预训练语言模型详解
总目录
-
[第四章 大语言模型](#第四章 大语言模型)
-
[第五章 动手搭建大模型](#第五章 动手搭建大模型)
-
[第六章 大模型训练实践](#第六章 大模型训练实践)
-
[第七章 大模型应用](#第七章 大模型应用)
目录
- Decoder-Only 预训练语言模型
- 4.1 GPT模型
- 4.1.1 [模型架构------Decoder Only](#模型架构——Decoder Only)
- 4.1.2 预训练任务------CLM
- 4.1.3 GPT系列模型的发展
- 4.2 LLaMA模型
- 4.2.1 [模型架构------Decoder Only](#模型架构——Decoder Only)
- 4.2.2 LLaMA模型的发展历程
- 4.3 GLM模型
- 4.3.1 模型架构------相对于GPT的略微修正
- 4.3.2 预训练任务------GLM
- 4.3.3 GLM家族的发展
- 4.1 GPT模型
- 参考资料
Decoder-Only 预训练语言模型
在前两节中,我们学习了Encoder-Only模型(以BERT为代表)和Encoder-Decoder模型(以T5为代表)。现在让我们深入探讨第三种架构------Decoder-Only,这正是当今大型语言模型(LLM)的基础架构。
Decoder-Only架构是目前最主流的LLM架构,几乎所有的LLM(除RWKV、Mamba等非Transformer架构外)都采用这种设计。引发LLM热潮的ChatGPT,正是Decoder-Only系列代表模型GPT的集大成之作。目前作为开源LLM基础架构的LLaMA模型,也是在GPT架构基础上优化发展而来。
GPT模型
GPT(Generative Pre-Training Language Model,生成式预训练语言模型)是OpenAI团队于2018年发布的预训练语言模型。虽然学界普遍认可BERT作为预训练语言模型时代的代表,但首先明确提出预训练-微调思想的其实是GPT。
模型架构---Decoder Only
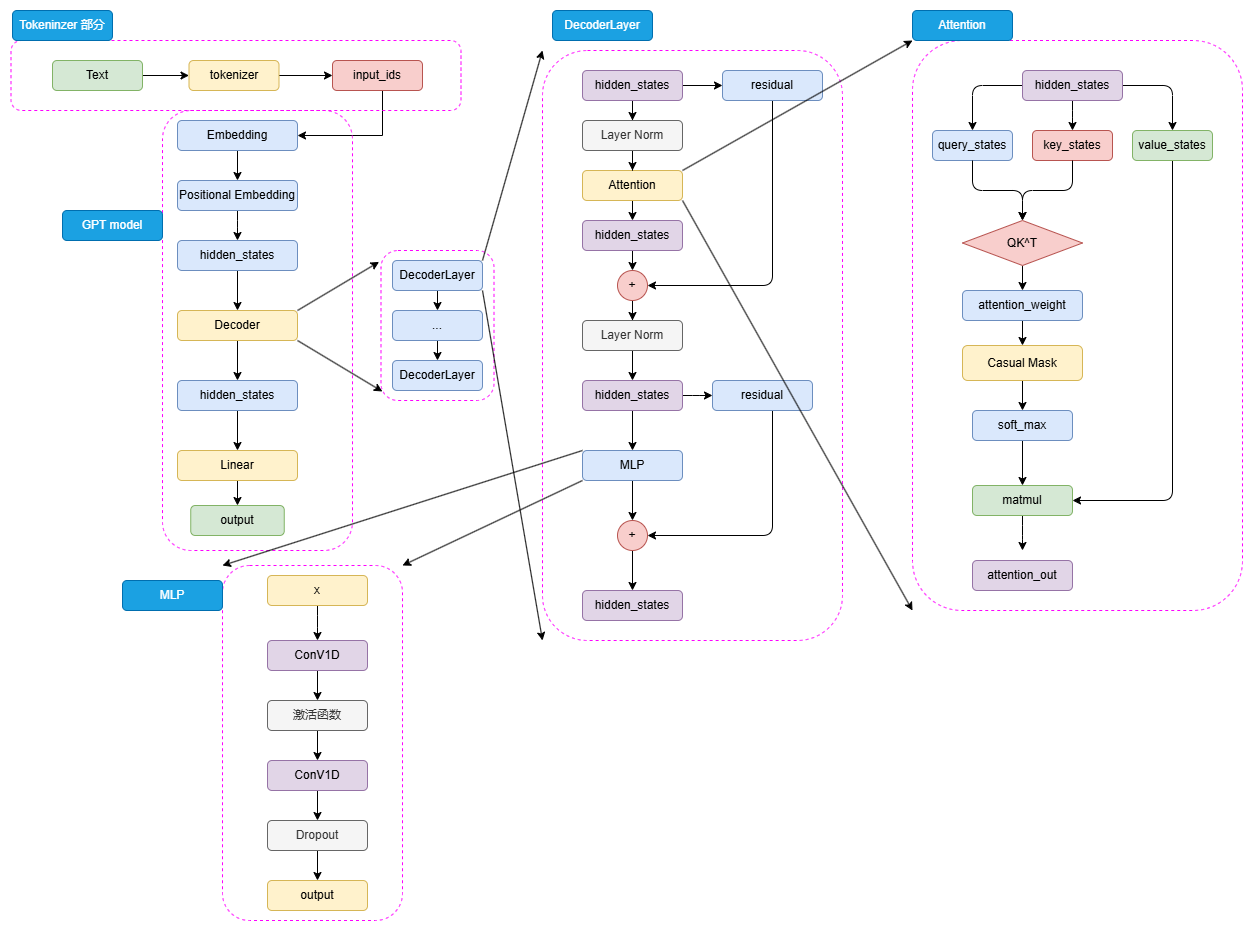
GPT的整体结构与BERT有相似之处,但选择使用Decoder而非Encoder进行堆叠。由于Decoder-Only结构天生适合文本生成任务,相比更贴合NLU任务设计的BERT,GPT和T5的设计更契合NLG任务和Seq2Seq任务。
GPT的核心组件:
python
class GPTModel:
"""
GPT模型实现
"""
def __init__(self, config):
self.vocab_size = config.vocab_size
self.n_positions = config.n_positions # 最大序列长度
self.n_layer = config.n_layer # Decoder层数
self.n_head = config.n_head # 注意力头数
self.n_embd = config.n_embd # Embedding维度
# Embedding层
self.token_embedding = nn.Embedding(self.vocab_size, self.n_embd)
self.position_embedding = nn.Embedding(self.n_positions, self.n_embd)
# Decoder层
self.decoder_blocks = nn.ModuleList([
GPTDecoderBlock(config) for _ in range(self.n_layer)
])
# 最终的LayerNorm
self.ln_f = nn.LayerNorm(self.n_embd)
# 输出层(映射到词表)
self.lm_head = nn.Linear(self.n_embd, self.vocab_size, bias=False)
def forward(self, input_ids):
batch_size, seq_length = input_ids.shape
# 1. Token Embedding
token_embeds = self.token_embedding(input_ids) # [batch, seq_len, n_embd]
# 2. Position Embedding(Sinusoidal位置编码)
position_ids = torch.arange(0, seq_length, dtype=torch.long, device=input_ids.device)
position_ids = position_ids.unsqueeze(0).expand_as(input_ids)
position_embeds = self.position_embedding(position_ids)
# 3. 合并embeddings
hidden_states = token_embeds + position_embeds
# 4. 通过所有Decoder blocks
for block in self.decoder_blocks:
hidden_states = block(hidden_states)
# 5. 最终LayerNorm
hidden_states = self.ln_f(hidden_states)
# 6. 映射到词表
logits = self.lm_head(hidden_states)
return logitsGPT Decoder Block的结构:
python
class GPTDecoderBlock:
"""
GPT的Decoder Block
与Transformer的Decoder不同,GPT只有masked self-attention,没有cross-attention
"""
def __init__(self, config):
self.ln_1 = nn.LayerNorm(config.n_embd) # Pre-norm
self.attn = MaskedSelfAttention(config)
self.ln_2 = nn.LayerNorm(config.n_embd)
self.mlp = MLP(config)
def forward(self, hidden_states):
# 1. Pre-LayerNorm + Masked Self-Attention + 残差连接
residual = hidden_states
hidden_states = self.ln_1(hidden_states)
attn_output = self.attn(hidden_states)
hidden_states = residual + attn_output
# 2. Pre-LayerNorm + MLP + 残差连接
residual = hidden_states
hidden_states = self.ln_2(hidden_states)
mlp_output = self.mlp(hidden_states)
hidden_states = residual + mlp_output
return hidden_statesMasked Self-Attention机制:
GPT的关键创新在于masked self-attention,确保每个token只能关注到它之前的tokens:
python
class MaskedSelfAttention:
"""
带因果掩码的自注意力机制
"""
def __init__(self, config):
self.n_head = config.n_head
self.n_embd = config.n_embd
self.head_dim = self.n_embd // self.n_head
# Q, K, V的投影(合并为一个矩阵以提高效率)
self.c_attn = nn.Linear(self.n_embd, 3 * self.n_embd)
self.c_proj = nn.Linear(self.n_embd, self.n_embd)
# 注册因果掩码(下三角矩阵)
self.register_buffer(
"bias",
torch.tril(torch.ones(config.n_positions, config.n_positions))
.view(1, 1, config.n_positions, config.n_positions)
)
def forward(self, hidden_states):
batch_size, seq_length, _ = hidden_states.shape
# 1. 计算Q, K, V
qkv = self.c_attn(hidden_states) # [batch, seq_len, 3*n_embd]
q, k, v = qkv.split(self.n_embd, dim=2)
# 2. 重塑为多头形式
q = q.view(batch_size, seq_length, self.n_head, self.head_dim).transpose(1, 2)
