目录
一 、 ETL计算引擎定义
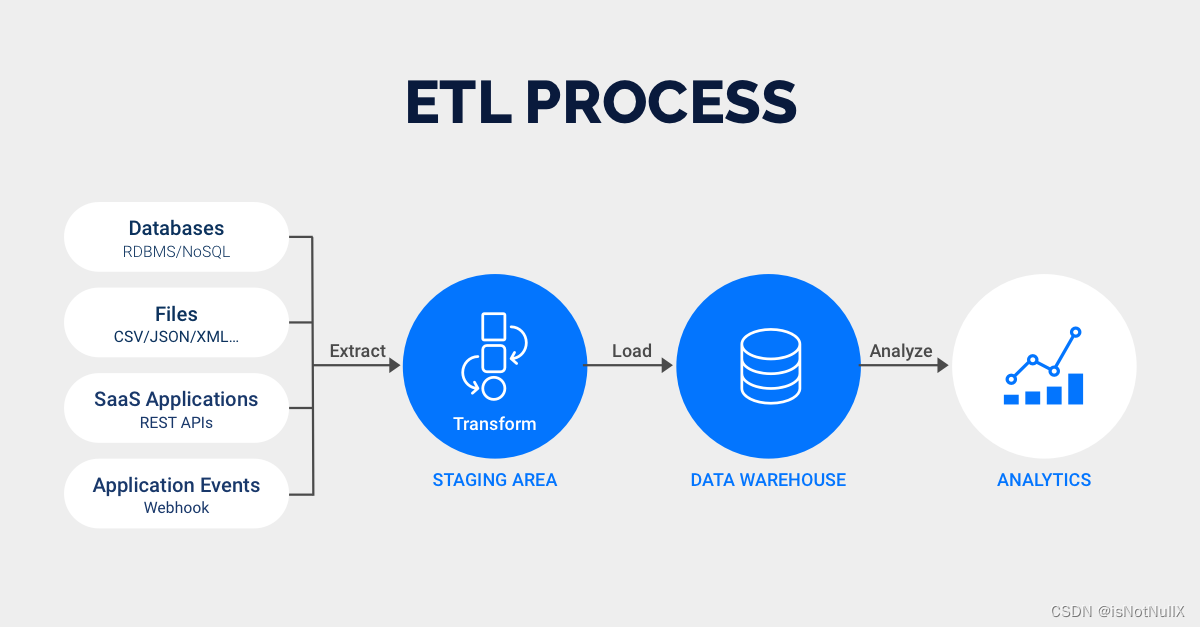
ETL(Extract, Transform, Load)计算引擎是用于执行ETL过程中数据转换阶段的关键组件之一。它负责处理从不同数据源抽取的数据,并根据预定义的转换规则进行数据的清洗、整合、计算和格式化等操作,最终将处理后的数据加载到目标系统(如数据库、数据仓库等)中。ETL计算引擎是ETL过程中的核心技术组件,通过其强大的数据处理能力和功能特性,可以实现从多源数据提取、转换到加载目标系统的全流程数据管理和处理。
二、ETL计算引擎的功能和特性
1.数据清洗和验证 :
对从源系统抽取的数据进行清洗,确保数据的准确性和一致性。这可能包括去除重复数据、处理缺失值、统一数据格式等操作。
2.数据转换 :
根据预定义的业务逻辑和转换规则,对数据进行转换和计算。例如,可以进行数据格式化、计算衍生字段、进行数学运算或逻辑运算等。
3.数据映射和重构 :
将来自不同数据源的数据映射到目标系统的数据模型中。这可能涉及到对数据结构进行重构,以适应目标系统的数据模式。
4.性能优化 :
处理大量数据时,ETL计算引擎需要具备高效的性能和处理能力,以确保数据转换和加载的速度和效率。
5.任务调度和监控 :
管理和监控ETL任务的执行,包括调度任务的执行时间、任务失败时的错误处理以及实时监控任务执行状态等功能。
6. 容错和恢复能力 :
在处理过程中,ETL计算引擎需要具备容错机制,以应对突发情况或异常,确保数据处理的稳定性和完整性。
7.扩展性和灵活性 :
支持多种数据源和目标系统,以及灵活的配置选项和定制化需求,以满足不同业务场景下的数据处理要求。
三 、6 种ETL计算引擎
1、MapReduce
MapReduce是一种用于处理大规模数据集的并行计算模型,通常运行在Hadoop等分布式计算平台上,能够处理数十亿条记录和数百台计算机组成的大规模数据集。MapReduce采用"分而治之"策略,将一个存储在分布式文件系统中的大规模数据集切分成许多独立的分片,这些分片可以被多个Map任务并行处理。Map和Reduce函数可以由用户自定义实现,这样MapReduce可以适用于各种不同的计算任务。
然而,MapReduce模型也存在以下缺陷:
1. 抽象层次较低:开发者需要手工完成大量的底层逻辑,这使得开发变得复杂且难以维护。
2. 只提供Map和Reduce操作:许多现实中的场景并不适用于该模型,实现复杂的操作需要技巧,从而导致整个工程庞大且难以维护。
3. 系统延迟:Hadoop中每个Job的计算结果都存储在HDFS中,每次计算都需要进行硬盘的读取和写入,导致系统延迟增加。
