在使用 JuiceFS 时,我们选择了 SeaweedFS 作为对象存储,以及 TiKV 作为元数据存储,目前在 SeaweedFS 上已经存储了近1.5PB 的数据。关于 SeaweedFS 和 TiKV 配置的参考资料不多,本文将为社区各位用户提供我们的部署实践,并提供详细的命令示例,希望能给社区各位用户一些参考。此外,在文章的最后会附上我们通过多个文件实现配额管理以及在 JuiceFS 文件系统内进行跨机房数据迁移的实践。
如何部署 TIKV + SeaweedFS
JuiceFS 是一款高性能的分布式文件系统,专为云原生环境设计,遵循 Apache 2.0 开源协议。该系统完全兼容 POSIX,允许用户将各种对象存储作为海量本地磁盘使用。
我们为什么会选择 SeaweedFS 作为 JuiceFS 的对象存储,可以参见构建易于运维的 AI 训练平台:存储选型与最佳实践、基于 JuiceFS 构建高校 AI 存储方案:高并发、系统稳定、运维简单。目前我们在 SeaweedFS 上保存了近 1.5PB 的 JuiceFS 数据。
1. 开始部署
下文将介绍如何结合 SeaweedFS 和 TiKV 来构建 JuiceFS 文件系统。SeaweedFS 支持 S3 协议,使用 SeaweedFS 作为对象存储;同时由 TiKV 提供 JuiceFS 元数据服务。
当 JuiceFS 文件系统的 prefix 与 SeaweedFS 的 key 构造规则不一致时,可以使用相同的 TiKV 实例。例如,可以选用 uuid 作为 JuiceFS 的 prefix。本文假设 JuiceFS 与 SeaweedFS 共享同一套 TiKV。****但是,推荐分开部署。
操作将在 Rocky8.9 操作系统上进行,所使用的命令与 CentOS 兼容。
软件版本信息:
Tikv:v6.5.0
SeaweedFS:3.59
节点信息:
| 机器 | 操作系统 | 内核版本 | CPU | Memory | Disk |
|---|---|---|---|---|---|
| tikv01 | Rocky8.9 | 4.18.0-513.5.1.el8_9.x86_64 | 80 Core | 512GB | 1* NVME 1.92T DWPD >=1 |
| tikv02 | Rocky8.9 | 4.18.0-513.5.1.el8_9.x86_64 | 80 Core | 512GB | 1* NVME 1.92T DWPD >=1 |
| tikv03 | Rocky8.9 | 4.18.0-513.5.1.el8_9.x86_64 | 80 Core | 512GB | 1* NVME 1.92T DWPD >=1 |
| seaweedfs01 | Rocky8.9 | 4.18.0-513.5.1.el8_9.x86_64 | 80 Core | 256GB | 10* 18TB HDD |
| seaweedfs02 | Rocky8.9 | 4.18.0-513.5.1.el8_9.x86_64 | 80 Core | 256GB | 10* 18TB HDD |
| seaweedfs03 | Rocky8.9 | 4.18.0-513.5.1.el8_9.x86_64 | 80 Core | 256GB | 10* 18TB HDD |
2. 机器配置优化
节点参数调优
bash
yum install -y numactl vim
echo vm.swappiness = 0 >> /etc/sysctl.conf
echo net.core.somaxconn = 32768 >> /etc/sysctl.conf
echo net.ipv4.tcp_syncookies = 0 >> /etc/sysctl.conf
echo fs.nr_open = 20000000 >> /etc/sysctl.conf
echo fs.file-max = 40000000 >> /etc/sysctl.conf
echo vm.max_map_count = 5642720 >> /etc/sysctl.conf
sysctl -p
echo '* - nofile 10000000' >> /etc/security/limits.conf机器时间同步
bash
#rocky8.9 操作系统自带chronyc工具,因此不需要额外下载
vim /etc/chrony.conf
# 注释下面一行,新增server time1.aliyun.com iburst
#pool 2.pool.ntp.org iburst
server time1.aliyun.com iburst
# 命令行执行,触发时间同步
systemctl daemon-reload
systemctl restart chronyd
chronyc makestep
timedatectl set-timezone Asia/Shanghai
date3. TiKV 部署
根据 TiKV 的文档,用户需要先检查机器配置是否满足先决条件。TiKV 默认配置下会占用机器最多 75% 的内存,强烈不建议在未调整参数的情况下将 TiKV 与其他服务共同部署。
混合部署需要参照 TIKV混合部署拓扑进行参数调优、部署,也可参照 TiKV 配置文件描述自行修改配置。
1. 初始化集群拓扑文件
bash
tiup cluster template > topology.yaml
# 根据实际情况修改tikv配置文件topology.example.yaml
yaml
# 配置 tikv 全局参数
global:
user: "root"
ssh_port: 22
deploy_dir: "/mnt/disk1/tikv-deploy"
data_dir: "/mnt/disk1/tikv-data"
listen_host: 0.0.0.0
arch: "amd64"
