注:插件均在谷歌应用商店 下载
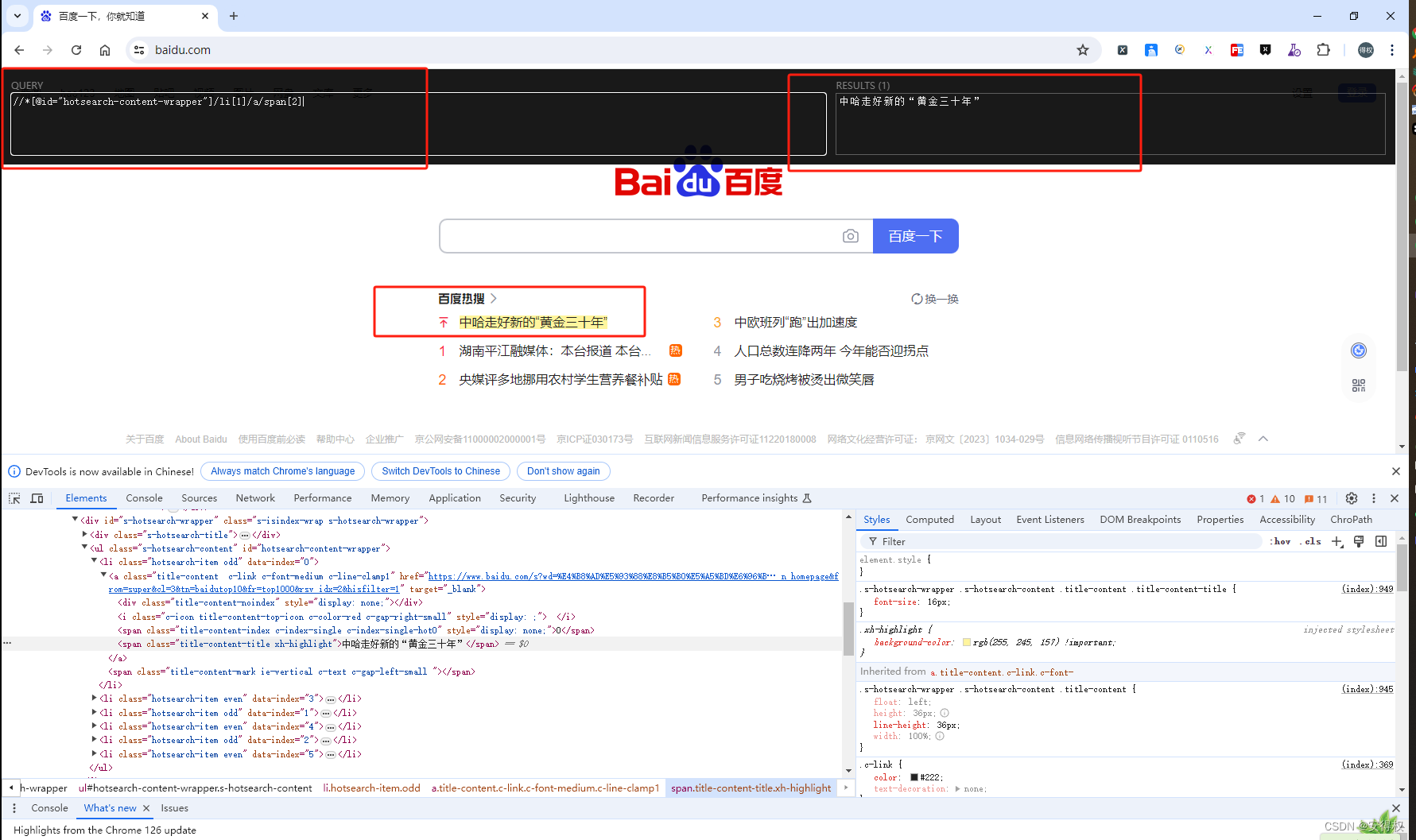
1.XPath Helper 插件
作用:用于Html中对目标字段或者属性值进行匹配
快捷启动:ctrl + shift + x
示例图如下:
