今日继续学习树莓派4B 4G:(Raspberry Pi,简称RPi或RasPi)
本人所用树莓派4B 装载的系统与版本如下:
版本可用命令 (lsb_release -a) 查询:
Python 版本3.7.3:
本文很水,就介绍一下我以后的学习使用PC训练深度学习模型,然后给树莓派推理的开发想法
为何在PC端安装pytorch环境:
模型训练通常对硬件要求较高,但推理阶段对硬件的要求相对较低。这允许你将模型部署到各种边缘设备上,如树莓派。
使用树莓派进行PyTorch深度学习模型的训练,虽然技术上可行,但通常不是最优选择,主要因为树莓派的计算能力和内存资源相对有限。
因此,在更高性能的Windows电脑上先训练好模型,然后再将训练好的模型部署到树莓派上进行推理(即使用模型进行预测或分类等操作)的做法是非常提倡的,也是实际应用中常见的做法。
- 模型兼容性:确保在Windows上训练的模型能够无缝迁移到树莓派上。这通常不是问题,因为PyTorch模型是跨平台的,但你需要确保所有依赖库(如PyTorch本身)在树莓派上也是兼容的。
- 性能优化:虽然树莓派足以进行推理,但可能需要对模型进行量化或剪枝等优化措施,以进一步提高在树莓派上的运行效率。
- 数据传输:如果模型或数据集非常大,可能需要考虑如何将它们从Windows电脑传输到树莓派。确保有稳定且足够快的网络连接,或者使用外部存储设备(如USB驱动器)进行传输。
- 选择合适的模型:根据树莓派的性能限制,选择适合在边缘设备上运行的模型。
- 进行模型优化:在部署到树莓派之前,对模型进行必要的优化,如量化、剪枝等。
- 使用容器化技术:考虑使用Docker等容器化技术来打包和部署模型,以确保在不同环境下的一致性和可移植性。
- 测试与验证:在树莓派上充分测试模型,确保其在目标应用中的准确性和性能符合预期。
ONNX协议:
- 模型转换:将不同框架(如PyTorch、TensorFlow、MXNet等)训练的模型转换为ONNX格式,以便在其他框架或硬件上部署。
- 模型优化:利用ONNX Runtime等推理引擎对ONNX模型进行优化,提高模型的推理速度和效率。
- 模型部署:将ONNX模型部署到各种硬件和平台上,包括云端、边缘设备和移动端等。
初步认识Pytorch:
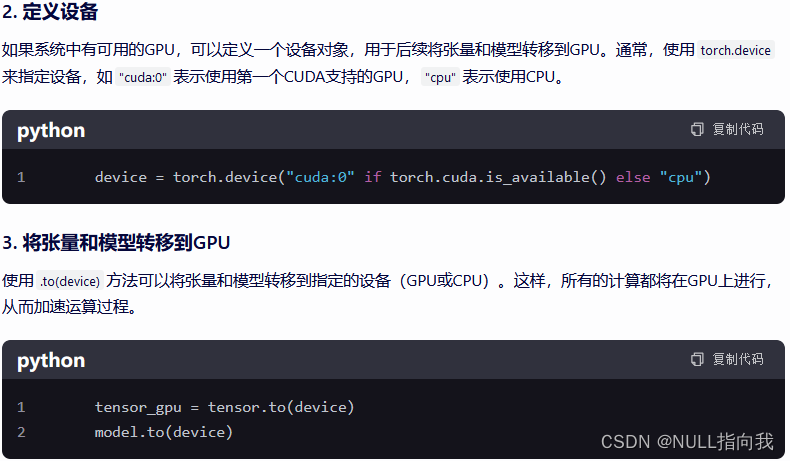
GPU加速
GPU加速是通过将数据和模型从CPU转移到GPU来实现的,从而利用GPU的并行计算能力来加速深度学习模型的训练和推理过程。
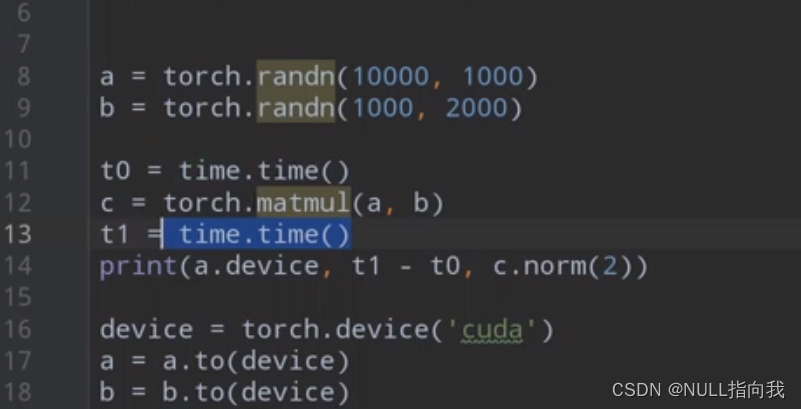
**示例:**定义俩个比较大的矩阵进行运算,分别使用CPU与GPU进行运算比较
GPU运行了俩次,第二次所用时间小于CPU:
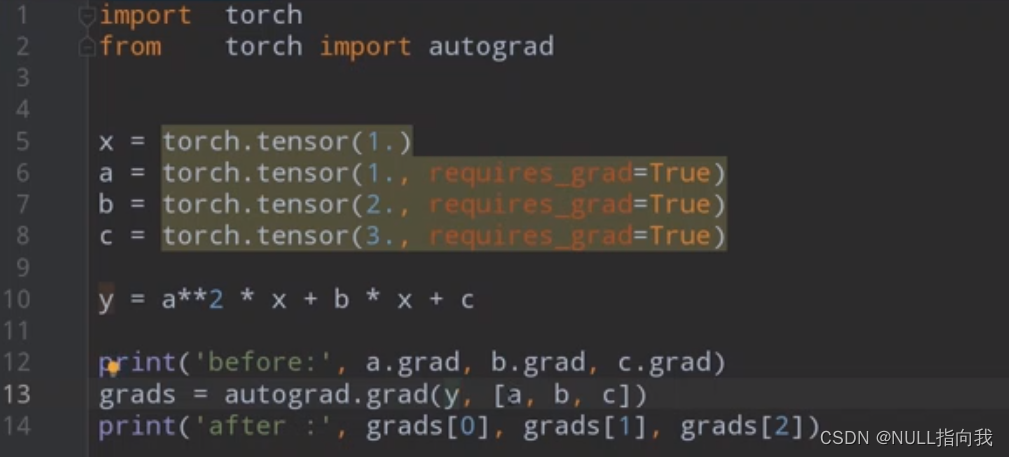
自动求导
PyTorch的自动求导机制是训练神经网络时的一个核心概念,它使得计算梯度变得简单而高效。
常用网络层
PyTorch提供了丰富的网络层实现,包括全连接层、卷积层、池化层、激活函数层等。
深度学习训练过程:
把图像拆分成以为像素阵列
Pytorch 最全入门介绍,Pytorch入门看这一篇就够了-CSDN博客

匆匆结语:
没有实践的理论学习与查找资料真是枯燥无味......
配置个环境变量丝毫没有任何成就感,觉得很浪费时间...