# 开启 tls 认证,部署完成后可使用 tiup cluster display test 获取证书文件路径
enable_tls: true
monitored:
# 建议不使用默认端口,防止在混布场景下的端口冲突
node_exporter_port: 9900
blackbox_exporter_port: 9915
pd_servers:
- host: 192.168.0.1
client_port: 2279
peer_port: 2280
- host: 192.168.0.2
client_port: 2279
peer_port: 2280
- host: 192.168.0.3
client_port: 2279
peer_port: 2280
tikv_servers:
- host: 192.168.0.1
port: 2260
status_port: 2280
- host: 192.168.0.2
port: 2260
status_port: 2280
- host: 192.168.0.3
port: 2260
status_port: 2280
monitoring_servers:
- host: 192.168.0.1
port: 9190
grafana_servers:
- host: 192.168.0.1
port: 3100
alertmanager_servers:
- host: 192.168.0.1
web_port: 9193
cluster_port: 91942. 执行部署命令
检查修复集群中潜在的问题
bash
tiup cluster check ./topology.yaml --user root [-p] [-i /home/root/.ssh/gcp_rsa]
# 遇到的问题基本都可以通过 --apply 进行修复
tiup cluster check ./topology.yaml --apply --user root [-p] [-i /home/root/.ssh/gcp_rsa]使用 deploy 命令部署集群
bash
tiup cluster deploy test v6.5.0 ./topology.yaml --user root [-p] [-i /home/root/.ssh/gcp_rsa]安装 tikv 相关组件可能耗时较长,耐心等待即可
3. 检查部署 TiKV 集群
bash
tiup cluster list
tiup cluster display test4. 启动 TiKV 集群
bash
tiup cluster start test5. 测试 TiKV 集群
参照 TiKV Performance Overview 使用 ycsb 工具进行性能测试,测试完毕后需要重新部署 TiKV。
4. Seaweedfs 部署
关于 SeaweedFS 组件介绍,可以参考 Seaweedfs Components。本文默认数据复制级别为三副本。
节点信息
| 机器 | IP | 操作系统 | 内核版本 | CPU | Memory | Disk |
|---|---|---|---|---|---|---|
| seaweedfs01 | 192.168.1.1 | Rocky8.9 | 4.18.0-513.5.1.el8_9.x86_64 | 80 Core | 256GB | 10* 18TB HDD |
| seaweedfs02 | 192.168.1.2 | Rocky8.9 | 4.18.0-513.5.1.el8_9.x86_64 | 80 Core | 256GB | 10* 18TB HDD |
| seaweedfs03 | 192.168.1.3 | Rocky8.9 | 4.18.0-513.5.1.el8_9.x86_64 | 80 Core | 256GB | 10* 18TB HDD |
架构信息
| 服务 | 节点 |
|---|---|
| master01 | seaweedfs01 |
| master02 | seaweedfs02 |
| master03 | seaweedfs03 |
| filer01 | seaweedfs01 |
| filer02 | seaweedfs02 |
| filer03 | seaweedfs03 |
| volumer01-10 | seaweedfs01 |
| volumer11-20 | seaweedfs02 |
| volumer21-30 | seaweedfs03 |
1. 部署 prometheus push gateway
prometheus push gateway 用于汇总 seaweedfs 监控数据,需要对接prometheus 将 metrics 保存至 tsdb
deploy prometheus push gateway
bash
wget https://github.com/prometheus/pushgateway/releases/download/v1.5.1/pushgateway-1.5.1.linux-amd64.tar.gz
tar -xvf pushgateway-1.5.1.linux-amd64.tar.gz
cd pushgateway-1.5.1.linux-amd64/
cp pushgateway /usr/local/bin/pushgateway
cat > /etc/systemd/system/pushgateway.service << EOF
[Unit]
Description=Prometheus Pushgateway
Wants=network-online.target
After=network-online.target
[Service]
User=root
Group=root
Type=simple
ExecStart=/usr/local/bin/pushgateway
[Install]
WantedBy=multi-user.target
EOF
cd ..