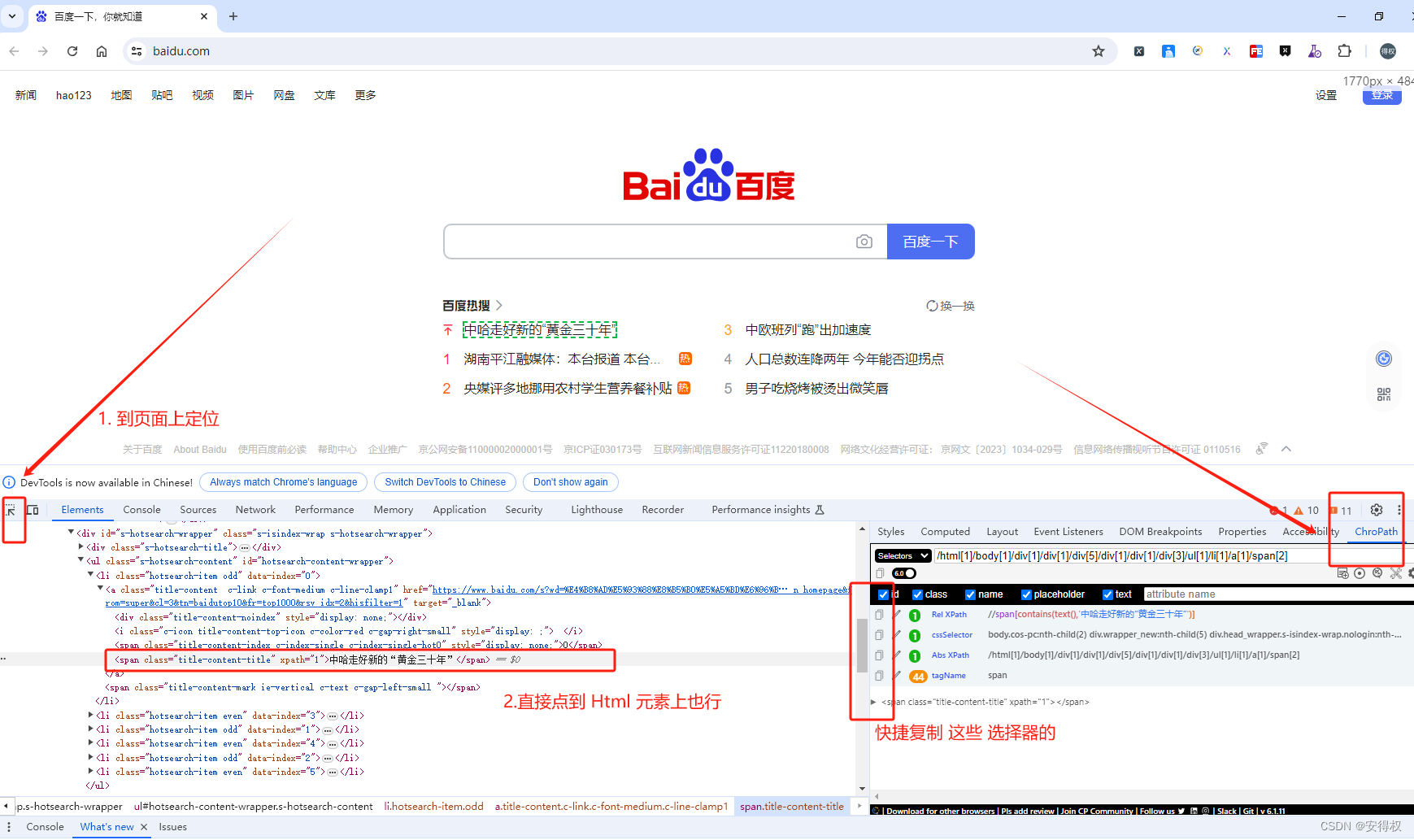
2. ChroPath 插件
作用: 提高元素定位效率
启动:谷歌浏览器 按 F12 -> Elements -> ChroPath
示例图如下:
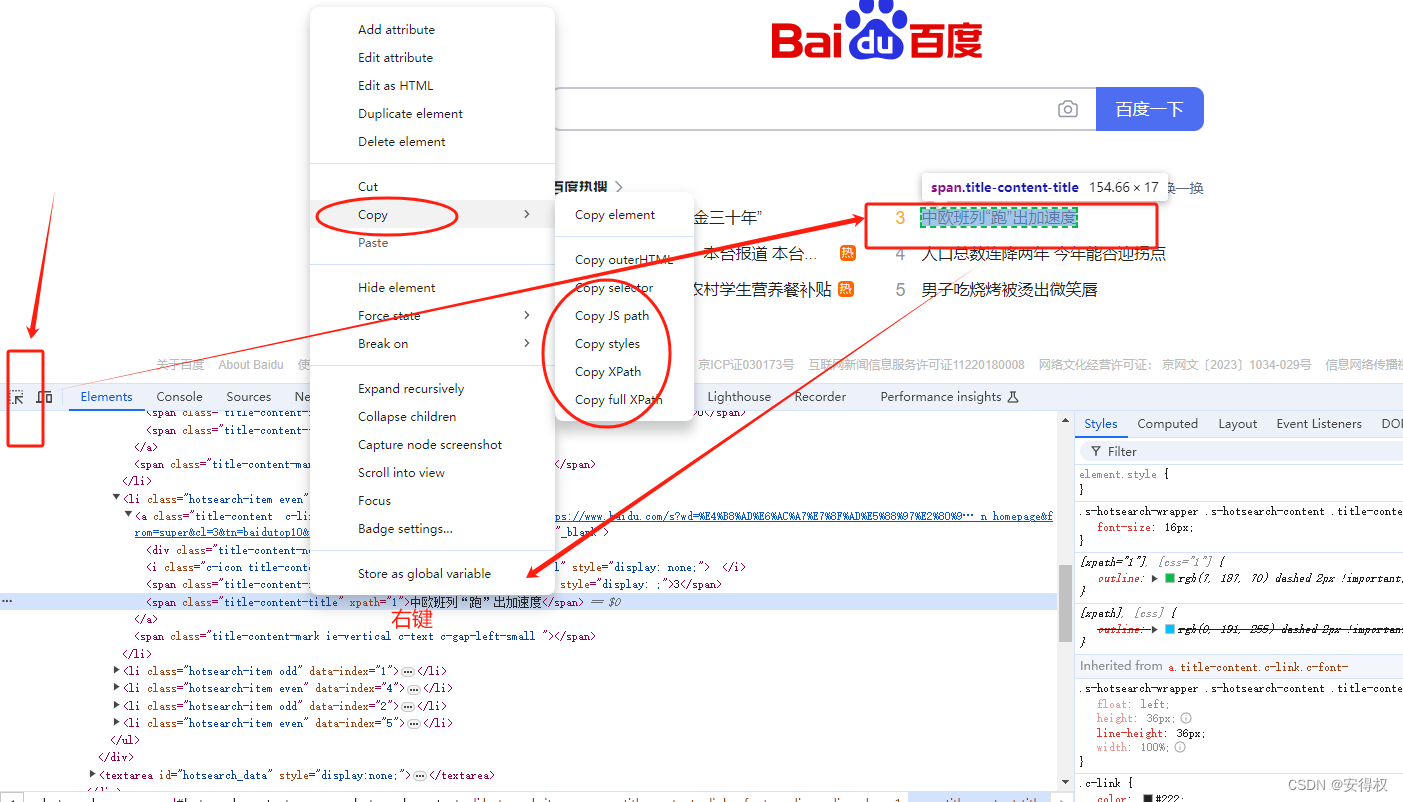
附录:
谷歌浏览器 - 任何插件都没安装的情况下如何定位呢?
F12 -> 点击左侧箭头/ctrl+shift+c 来选中元素
右键 - > Copy -> Copy XPath 等自己需要用到的选择器
如下图: