前言
查询的sql的结构是
select...from...where...group by...having...order by...limit...
写查询sql的时候需要按照如下顺序写
from,where(and,or,!=),group by,select,having,order by,limit
关键字
having
where相当于对group by过滤前;having相当于对group by过滤后的数据再进行过滤;
order by
存在对单个列排序也存在多个列排序;
默认是正序排序,加上desc为逆序排序。
limit
limit 1,2;代表从第一行开始取,取两行
case when
类比if else;
写在select和from之间,相当于作为查询出来的表的列名。
格式:
case when 表达式
then 输出
when 表达式
then 输出
else 输出增删改
插入
汇总
插入记录的方式汇总:
普通插入(全字段):
INSERT INTO table_name VALUES (value1, value2, ...)
普通插入(限定字段):
INSERT INTO table_name (column1, column2, ...) VALUES (value1, value2, ...)
多条一次性插入:
INSERT INTO table_name (column1, column2, ...) VALUES (value1_1, value1_2, ...), (value2_1, value2_2, ...), ...
从另一个表导入:
INSERT INTO table_name SELECT * FROM table_name2 [WHERE key=value]
带更新的插入:
REPLACE INTO table_name VALUES (value1, value2, ...) (注意这种原理是检测到主键或唯一性索引键重复就删除原记录后重新插入)
基本插入
insert into
exam_record (uid, start_time, submit_time, exam_id, score)
values
(1001, '2021-09-01 22:11:12',
'2021-09-01 22:11:12' + interval 50 minute,
9001,
90
),
(1002, '2021-09-04 07:01:02', null, 9002, null);
条件插入
insert into
exam_record_before_2021
select
null,
uid,
exam_id,
start_time,
submit_time,
score
from
exam_record
where
year (submit_time) < 2021更新插入
ID列有唯一性索引,自增主键可直接设置为NULL或0或DEFAULT:
replace into examination_info
values
(
NULL,
9003,
"SQL",
"hard",
90,
"2021-01-01 00:00:00"
);
当然也可以限定字段插入,写作:
REPLACE INTO examination_info(exam_id,tag,difficulty,duration,release_time) VALUES
(9003, "SQL", "hard", 90, "2021-01-01 00:00:00");
更新
汇总
更新记录的方式汇总:
设置为新值:
UPDATE table_name SET column_name=new_value [, column_name2=new_value2] [WHERE column_name3=value3]
根据已有值替换:
UPDATE table_name SET key1=replace(key1, '查找内容', '替换成内容') [WHERE column_name3=value3]
设置为新值
只改2021年9月1日之前开始作答的记录;
只改未完成的记录;
改为被动完成:完成时间改为'2099-01-01 00:00:00',分数改为0
update
exam_record
set
submit_time = '2099-01-01 00:00:00',
score = 0
where
start_time < '2021-09-01'
and score is NULL;根据已有值替换
- tag为PYTHON的tag字段全部修改为Python
第一种:
UPDATE examination_info
SET tag = "Python"
WHERE tag = "PYTHON";
第二种:
UPDATE examination_info
SET tag = REPLACE(tag, "PYTHON", "Python")
WHERE tag = "PYTHON";
