https://github.com/echonoshy/cgft-llm
cgft-llm/llama-cpp/README.md at master · echonoshy/cgft-llm (github.com)
【大模型量化】- Llama.cpp轻量化模型部署及量化_哔哩哔哩_bilibili
Release模式是直接运行,Debug模式是调试模型。github.com/ggerganov/llama.cpp
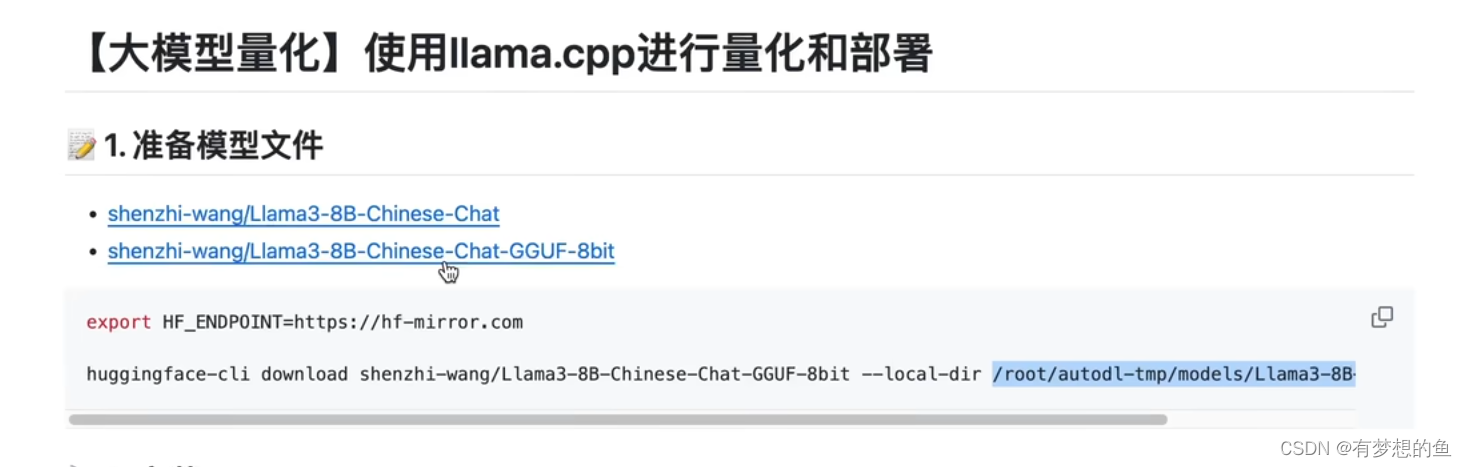
export HF_ENDPOINT=https://hf-mirror.com
huggingface-cli download shenzhi-wang/Llama3-8B-Chinese-Chat-GGUF-8bit --local-dir /root/autodl-tmp/models/Llama3-8B-Chinese-Chat-GGUF
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp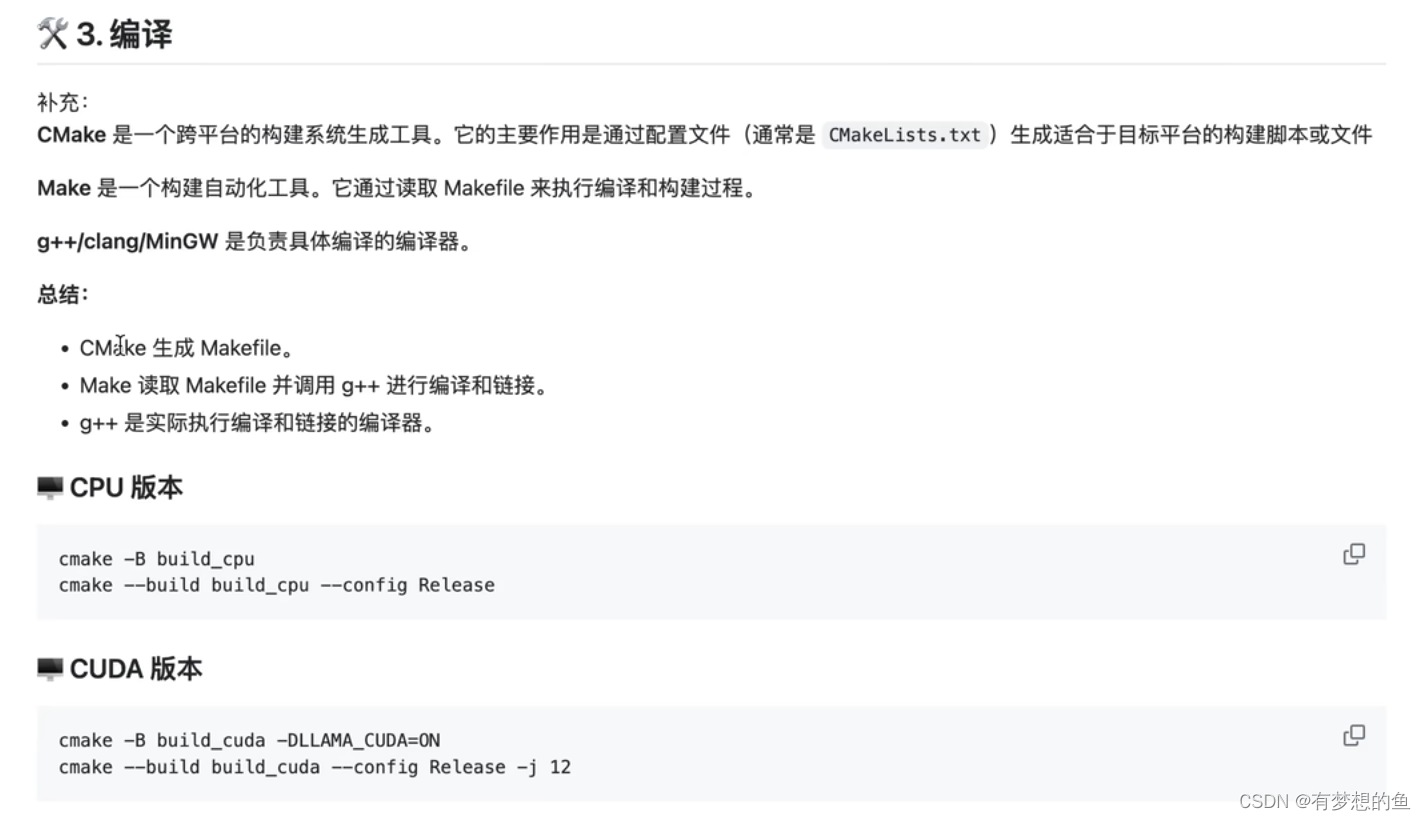
cmake -B build_cpu
cmake --build build_cpu --config Release
cmake -B build_cuda -DLLAMA_CUDA=ON
cmake --build build_cuda --config Release -j 12

cd ~/code/llama.cpp/build_cuda/bin
./quantize --allow-requantize /root/autodl-tmp/models/Llama3-8B-Chinese-Chat-GGUF/Llama3-8B-Chinese-Chat-q8_0-v2_1.gguf /root/autodl-tmp/models/Llama3-8B-Chinese-Chat-GGUF/Llama3-8B-Chinese-Chat-q4_1-v1.gguf Q4_1
python convert-hf-to-gguf.py /root/autodl-tmp/models/Llama3-8B-Chinese-Chat --outfile /root/autodl-tmp/models/Llama3-8B-Chinese-Chat-GGUF/Llama3-8B-Chinese-Chat-q8_0-v1.gguf --outtype q8_0