k = k.view(batch_size, seq_length, self.n_head, self.head_dim).transpose(1, 2)
v = v.view(batch_size, seq_length, self.n_head, self.head_dim).transpose(1, 2)
# 3. 计算注意力分数
attn_scores = torch.matmul(q, k.transpose(-2, -1)) / math.sqrt(self.head_dim)
# 4. 应用因果掩码(关键步骤)
causal_mask = self.bias[:, :, :seq_length, :seq_length]
attn_scores = attn_scores.masked_fill(causal_mask == 0, float('-inf'))
# 5. Softmax
attn_probs = F.softmax(attn_scores, dim=-1)
# 6. 加权求和
attn_output = torch.matmul(attn_probs, v)
# 7. 重塑并投影
attn_output = attn_output.transpose(1, 2).contiguous()
attn_output = attn_output.view(batch_size, seq_length, self.n_embd)
attn_output = self.c_proj(attn_output)
return attn_output
# 因果掩码可视化
def visualize_causal_mask(seq_length=5):
"""
可视化因果掩码矩阵
"""
mask = torch.tril(torch.ones(seq_length, seq_length))
print("Causal Mask (1表示可以attend,0表示被mask):")
print(mask)
# Output:
# tensor([[1., 0., 0., 0., 0.],
# [1., 1., 0., 0., 0.],
# [1., 1., 1., 0., 0.],
# [1., 1., 1., 1., 0.],
# [1., 1., 1., 1., 1.]])MLP层的实现:
GPT的MLP层使用一维卷积核而非传统的线性层:
python
class MLP:
"""
GPT的MLP层(使用1D卷积)
"""
def __init__(self, config):
self.c_fc = nn.Conv1D(config.n_embd, 4 * config.n_embd) # 升维
self.c_proj = nn.Conv1D(4 * config.n_embd, config.n_embd) # 降维
self.act = nn.GELU() # 激活函数
def forward(self, hidden_states):
# 升维
hidden_states = self.c_fc(hidden_states)
# 激活
hidden_states = self.act(hidden_states)
# 降维
hidden_states = self.c_proj(hidden_states)
return hidden_states
# 注:虽然使用Conv1D,但效果上与Linear层类似
# 主要区别在于参数的组织方式和计算效率预训练任务---CLM
python
# 示例:文本生成(续)
def generate_text(model, prompt, max_length=50):
"""
使用CLM生成文本
"""
tokens = tokenizer.encode(prompt)
for _ in range(max_length):
# 获取模型预测
logits = model(tokens)
# 取最后一个位置的logits
next_token_logits = logits[-1, :]
# 采样下一个token(使用temperature控制随机性)
next_token = torch.multinomial(
F.softmax(next_token_logits / temperature, dim=-1),
num_samples=1
)
# 添加到生成序列
tokens.append(next_token.item())
# 如果生成了结束符,停止生成
if next_token.item() == eos_token_id:
break
return tokenizer.decode(tokens)
# 实际使用示例
prompt = "今天天气"
generated_text = generate_text(model, prompt)
# 可能的输出: "今天天气很好,阳光明媚,适合外出游玩。"CLM的优势:
- 直接对齐人类写作:模拟人类从左到右书写的自然过程
- 无限量训练数据:可以在任何文本上直接应用
- 训练与推理一致:不存在BERT的MLM那样的预训练-微调不一致问题
- 自然支持生成任务:天生适合文本生成
python
# CLM vs MLM 对比
def compare_clm_mlm():
"""
对比CLM和MLM的训练方式
"""
text = "我爱自然语言处理"
# CLM训练方式
print("CLM训练:")
print("输入: 我爱自然语言")
print("目标: 爱自然语言处理")
print("特点: 逐token预测,从左到右")
# MLM训练方式
print("\nMLM训练:")
print("输入: 我[MASK]自然[MASK]处理")
print("目标: [MASK]→爱, [MASK]→语言")
print("特点: 随机遮蔽,双向理解")GPT系列模型的发展
OpenAI坚信"体量即正义"的优化思路,通过不断扩大预训练数据和模型规模来提升性能。
GPT系列演进对比:
| 模型 | Decoder层数 | 隐藏层维度 | 注意力头数 | 头维度 | 总参数量 | 预训练语料 |
|---|---|---|---|---|---|---|
| GPT-1 | 12 | 768 | 12 | 64 | 0.12B | 5GB |
| GPT-2 | 48 | 1600 | 25 | 64 | 1.5B | 40GB |
| GPT-3 | 96 | 12288 | 96 | 128 | 175B | 570GB |
1. GPT-1:开山之作
python
# GPT-1配置
class GPT1Config:
vocab_size = 40478
n_positions = 512 # 最大序列长度
n_layer = 12 # Decoder层数
n_head = 12 # 注意力头数
n_embd = 768 # Embedding维度
# 训练配置
dataset = "BooksCorpus"
dataset_size = "5GB"
training_tokens = "~1B"GPT-1虽然首次提出预训练-微调思想,但由于模型规模和BERT相当而性能略逊,未能成为主流。
2. GPT-2:规模扩张
GPT-2的核心改进是大幅增加模型规模和预训练数据:
python
# GPT-2配置(最大版本)
class GPT2Config:
vocab_size = 50257
n_positions = 1024
n_layer = 48
n_head = 25
n_embd = 1600
# 关键改进
layer_norm_position = "pre" # Pre-Norm而非Post-Norm
# 训练配置
dataset = "WebText"
dataset_size = "40GB"
training_tokens = "~10B"
# Pre-Norm vs Post-Norm
class PreNormBlock:
"""
GPT-2使用的Pre-Norm结构
"""
def forward(self, x):
# 先LayerNorm,再进入子层
residual = x
x = self.layer_norm(x)
x = self.sublayer(x)
x = residual + x
return x
class PostNormBlock:
"""
GPT-1使用的Post-Norm结构
"""
def forward(self, x):
# 先进入子层,再LayerNorm
residual = x
x = self.sublayer(x)
x = residual + x
x = self.layer_norm(x)
return xZero-shot学习:
GPT-2首次强调zero-shot能力,即不需要任何训练样本直接解决任务:
python
def zero_shot_classification(model, text, classes):
"""
零样本分类示例
"""
best_class = None
best_score = float('-inf')
for class_name in classes:
# 构造prompt
prompt = f"{text}\nThis text expresses {class_name} sentiment."