因此,随着大数据场景不断发展,一些新的计算框架模型也正在逐渐浮出水面,例如下面将要介绍的Apache Spark、Apache Flink等。这些框架模型推动了大数据处理的快速、高效和灵活发展,并且正在逐步替代MapReduce。

MapReduce 工作流程
2、Tez
Hadoop虽然能处理大规模数据且具有良好的水平扩展性,但对用户而言使用难度仍然很大。因此,Hive的出现恰好解决了这个问题,这使得Hive被迅速推广并成为大数据时代数据仓库组件的代名词。
Hive使用HDFS作为存储,使用MapReduce作为计算引擎。
为了解决Hive执行性能太差的问题,在计算引擎方面出现了Tez。
Tez是一款开源的计算框架,支持DAG(有向无环图,Directed Acyclic Graph)作业。Tez将Map/Reduce过程拆分成若干个子过程,并可以将多个Map/Reduce任务组合成一个较大的DAG任务,减少了Map/Reduce之间的文件存储,并且通过合理组合子过程,可以减少任务的运行时间。加上内存计算,Tez的计算性能实际上可以与Spark相媲美。
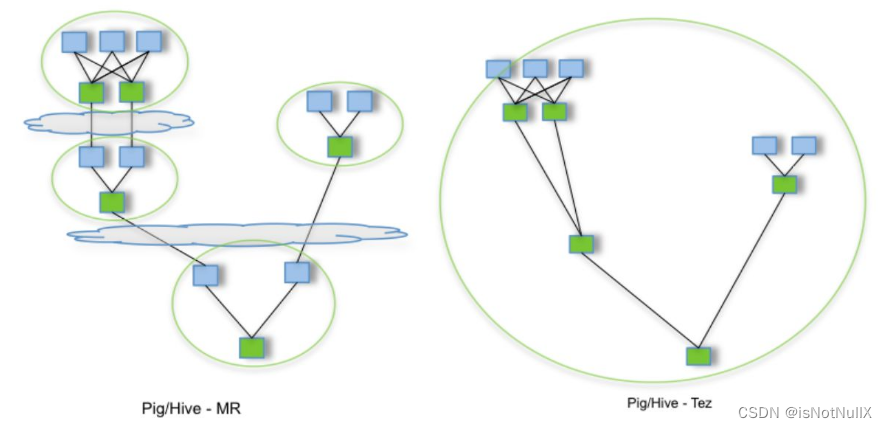
MR 与 Tez 的比较
3、Spark
Apache Spark是一个以速度、易用性和复杂分析为基础的大数据处理框架。Apache Spark具有广泛的应用场景,包括:
1. 离线计算:使用算子或SQL执行大规模批处理,对标MapReduce、Hive。同时提供了对各种数据源的读写支持。
2. 实时处理:以一种微批的方式,使用各种窗口函数对流式数据进行实时计算。主要实现在这两部分:Spark Streaming、Structured Streaming(Spark 2.3版本推出)。
3. MLlib:一个常用的机器学习算法库,算法被实现为对RDD的Spark操作。该库包含各种可扩展的学习算法,例如分类、回归等需要对大量数据集进行迭代操作的算法。
4. GraphX:控制图、并行图操作和计算的一组算法和工具的集合。GraphX扩展了RDD API,包含控制图、创建子图、访问路径上所有顶点的操作等。
SparkUI Stage 页面
在Spark中,内置的数据结构有RDD、DataFrame和DataSet,其中:
**1. RDD:**弹性分布式数据集,它代表一个可以被分区(partition)的只读数据集,内部可以有很多分区,每个分区又有大量的数据记录(record)。RDD是已被分区、不可变的数据集,可以被并行操作。
**2. DataFrame:**可以被视为一种特殊的DataSet。
**3. DataSet:**Spark 1.6版本引入的接口,类似于关系型数据库中的表,提供数据表的schema信息,比如列名、列数据类型等。
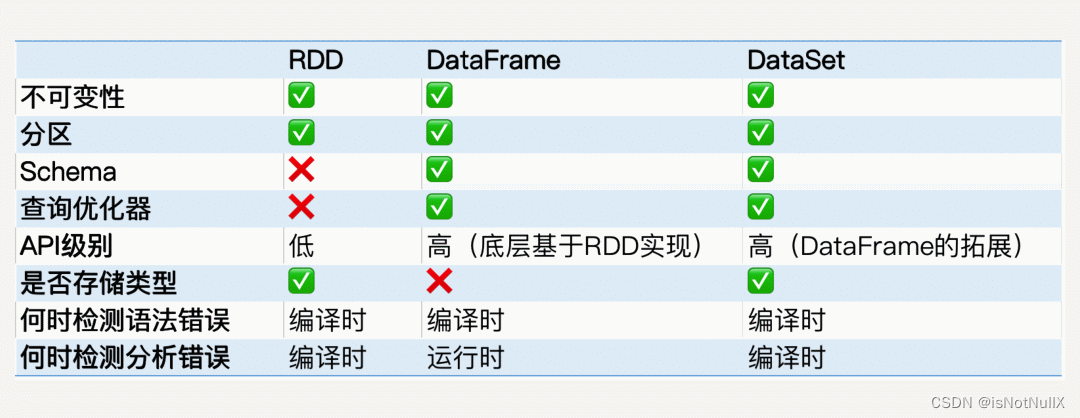
