一、目的
由于之前很少用ClickHouse的SQL语句,因此在where条件中截取create_time字段的时分秒部分,即Hive的substr(create_time,12,8),但是ClickHouse中却无法使用,因此就研究了一下
二、Hive的substr函数截取时间戳字段的时分秒
2.1 SQL语句
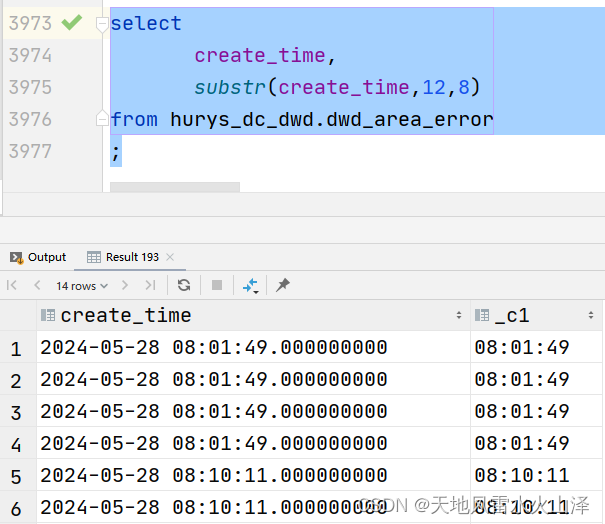
select
create_time,
substr(create_time,12,8)
from hurys_dc_dwd.dwd_area_error
;2.2 运行结果
三、ClickHouse的formatDateTime函数截取时间戳字段的时分秒
3.1 SQL语句
select
create_time,
toDate(create_time) day,
formatDateTime(create_time,'%H:%M:%S') time
from hurys_dc.b_event
limit 10
;3.2 运行结果
--2023-08-07 00:01:49,2023-08-07,00:01:49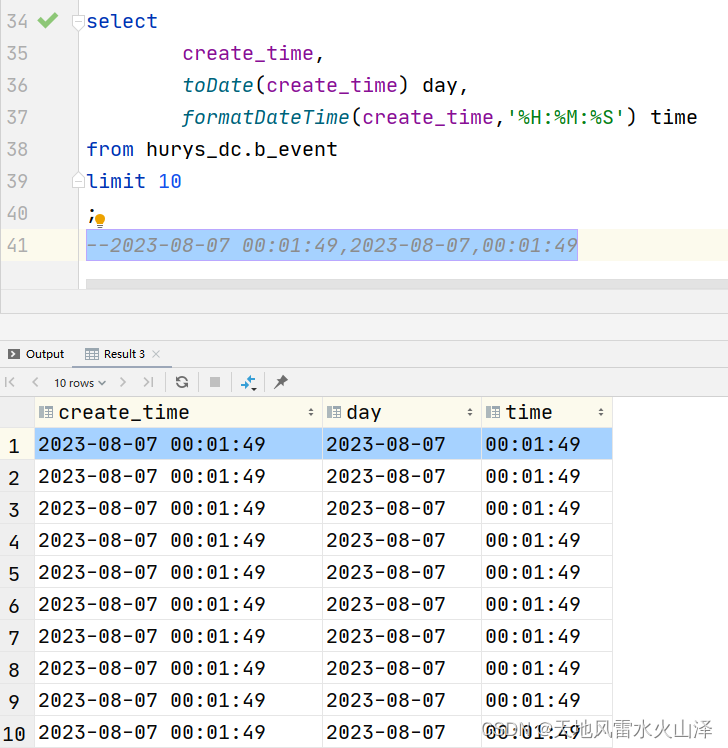
不同数据库的SQL语言真的不太一样,尤其是与标准SQL不同的一些非关系型数据库的SQL语句。不过,只要区别不大,刚起来用的时候注意点就行了