# 计算该prompt的困惑度
score = model.score(prompt)
if score > best_score:
best_score = score
best_class = class_name
return best_class
# 使用示例
text = "这部电影真是太棒了!"
classes = ["positive", "negative", "neutral"]
result = zero_shot_classification(model, text, classes)
# 输出: "positive"3. GPT-3:涌现能力的开创
GPT-3是LLM的真正开创者,其175B的参数量带来了质的飞跃:
python
# GPT-3配置
class GPT3Config:
vocab_size = 50257
n_positions = 2048
n_layer = 96
n_head = 96
n_embd = 12288
# 稀疏注意力(由于模型巨大)
attention_type = "sparse"
# 训练配置
datasets = ["CC", "WebText", "Books", "Wikipedia"]
dataset_size = "570GB"
training_tokens = "300B"
# 训练资源
gpus = "1024 x A100 (80GB)"
training_time = "~1 month"
# 稀疏注意力机制
class SparseAttention:
"""
GPT-3使用的稀疏注意力
"""
def __init__(self, config):
self.n_head = config.n_head
self.block_size = 128 # 局部注意力窗口
def forward(self, q, k, v):
"""
局部+全局的稀疏注意力模式
"""
seq_len = q.size(1)
# 1. 局部注意力:每个token只关注前后一定范围
local_mask = self.create_local_mask(seq_len, self.block_size)
# 2. 全局注意力:特定位置的token关注所有位置
global_mask = self.create_global_mask(seq_len)
# 3. 合并掩码
attention_mask = local_mask | global_mask
# 4. 计算注意力
attn_scores = torch.matmul(q, k.transpose(-2, -1))
attn_scores = attn_scores.masked_fill(~attention_mask, float('-inf'))
attn_probs = F.softmax(attn_scores, dim=-1)
output = torch.matmul(attn_probs, v)
return outputFew-shot学习:
GPT-3的重大突破是few-shot in-context learning:
python
def few_shot_learning(model, task_description, examples, query):
"""
Few-shot学习示例
"""
# 构造包含示例的prompt
prompt = f"{task_description}\n\n"
# 添加示例
for example in examples:
prompt += f"输入: {example['input']}\n"
prompt += f"输出: {example['output']}\n\n"
# 添加查询
prompt += f"输入: {query}\n输出:"
# 生成答案
output = model.generate(prompt)
return output
# 情感分类few-shot示例
task = "请判断以下文本的情感倾向(正向/负向)"
examples = [
{"input": "你的表现非常好", "output": "正向"},
{"input": "太糟糕了", "output": "负向"},
{"input": "真是一个好主意", "output": "正向"}
]
query = "这真是一个绝佳的机会"
result = few_shot_learning(model, task, examples, query)
# 输出: "正向"涌现能力(Emergent Abilities):
当模型规模达到一定阈值后,会出现小模型不具备的能力:
python
class EmergentAbilities:
"""
GPT-3展现的涌现能力
"""
abilities = {
"arithmetic": "执行多位数加减法",
"reasoning": "逻辑推理和常识推理",
"code_generation": "根据描述生成代码",
"translation": "多语言翻译",
"question_answering": "基于上下文回答问题",
"summarization": "长文本摘要",
"few_shot_adaptation": "快速适应新任务"
}
@staticmethod
def demonstrate_arithmetic(model):
"""
演示算术能力
"""
prompt = "请计算: 1234 + 5678 = "
result = model.generate(prompt)
return result # "6912"
@staticmethod
def demonstrate_reasoning(model):
"""
演示推理能力
"""
prompt = """
问题: 如果所有的A都是B,所有的B都是C,那么所有的A都是C吗?
答案:
"""
result = model.generate(prompt)
return result # "是的,这是一个有效的三段论推理。"4. GPT-4:多模态突破
GPT-4是OpenAI在2023年3月发布的多模态大型语言模型,标志着从纯文本模型向多模态模型的重大转变。
python
# GPT-4配置(推测,OpenAI未完全公开)
class GPT4Config:
# 架构细节未完全公开
model_type = "Mixture of Experts (MoE)" # 推测使用MoE架构
total_params = "~1.76T" # 总参数(推测)
active_params = "~220B" # 激活参数
n_experts = 8 # 专家数量(推测)
# 多模态能力
modalities = ["text", "image", "audio"]
vision_encoder = "CLIP-like"
max_image_tokens = 4096
# 上下文窗口
context_windows = {
"standard": 8192,
"extended": 32768,
"turbo": 128000 # GPT-4-turbo
}
# 训练配置
training_cutoff = "2023-04"
training_tokens = "~13T" # 推测
# MoE架构示例
class MixtureOfExpertsLayer:
"""
GPT-4可能使用的混合专家架构
"""
def __init__(self, num_experts=8, expert_capacity=2):
self.num_experts = num_experts
self.expert_capacity = expert_capacity
# 创建多个专家网络
self.experts = nn.ModuleList([
FeedForwardExpert(hidden_size) for _ in range(num_experts)
])
# 门控网络(路由)
self.gate = nn.Linear(hidden_size, num_experts)
def forward(self, hidden_states):
batch_size, seq_len, hidden_dim = hidden_states.shape
# 1. 计算门控分数(决定使用哪些专家)
gate_logits = self.gate(hidden_states) # [batch, seq, num_experts]
gate_probs = F.softmax(gate_logits, dim=-1)
# 2. 选择top-k个专家(稀疏激活)
top_k_gates, top_k_indices = torch.topk(gate_probs, k=2, dim=-1)
# 3. 通过选中的专家处理
expert_outputs = torch.zeros_like(hidden_states)
for i in range(2): # 只激活top-2专家
expert_idx = top_k_indices[:, :, i]
expert_weight = top_k_gates[:, :, i].unsqueeze(-1)
# 分发到对应专家
for expert_id in range(self.num_experts):
mask = (expert_idx == expert_id)
if mask.any():
expert_input = hidden_states[mask]
expert_output = self.experts[expert_id](expert_input)
expert_outputs[mask] += expert_weight[mask] * expert_output
return expert_outputsGPT-4的核心能力:
python
class GPT4Capabilities:
"""
GPT-4的关键能力展示
"""
@staticmethod
def multimodal_understanding():
"""
多模态理解:图像+文本
"""
prompt = {
"image": "一张包含数学公式的图片",
"text": "请解释这个图片中的数学推导过程"
}
# GPT-4可以理解图像中的内容并给出详细解释
return "这是一个关于微积分的推导..."
@staticmethod
def advanced_reasoning():
"""
高级推理能力
"""
prompt = """
有三个箱子,其中一个装有金币。
箱子A上写着:"金币在这里"
箱子B上写着:"金币不在A中"
箱子C上写着:"金币不在这里"
已知只有一个箱子上的话是真的,金币在哪个箱子?