rm -rf pushgateway-1.5.1.linux-amd64.tar.gz
systemctl daemon-reload
systemctl start pushgateway2. 部署 SeaweedFS Master服务
下载 seaweedfs 二进制文件
deploy seaweedfs master
bash
wget https://github.com/seaweedfs/seaweedfs/releases/download/3.59/linux_amd64_full.tar.gz
tar -xvf linux_amd64_full.tar.gz
rm -rf ./linux_amd64_full.tar.gz
cp weed /usr/local/bin参考文档:
准备 master 配置文件 + 运行环境
在本文档中,会在三台 seaweedfs 机器上各部署一个 master service,并声明数据复制级别为三副本。
准备 Master 配置文件
bash
# 清空seaweedfs 即将使用的目录
# rm -rf /seaweedfs/master/*
mkdir -p /seaweedfs/master/mlog /seaweedfs/master/mdir
mkdir -p /etc/seaweedfs
cat > /etc/seaweedfs/master.conf << EOF
loglevel=2
logdir=/seaweedfs/master/mlog
mdir=/seaweedfs/master/mdir
# 三个master地址
peers=192.168.1.1:9333,192.168.1.2:9333,192.168.1.3:9333
port=9333
# 设置集群复制级别为三副本
defaultReplication=020
# 当前节点IP
ip=192.168.1.1
# prometheus push gateway 地址
metrics.address=192.168.1.1:9091
EOF配置 Master Service
bash
cat > /etc/systemd/system/weed-master.service << EOF
[Unit]
Description=SeaweedFS Server
After=network.target
[Service]
Type=simple
User=root
Group=root
ExecStart=/usr/local/bin/weed master -options=/etc/seaweedfs/master.conf
WorkingDirectory=/usr/local/bin
SyslogIdentifier=seaweedfs-master
[Install]
WantedBy=multi-user.target
EOF4. 部署 SeaweedFS Volume 服务
在本文档中,会在 seaweedfs 机器上各部署 10个 volume server,不展示重复操作。请自行格式化、挂载磁盘。
参考文档:
PS:
-
采用一个 volume 管理一块盘的方式,便于磁盘故障后的更换。
-
volume server 将参数写进 service而不是配置文件,便于服务管理。
-
配置 index=leveldb 来减少内存占用(Seaweedfs Memory consumption)。
-
默认一个 volume 30GB,-max 限制至多存在max个volume。
-
需要提前创建 volume 目录。
-
一个 volume server 设置的 volume max 在 Seaweedfs FAQ 中的建议是保持总大小小于磁盘大小。
部署 volume service
bash
# 将 mserver 地址替换为真实 master 的地址
# 根据实际情况配置 dir、datacenter、rack、ip、port等信息
# 根据磁盘数量重复执行命令以创建多个service
mkdir -p /seaweedfs/volume1/log /mnt/disk1/volume
cat > /etc/systemd/system/weed-volume1.service << EOF
[Unit]
Description=SeaweedFS Volume
After=network.target
[Service]
Type=simple
User=root
Group=root
ExecStart=/usr/local/bin/weed volume -index=leveldb -logdir=/seaweedfs/volume1/log -dir=/mnt/disk1/volume -mserver=192.168.1.1:9333,192.168.1.2:9333,192.168.1.3:9333 -dataCenter=dc1 -rack=rack1 -ip=192.168.1.1 -port=10001 -max=20000
WorkingDirectory=/usr/local/bin/
SyslogIdentifier=seaweedfs-volume
[Install]
WantedBy=multi-user.target
EOF5. 部署 SeaweedFS Filer 服务
