大模型技术的发展和应用,预示着更加智能化、个性化未来的到来。如果将大模型比喻为正在疾驰的科技列车,语料便是珍贵的"燃料"。本次世界人工智能大会期间,合合信息为大模型打造的"加速器"解决方案备受关注。
在大模型训练的上游阶段,"加速器"中的文档解析引擎将助力大模型突破在书籍、论文、研报等文档中的版面解析障碍,从源头为模型训练与应用输送纯净的"燃料",助力大模型跑得更快;"加速器"还加载了行业领先的acge文本向量化模型,助力大模型解决"已读乱回"的"幻觉"问题,让大模型在正确的航线上行驶得更远。
TextIn是合合信息旗下的智能文档处理平台,在智能文字识别领域深耕17年,致力于图像处理、模式识别、神经网络、深度学习、STR、NLP、知识图谱等人工智能领域研究。凭借行业领先的技术实力,为扫描全能王、名片全能王等智能文字识别产品提供强大的底层技术支持,并对企业、开发者、个人用户提供智能文字识别引擎、产品、云端服务。
立足AI时代,TextIn以深厚的技术积累为基础,接连推出通用文档解析、通用文本向量等技术,赋能大模型文档应用落地、RAG与Agent开发,成为大模型的"加速器"。
文档解析引擎:百页文档秒级处理,为大模型发展输送更加纯净的"燃料"
大模型如火如荼发展的背后,高质量的语料正在被急速消耗。对于中国的大模型企业而言,语料短缺问题更为严峻:当前大模型数据集主要为英文,全球通用的50亿大模型数据训练集里,中文语料占比极低。大批高价值语料数据"沉睡"在报告、论文、报纸等文档里,复杂的版面结构制约了大模型的训练语料处理及大模型文档问答的应用能力,使之无法被提取。