请详细说明推理过程。
"""
# GPT-4能进行复杂的逻辑推理
@staticmethod
def long_context_processing():
"""
长文本处理(128K上下文)
"""
# GPT-4-turbo可以处理整本书的内容
book_content = "..." # 约10万字的书籍内容
question = "请总结这本书的核心观点并分析其论证逻辑"
# 可以准确理解和分析超长文本
# GPT-4的安全对齐
class GPT4Safety:
"""
GPT-4增强的安全性
"""
safety_features = {
"refusal_training": "拒绝有害请求",
"factuality": "提高事实准确性",
"reduced_hallucination": "减少幻觉",
"bias_mitigation": "降低偏见",
"jailbreak_resistance": "抵抗越狱攻击"
}5. GPT-4o:全方位优化
GPT-4o("o"代表"omni",全能)于2024年5月发布,是GPT-4的优化版本。
python
# GPT-4o特性
class GPT4oConfig:
"""
GPT-4o配置
"""
# 性能提升
speed = "2x faster than GPT-4" # 速度提升2倍
cost = "50% cheaper" # 成本降低50%
# 多模态增强
modalities = {
"text": "文本理解和生成",
"vision": "图像理解(更强)",
"audio": "原生音频输入输出(新增)"
}
# 上下文窗口
context_window = 128000
# 多语言能力
language_performance = {
"english": "基准",
"chinese": "+20% vs GPT-4",
"japanese": "+15% vs GPT-4",
# 其他非英语语言显著提升
}
class GPT4oFeatures:
"""
GPT-4o的独特功能
"""
@staticmethod
def real_time_audio():
"""
实时音频交互(突破性功能)
"""
# 可以直接处理语音输入,生成语音输出
# 平均响应延迟:320ms(接近人类反应速度)
audio_input = "用户的语音问题"
# 直接输出语音,无需先转文字
audio_output = model.generate_audio(audio_input)
return audio_output
@staticmethod
def vision_enhancement():
"""
增强的视觉理解
"""
capabilities = [
"更准确的OCR(文字识别)",
"复杂图表和图像理解",
"手写内容识别",
"多图像关联理解",
"视频帧分析"
]
return capabilities
@staticmethod
def multilingual_boost():
"""
多语言性能提升
"""
# 在非英语任务上的性能大幅提升
benchmark_improvements = {
"MMLU (中文)": "+18%",
"MGSM (多语言数学)": "+22%",
"翻译质量": "+15%"
}
return benchmark_improvements
# 实际应用示例
def gpt4o_multimodal_example():
"""
GPT-4o多模态应用示例
"""
# 场景:分析会议记录
meeting_data = {
"audio": "会议录音(2小时)",
"slides": "演示文稿图片(30页)",
"chat": "聊天记录文本"
}
prompt = """
分析这次会议的内容:
1. 总结主要讨论点
2. 识别关键决策
3. 提取行动项
4. 分析参与者的情绪和态度
"""
# GPT-4o可以综合处理音频、图像、文本
result = gpt4o.process_multimodal(meeting_data, prompt)
return resultLLaMA模型
LLaMA(Large Language Model Meta AI)是Meta开发的主流开源LLM系列,从LLaMA-1到LLaMA-3,展示了大规模预训练语言模型的持续演进。
模型架构---Decoder Only
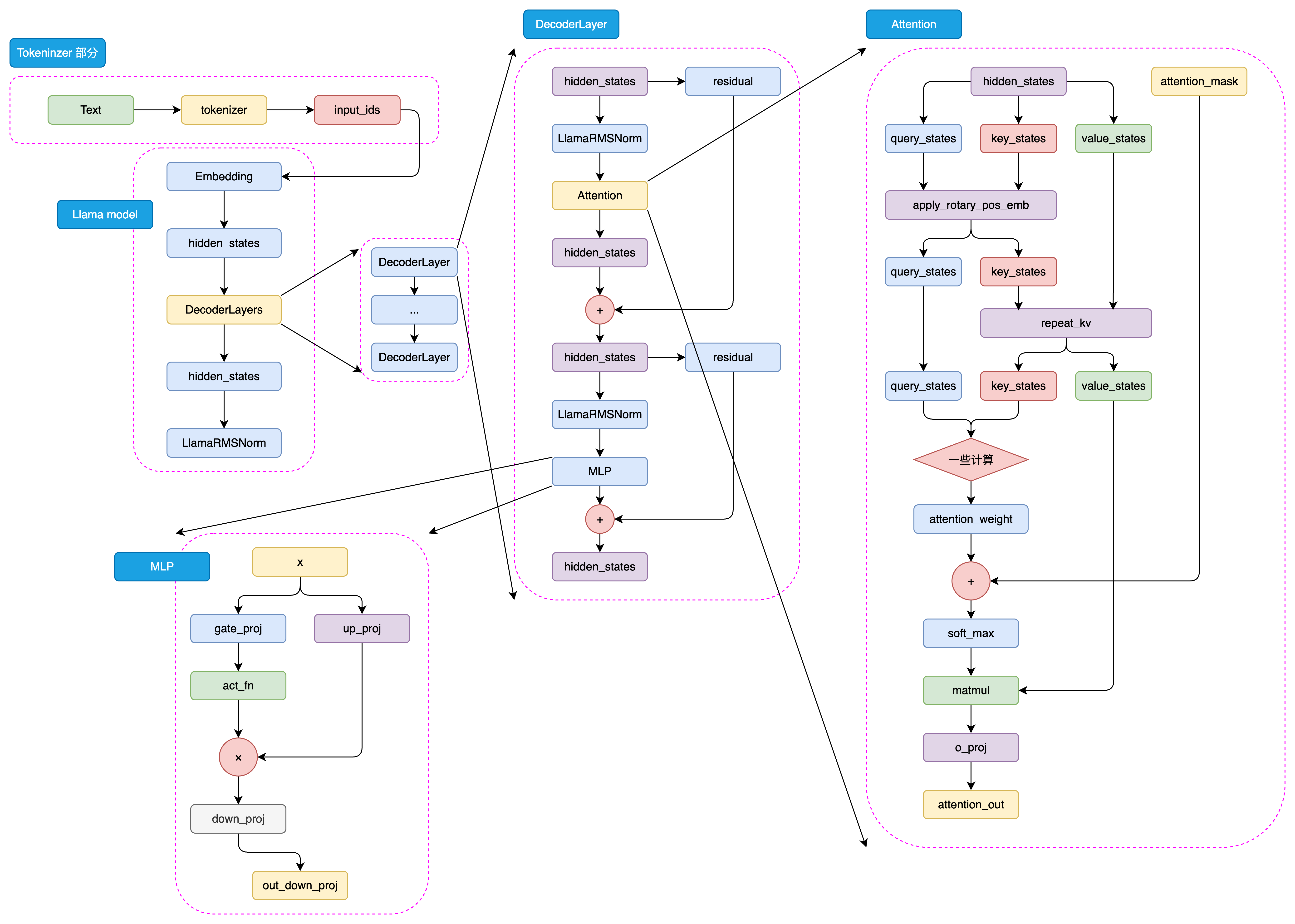
LLaMA采用与GPT类似的Decoder-Only架构,但进行了多项优化:
python
class LLaMAModel:
"""
LLaMA模型实现
"""
def __init__(self, config):
# Embedding
self.embed_tokens = nn.Embedding(config.vocab_size, config.hidden_size)
# Decoder layers
self.layers = nn.ModuleList([
LLaMADecoderLayer(config) for _ in range(config.num_hidden_layers)
])
# 最终的RMSNorm
self.norm = LLamaRMSNorm(config.hidden_size)
# 输出层
self.lm_head = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
def forward(self, input_ids):
# Embedding
hidden_states = self.embed_tokens(input_ids)
# 通过所有decoder layers
for layer in self.layers:
hidden_states = layer(hidden_states)
# 最终归一化
hidden_states = self.norm(hidden_states)
# 输出logits
logits = self.lm_head(hidden_states)
return logits关键技术创新:
1. RMSNorm替代LayerNorm:
python
class LLamaRMSNorm:
"""
LLaMA使用的RMSNorm
"""
def __init__(self, hidden_size, eps=1e-6):
self.weight = nn.Parameter(torch.ones(hidden_size))
self.variance_epsilon = eps
def forward(self, hidden_states):
# 计算RMS
variance = hidden_states.pow(2).mean(-1, keepdim=True)
hidden_states = hidden_states * torch.rsqrt(variance + self.variance_epsilon)
# 应用可学习的权重
return self.weight * hidden_states2. RoPE位置编码:
LLaMA使用旋转位置编码(Rotary Position Embedding, RoPE),这是一种更高效的相对位置编码方式:
python
class RotaryPositionEmbedding:
"""
旋转位置编码(RoPE)
"""
def __init__(self, dim, max_position=2048, base=10000):
self.dim = dim
self.max_position = max_position
self.base = base
# 预计算旋转角度
inv_freq = 1.0 / (self.base ** (torch.arange(0, dim, 2).float() / dim))
self.register_buffer("inv_freq", inv_freq)
def forward(self, seq_len):
"""
生成旋转矩阵
"""
# 生成位置序列
t = torch.arange(seq_len, dtype=self.inv_freq.dtype, device=self.inv_freq.device)
# 计算频率
freqs = torch.einsum("i,j->ij", t, self.inv_freq)
# 生成旋转矩阵
emb = torch.cat((freqs, freqs), dim=-1)
return emb.cos(), emb.sin()
def apply_rotary_pos_emb(self, q, k, cos, sin):
"""
将旋转位置编码应用到Q和K
"""
# 旋转Q
q_embed = (q * cos) + (self.rotate_half(q) * sin)
# 旋转K
k_embed = (k * cos) + (self.rotate_half(k) * sin)
return q_embed, k_embed
def rotate_half(self, x):
"""
旋转向量的一半维度
"""
x1, x2 = x[..., :x.shape[-1]//2], x[..., x.shape[-1]//2:]
return torch.cat((-x2, x1), dim=-1)
# 在注意力机制中使用RoPE
class LLaMAAttention:
"""
LLaMA的注意力机制(包含RoPE)
"""
def __init__(self, config):
self.hidden_size = config.hidden_size
self.num_heads = config.num_attention_heads
self.head_dim = self.hidden_size // self.num_heads
# Q, K, V投影
self.q_proj = nn.Linear(self.hidden_size, self.hidden_size, bias=False)
self.k_proj = nn.Linear(self.hidden_size, self.hidden_size, bias=False)
self.v_proj = nn.Linear(self.hidden_size, self.hidden_size, bias=False)
self.o_proj = nn.Linear(self.hidden_size, self.hidden_size, bias=False)
# RoPE
self.rotary_emb = RotaryPositionEmbedding(self.head_dim)
def forward(self, hidden_states):
batch_size, seq_length, _ = hidden_states.shape
# 计算Q, K, V
q = self.q_proj(hidden_states).view(batch_size, seq_length, self.num_heads, self.head_dim)
k = self.k_proj(hidden_states).view(batch_size, seq_length, self.num_heads, self.head_dim)
