开源基础模型(FMs)已成为生成式 AI 创新的核心支柱,使组织能够构建和定制 AI 应用,同时保持对成本和部署策略的控制。通过提供高质量、公开可用的模型,AI 社区推动了快速迭代、知识共享和成本效益解决方案的发展,惠及开发者和终端用户。专注于 AI 技术研发的研究公司 DeepSeek AIEXTERN,EN 已成为该生态系统的重要贡献者。其 DeepSeek-R1EXTERN,EN 模型系列是一系列大型语言模型(LLMs),旨在处理广泛的任务,从代码生成到通用推理,同时保持有竞争力的性能和效率。
亚马逊云科技的 Bedrock 自定义模型导入 允许在现有 FMs 之外导入和使用自定义模型,通过单一的无服务器统一 API 实现。无需管理底层基础设施,即可按需访问导入的自定义模型。通过将受支持的自定义模型与 Bedrock 原生工具和功能(如知识库、防护措施和代理)集成,加速生成式 AI 应用开发 ------ 前端开发者可借此快速将模型能力嵌入到用户界面中,减少从模型部署到前端交互的开发周期。
本文探讨如何通过亚马逊云科技的 Bedrock 自定义模型导入功能部署 DeepSeek-R1 的蒸馏版本,让希望在安全、可扩展的基础设施内以高效成本使用最先进 AI 能力的组织能够轻松获取这些模型。
DeepSeek-R1 蒸馏变体
基于 DeepSeek-R1 的基础,DeepSeek AI 开发了一系列蒸馏模型。这些模型基于 Meta 的 Llama 和 Qwen 架构,参数规模从 15 亿到 700 亿不等。蒸馏过程包括训练更小、更高效的模型,以模仿更大的 DeepSeek-R1 模型(作为教师模型)的行为和思维模式。本质上,6710 亿参数模型的知识和能力被转移到更紧凑的架构中。