RDD、DataFrame、DataSet 对比
4、Flink
Flink是一个强大而灵活的分布式数据处理框架,被广泛地应用于流式数据处理和批处理任务,并且具有许多优点,如高性能、低延迟、强大的容错性、支持多种数据源和格式、易于使用等等。Flink的架构设计基于基于流的数据流和基于批处理的数据集两个API,这使得它非常灵活,可以适应各种数据处理任务的需求。Flink提供了多种高抽象层的API用于分布式任务的编写,如:
1. DataSet API:用于处理静态数据的批处理操作,将静态数据抽象成分布式的数据集。用户可以方便地使用Flink提供的各种操作符对分布式数据集进行处理。支持Java、Scala和Python编程语言。
2. DataStream API:用于处理数据流的流处理操作,将流式的数据抽象成分布式的数据流。用户可以方便地进行各种操作来处理分布式数据流。支持Java和Scala。
3. Table API:用于查询结构化数据,将结构化数据抽象成关系表,并通过类SQL的DSL对关系表进行各种查询操作。支持Java和Scala。
4. Flink ML:Flink的机器学习库。
5. Gelly:Flink的图计算库,提供了与图计算相关的API和多种图计算算法实现。
这些API可以帮助用户更轻松地编写各种分布式任务,从而更方便地处理数据,并支持众多的编程语言和计算领域。此外,Flink还提供了丰富的可扩展性和自定义性,使用户能够轻松地根据自己的需求进行更深入的定制和优化。
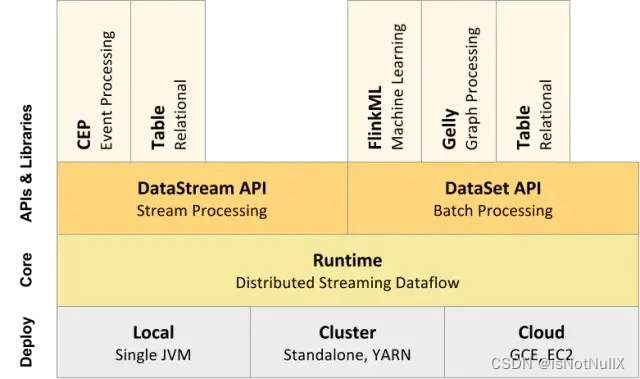
Flink 组件栈
Flink相对于Spark,具有其独特的优势,比如更高层次的抽象、更简洁的调用方式、高的吞吐,更少的资源占用等。但是Flink想要完全超越Spark,还有一些问题需要解决,如SQL的支持、批流一体的实现、机器学习、图计算等等。
对于数据开发者来说,Spark相比于MapReduce支持的场景更广,使用起来也更加容易。而Flink相比于Spark同样更易用。所以未来大数据开发的门槛将会越来越低,如完全SQL化、低代码等技术的发展,甚至会像传统ETL工具一样无代码。大数据从业者需要跟上技术的发展趋势,不断更新自己的技术知识,并不断提高自己的技能和能力,以适应未来大数据行业的发展。
5、ClickHouse