v = self.v_proj(hidden_states).view(batch_size, seq_length, self.num_heads, self.head_dim)
# 应用RoPE
cos, sin = self.rotary_emb(seq_length)
q, k = self.rotary_emb.apply_rotary_pos_emb(q, k, cos, sin)
# 转置以进行注意力计算
q = q.transpose(1, 2) # [batch, num_heads, seq_len, head_dim]
k = k.transpose(1, 2)
v = v.transpose(1, 2)
# 计算注意力
attn_weights = torch.matmul(q, k.transpose(-2, -1)) / math.sqrt(self.head_dim)
# 应用因果掩码
causal_mask = torch.tril(torch.ones(seq_length, seq_length)).to(hidden_states.device)
attn_weights = attn_weights.masked_fill(causal_mask == 0, float('-inf'))
# Softmax
attn_weights = F.softmax(attn_weights, dim=-1)
# 加权求和
attn_output = torch.matmul(attn_weights, v)
# 重塑并投影
attn_output = attn_output.transpose(1, 2).contiguous()
attn_output = attn_output.view(batch_size, seq_length, self.hidden_size)
attn_output = self.o_proj(attn_output)
return attn_output3. SwiGLU激活函数:
LLaMA使用SwiGLU(Swish-Gated Linear Unit)替代传统的ReLU或GELU:
python
class SwiGLU:
"""
SwiGLU激活函数
"""
def forward(self, x):
# 将输入分成两部分
x, gate = x.chunk(2, dim=-1)
# Swish激活
return x * F.silu(gate)
class LLaMAMLP:
"""
LLaMA的MLP层(使用SwiGLU)
"""
def __init__(self, config):
self.hidden_size = config.hidden_size
self.intermediate_size = config.intermediate_size
# 门控投影(输出维度是2倍,用于分割)
self.gate_proj = nn.Linear(self.hidden_size, self.intermediate_size * 2, bias=False)
# 下投影
self.down_proj = nn.Linear(self.intermediate_size, self.hidden_size, bias=False)
def forward(self, hidden_states):
# 上投影并应用SwiGLU
gate_output = self.gate_proj(hidden_states)
hidden_states = F.silu(gate_output) # SwiGLU激活
# 下投影
hidden_states = self.down_proj(hidden_states)
return hidden_states4. GQA(Grouped Query Attention):
LLaMA-2引入了分组查询注意力,在保持性能的同时减少KV缓存:
python
class GroupedQueryAttention:
"""
分组查询注意力(GQA)
相比MHA,GQA让多个query头共享同一组key和value
"""
def __init__(self, config):
self.num_heads = config.num_attention_heads # 例如32个query头
self.num_key_value_heads = config.num_key_value_heads # 例如8个kv头
self.num_key_value_groups = self.num_heads // self.num_key_value_heads # 4个query共享1个kv
self.head_dim = config.hidden_size // self.num_heads
# Q投影(完整的头数)
self.q_proj = nn.Linear(config.hidden_size, self.num_heads * self.head_dim, bias=False)
# K, V投影(较少的头数)
self.k_proj = nn.Linear(config.hidden_size, self.num_key_value_heads * self.head_dim, bias=False)
self.v_proj = nn.Linear(config.hidden_size, self.num_key_value_heads * self.head_dim, bias=False)
self.o_proj = nn.Linear(self.num_heads * self.head_dim, config.hidden_size, bias=False)
def forward(self, hidden_states):
batch_size, seq_length, _ = hidden_states.shape
# 计算Q, K, V
q = self.q_proj(hidden_states).view(batch_size, seq_length, self.num_heads, self.head_dim)
k = self.k_proj(hidden_states).view(batch_size, seq_length, self.num_key_value_heads, self.head_dim)
v = self.v_proj(hidden_states).view(batch_size, seq_length, self.num_key_value_heads, self.head_dim)
# 重复K和V以匹配Q的头数
k = k.repeat_interleave(self.num_key_value_groups, dim=2)
v = v.repeat_interleave(self.num_key_value_groups, dim=2)
# 后续注意力计算与标准MHA相同
q = q.transpose(1, 2)
k = k.transpose(1, 2)
v = v.transpose(1, 2)
attn_weights = torch.matmul(q, k.transpose(-2, -1)) / math.sqrt(self.head_dim)
attn_weights = F.softmax(attn_weights, dim=-1)
attn_output = torch.matmul(attn_weights, v)
attn_output = attn_output.transpose(1, 2).contiguous()
attn_output = attn_output.view(batch_size, seq_length, -1)
attn_output = self.o_proj(attn_output)
return attn_outputGQA的优势:
- 减少KV缓存大小(对长文本生成很重要)
- 推理速度更快
- 性能几乎不损失
LLaMA模型的发展历程
LLaMA-1(2023年2月):
python
# LLaMA-1系列配置
llama1_configs = {
"7B": {
"hidden_size": 4096,
"num_hidden_layers": 32,
"num_attention_heads": 32,
"intermediate_size": 11008,
"vocab_size": 32000,
"max_position_embeddings": 2048,
"training_tokens": "1T"
},
"13B": {
"hidden_size": 5120,
"num_hidden_layers": 40,
"num_attention_heads": 40,
"intermediate_size": 13824,
"vocab_size": 32000,
"max_position_embeddings": 2048,
"training_tokens": "1T"
},
"65B": {
"hidden_size": 8192,
"num_hidden_layers": 80,
"num_attention_heads": 64,
"intermediate_size": 22016,
"vocab_size": 32000,
"max_position_embeddings": 2048,
"training_tokens": "1.4T",
"training_gpus": "2048 x A100 80G",
"training_days": 21
}
}LLaMA-2(2023年7月):
主要改进:
- 预训练语料扩充到2T token
- 上下文长度从2048扩展到4096
- 引入GQA机制
python
# LLaMA-2的改进
llama2_improvements = {
"context_length": 4096, # 从2048提升
"training_tokens": "2T", # 从1T提升
"attention_mechanism": "GQA", # 新增
"num_key_value_heads": 8, # GQA配置
"ghost_attention": True # 用于对话任务
}LLaMA-3(2024年4月):
最新的重大升级:
python
# LLaMA-3配置
llama3_configs = {
"8B": {
"hidden_size": 4096,
"num_hidden_layers": 32,
"num_attention_heads": 32,
"num_key_value_heads": 8, # GQA
"vocab_size": 128000, # 显著扩大
"max_position_embeddings": 8192, # 支持8K长文本
"training_tokens": "15T", # 是LLaMA-2的7.5倍
},
"70B": {
"hidden_size": 8192,
"num_hidden_layers": 80,
"num_attention_heads": 64,
"num_key_value_heads": 8,
"vocab_size": 128000,
"max_position_embeddings": 8192,
"training_tokens": "15T",