由此产生的蒸馏模型,如 DeepSeek-R1-Distill-Llama-8B(基于基础模型 Llama-3.1-8BEXTERN,EN)和 DeepSeek-R1-Distill-Llama-70B(基于基础模型 Llama-3.3-70B-InstructEXTERN,EN),在性能和资源需求之间取得了不同的平衡。尽管与原始 671B 模型相比,蒸馏模型的推理能力可能有所降低,但它们显著提高了推理速度并降低了计算成本。例如,像 8B 版本这样的小型蒸馏模型可以更快地处理请求,消耗更少的资源,使其在生产部署中更具成本效益。同时,像 70B 模型这样的大型蒸馏版本保持了更接近原始模型的性能,同时仍能显著提高效率 ------ 这对需要在前端应用中实现快速响应的开发者来说尤为重要,可提升用户交互体验。
解决方案概述
通过亚马逊云科技的 Bedrock 自定义模型导入功能部署 DeepSeek-R1 模型的蒸馏版本。重点介绍当前受支持的变体 DeepSeek-R1-Distill-Llama-8B 和 DeepSeek-R1-Distill-Llama-70B,它们在性能和资源效率之间实现了最佳平衡。
可以从 Amazon Simple Storage Service(Amazon S3)或 Amazon SageMaker AI 模型仓库导入这些模型,并通过 Amazon Bedrock 在完全托管的无服务器环境中部署。下图展示了端到端流程。
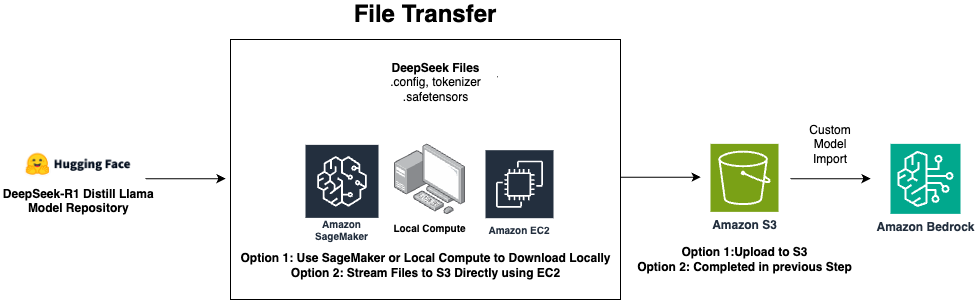