第二种方式不仅可用于整体替换,还能做子串替换,例如要实现将tag中所有的PYTHON替换为Python(如CPYTHON=>CPython),可写作:
UPDATE examination_info
SET tag = REPLACE(tag, "PYTHON", "Python")
WHERE tag LIKE "%PYTHON%";
删除
汇总
删除记录的方式汇总:
根据条件删除:
DELETE FROM tb_name [WHERE options] [ [ ORDER BY fields ] LIMIT n ]
全部删除(表清空,包含自增计数器重置):
TRUNCATE table tb_name
时间差:
TIMESTAMPDIFF(interval, time_start, time_end)可计算time_start-time_end的时间差,单位以指定的interval为准,常用可选:SECOND 秒
MINUTE 分钟(返回秒数差除以60的整数部分)
HOUR 小时(返回秒数差除以3600的整数部分)
DAY 天数(返回秒数差除以3600*24的整数部分)
MONTH 月数
YEAR 年数根据条件删除
作答时间小于5分钟整的记录;分数不及格(及格线为60分)的记录;
delete from
exam_record
where
timestampdiff (minute, start_time, submit_time) < 5
and score < 60;未完成作答的记录;或作答时间小于5分钟整的记录;开始作答时间最早的3条记录;
delete from
exam_record
where
submit_time is NULL
or timestampdiff (minute, start_time, submit_time) < 5
order by
start_time
limit
3;全部删除
删除exam_record表中所有记录;并重置自增主键;
truncate table exam_record;表与索引
表
汇总
表的创建:
1.直接创建表:
2.从另一张表复制表结构创建表:
create table tb_name like tb_name_old
3.从另一张表的查询结果创建表:
create table tb_name as select * from tb_name_old where options表的修改:
alter table user_info add school varchar(15) after level;
增加列在某列之后
alter table 增加的表格 add 增加列的名称 数据类型 位置(after level 在level 之后)
alter table user_info change job profession varchar(10);
更换列的名称及数据类型
alter table user_info change 原列名 修改列名 修改数据类型
alter table user_info modify achievement int(11) default 0;
更改数据类型
alter table 表名 modify 修改列名称 数据类型 默认值等表的删除:
drop table [if exists] table_name;创建一张新表
自增ID:AUTO_INCREMENT;
设置主键:PRIMARY KEY;
唯一性约束:UNIQUE
非空约束:NOT NULL
设置默认值:DEFAULT 0
当前时间戳:CURRENT_TIMESTAMP
评论/注释:COMMENT
如果该表已创建过,正常返回:IF NOT EXISTS
CREATE TABLE IF NOT EXISTS user_info_vip (
id int PRIMARY KEY AUTO_INCREMENT COMMENT '自增ID',
uid int UNIQUE NOT NULL COMMENT '用户ID',
nick_name varchar(64) COMMENT '昵称',
achievement int DEFAULT 0 COMMENT '成就值',
`level` int COMMENT '用户等级',
job varchar(32) COMMENT '职业方向',
register_time datetime DEFAULT CURRENT_TIMESTAMP COMMENT '注册时间'
) CHARACTER SET utf8 COLLATE utf8_general_ci;修改一张表
字段level的后面增加一列最多可保存15个汉字的字段school;
并将表中job列名改为profession;
achievement的默认值设置为0;
alter table user_info add school varchar(15) after level;
alter table user_info change job profession varchar(10);