}
}
# LLaMA-3的关键改进
llama3_features = {
"tokenizer": "更高效的128K词表",
"context_length": "8K",
"training_data": "15T tokens(高质量多语言数据)",
"multilingual": "增强的多语言能力",
"coding": "显著提升的代码能力"
}性能对比示例:
python
def benchmark_llama_models():
"""
LLaMA系列模型性能对比
"""
benchmarks = {
"LLaMA-1-7B": {
"MMLU": 35.1,
"HumanEval": 10.5,
"GSM8K": 11.0
},
"LLaMA-2-7B": {
"MMLU": 45.3,
"HumanEval": 12.8,
"GSM8K": 14.6
},
"LLaMA-3-8B": {
"MMLU": 66.6,
"HumanEval": 62.2,
"GSM8K": 79.6
}
}
return benchmarksLLaMA-3.2(2024年9月)
LLaMA系列的最新版本,引入多模态能力和边缘设备优化。
核心特性
LLaMA-3.2是首个支持视觉理解的LLaMA模型,同时推出了专为移动和边缘设备优化的轻量级版本。
模型矩阵
python
# LLaMA-3.2配置
llama32_configs = {
# 多模态模型(Vision + Text)
"11B-Vision": {
"hidden_size": 4096,
"num_hidden_layers": 32,
"num_attention_heads": 32,
"num_key_value_heads": 8,
"vocab_size": 128256,
"max_position_embeddings": 131072, # 128K上下文!
"vision_config": {
"image_size": 560,
"patch_size": 14,
"num_channels": 3,
"hidden_size": 1280,
"intermediate_size": 5120,
"num_hidden_layers": 32,
"num_attention_heads": 16,
"supported_aspect_ratios": [[1, 1], [1, 2], [2, 1], [1, 3], [3, 1]]
},
"modalities": ["text", "image"],
"training_tokens": "~6T"
},
"90B-Vision": {
"hidden_size": 8192,
"num_hidden_layers": 80,
"num_attention_heads": 64,
"num_key_value_heads": 8,
"vocab_size": 128256,
"max_position_embeddings": 131072, # 128K上下文
"vision_config": {
"image_size": 560,
"patch_size": 14,
"num_channels": 3,
"hidden_size": 1280,
"intermediate_size": 5120,
"num_hidden_layers": 32,
"num_attention_heads": 16
},
"modalities": ["text", "image"],
"training_tokens": "~6T"
},
# 轻量级纯文本模型(边缘设备优化)
"1B": {
"hidden_size": 2048,
"num_hidden_layers": 16,
"num_attention_heads": 32,
"num_key_value_heads": 8,
"vocab_size": 128256,
"max_position_embeddings": 131072, # 128K上下文
"training_tokens": "~9T",
"optimizations": ["pruning", "quantization", "knowledge_distillation"]
},
"3B": {
"hidden_size": 3072,
"num_hidden_layers": 28,
"num_attention_heads": 24,
"num_key_value_heads": 8,
"vocab_size": 128256,
"max_position_embeddings": 131072, # 128K上下文
"training_tokens": "~9T",
"optimizations": ["pruning", "quantization", "knowledge_distillation"]
}
}
# LLaMA-3.2的突破性功能
llama32_features = {
"multimodal": "首次支持图像理解(11B/90B-Vision)",
"context_length": "128K tokens(所有模型)",
"edge_optimized": "1B/3B模型可在移动设备运行",
"training_data": "轻量级模型使用9T tokens",
"vision_capabilities": [
"图像描述与分析",
"图表和文档理解",
"视觉问答",
"图像推理"
],
"deployment": {
"1B": "智能手机、平板",
"3B": "笔记本电脑、边缘服务器",
"11B-Vision": "标准服务器、工作站",
"90B-Vision": "高性能服务器"
}
}关键创新
1. 多模态架构
python
class LLaMA32VisionArchitecture:
"""
LLaMA-3.2视觉模型架构
"""
components = {
"vision_encoder": "ViT-based (1280 hidden size)",
"cross_attention_layers": "每4层插入一次",
"image_token_limit": 5120, # 单图最大tokens
"max_images": 1, # 当前版本单图支持
"aspect_ratio_handling": "动态分辨率"
}- 超长上下文支持
- 所有LLaMA-3.2模型均支持128K tokens上下文窗口
- 是LLaMA-3的16倍提升(8K → 128K)
- 适用于长文档分析、大规模代码库理解
3. 边缘AI优化
python
edge_optimization_techniques = {
"1B/3B模型": {
"pruning": "结构化剪枝减少参数",
"quantization": "支持INT4/INT8量化",
"distillation": "从70B模型蒸馏知识",
"memory_footprint": {
"1B": "~1.2GB(INT4量化)",
"3B": "~2.8GB(INT4量化)"
},
"performance": {
"1B": "iPhone 15 Pro可流畅运行",
"3B": "Snapdragon 8 Gen 3可运行"
}
}
}性能对比
全面基准测试
python
def benchmark_llama_models():
"""
LLaMA系列模型性能对比
"""
benchmarks = {
"LLaMA-1-7B": {
"MMLU": 35.1,
"HumanEval": 10.5,
"GSM8K": 11.0,
"context": "2K"
},
"LLaMA-2-7B": {
"MMLU": 45.3,
"HumanEval": 12.8,
"GSM8K": 14.6,
"context": "4K"
},
"LLaMA-3-8B": {
"MMLU": 66.6,
"HumanEval": 62.2,
"GSM8K": 79.6,
"context": "8K"
},
"LLaMA-3.2-3B": {
"MMLU": 63.4,
"HumanEval": 54.8,
"GSM8K": 74.5,
"context": "128K",
"note": "轻量级模型,性能接近LLaMA-3-8B"
},
"LLaMA-3.2-11B-Vision": {
"MMLU": 73.0,
"HumanEval": 66.7,
"GSM8K": 83.4,
"MMMU": 50.7, # 多模态理解
"VQAv2": 75.2, # 视觉问答
"context": "128K"
},
"LLaMA-3.2-90B-Vision": {
"MMLU": 86.0,
"HumanEval": 75.8,
"GSM8K": 91.1,
"MMMU": 60.3,
"VQAv2": 82.9,
"context": "128K"
}
}
return benchmarks技术演进路线图
LLaMA-1 (2023.02)
↓
- 开源基础大模型
- 1T tokens训练
- 2K上下文
↓
LLaMA-2 (2023.07)
↓
+ GQA注意力机制
+ 2T tokens训练
+ 4K上下文
+ 对话优化(Chat版本)
↓
LLaMA-3 (2024.04)
↓
+ 128K词表优化
+ 15T tokens训练
+ 8K上下文
+ 多语言增强
+ 代码能力飞跃
↓
LLaMA-3.2 (2024.09)
↓
+ 多模态(Vision)
+ 128K超长上下文
+ 边缘设备优化(1B/3B)
+ 知识蒸馏技术GLM模型
GLM系列模型是智谱AI开发的主流中文LLM之一,包括ChatGLM-6B、ChatGLM2、ChatGLM3及GLM-4系列。GLM在中文LLM发展历程中具有独特的技术意义。
模型架构---相对于GPT的略微修正
python
# GPT使用Pre Norm(对比)
class GPTBlock:
"""
GPT的Decoder Block(Pre Norm)
"""
def forward(self, hidden_states):
# 1. LayerNorm + Self-Attention + 残差
residual = hidden_states
hidden_states = self.layer_norm1(hidden_states) # Pre Norm
attn_output = self.attention(hidden_states)
hidden_states = residual + attn_output
# 2. LayerNorm + FFN + 残差
residual = hidden_states
hidden_states = self.layer_norm2(hidden_states) # Pre Norm
ffn_output = self.ffn(hidden_states)
hidden_states = residual + ffn_output
return hidden_statesPost Norm vs Pre Norm的特点:
| 特性 | Post Norm | Pre Norm |
|---|---|---|
| 归一化位置 | 残差连接之后 | 子层计算之前 |
| 参数正则化 | 更强(所有参数都经过归一化) | 较弱(部分参数直接相加) |