ClickHouse是俄罗斯搜索引擎公司Yandex于2016年开源的一款数据分析MPP数据库。作为数据库,它在计算层面采用了许多技术,如单机多核并行、分布式计算、向量化执行、SIMD指令、代码生成等,以提高查询速度。在普通的大数据集群中,ClickHouse可以在几秒钟内查询十几亿条数据,因此在许多即席查询场景中被广泛使用。
ClickHouse具有成熟的稳定性和高性能,可以用于处理海量数据。但是,使用ClickHouse需要掌握特定的技术,调优也比较复杂,因此需要有相应的经验和技能。但是,随着越来越多人对此感兴趣和认可,ClickHouse也成为了大数据处理的一个重要工具之一。
ClickHouse界面
6、Doris
ClickHouse是一个非常优秀的产品,但也有一些缺点。比如,ClickHouse过度依赖大宽表,较难应对高并发的业务场景,而且并不完全支持标准SQL和UDF等,同时ClickHouse的集群运维也是比较复杂的,需要一定的经验和技能。Apache Doris的诞生试图解决这些问题,使得大数据查询和分析更加容易和高效。
Apache Doris是一个现代化的MPP分析型数据库产品,由百度开源并贡献给Apache社区,具有以下特点:
**1. 响应时间短。**Apache Doris的响应时间非常短,仅需要亚秒级的时间即可获得查询结果,因此能够有效地支持实时数据分析。
**2. 架构简洁,扩展性高。**Apache Doris的分布式架构非常简洁,易于运维,并且具备很高的扩展性,可以支持10PB以上的超大数据集。
**3. 满足多种数据分析需求。**Apache Doris可以满足多种数据分析需求,例如固定历史报表、实时数据分析、交互式数据分析和探索式数据分析等。
**4. 支持多种数据源。**Apache Doris支持多种数据源和多种数据格式的导入和导出,还提供了灵活的数据模型,支持多维数据分析、多维度数据查询和跨表联合查询。
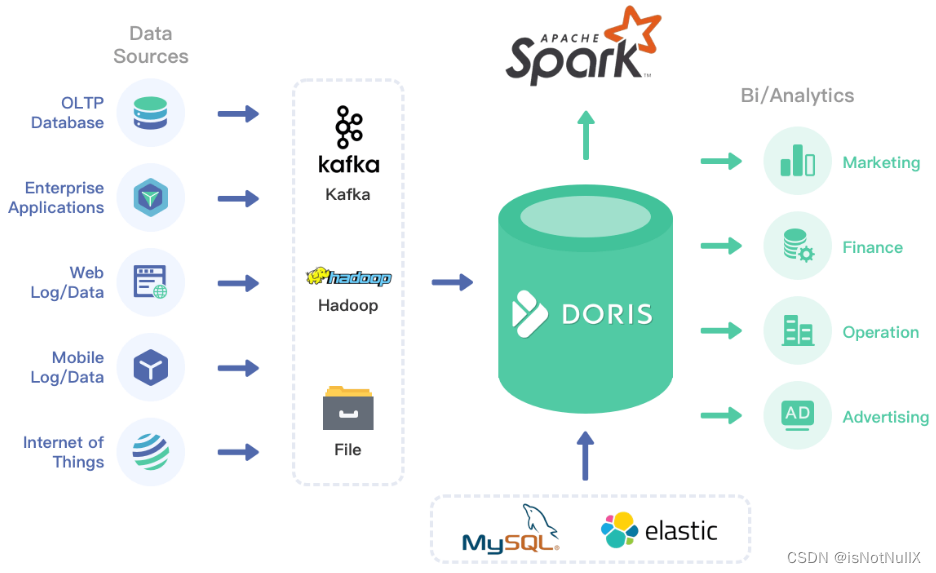
Doris 示意图
在以上6种ETL计算引擎中,ClickHouse和Apache Doris都是MPP分析型数据库产品。帆软推出的FineDataLink是一款ETL工具,同时也是一个数据集成平台,可以对接ClickHouse、Doris、StarRocks等MPP数据库,这使得数据开发工程师在"从常规数据库到大数据转移"阶段------实现"ETL零学习成本",也使得企业拥有高性能存储的同时具备轻松驾驭数据洞察力,从数据集成到BI自主分析。
FDL功能体验请点击:FineDataLink功能体验
往期内容推荐:
「ETL趋势」FDL数据开发支持版本管理、实时管道支持多对一、数据源新增支持神通-CSDN博客