alter table user_info modify achievement int(11) default 0;删除表
把2011到2014年的备份表都删掉;
如果存在才删除;
drop table
if exists exam_record_2011,
exam_record_2012,
exam_record_2013,
exam_record_2014;索引
创建索引
在duration列创建普通索引idx_duration、
在exam_id列创建唯一性索uniq_idx_exam_id、
在tag列创建全文索引full_idx_tag。
-- 普通索引
create index idx_duration on examination_info(duration);
-- 唯一索引
create unique index uniq_idx_exam_id on examination_info(exam_id);
-- 全文索引
create fulltext index full_idx_tag on examination_info(tag);删除索引
请删除examination_info表上的唯一索引uniq_idx_exam_id和全文索引full_idx_tag。
第一种删除方法:
drop index uniq_idx_exam_id on examination_info;
drop index full_idx_tag on examination_info;第二种删除方法:
alter table examination_info drop index uniq_idx_exam_id;
alter table examination_info drop index full_idx_tag;聚合分组查询
聚合函数
round函数
round函数通常有两个参数:第一个参数是你希望进行四舍五入的数值。第二个参数是保留小数点后的位数。如果省略第二个参数,则默认为0,即四舍五入到整数。

从exam_record数据表中计算所有用户完成SQL类别高难度试卷得分的截断平均值(去掉一个最大值和一个最小值后的平均值)。
select
tag,
difficulty,
round(
(sum(score) - max(score) - min(score)) / (count(score) - 2),
1
) as clip_avg_score
from
exam_record
join examination_info using (exam_id)
where
tag = "SQL"
and difficulty = "hard"count函数
COUNT函数用于计算特定列中的行数,或者也可以用来计数满足特定条件的行数;
如果值为null则不记数,即count(1)与count(name)存在区别;
count函数可添加distinct筛选出不重复的数据
count(distinct name)。
有一个试卷作答记录表exam_record,请从中统计出总作答次数total_pv、试卷已完成作答数complete_pv、已完成的试卷数complete_exam_cnt。
select
count(*) as total_pv,
count(score) as complete_pv,
count(
distinct case
when score is null then null
else exam_id
end
) as complete_exam_c
from
exam_recordavg函数
通常是求某个列的所有值的平均值,它忽略null值。
SELECT department, AVG(salary) as avg_salary
FROM employees
GROUP BY department;分组查询
group by
根据条件先分组,返回每组中的第一条内容;通常配合聚合函数一起使用。
select count(distinct name),uid from Stu
group by uid根据多列条件分组
select * from Stu
group by clid,name多表查询
嵌套子查询
select name from stu
where classid = (
select id from class where manager = "小蓝"
);-
子查询(括号中的内容)如果在where或select中时相当于子查询先计算结果再判断。
-
子查询可以写在select、from、where、having等之后。
-
子查询写代码时比较直观。
select
min(t.score) as min_score_over_avg
from
(
select
t1.exam_id,
if (t1.score is null, 0, t1.score) as score,
t2.tag,
avg(score) over (
partition by
t2.tag
) as avg_score