| 训练稳定性 | 较差(深层模型易梯度消失/爆炸) | 较好(梯度流动更稳定) |
| 适用场景 | 较小规模模型 | 大规模深层模型 |
- 单个线性层实现最终预测:
python
class GLMOutput:
"""
GLM的输出层:使用单个线性层
"""
def __init__(self, hidden_size, vocab_size):
self.lm_head = nn.Linear(hidden_size, vocab_size, bias=False)
def forward(self, hidden_states):
# 直接映射到词表
logits = self.lm_head(hidden_states)
return logits
class GPTOutput:
"""
GPT的输出层:使用MLP(对比)
"""
def __init__(self, hidden_size, vocab_size):
self.mlp = nn.Sequential(
nn.Linear(hidden_size, hidden_size * 4),
nn.GELU(),
nn.Linear(hidden_size * 4, vocab_size)
)
def forward(self, hidden_states):
logits = self.mlp(hidden_states)
return logitsGLM使用单线性层的优势:
- 参数量更少
- 计算更高效
- 更加鲁棒
- 将更多参数分配给模型主体
- GELU激活函数:
GLM从ReLU换成GELU:
python
# ReLU vs GELU对比
import torch.nn.functional as F
def compare_activations(x):
"""
对比ReLU和GELU的激活效果
"""
relu_output = F.relu(x) # max(0, x)
gelu_output = F.gelu(x) # x * Φ(x), Φ是标准正态分布的CDF
return relu_output, gelu_output
# GELU的数学表达
def gelu_formula(x):
"""
GELU的数学公式
"""
return 0.5 * x * (1 + torch.tanh(
math.sqrt(2 / math.pi) * (x + 0.044715 * x**3)
))GELU的优势:
- 平滑的非线性变换
- 接近0的正值有连续性
- 更好的梯度流动
- 在实践中通常优于ReLU
预训练任务---GLM
GLM任务是结合自编码(MLM)和自回归(CLM)思想的预训练方法。
GLM任务的核心思想:
python
class GLMPretraining:
"""
GLM预训练任务实现
"""
def create_glm_sample(self, text):
"""
创建GLM训练样本
核心:遮蔽连续的token片段,而非单个token
"""
tokens = self.tokenize(text)
# 1. 随机选择要遮蔽的span
num_spans = random.randint(1, 3) # 遮蔽1-3个span
masked_spans = self.sample_spans(tokens, num_spans)
# 2. 构建输入序列
input_tokens = []
span_tokens = []
for i, token in enumerate(tokens):
if i in masked_spans:
if len(span_tokens) == 0 or span_tokens[-1]['end'] != i:
# 新的span开始
span_id = len(span_tokens)
input_tokens.append(f'[MASK{span_id}]')
span_tokens.append({'id': span_id, 'tokens': [token], 'start': i, 'end': i})
else:
# 继续当前span
span_tokens[-1]['tokens'].append(token)
span_tokens[-1]['end'] = i
else:
input_tokens.append(token)
# 3. 构建目标序列(按自回归方式重建每个span)
target_tokens = []
for span in span_tokens:
target_tokens.append(f"[MASK{span['id']}]")
target_tokens.extend(span['tokens'])
return {
'input': input_tokens,
'target': target_tokens
}
def sample_spans(self, tokens, num_spans):
"""
随机采样要遮蔽的连续token片段
"""
masked_indices = set()
for _ in range(num_spans):
# 随机选择起始位置
start = random.randint(0, len(tokens) - 1)
# 随机选择span长度(1-5个token)
span_length = random.randint(1, 5)
# 添加span中的所有索引
for i in range(start, min(start + span_length, len(tokens))):
masked_indices.add(i)
return masked_indices
# GLM训练示例
def glm_training_example():
"""
GLM训练示例
"""
text = "我爱自然语言处理技术"
# 创建GLM样本
sample = GLMPretraining().create_glm_sample(text)
print("原始文本:", text)
print("输入序列:", sample['input'])
# 可能输出: ['我', '[MASK0]', '语言', '[MASK1]', '技术']
print("目标序列:", sample['target'])
# 可能输出: ['[MASK0]', '爱', '自然', '[MASK1]', '处理']
# 训练过程
# 1. 模型看到上下文:['我', '[MASK0]', '语言', '[MASK1]', '技术']
# 2. 需要预测:['爱', '自然'] 和 ['处理']
# 3. 预测时采用自回归方式:
# - 预测'爱'时可以看到:'我'、'语言'、'技术'
# - 预测'自然'时可以看到:'我'、'爱'、'语言'、'技术'
# - 预测'处理'时可以看到:'我'、'爱'、'自然'、'语言'、'技术'GLM vs MLM vs CLM对比:
python
def compare_pretraining_tasks():
"""
对比三种预训练任务
"""
text = "我爱自然语言处理"
# MLM (BERT)
mlm_sample = {
'input': ['我', '[MASK]', '自然', '[MASK]', '处理'],
'target': {2: '爱', 4: '语言'}, # 独立预测每个被遮蔽的token
'context': '双向',
'prediction': '并行'
}
# CLM (GPT)
clm_sample = {
'input': ['我', '爱', '自然', '语言'],
'target': ['爱', '自然', '语言', '处理'], # 逐个预测下一个token
'context': '单向(从左到右)',
'prediction': '自回归'
}
# GLM
glm_sample = {
'input': ['我', '[MASK0]', '语言', '[MASK1]'],
'target': ['[MASK0]', '爱', '自然', '[MASK1]', '处理'],
'context': '双向(理解部分)+ 单向(生成部分)',
'prediction': '自回归(针对每个span)'
}
return {
'MLM': mlm_sample,
'CLM': clm_sample,
'GLM': glm_sample
}GLM的优势与局限:
优势:
- 结合了理解和生成能力
- 双向上下文理解
- 适配多种下游任务
局限:
- 在超大规模预训练中,CLM展现出更强的扩展性
- 训练复杂度高于纯CLM
python
# GLM的注意力掩码
class GLMAttentionMask:
"""
GLM的注意力掩码机制
"""
def create_glm_mask(self, input_tokens, target_tokens):
"""
创建GLM的attention mask
"""
total_len = len(input_tokens) + len(target_tokens)
mask = torch.ones(total_len, total_len)
input_len = len(input_tokens)
# 1. 输入部分可以双向attention
mask[:input_len, :input_len] = 1
# 2. 目标部分只能看到输入和之前的目标
for i in range(input_len, total_len):
mask[i, :i+1] = 1 # 因果掩码
mask[i, i+1:] = 0
# 3. 输入部分不能看到目标部分
mask[:input_len, input_len:] = 0
return maskGLM家族的发展
ChatGLM-6B(2023年3月):
第一个开源的中文LLM,采用GLM架构和预训练任务。
python
# ChatGLM-6B配置
chatglm_6b_config = {
"num_layers": 28,
"hidden_size": 4096,
"num_attention_heads": 32,
"vocab_size": 130528,
"max_sequence_length": 2048,
"pretraining_data": "1T tokens",
"architecture": "GLM",
"pretraining_task": "GLM (autoregressive blank filling)"
}ChatGLM2-6B(2023年6月):
重大升级,回归传统CLM架构。
python
# ChatGLM2-6B的改进
chatglm2_improvements = {
"context_length": 32768, # 从2K扩展到32K
"architecture": "Modified LLaMA", # 基本回归主流架构
"attention": "Multi-Query Attention (MQA)", # 引入MQA
"pretraining_task": "CLM", # 放弃GLM,采用传统CLM
"performance": "显著提升"
}
# MQA实现
class MultiQueryAttention:
"""
多查询注意力(MQA)
所有query头共享一组key和value
"""
def __init__(self, hidden_size, num_attention_heads):
