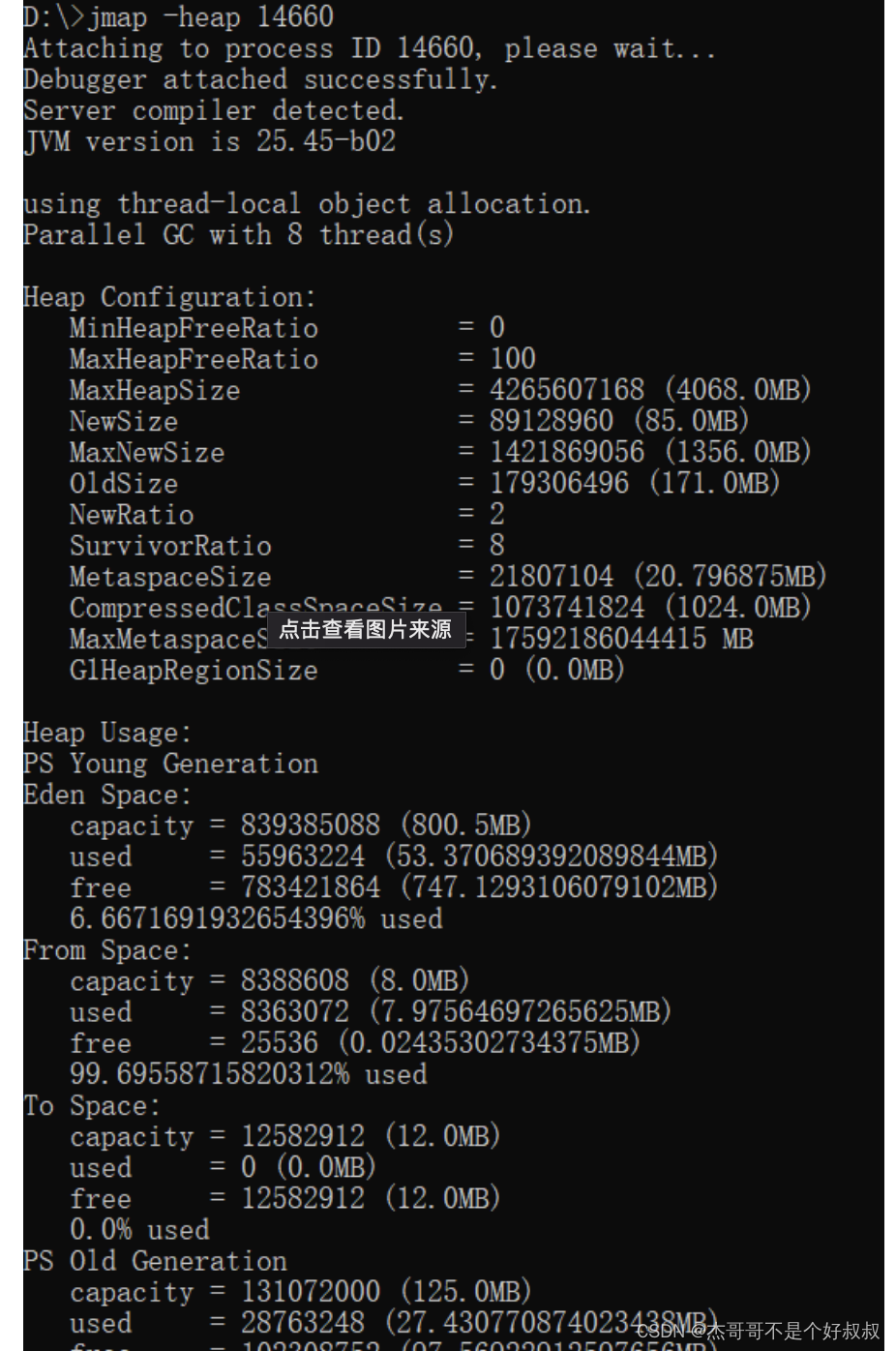
4.输出指定线程的堆内存信息
jmap -heap 49339
解释:输出指定线程的堆内存信息
jstack -l 49339|grep c22a -A 20
解释:时候用jstack工具来输出java进程的线程堆栈信息,并查找包含字符串"c22a"的行,打印其后面的20行
"-l":指定输出java进程的线程ID;"-A 20":打印匹配行及其后面的20行
5.观察日志
发现kafka消费线程占用cpu较高,kafka consumer正常epollWait等待kafaka数据,无其他特别异常信息,暂时跳过
6.本地环境复现
更换jdbc连接池至druid,通过dashboard排查分表后的真实sql耗时,中等数据量时,由于分表的存在,limit 20w,20w+10会被重写0,20W+10,以便跨表数据内存排序,数据量大,便造成了慢查询,有可能导致OOM
总结篇:
以下是大致的排查JVM问题的思路:
- 初步观察和监控
查看系统指标:使用系统监控工具(如Linux的top命令或Windows的任务管理器)查看CPU、内存和网络IO等关键指标。
观察JVM监控工具:使用JDK自带的工具如jConsole、VisualVM或第三方工具(如Arthas)来远程连接并监控JVM的内存使用趋势、线程状态、垃圾回收活动等。 - 确定问题类型
内存问题:观察是否出现OutOfMemoryError(OOM)错误,或者内存使用量异常增长。
CPU问题:查看CPU使用率是否过高,特别是某个或某些Java线程的CPU占用率异常。
线程问题:检查是否存在死锁、线程饥饿或线程阻塞等问题。
垃圾回收问题:分析垃圾回收日志,查看垃圾回收的频率、时间和类型,判断是否存在频繁的Full GC或GC时间过长等问题。 - 使用诊断工具