在此工作流中,存储在 Amazon S3 中的模型工件被导入到 Amazon Bedrock,然后 Bedrock 自动负责模型的部署和扩展。这种无服务器方法消除了基础设施管理的需求,同时提供企业级的安全性和可扩展性。前端开发者可通过统一 API 直接调用部署后的模型,无需关注后端基础设施细节,专注于构建直观的用户交互界面。
前提条件
需要满足以下前提条件:
- 一个可访问Amazon Bedrock 的亚马逊云科技账户。
- 适用于亚马逊云科技 Bedrock 和 Amazon S3 的 Amazon Identity and Access Management(IAM)角色和权限。
- 一个准备好存储自定义模型的 S3 存储桶。
- 足够的本地存储空间,8B 模型至少需要 17 GB,70B 模型至少需要 135 GB------ 这一步骤虽然主要涉及后端准备,但前端开发者也需了解模型规模对前端加载和交互延迟的潜在影响,以便优化用户体验。
准备模型包
执行以下步骤准备模型包:
- 从 Hugging Face 的以下链接之一下载 DeepSeek-R1-Distill-Llama 模型工件。根据要部署的模型选择链接:
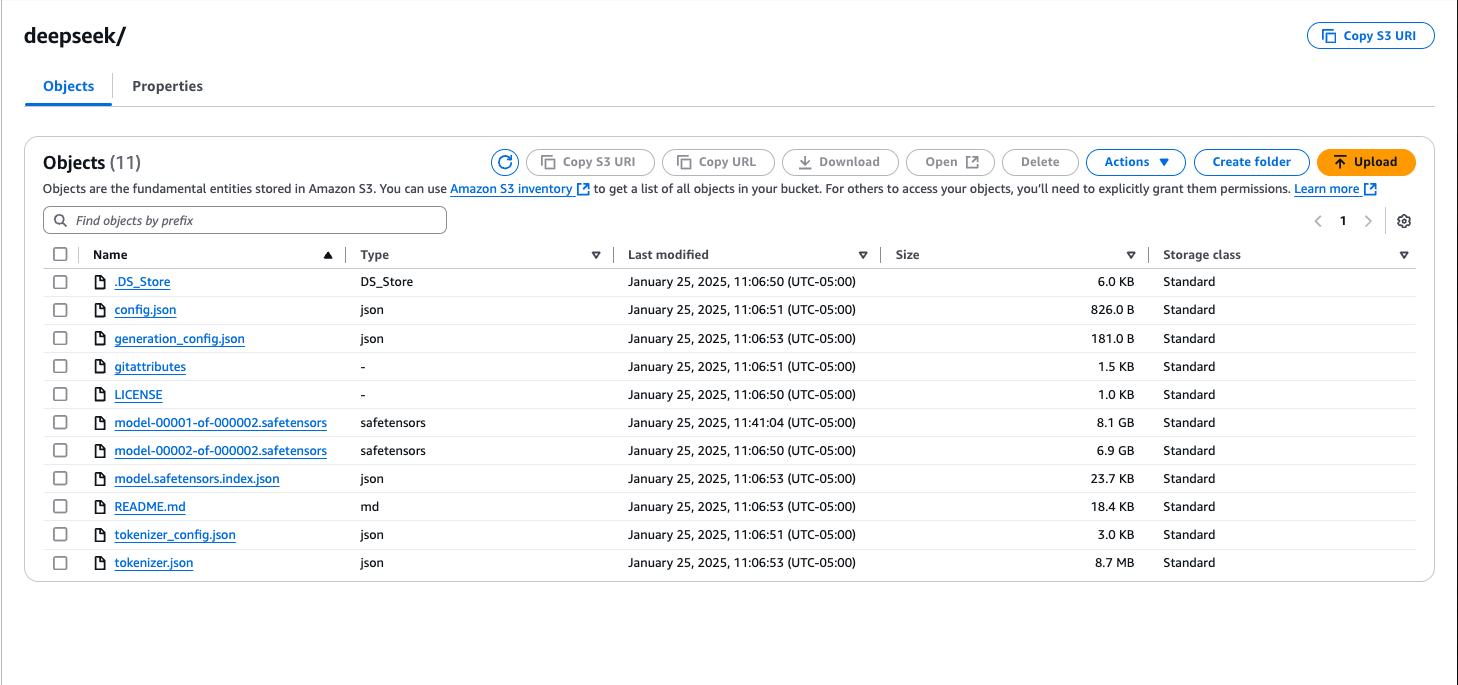
通常,需要以下文件:
- 模型配置文件:
<font style="background-color:rgb(187,191,196);">config.json</font> - 分词器文件:
<font style="background-color:rgb(187,191,196);">tokenizer.json</font>、<font style="background-color:rgb(187,191,196);">tokenizer.model</font>、<font style="background-color:rgb(187,191,196);">tokenizer_config.json</font>和<font style="background-color:rgb(187,191,196);">special_tokens_map.json</font> <font style="background-color:rgb(187,191,196);">.safetensors</font>格式的模型权重文件
- 将这些文件上传到的 S3 存储桶中与要使用 Amazon Bedrock 区域相同的文件夹中。然后记下使用的 S3 路径。
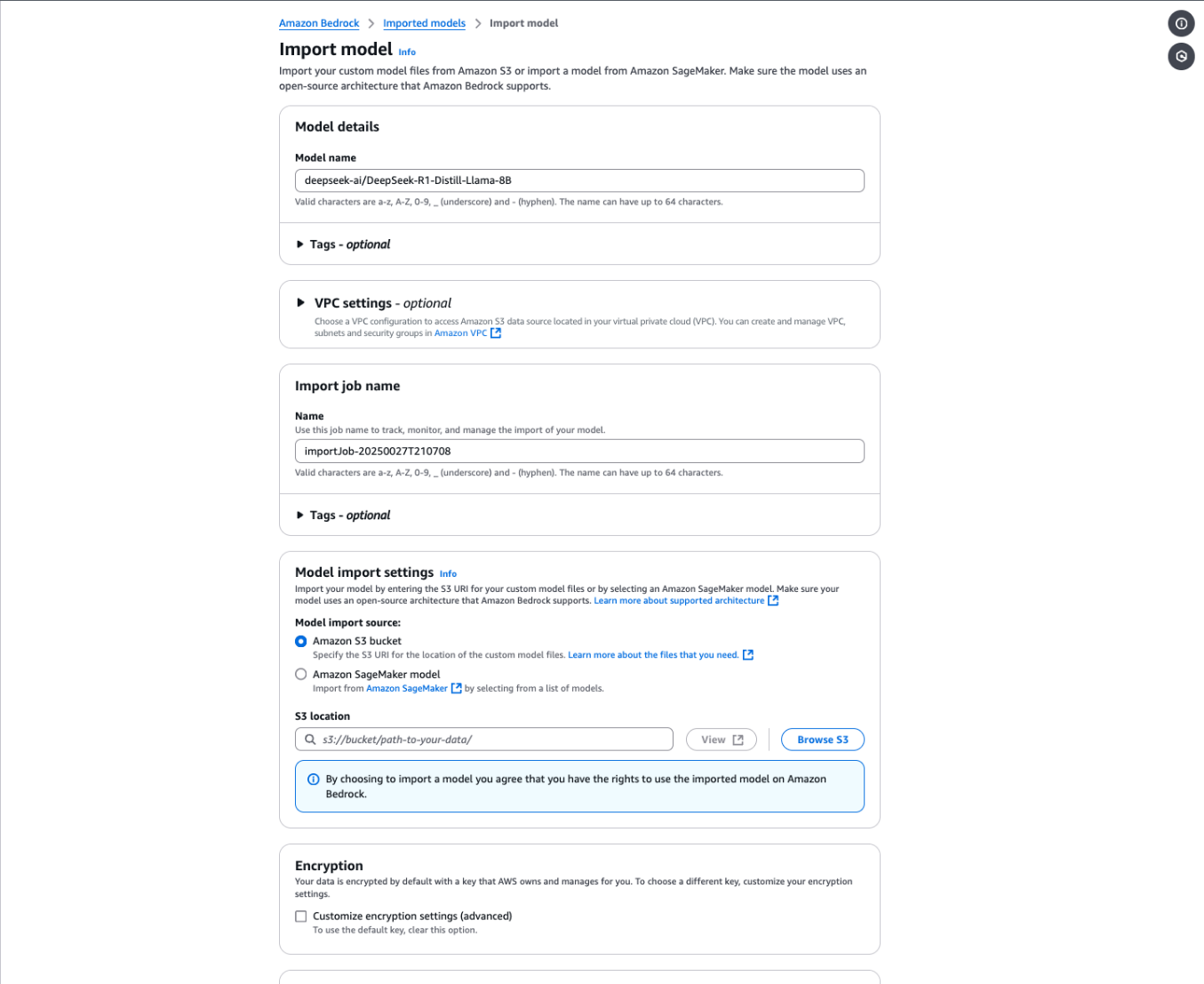
导入模型
执行以下步骤导入模型:
- 在亚马逊云科技 Bedrock 控制台的导航栏中,选择 Foundation models 下的 Imported models。
- 选择 Import model。
- 在 Model name 下,为的模型输入一个名称(建议在名称中使用版本控制方案,以跟踪导入的模型)。
- 在 Import job name 下,为的导入作业输入一个名称。
- 在 Model import settings 中,选择 Amazon S3 bucket 作为导入源,并输入之前记下的 S3 路径(以