self.num_heads = num_attention_heads
self.head_dim = hidden_size // num_attention_heads
# Q有多个头
self.q_proj = nn.Linear(hidden_size, hidden_size, bias=False)
# K和V只有一个头(共享)
self.k_proj = nn.Linear(hidden_size, self.head_dim, bias=False)
self.v_proj = nn.Linear(hidden_size, self.head_dim, bias=False)
self.o_proj = nn.Linear(hidden_size, hidden_size, bias=False)
def forward(self, hidden_states):
batch_size, seq_length, _ = hidden_states.shape
# Q: [batch, seq_len, num_heads, head_dim]
q = self.q_proj(hidden_states).view(
batch_size, seq_length, self.num_heads, self.head_dim
).transpose(1, 2)
# K, V: [batch, seq_len, 1, head_dim]
k = self.k_proj(hidden_states).unsqueeze(2)
v = self.v_proj(hidden_states).unsqueeze(2)
# 扩展K和V以匹配Q的头数
k = k.expand(-1, -1, self.num_heads, -1).transpose(1, 2)
v = v.expand(-1, -1, self.num_heads, -1).transpose(1, 2)
# 标准attention计算
attn_weights = torch.matmul(q, k.transpose(-2, -1)) / math.sqrt(self.head_dim)
attn_weights = F.softmax(attn_weights, dim=-1)
attn_output = torch.matmul(attn_weights, v)
attn_output = attn_output.transpose(1, 2).contiguous()
attn_output = attn_output.view(batch_size, seq_length, -1)
attn_output = self.o_proj(attn_output)
return attn_outputChatGLM3-6B(2023年10月):
进一步优化,支持工具调用。
python
# ChatGLM3的新特性
chatglm3_features = {
"performance": "语义、数学、推理、代码、知识显著提升",
"architecture": "与ChatGLM2基本一致",
"optimization": {
"training_data": "更多样化",
"training_steps": "更充足",
"training_strategy": "更优化"
},
"new_capabilities": [
"function_calling", # 函数调用
"code_interpreter", # 代码解释器
"agent_support" # Agent支持
]
}
# 函数调用示例
def chatglm3_function_calling_example():
"""
ChatGLM3的函数调用能力演示
"""
# 定义可用的工具
tools = [
{
"name": "get_weather",
"description": "获取指定城市的天气信息",
"parameters": {
"city": {"type": "string", "description": "城市名称"}
}
},
{
"name": "calculate",
"description": "执行数学计算",
"parameters": {
"expression": {"type": "string", "description": "数学表达式"}
}
}
]
# 用户查询
query = "北京今天天气怎么样?"
# 模型输出(包含工具调用)
model_output = {
"tool_calls": [
{
"name": "get_weather",
"arguments": {"city": "北京"}
}
]
}
# 执行工具
weather_result = get_weather(city="北京")
# 将结果返回给模型
final_response = model.generate_with_tool_result(
query=query,
tool_result=weather_result
)
return final_responseGLM-4(2024年1月):
最新的旗舰模型,支持128K上下文。
python
# GLM-4系列
glm4_family = {
"GLM-4": {
"context_length": 131072, # 128K
"performance": "达到GPT-4级别",
"status": "未直接开源"
},
"GLM-4-9B": {
"parameters": "9B",
"context_length": 8192,
"training_tokens": "10T",
"features": [
"支持GLM-4的所有工具功能",
"多语言能力",
"长文本理解",
"函数调用",
"All Tools"
],
"status": "开源",
"performance": "超越Llama-3-8B"
}
}
# GLM-4-9B的配置
class GLM4_9BConfig:
num_layers = 40
hidden_size = 4096
num_attention_heads = 32
num_key_value_heads = 2 # GQA
vocab_size = 151552
max_position_embeddings = 8192
rope_theta = 10000
use_cache = TrueGLM系列性能演进:
python
def glm_benchmark_evolution():
"""
GLM系列模型在基准测试上的性能演进
"""
benchmarks = {
"ChatGLM-6B": {
"C-Eval": 38.9,
"MMLU": 40.6,
"GSM8K": 23.1
},
"ChatGLM2-6B": {
"C-Eval": 51.7,
"MMLU": 47.9,
"GSM8K": 32.4
},
"ChatGLM3-6B": {
"C-Eval": 66.1,
"MMLU": 61.4,
"GSM8K": 72.3
},
"GLM-4-9B": {
"C-Eval": 75.6,
"MMLU": 72.4,
"GSM8K": 79.6,
"HumanEval": 71.8
}
}
return benchmarks参考资料
1 Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova. (2019). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv preprint arXiv:1810.04805.
2 Yinhan Liu, Myle Ott, Naman Goyal, et al. (2019). RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv preprint arXiv:1907.11692.
3 Zhenzhong Lan, Mingda Chen, Sebastian Goodman, et al. (2020). ALBERT: A Lite BERT for Self-supervised Learning of Language Representations. arXiv preprint arXiv:1909.11942.
4 Colin Raffel, Noam Shazeer, Adam Roberts, et al. (2023). Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. arXiv preprint arXiv:1910.10683.
5 Colin Raffel, Noam Shazeer, Adam Roberts, et al. (2020). Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. Journal of Machine Learning Research, 21(140), 1--67.
6 Alec Radford, Karthik Narasimhan. (2018). Improving Language Understanding by Generative Pre-Training.
7 Tom B. Brown, Benjamin Mann, Nick Ryder, et al. (2020). Language Models are Few-Shot Learners. arXiv preprint arXiv:2005.14165.
8 张帆, 陈安东. "万字长文带你梳理Llama开源家族:从Llama-1到Llama-3".
9 Team GLM, Aohan Zeng, Bin Xu, et al. (2024). ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools. arXiv preprint arXiv:2406.12793.
10 Zhengxiao Du, Yujie Qian, Xiao Liu, et al. (2022). GLM: General Language Model Pretraining with Autoregressive Blank Infilling. arXiv preprint arXiv:2103.10360.
总结
本章系统介绍了预训练语言模型的三大架构:
-
Encoder-Only(以BERT为代表):
- 擅长文本理解任务(NLU)
- 使用MLM和NSP预训练任务
- 通过双向注意力捕捉上下文
- 在分类、序列标注等任务上表现优异
-
Encoder-Decoder(以T5为代表):
- 统一处理理解和生成任务
- 采用文本到文本的大一统思想
- 适合序列到序列任务
- 灵活适配多种NLP任务
-
Decoder-Only(以GPT、LLaMA、GLM为代表):
- 天生适合文本生成任务(NLG)
- 使用CLM预训练任务
- 通过扩大规模展现涌现能力
- 成为当今大型语言模型的主流架构
随着模型规模的不断扩大和训练数据的持续增加,Decoder-Only架构逐渐成为主流,并在few-shot学习、指令跟随、推理能力等方面展现出强大的潜力。这为我们迈向AGI(通用人工智能)提供了重要的技术基础。