现阶段,无线表、跨页表格、复杂公式等元素的处理仍是大模型语料处理中的"拦路虎"。合合信息文档解析引擎"动能"强大,最快1.5秒可解析百页长文档中的文本、表格、图像等非结构化数据,系现阶段市面上同类文档解析引擎中处理速度最快的产品之一;引擎还具备优秀的文档"理解力",可智能还原文档阅读顺序,加速了模型在预训练、开发、使用落地等多方面的流程。
在现场,参观者可选择物理、医学、金融、社会学等多个知识领域的文档,向大模型提问专业问题,例如对特定表格内容的总结、关键要素的分析等。对比测试结果显示,加载了文档解析引擎的大模型,在回答问题的速度、详细程度、准确度上更胜一筹。
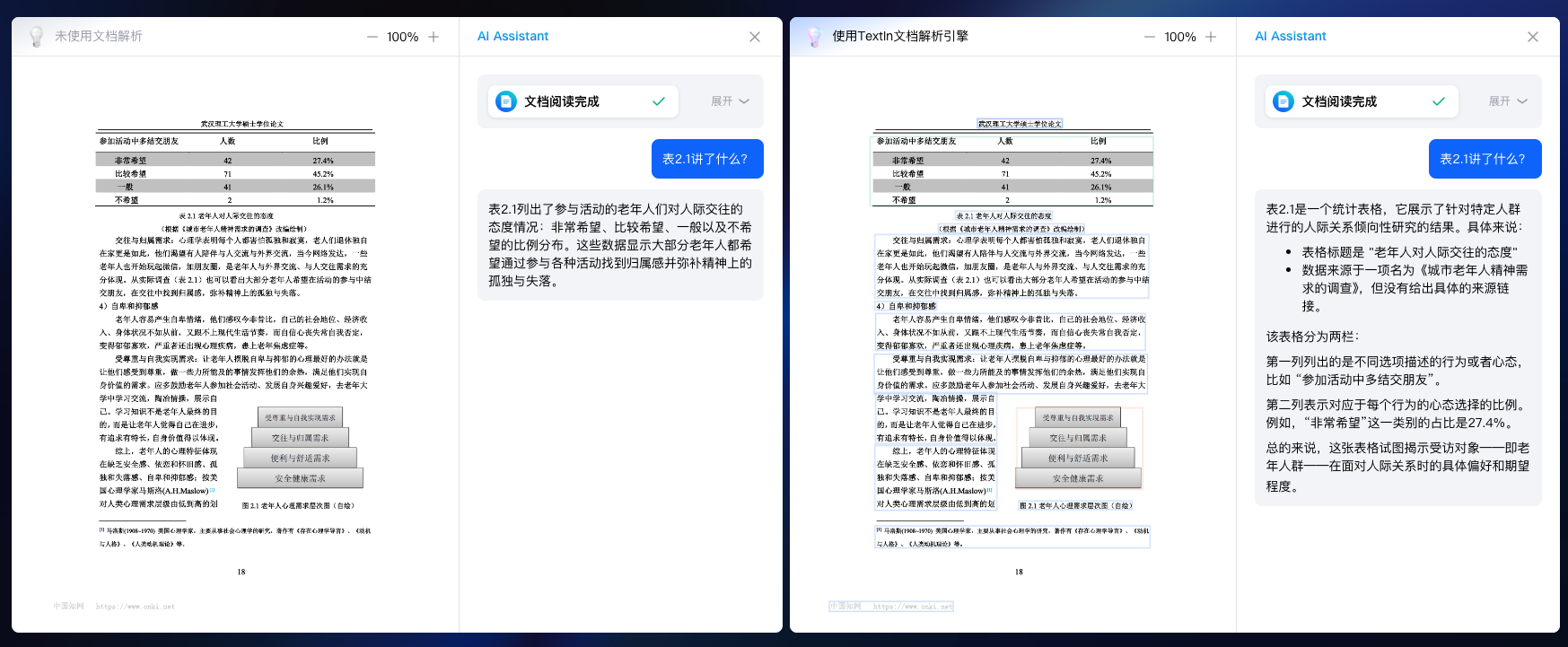
图:大模型使用文档解析引擎之前(左框)和之后(右框)的效果对比。使用后大模型具备了更快速、优秀的文档要素分析、表格内容识别能力。
文档解析引擎的"理解力"从对于图表等对象的处理能力可见一斑。目前,市面上大多数大模型尚不具备对于图表内容的识别、解析能力,文档解析引擎可对研报、论文等文档中的柱状图、折线图、饼图、雷达图等十余种常见图表进行"还原",将其拆解为大模型能"读懂"的markdown格式。
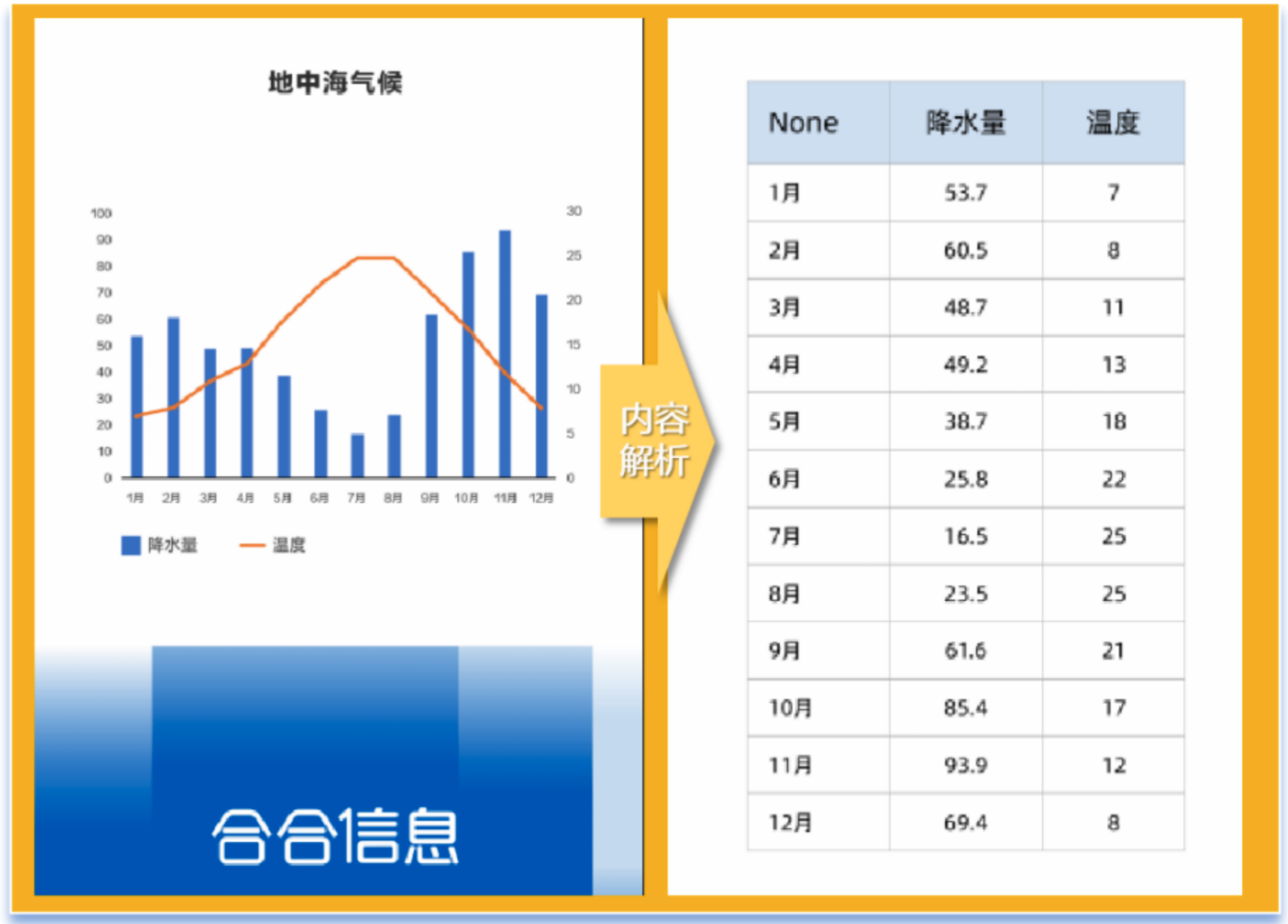
图:文档解析引擎将地中海气候图表解析为带有具体数值的Excel表格
在文档解析引擎的帮助下,大模型可以直接获取图表原始的结构化数据,高效地学习理解商业研报和学术论文等专业文档中的论证逻辑,提升语言理解、数据处理、知识推理分析的效率和准确性,满足更高价值的金融和学术等应用场景的需要。此外,文档解析引擎也能做到在图表不显示具体数值的情况下,仅依据坐标轴区间估算具体数值,实现了行业级突破。