<font style="background-color:rgb(187,191,196);">s3://<your-bucket>/folder-with-model-artifacts/</font>形式输入完整路径)。 - 在 Encryption 下,可选择自定义加密设置。
- 在 Service access role 下,选择创建新的 IAM 角色或指定自己的角色。
- 选择 Import model。
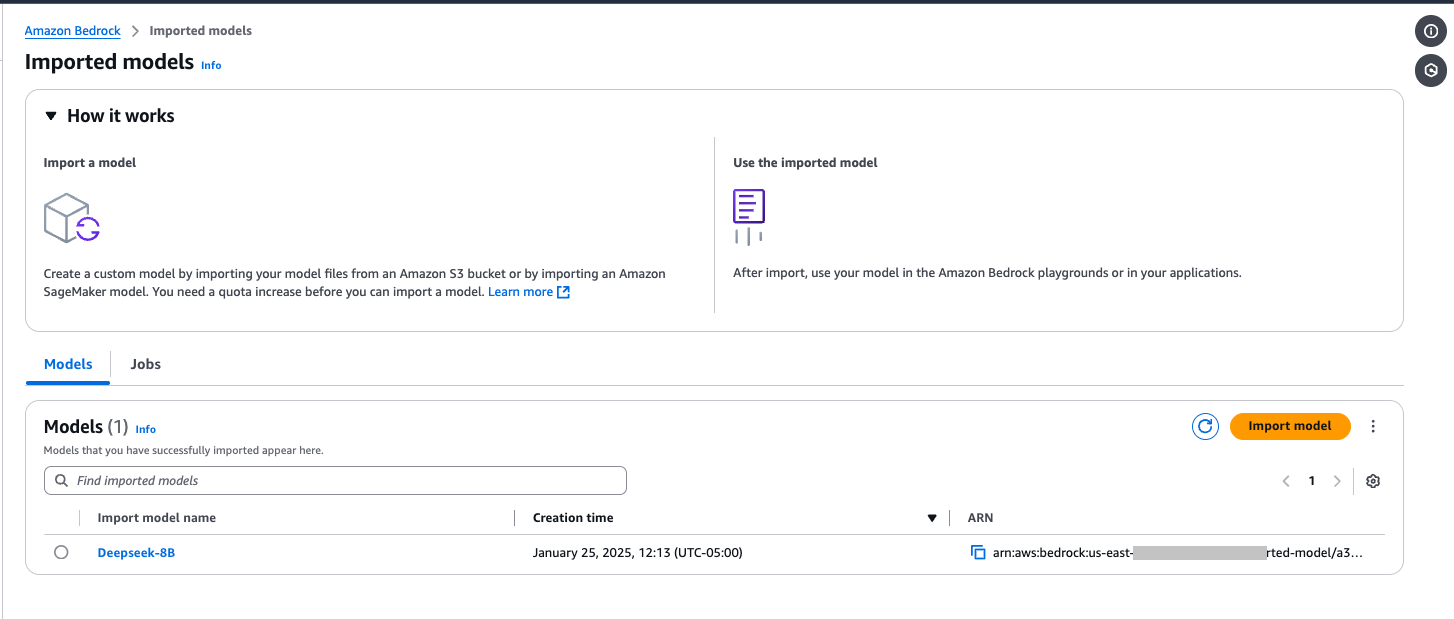
模型导入时间因导入的模型而异,可能需要几分钟(例如,Distill-Llama-8B 模型可能需要 5-20 分钟才能完成)。
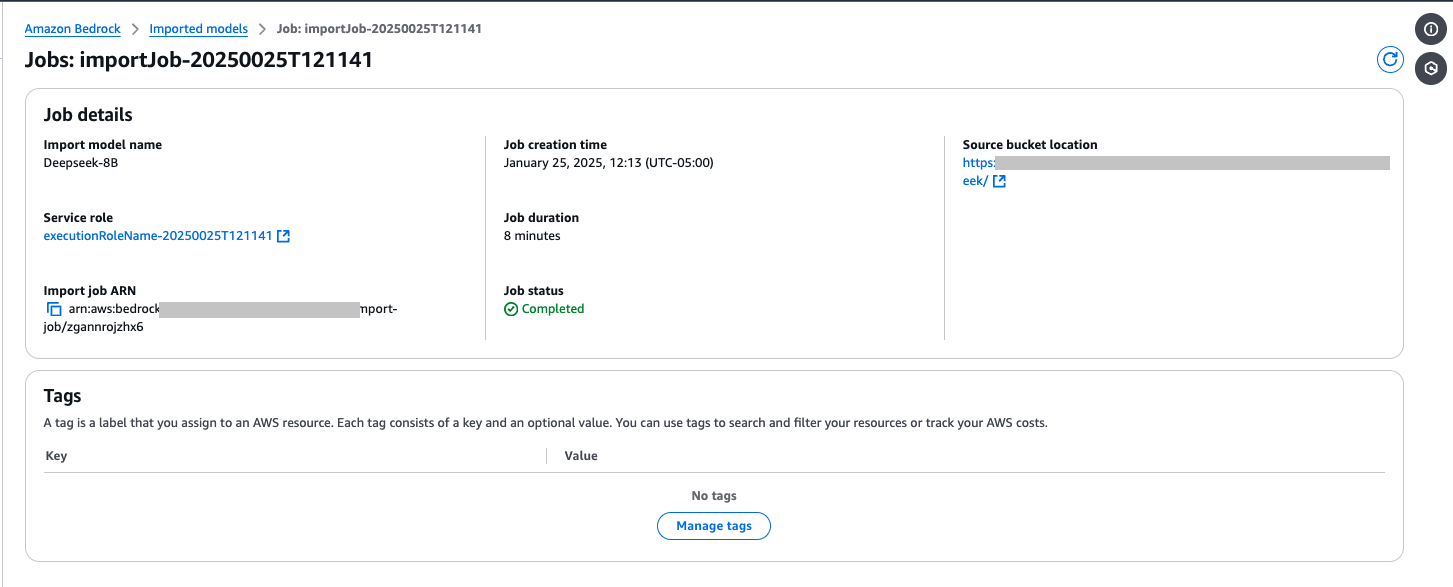
测试导入的模型
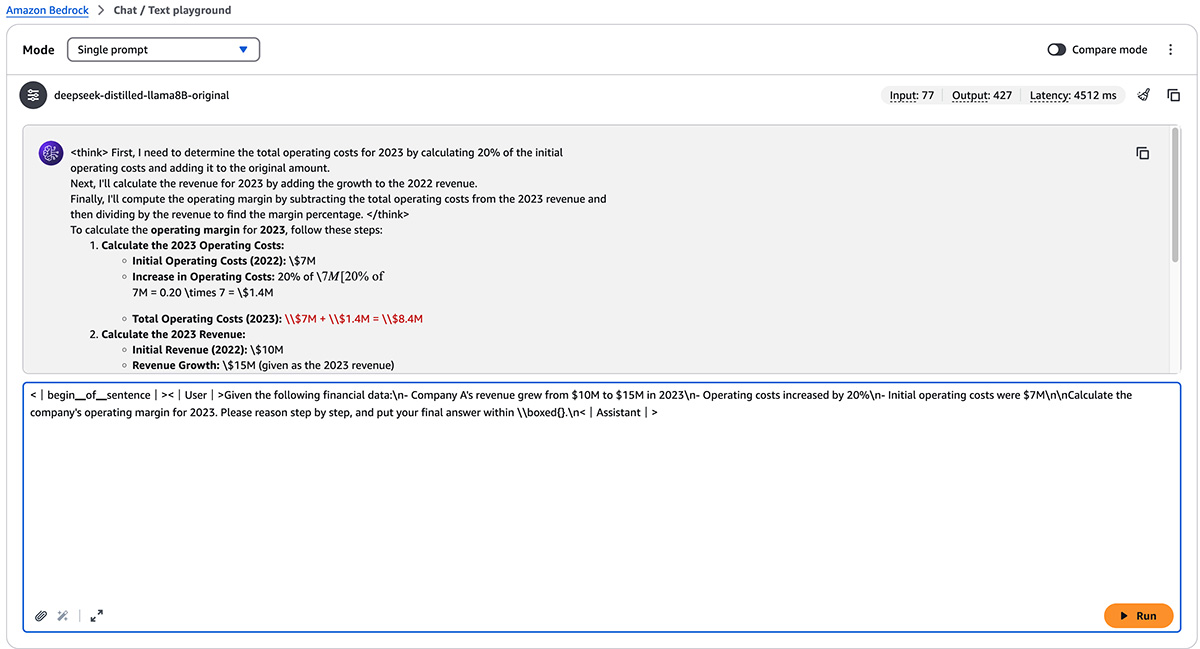
导入模型后,可以使用亚马逊云科技的 Bedrock Playground 或直接通过亚马逊云科技的 Bedrock 调用 API 进行测试。要使用 Playground,请执行以下步骤:
- 在亚马逊云科技 Bedrock 控制台的导航栏中,选择 Playgrounds 下的 Chat / Text。
- 从模型选择菜单中选择导入的模型名称。
- 根据需要调整推理参数并编写测试查询。例如:
<font style="background-color:rgb(187,191,196);"><|begin▁of▁sentence|><|User|>Given the following financial data: - Company A's revenue grew from $10M to $15M in 2023 - Operating costs increased by 20% - Initial operating costs were $7M Calculate the company's operating margin for 2023. Please reason step by step, and put your final answer within \\boxed{}<|Assistant|></font>
由于在 Playground 中使用导入的模型,需要添加 "beginning_of_sentence" 和 "user/assistant" 标签,以正确格式化 DeepSeek 模型的上下文;这些标签帮助模型理解对话结构并提供更准确的响应。如果遵循 以下笔记本EXTERN,EN 中的编程方法,模型配置会自动完成此操作 ------ 前端开发者可基于此 API 封装前端请求逻辑,实现与用户输入的无缝对接。
- 检查模型响应和提供的指标。
注意 :如果在首次运行模型时遇到 <font style="background-color:rgb(187,191,196);">ModelNotReadyException</font> 错误,SDK 会自动使用指数退避重试请求。恢复时间因按需集群规模和模型大小而异。可以使用 Amazon SDK for Python (Boto3) 配置对象调整重试行为。
前端同学的小烦恼?试试这个!