jstack:用于打印Java线程的堆栈跟踪信息,帮助定位线程问题,如死锁、线程阻塞等。
示例命令:jstack ,其中是Java进程的进程ID。
jmap:用于生成堆内存快照和查询堆内存使用情况。
示例命令:jmap -heap 查看堆内存使用情况,jmap -dump:live,format=b,file=.hprof 生成堆内存快照。
jstat:用于监视JVM中类的加载、内存、垃圾收集、JIT编译等运行时数据。
示例命令:jstat -gc 1000每1000毫秒打印一次GC信息。
jcmd(JDK 1.8+):集成了多个JDK诊断命令的功能,用于执行更复杂的诊断任务。
示例命令:jcmd Thread.print打印线程信息。 - 分析日志和堆内存快照
分析GC日志:通过GC日志分析垃圾回收的频率、时间、类型和原因,判断是否存在内存泄漏、堆内存设置不合理等问题。
分析堆内存快照:使用MAT(Memory Analyzer Tool)等内存分析工具分析堆内存快照,查找内存泄漏的源头、大对象占用等。
查看应用程序日志:检查应用程序日志以获取更多关于错误和异常的上下文信息。 - 定位和解决问题
代码优化:根据分析结果优化代码,减少内存占用、避免内存泄漏、优化数据结构等。
JVM参数调整:调整JVM启动参数,如堆内存大小(-Xms,-Xmx)、垃圾回收器类型(-XX:+UseG1GC)等,以改善JVM性能。
升级JDK版本:如果问题是由于JDK的已知bug引起的,考虑升级到更高版本的JDK。 - 验证和监控
验证修复:在开发或测试环境中验证修复是否有效,确保问题得到解决。
持续监控:在问题解决后,持续监控系统性能,确保没有新的问题出现。
通过以上步骤,可以系统地排查和解决JVM问题,提高系统的稳定性和性能。需要注意的是,排查JVM问题可能需要一定的经验和耐心,因为问题可能由多种因素引起,需要综合考虑各种信息来找到问题的根源。