在本文档中,会在 3 台 seaweedfs 机器上各部署 1个 filer,使用 tikv 为filer 提供存储。不展示重复操作。
参考文档:
Tips****:
-
提前在机器上准备 /etc/seaweedfs/filer.toml /etc/seaweedfs/s3.json文件,/etc/seaweedfs 是 filer 的默认配置文件路径,可以根据实际情况显示指定文件位置
-
提前将 tikv 密钥拷贝至运行 filer 的机器
-
Seaweedfs filer 默认无需身份认证就能访问,为保护数据安全请参照 Longhorn Create an Ingress with Basic Authentication (nginx) 为 filer web ui 配置带身份认证的 nginx,filer web ui 默认端口为 8888。
配置 file service
bash
mkdir -p /seaweedfs/filer/log
cat > /etc/systemd/system/weed-filer.service << EOF
[Unit]
Description=SeaweedFS Filer
After=network.target
[Service]
Type=simple
User=root
Group=root
ExecStart=/usr/local/bin/weed filer -logdir=/seaweedfs/filer/log -ip=192.168.1.1 -port=8888 -master=192.168.1.1:9333,192.168.1.2:9333,192.168.1.3:9333 -s3 -s3.config=/etc/seaweedfs/s3.json
WorkingDirectory=/usr/local/bin/
SyslogIdentifier=seaweedfs-filer
[Install]
WantedBy=multi-user.target
EOFfiler.toml
bash
cat > /etc/seaweedfs/filer.toml << EOF
[tikv]
enabled = true
# If you have many pd address, use ',' split then:
# pdaddrs = "pdhost1:2379, pdhost2:2379, pdhost3:2379"
pdaddrs = "192.168.0.1:2279,192.168.0.1:2279,192.168.0.1:2279"
# Concurrency for TiKV delete range
deleterange_concurrency = 1
# Enable 1PC
enable_1pc = false
# Set the CA certificate path
ca_path="/etc/seaweedfs/tikv/tls/ca.crt"
# Set the certificate path
cert_path="/etc/seaweedfs/tikv/tls/client.crt"
# Set the private key path
key_path="/etc/seaweedfs/tikv/tls/client.pem"
# The name list used to verify the cn name
verify_cn=""
EOFS3.json
json
# 配置s3信息
cat > /etc/seaweedfs/s3.json << EOF
{
"identities": [
{
"name": "名称",
"credentials": [
{
"accessKey": "access密钥",
"secretKey": "secret密钥"
}
],
"actions": [
"Read",
"Write",
"List",
"Tagging",
"Admin"
]
}
]
}
EOF启动服务 启动 master
bash
systemctl daemon-reload
systemctl start weed-master.service启动 filer 和 volume server
bash
systemctl start weed-filer.service
# 启动所有 volume server
systemctl start weed-volume{1..10}.service6. 验证
使用 weed shell 检查 seaweedfs 组件运行情况
bash
# 登录任一master节点,进入weed shell控制台
weed shell
# 常用命令:
cluster.check # 检查集群网络连通性
cluster.ps # 检查集群进程状态
volume.list # 列出集群volume server7. 访问 SeaweedFS filer
浏览器打开:http://192.168.1.1:8888
将 IP 替换为真实 filer 地址、域名即可。生产环境建议使用域名进行访问并为web ui配置带身份认证的 nginx。
其他实践
多文件系统实现目录配额管理