很多前端开发者想转全栈或后端,但一提到 "服务器" 就犯怵:本地搭个 Node 服务还行,真要操作云服务器,要么怕复杂,要么觉得租服务器贵,迟迟不敢下手。用亚马逊云服务器有个好处,新用户前半年Free!
对想练手服务端开发的前端同学来说,这简直是量身定做的练习场,不用花一分💰,就能体验真实的云服务器环境,部署个 Express 后端、试试数据库交互,甚至搭个完整的前后端项目。
对公司来说也很合适:如果想换云服务商,先用免费额度试点跑一跑,看看流程顺不顺,再决定要不要全面迁移,成本几乎为零。

基准测试
DeepSeek 发布了基准测试EXTERN,EN,将其蒸馏模型与模型仓库中可用的原始 DeepSeek-R1 和基础 Llama 模型进行了比较。基准测试表明,根据任务的不同,DeepSeek-R1-Distill-Llama-70B 保留了原始模型 80-90% 的推理能力,而 8B 版本在资源需求显著降低的情况下达到了 59-92% 的性能。两种蒸馏版本在特定推理任务中都比其相应的基础 Llama 模型有所改进 ------ 这意味着前端开发者可以根据应用场景选择合适的模型,在保证用户体验的同时控制成本。
其他注意事项
在亚马逊云科技 Bedrock 中部署 DeepSeek 模型时,请考虑以下方面:
- 模型版本控制至关重要。由于自定义模型导入为每次导入创建独特的模型,因此请在模型名称中实施清晰的版本控制策略,以跟踪不同版本和变体 ------ 前端开发者需与后端团队同步版本信息,确保调用的模型版本与应用功能匹配。
- 当前支持的模型格式主要集中在基于 Llama 的架构。尽管 DeepSeek-R1 的蒸馏版本表现出色,但 AI 生态系统正在快速发展。请关注亚马逊云科技 Bedrock 模型目录,因为新的架构和更大的模型将通过该平台提供。
- 仔细评估的应用场景需求。尽管像 DeepSeek-R1-Distill-Llama-70B 这样的大型模型提供更好的性能,但 8B 版本可能以更低的成本为许多应用提供足够的能力 ------ 前端开发者可通过 A/B 测试,验证不同模型在实际用户交互中的表现。
- 考虑实施监控和可观测性。亚马逊云科技 CloudWatch 提供导入模型的指标,帮助跟踪使用模式和性能。可以使用 Amazon Cost Explorer 监控成本 ------ 前端团队可结合用户行为数据,分析模型调用效率与用户体验的关联。
- 从较低的并发配额开始,根据实际使用模式进行扩展。每个账户 3 个并发模型副本的标准限制适用于大多数初始部署。
总结
亚马逊云科技 Bedrock 自定义模型导入使组织能够使用强大的公开可用模型(如 DeepSeek-R1 的蒸馏版本等),同时受益于企业级基础设施。Amazon Bedrock 的无服务器特性消除了模型部署和运营管理的复杂性,使团队能够专注于应用开发而非基础设施 ------ 这对前端开发者尤为友好,可将更多精力投入到用户界面设计和交互体验优化上。
凭借自动扩展、基于使用量的定价以及与亚马逊云科技服务的无缝集成,Amazon Bedrock 为 AI 工作负载提供了生产级环境。DeepSeek 的创新蒸馏方法与 Amazon Bedrock 的托管基础设施相结合,在性能、成本和运营效率之间取得了最佳平衡。组织可以从小型模型开始,根据需要进行扩展,同时保持对模型部署的完全控制,并受益于亚马逊云科技的安全和合规能力。
在Amazon Bedrock 中选择专有和开源 FMs 的能力为组织提供了优化特定需求的灵活性。开源模型支持具有成本效益的部署,并能完全控制模型工件,使其成为需要定制、成本优化或模型透明度的场景的理想选择。这种灵活性与Amazon Bedrock 的统一 API 和企业级基础设施相结合,使组织能够构建能够适应不断变化的需求的强大 AI 战略。