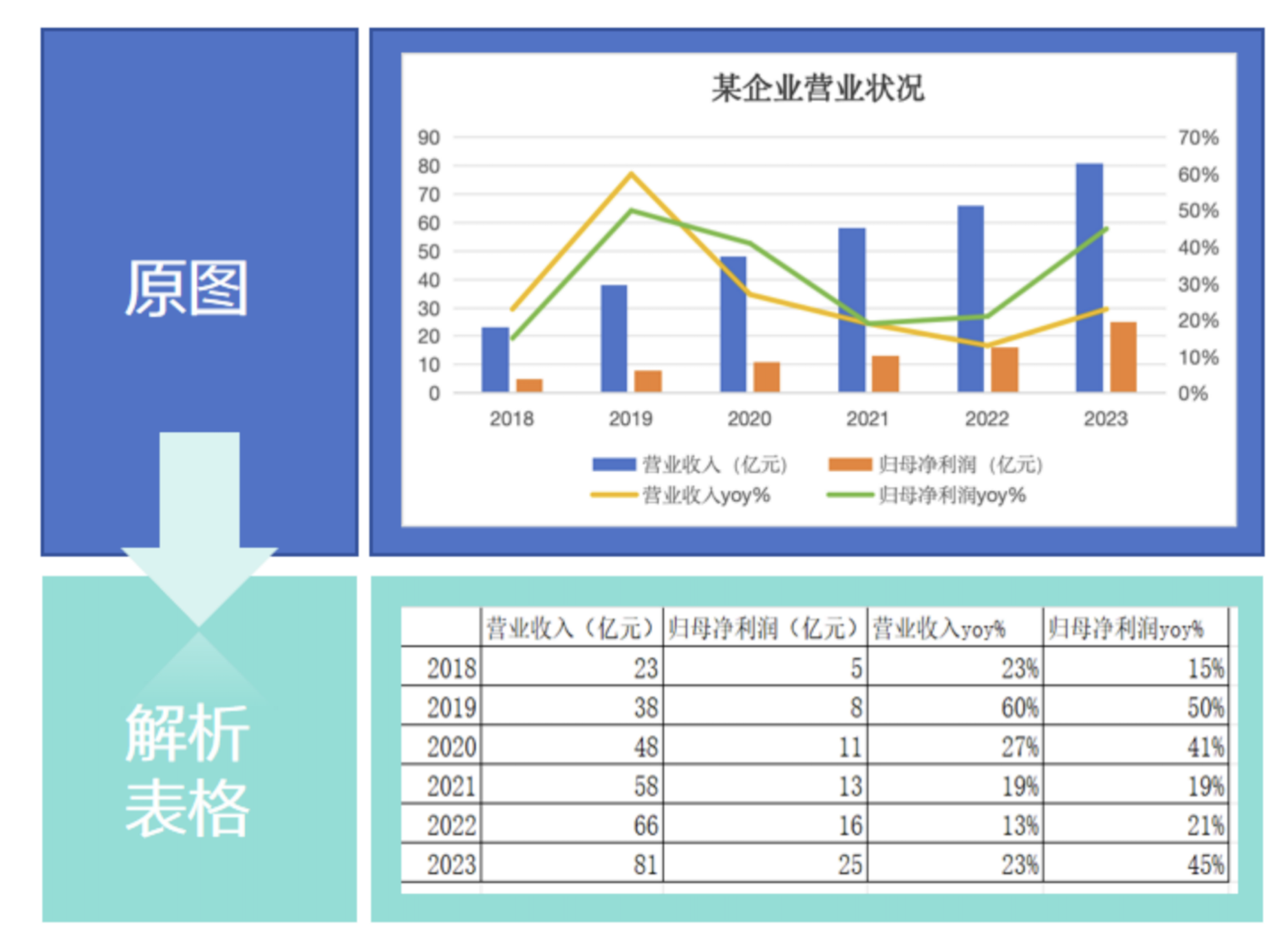
图:文档解析引擎基于坐标轴区间,对不显示具体数据的图表进行数值估算。
acge模型:为大模型发展打造"指南针"
除了语料质量问题,制约大模型发展的另一个关键点在于"幻觉"现象的产生。合合信息大模型"加速器"加载了acge_text_embedding模型(简称"acge模型"),通过对大量中文文本数据的深入学习,能够在应用中显著提高大模型信息搜索和问答的质量、效率和准确性,让搜索和问答引擎不再只是匹配文字,而是可以真正理解人的意图的特性。
如果将大模型比喻为一艘正在行驶的船,acge模型则充分发挥了"指南针"的作用,帮助大模型快速定位通往正确"思路"的航向,在信息的海洋里快速"捞针",让大模型更准确地理解专业问题。acge模型具备广泛的应用场景,从相似性搜索、信息检索到推荐系统,模型均可提供强有力的技术支撑,极大地提升系统的性能和体验。
此外,acge模型还引入持续学习训练方式,克服了神经网络存在灾难性遗忘的问题,可帮助大模型在多个行业中快速创造价值,为构建新质生产力提供强有力的技术支持。
当前,acge模型已在多个应用场景下展现其优势:
(a) 文档分类:通过ocr技术精确识别图片、文档等场景中的文字,利用acge强大的文本编码能力,结合语义相似度匹配技术,构建通用分类模型;
(b) 长文档信息抽取:通过文档解析引擎与层级切片技术,利用acge生成向量索引,检索抽取内容块,提升长文档信息抽取模型精度;
(c) 知识问答:通过文档解析引擎与层级切片技术,利用acge生成向量索引,定位文件内容,实现精准问答。
目前,合合信息大模型"加速器"已被应用于多家头部大模型厂商的预训练流程。此外,"加速器"有望在金融、财经、建筑、医疗等数据密集型领域中建立起"行业级知识库",帮助企业实现知识资产管理、搜索效率提升,优化业务沟通流程,让大模型在"源头活水"的哺育下,更快速地润泽千行百业。
行业应用:百川智能
在金融报表、行业报告等高知识密度的文档中,表格的含义是最精华的数据指标。失之毫厘差之千里,一个单元格的理解问题,可能导致整个表格的识别结果产生误差,而表格的还原准确率,直接影响着模型问答的效果。本次世界人工智能大会现场,合合信息与百川智能携手,穿透双栏、多栏、表格、图片等复杂的版式,从金融、社科等多领域文档图像中快速提取关键信息,精准地回答用户"***钻"的专业问题,引起了业内人士的关注。
百川智能是一家研发通用人工智能并提供相关服务的公司,核心业务是打造基础大模型及颠覆性上层应用。在大模型文档处理场景中,合合信息与百川共同探索技术应用新范式,破解困扰大模型产业已久的多文档元素识别、版面分析难题,将对百页文档的整体处理速率提升超过10倍。
在表格内容还原、复杂样本处理、多语言文档识别等方面,合合信息大模型"加速器"具备高准确性和稳定性,大幅提升了模型的理解力,并通过其强大的多语言识别、多类型支持能力,为多个行业提供了高效、准确、实用的文档解析服务。目前,大模型"加速器"已被多家大模型厂商应用于金融、医学、财经、媒体等多领域的文档的解析中,助力大模型更顺利地接轨"专业课"。
如有帮助,请多关注
TeahLead KrisChang,10+年的互联网和人工智能从业经验,10年+技术和业务团队管理经验,同济软件工程本科,复旦工程管理硕士,阿里云认证云服务资深架构师,上亿营收AI产品业务负责人。