我们初次使用 JuiceFS 时,社区版本还不支持目录配额(quota)功能,因此我们通过维护多个 JuiceFS 文件系统来实现文件系统配额控制。这种方法需要使用多个文件系统共享同一个缓存盘,从而会出现缓存容量的竞争。在极端情况下,可能会导致缓存盘空间被不活跃的目录占满,而活跃的目录则因缺乏空间而无法有效使用缓存盘。
JuiceFS v1.1 版本中推出目录配额功能,我们评估了是否需要合并所有文件系统,并改用目录配额来限制各目录的容量。以下是我们自己的一些分析:
-
多 JuiceFS 文件系统
-
优点
-
在不使用 JuiceFS 目录配额功能的情况下能进行目录容量限制。
-
单一文件系统数据量有限,利于社区版迁移文件系统(备份文件系统、跨机房迁移、协商停机窗口)。
-
单一 JuiceFS 文件系统挂载点掉线的影响范围有限。
-
-
缺点
-
单一机器同时挂载多个 JuiceFS 文件系统,使用同一块磁盘作为缓存盘会带来缓存盘空间竞争问题。
-
节点同时挂载多个目录时存在大量节点 CPU 和内存资源浪费。
-
跨文件系统的数据拷贝效率低。
-
CSI 场景下在一台机器上挂载多个 JuiceFS 进程会抢占一定量的任务内存资源。
-
-
-
单一 JuiceFS 文件系统
-
优点
-
独享缓存盘,对比在一台机器上挂载多 JuiceFS文件系统能更好的缓存热数据。
-
文件系统内数据拷贝、clone 方便。
-
总体 JuiceFS 进程数量更少,维护方便。
-
-
缺点
-
bucket 巨大,某些对象存储存在 object 数量、总大小限制、性能下降等问题,不支持这种超大 bucket。可通过 JuiceFS 配置数据分片 解决。
-
元数据体积庞大,对元数据备份机器的内存存在要求且备份时间极长,难以做到每小时备份一次元数据或每 8 小时备份一次元数据(最新发布的 JuiceFS v1.2 解决了此问题)。
-
挂载点掉线的影响范围更大。
-
-
考虑到我们的实际情况和某些迁移需求,最终还是使用多 JuiceFS 文件系统进行管理,但对于一些新用户,还是推荐单一文件系统。
JuiceFS 文件系统进行跨机房数据迁移
在过去三年中,我们进行了大量的数据迁移工作,涉及的数据总量达到 3PB。今年进行了近 1PB 的 JuiceFS 文件系统跨机房迁移。经验表明,使用 JuiceFS 的 S3 对拷加上元数据切换是两个 JuiceFS 之间迁移速度最快的方法。例如,使用 rclone 扫描一个 50TB 的文件系统可能需要至少半天时间,而通过直接对拷的方式,迁移过程可能仅需 10 分钟到半小时。
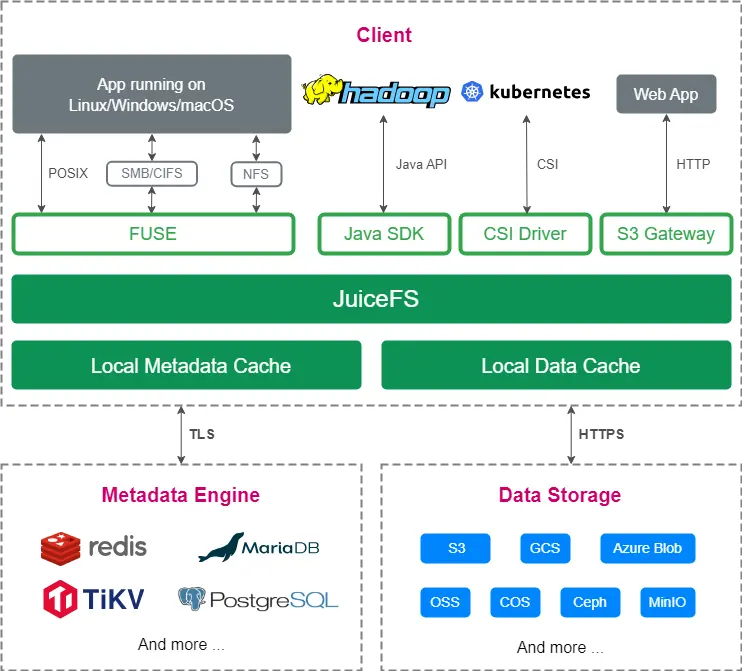
常规文件系统之间的数据迁移主要依靠文件系统对拷的方法,JuiceFS 文件系统之间的迁移方式却有所创新。JuiceFS 本身并不直接存储数据,而是将文件元数据保存在 Metadata Engine 中,把文件数据存储在对象存储中。这种独特的架构使得可以通过创新的方式来处理数据迁移。具体来说,JuiceFS 允许通过替换元数据和 S3 数据来执行迁移操作。只需确保迁移前后的元数据和 S3 数据完全匹配,便可以通过配置 JuiceFS 的设置来生成一个与原系统完全相同的克隆系统。
-
当需要迁移对象存储时,可以通过对象存储对拷 + 设置对象存储的方式进行切换。
-
当需要迁移元数据时,可以通过元数据 dump load (元数据备份和恢复)的方式进行切换。
-
当需要同时迁移对象存储和元数据时,可以同时使用 S3 对拷 + 元数据导入导出 + 设置对象存储的方式进行处理。
数据切换完成后可以使用 juicefs fsck 命令进行数据一致性校验,检查文件系统需要的每一个 s3 object 是否存在。然而,这种方法最大的缺点是需要停机 进行数据增量同步和元数据切换,对单个文件系统而言,停机时长 = 数据增量同步 + 元数据切换 (+ 数据校验) 。此外,对于数据同步过程,目标端多余的过时数据,可在后续通过 juicefs gc 进行清理。
增量同步 + 数据切换
bash
# 使用 juicefs sync 先进行数据同步
juicefs sync --list-depth=2 -u --delete-dst --no-https -p 40 s3://xxx:xxx@$bucket.oss s3://xxx:xxx@$bucket.oss2
# 使用 rclone 再进行一次补充同步
rclone copy --log-file=xxx --ignore-existing --checkers 300 --transfers 150 s3-1:bucket1 s3-2:bucket1
# 使用 juicefs 导入导出元数据
juicefs dump "origin meta address" meta.json
juicefs load "new meta address" meta.json
# 配置新文件系统使用新 s3,更新ak sk
juicefs config "new meta address" --bucket $NEW_BUCKET_ADDRESS --access-key xxxx --secret-key xxxx
# 使用 fsck 检查文件系统一致性
juicefs fsck "new meta address"以上内容总结了我们在部署 SeaweedFS 和 TiKV、设置目录配额以及进行数据迁移方面的实践经验。我们希望这些经验能为社区的其他用户提供参考和帮助。