from
exam_record t1
left join examination_info t2 on t1.exam_id = t2.exam_id
) t
where
t.score >= t.avg_score
and t.tag = 'SQL'
内层查询:
- 使用LEFT JOIN将exam_record表(别名t1)和examination_info表(别名t2)连接起来,基于exam_id字段。
- 使用IF函数处理score字段,如果score是NULL,则将其替换为0。
- 使用窗口函数AVG()来计算每个标签(tag)的平均分数,这是通过PARTITION BY t2.tag实现的。这意味着对于每个不同的tag,都会计算一个独立的平均分数。
外层查询:
- 将内层查询的结果命名为t。
- 在WHERE子句中,筛选出t中分数大于或等于其平均分数的记录,并且tag等于"SQL"。
- 使用MIN()函数来找出符合条件的记录中的最低分数,并将其命名为min_score_over_avg。
连接查询
join
-
用法为:from 表1 join 表2 where...;
-
on关键字用于过滤join前的数据,where用于过滤join后;
select
t1.id -- 学生ID
,t1.name -- 学生姓名
,t1.age -- 学生年龄
,t2.name -- 班级名称
from student t1
join classinfo t2
on t1.classid=t2.classid -
查询两个表(两个表都可以是自己)相关的信息;
也就是将一个表中的不同行的数据放在一行中。
-
表1 join 表2会形成一个新表,其中会包括两表的所有列并且表1会分别与表2(1对多)形成一行新数据(类似笛卡儿积)(若表一有5条数据表2有2条数据,则新表会有10条数据;
-
为区分两张表中相同的列名,需要在where判断条件时加上表名的前缀;
left join 和 right join
-
left join必须有on;
-
(保证左表完整)会检查左边表的数据是否都包含在新生成的表中,如果是则与join无区别,如果不是则用null与不包含的行组成新行加入新表(右表数据为null);
-
right join道理与left join相似。
窗口函数
窗口函数可以像聚合函数一样对一组数据进行分析并返回结果,二者的不同之处在于,窗口函数不是将一组数据汇总成单个结果而是为每一行数据都返回一个结果。
窗口函数定义:

聚合函数和窗口函数的区别如下图所示:

聚合函数:
SELECT SUM(salary) AS "所有员工月薪总和"
FROM employee
窗口函数:
SELECT emp_name AS "员工姓名",
SUM(salary) OVER () AS "所有员工月薪总和"
FROM employee;其中,关键字over()表明sum()是一个窗口函数。
括号内为空,表示将所有数据作为一个分组进行汇总。
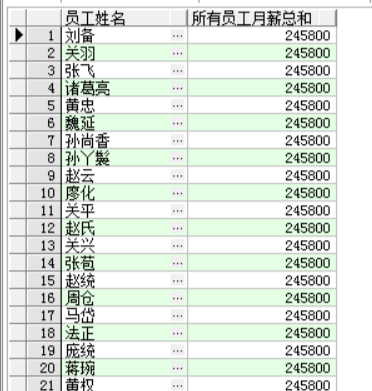
创建数据分区
窗口函数over子句中的partition by选项用于定义分区,其作用类似查询语句中的group by子句。
SELECT emp_name AS "员工姓名", salary "月薪", dept_id AS "部门编号",
SUM(salary) OVER (
PARTITION BY dept_id
) AS "部门合计"
FROM employee;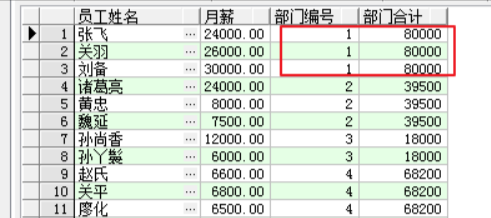
分区内的排序
窗口函数over子句中的order by选项用于指定分区内数据的排序方式,作用类似于查询语句中的order by。
以下语句用于分析员工在部门内的月薪排名:
SELECT emp_name AS "员工姓名", salary "月薪", dept_id AS "部门编号",
RANK() OVER (
PARTITION BY dept_id
ORDER BY salary DESC
) AS "部门内排名"
FROM employee;rank函数用于计算数据的名次。

指定窗口的大小
窗口函数over子句中的frame_clause选项用于指定一个移动的分析窗口,窗口总是位于分区的范围之内,是分区的一个子集。在指定了分析窗口之后,窗口函数不再基于分区进行分析,而是基于窗口内的数据进行分析。
窗口选项可以用于实现各种复杂的分析功能,例如计算累计到当前日期为止的销售额总和,每个月及其前后各N个月的平均销售额等。
指定窗口大小的具体选项如下:

下图说明了这些窗口大小选项的含义:
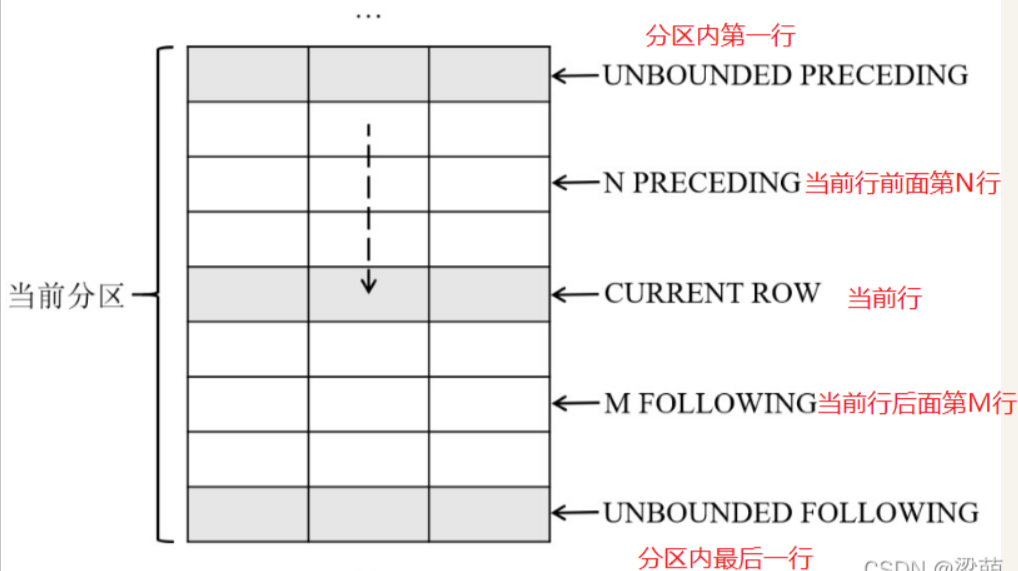
下面语句表示分析窗口从当前分区的第一行开始,直到当前行结束,即对应到图中前面5行记录。
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW